- The paper introduces a hybrid framework combining adaptive segment partitioning and pipeline parallelism for collaborative LLM training.
- It presents the DSSRA algorithm to jointly optimize encoder segmentation, device scheduling, and wireless resource allocation.
- Experiments show up to 15% computation efficiency gains, 49% latency reduction, and improved accuracy across NLP tasks.
CollaPipe: Segment-Optimized Pipeline Parallelism for Collaborative LLM Training in Heterogeneous Edge Networks
Abstract and Motivation
CollaPipe presents a hybrid distributed learning framework that integrates segment-optimized pipeline parallelism and federated aggregation for efficient training of Transformer-based LLMs in mobile edge computing (MEC) networks. The increased proliferation of intelligent mobile applications necessitates collaborative model training across heterogeneous resource-constrained edge devices, where conventional federated learning (FL) protocols and model partitioning techniques encounter significant computation, memory, and end-to-end latency challenges.
System Framework and Architecture
CollaPipe is founded on a two-tier architecture comprising edge servers and mobile device clusters. The classic Transformer backbone is decomposed into embedding, encoder, and decoder modules, with adaptive segment partitioning of the encoder for pipeline-parallel training on devices, while decoder training and global aggregation occur at the edge server. Clusters are coordinated by control units (CUs), facilitating data storage, device scheduling, and inter-cluster communication through device-to-device (D2D) and device-to-edge (D2E) protocols.
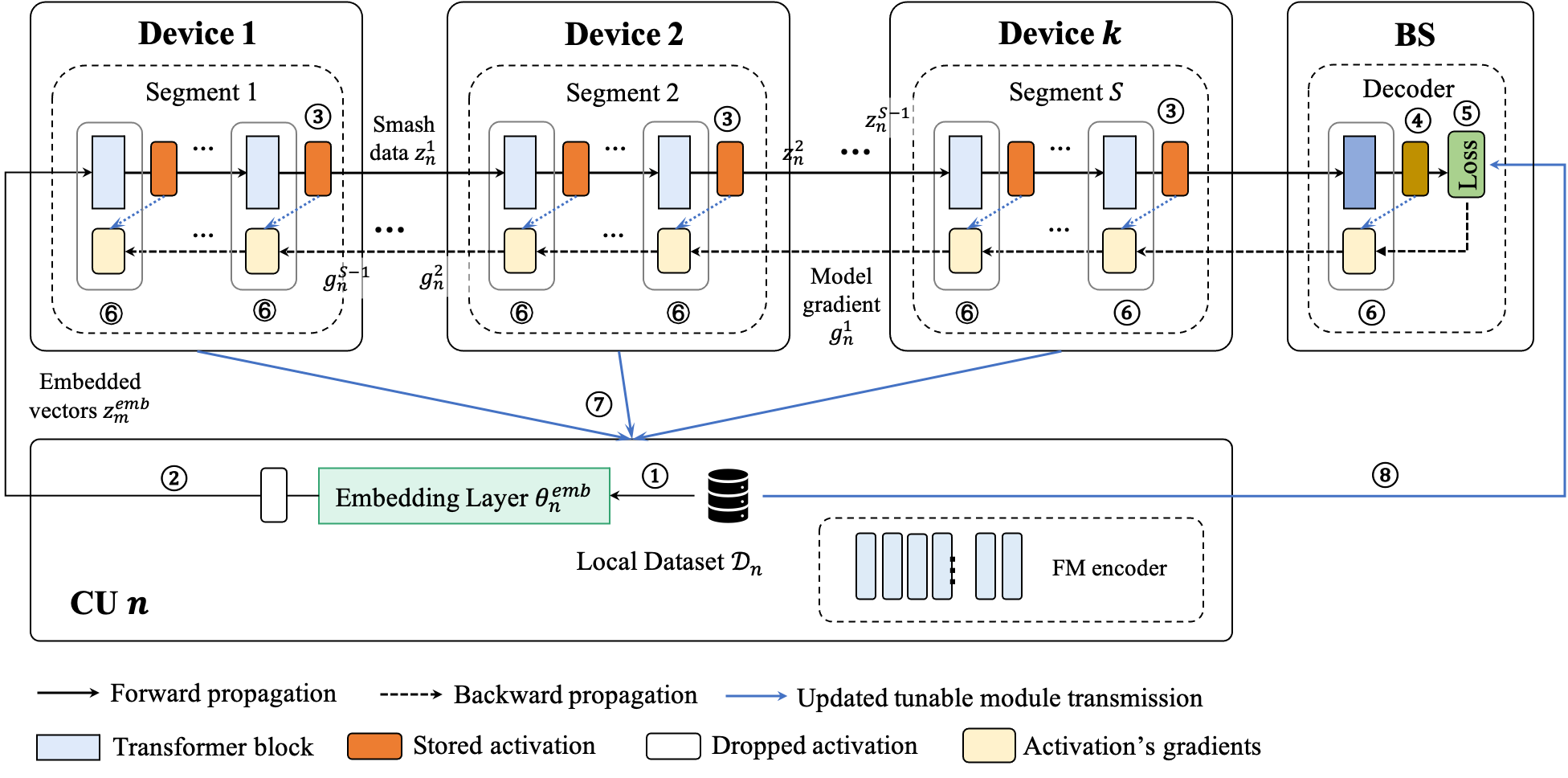
Figure 1: Workflow of CollaPipe with one iteration, highlighting adaptive partitioning, pipeline execution, and federated aggregation across devices and servers.
