- The paper presents meta-weight-ensembler, a novel framework that fuses task-specific knowledge to prevent catastrophic forgetting.
- It uses a mixing coefficient generator via meta-learning to adaptively integrate neural network layers during sequential learning.
- Experiments on Split CIFAR-10, CIFAR-100, and MiniImageNet show improved accuracy and effective backward transfer performance.
Adaptive Model Ensemble for Continual Learning
Continual learning is pivotal in advancing AI's ability to adapt and learn sequentially from tasks without compromising previously acquired knowledge — a process human cognition performs intuitively. The paper "Adaptive Model Ensemble for Continual Learning" (2509.19819) introduces an innovative framework to address the inherent challenges in this domain, specifically focusing on catastrophic forgetting and knowledge conflict in model ensembles.
Background and Challenges
Model ensemble methods have emerged as promising solutions to alleviate catastrophic forgetting in continual learning by interpolating parameters from various tasks. However, conventional ensemble approaches face knowledge conflict at both task and layer levels. Task-level conflict arises when disparate tasks contribute unique knowledge segments, and layer-level conflict originates from unequal knowledge significance across different neural network layers.
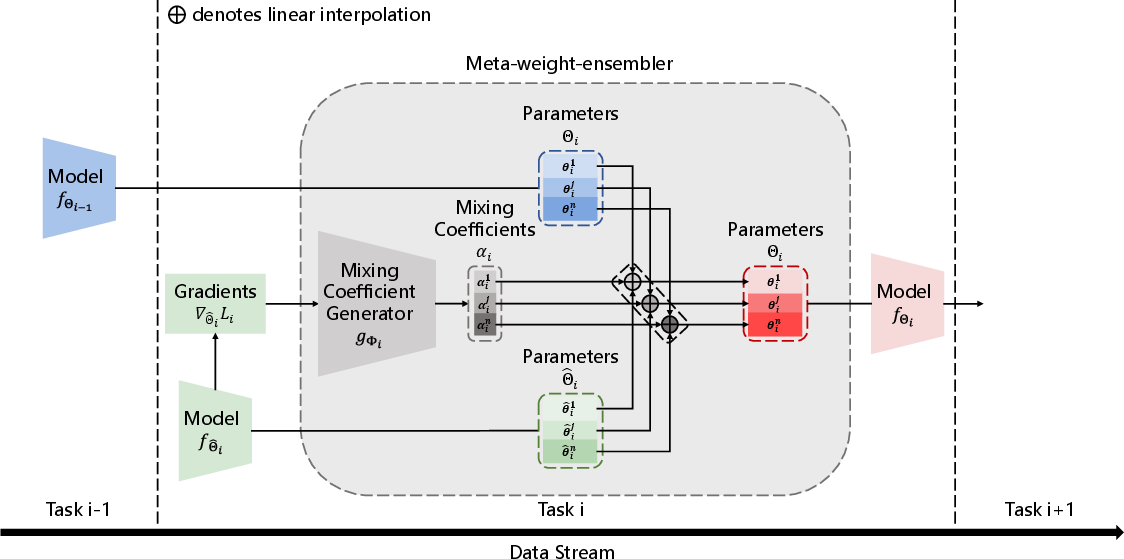
Figure 1: Formulation of Meta-weight-ensembler
Conventional solutions typically fail to adequately adapt and manage these conflicts, often leading to suboptimal model performance when handling new tasks alongside previously acquired ones.
The paper proposes "meta-weight-ensembler," an adaptive method that intelligently fuses task-specific knowledge across model layers. The method employs a mixing coefficient generator, trained through meta-learning, to optimize the parameter interpolation process strategically.
Significantly, meta-weight-ensembler generates mixing coefficients for each layer, solving both task-level and layer-level knowledge conflicts. This adaptive approach allows the model ensemble to preserve prior learned information while efficiently integrating new task-related knowledge.
Methodology
Layer-wise Model Ensemble
The meta-weight-ensembler facilitates model fusion through layer-wise interpolation. For each neural network layer, the method dynamically generates a mixing coefficient that dictates the proportionate contribution from models trained on previous tasks and models trained on the current task. This layer-specific integration ensures nuanced task knowledge retention and prevents catastrophic forgetting.
Mixing Coefficient Generation
A mixing coefficient generator employs a multilayer perceptron structure to produce layer-specific coefficients based on the gradient information from current tasks. This process captures task-specific optimization dynamics, which inform the layer adaptations required for seamless model parameter fusion.
(Figure 2)
Figure 2: Comparison between features extracted by different layers showcasing knowledge variance among layers.
The algorithm iteratively updates the mixing coefficients through a meta-learning framework, effectively accumulating prior knowledge and ensuring optimal parameter fusion strategies across diverse tasks.
Experimental Results
The paper reports extensive experimentation on Split CIFAR-10, Split CIFAR-100, and Split MiniImageNet datasets. The meta-weight-ensembler consistently demonstrated superior performance by significantly improving both Average Accuracy (ACC) and Backward Transfer (BWT) metrics across various continual learning settings, including task-incremental learning (TIL), class-incremental learning (CIL), and online class-incremental learning (OCIL).
In ablation studies, the nuanced benefit of layer-wise ensemble methods was underscored when compared with models treating layers uniformly. Visualization analyses further validated the adaptive ensemble’s capacity to retain historical knowledge while effectively incorporating new information.
(Figure 3)
Figure 3: Comparison of classification capacity across models indicating effective knowledge fusion.
Conclusion
The meta-weight-ensembler presents a nuanced advancement in continual learning methodologies by addressing core challenges in model ensemble dynamics. By employing a meta-learning framework to intelligently generate layer-wise mixing coefficients, the approach ensures efficient and adaptive integration of task-specific knowledge. This advancement significantly mitigates catastrophic forgetting and enhances model performance across varied continual learning contexts.
Continual learning is a burgeoning field, and methods like meta-weight-ensembler offer promising directions for further research expansions, particularly in exploring automated strategies for layer-specific knowledge assimilation and enhancing robustness in dynamic AI environments.