- The paper presents an innovative two-stage framework that combines a Variational Motion Generator with diffusion-based video synthesis to generate lifelike talking head videos.
- The methodology fuses audio features with AU intensity embeddings via a variational autoencoder to predict temporally coherent 2D landmarks for expressive facial animations.
- Experimental results on the MEAD dataset show superior visual quality and emotion accuracy, as measured by PSNR, SSIM, FID, and SyncNet confidence scores.
Talking Head Generation via AU-Guided Landmark Prediction
Introduction
Facial animations in synthetic media are constrained by the ability to replicate natural human expression. This research proposes a novel framework for talking head video generation driven by audio signals and fine-grained expression control using Facial Action Units (AUs). Traditional approaches have relied heavily on emotion labels or implicit AU conditioning, which can limit nuanced and precise facial reproduction.
Methodology
The framework consists of two main stages: the Variational Motion Generator (VMG) and the Motion-to-Video synthesis.
Variational Motion Generator:
The VMG employs a variational autoencoder (VAE) model. It fuses audio features with AU intensity embeddings to predict temporally coherent 2D landmarks. This stage aims to produce expressive facial motion sequences that reflect nuanced AU activations. The VAE uses dilated convolutions for encoding and decoding the frame-wise latent representations (Figure 1).
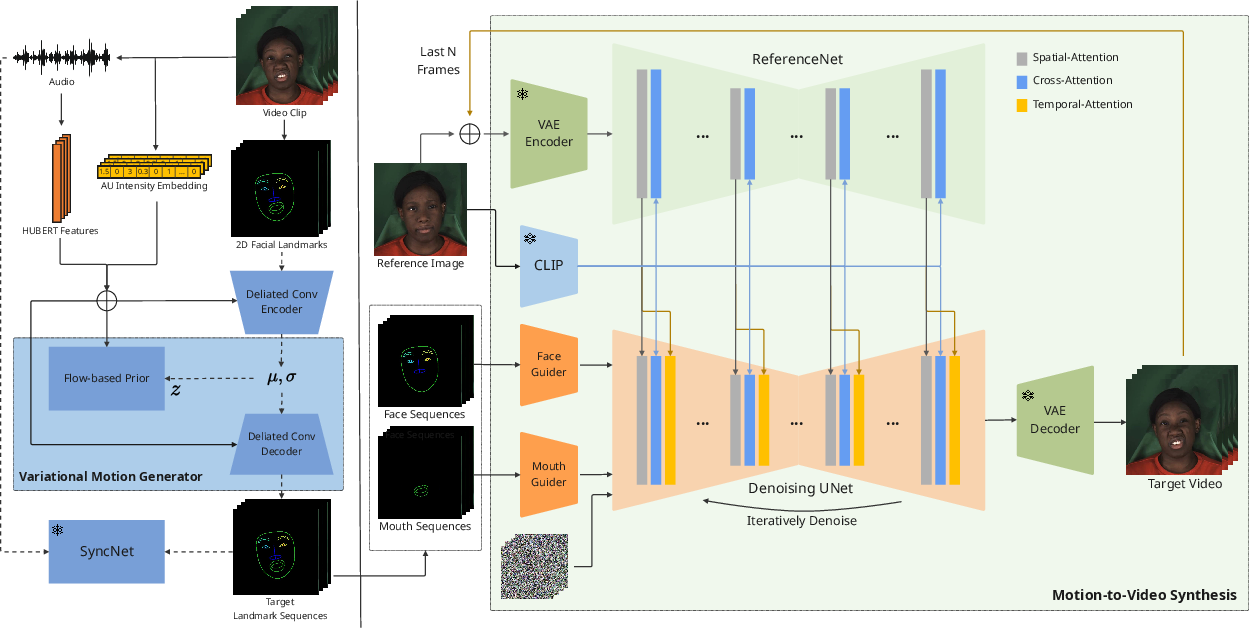
Figure 1: Overview of our model. Our method has two stages. In the first stage, our Variational Motion Generator extract audio features and the AU intensity embeddings...
Motion-to-Video Synthesis:
In the second stage, diffusion models transform these predicted landmarks into high-quality video. This involves a ReferenceNet to extract appearance features, a Pose Guider for lip-sync refinement, and a Temporal Alignment module to ensure video coherence. The diffusion model synthesizes videos conditioned on the landmarks ensuring both expression and audio-visual synchrony. Additional architectural details include temporal attention layers for smooth transitions (Figure 2).

Figure 2: Qualitative comparisons with state-of-the-art methods. Our method generates temporally consistent and visually realistic videos...
Experimental Results
Experiments performed on the MEAD dataset show that the proposed method achieves superior results, surpassing several state-of-the-art benchmarks in measures of perceptual quality and expression accuracy. Key metrics used include PSNR, SSIM, and FID for image quality and SyncNet confidence score for audio-visual synchronization. Additionally, AU-driven emotion accuracy demonstrates the model’s capability to reflect intended emotions with high fidelity (Table 1).
Implications and Future Work
This study introduces a robust approach to AU-guided facial animation that significantly enhances visual realism and expressive controllability. While performance metrics are indicative of substantial improvements, further exploration into user-level personalization remains an open issue. Future work may focus on style tokens for individual expression tendencies, robust AU detection under challenging conditions, and in-the-wild dataset training for enhanced real-world applicability.
Conclusion
The presented framework offers significant advancements in talking head video generation with its precise AU-based control mechanism. The capabilities of the AU-driven pipeline provide a promising direction for future innovations in expressive facial animation generation. The high fidelity of muscle activations achieved through landmark modeling highlights the importance of structural constraints in synthetic media (Figure 3).

Figure 3: Additional qualitative results using different source identities from the HDTF dataset.
Overall, the research validates the benefits of explicit AU-to-landmark modeling for generating lifelike expressions in synthetic videos.