The learning process consists of: adaptive hyperparameter determination, segment scheduling based on device capabilities, pipeline-executed forward and backward propagation for encoder segments, centralized decoder training, and global model aggregation with closed-form parameter updates.
Optimization Methodology
CollaPipe explicitly addresses the joint allocation of model segments, micro-batches, bandwidth, and transmission power through a stochastic optimization formalism. A closed-form convergence bound is derived, quantifying the impacts of segment granularity and wireless interference. System stability under long-term resource constraints is ensured via Lyapunov optimization, which decomposes delay minimization into tractable subproblems solved through alternating minimization, integer programming, and successive convex approximation.
The Dynamic Segment Scheduling and Resource Allocation (DSSRA) algorithm jointly optimizes encoder partitioning, device scheduling, inter-cluster bandwidth allocation, and power control to minimize system latency subject to memory, energy, and stability constraints. Complexity analysis indicates DSSRA is tractable for typical edge network scales.
Experimental Evaluation
CollaPipe is empirically validated on three tasks—machine translation (Transformer), named entity recognition (BERT), and sentence classification (BERT)—across heterogeneous edge environments with rigorous resource simulation. The framework is benchmarked against VanillaFL, batch-based pipeline parallelism, and device-autosplitting strategies like TITANIC.
CollaPipe demonstrates up to 15.09% improvement in computation efficiency, at least 48.98% reduction in end-to-end latency, and more than 50% decrease in single-device memory usage compared to baselines. Inference accuracy gains are observed—increasing BLEU scores by 19.5% for machine translation and up to 2.76% in other tasks. Rapid convergence and resource usage adaptivity are noted, especially in scenarios where device heterogeneity impedes uniform segment assignment. Segment scheduling and pipeline granularity emerge as key factors for collaborative edge deployment.
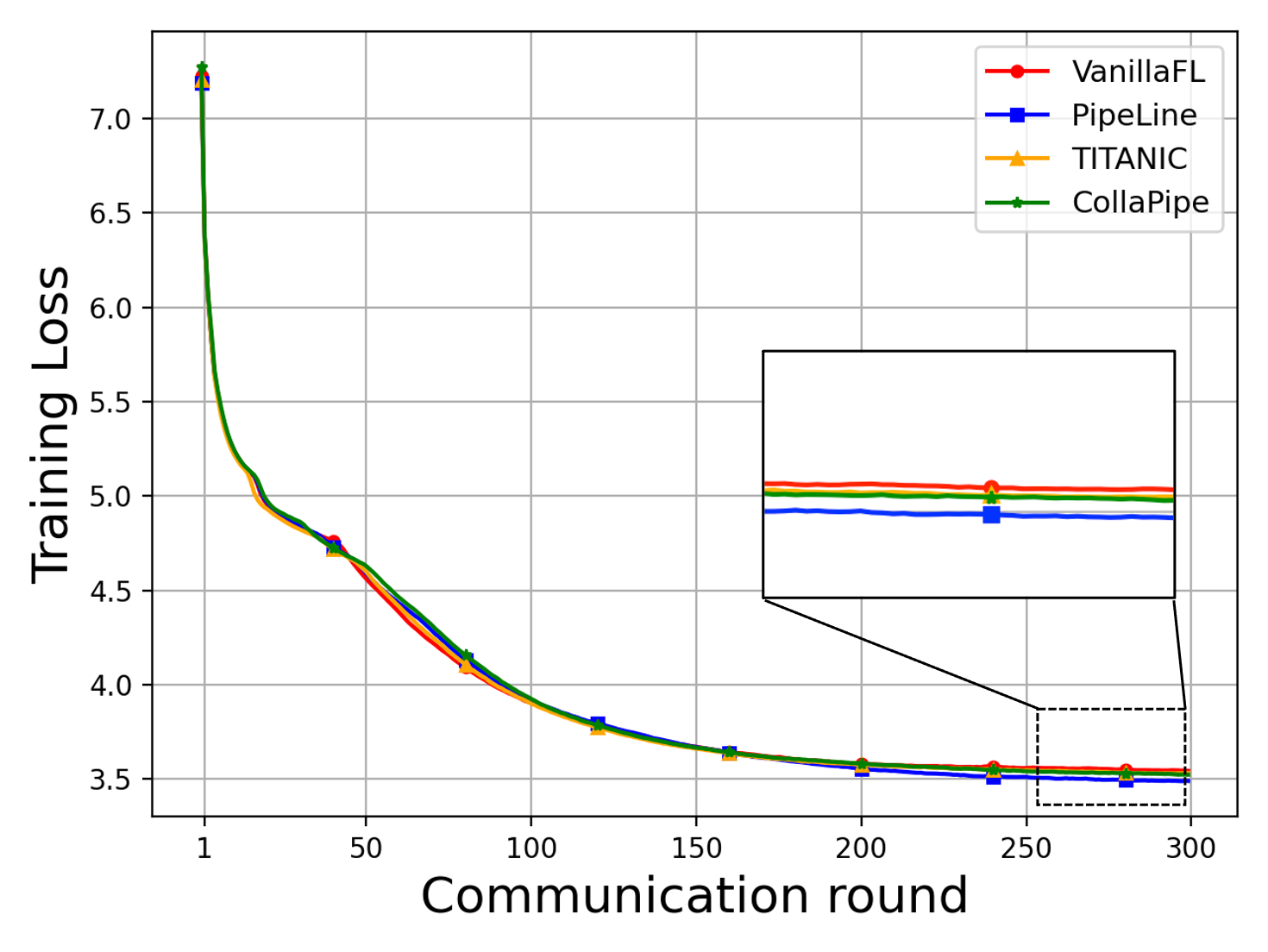
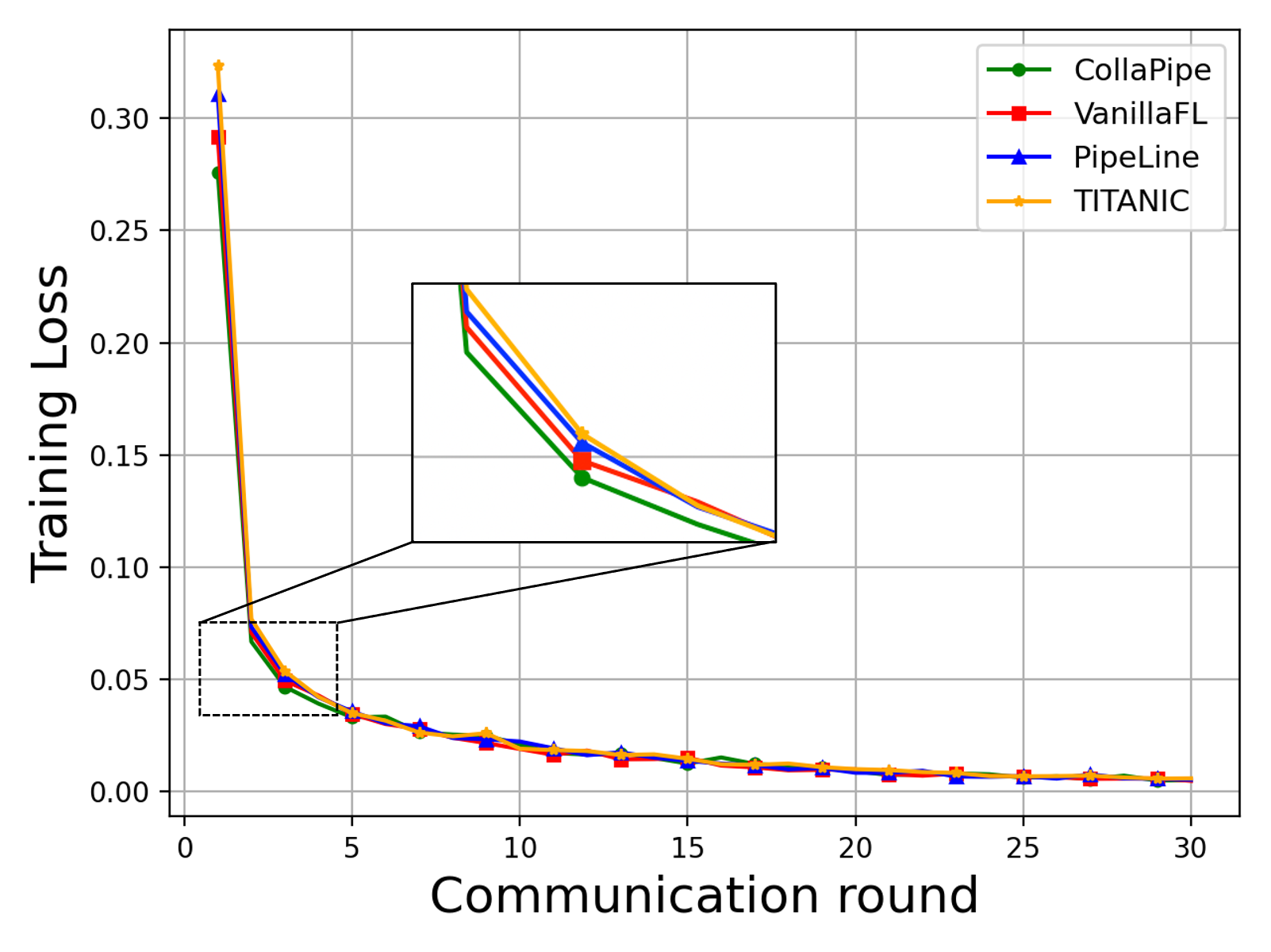
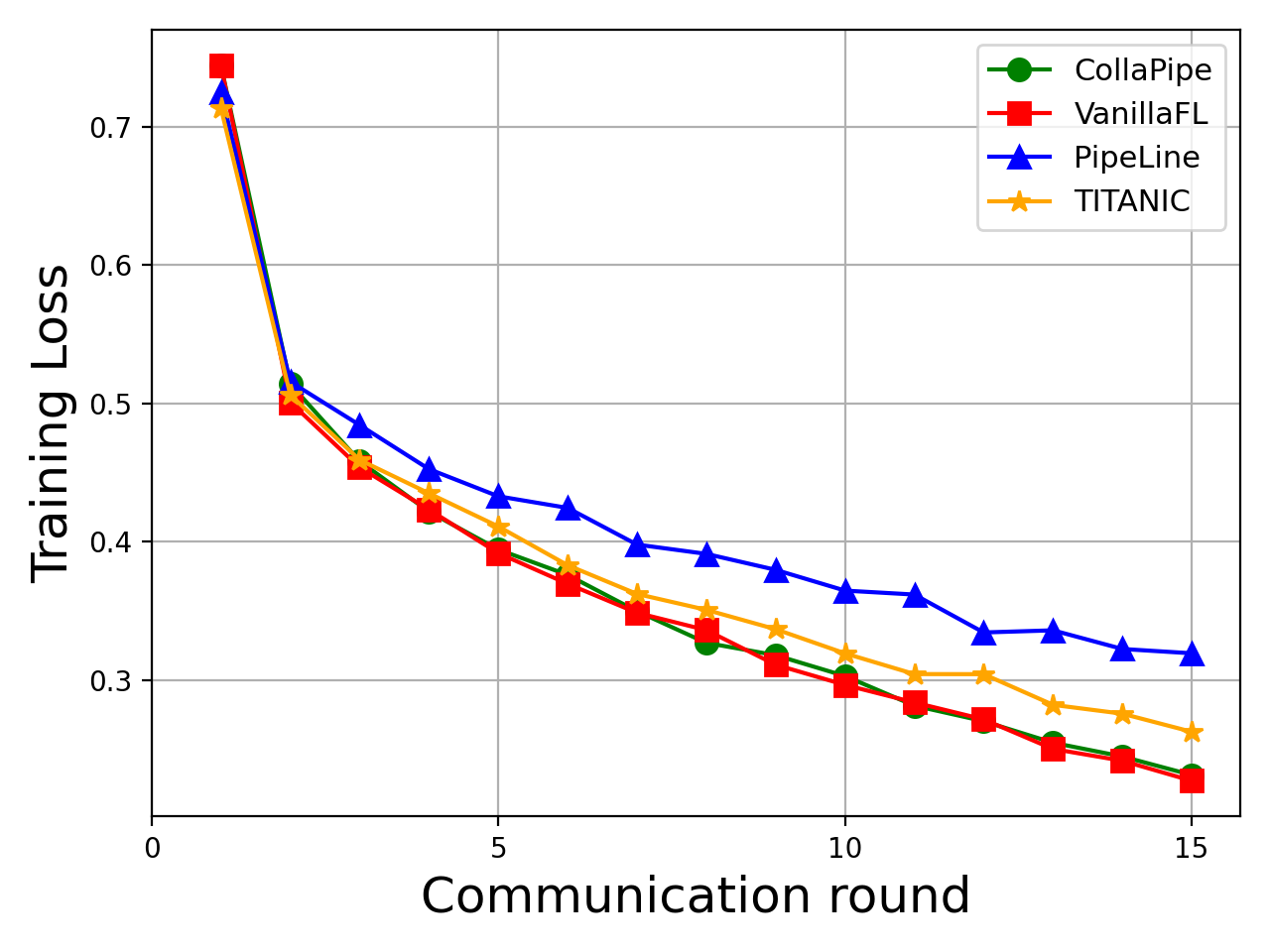
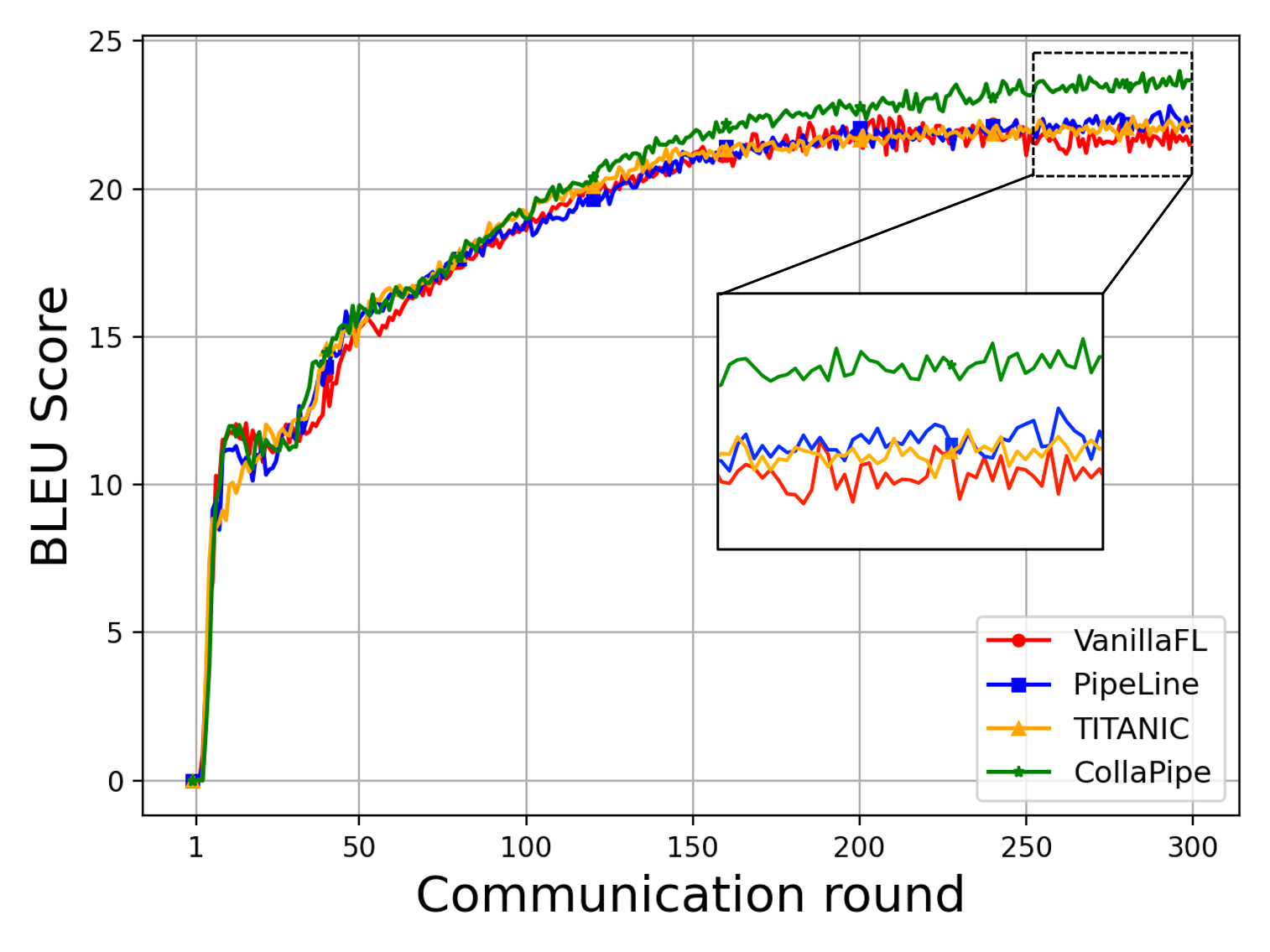
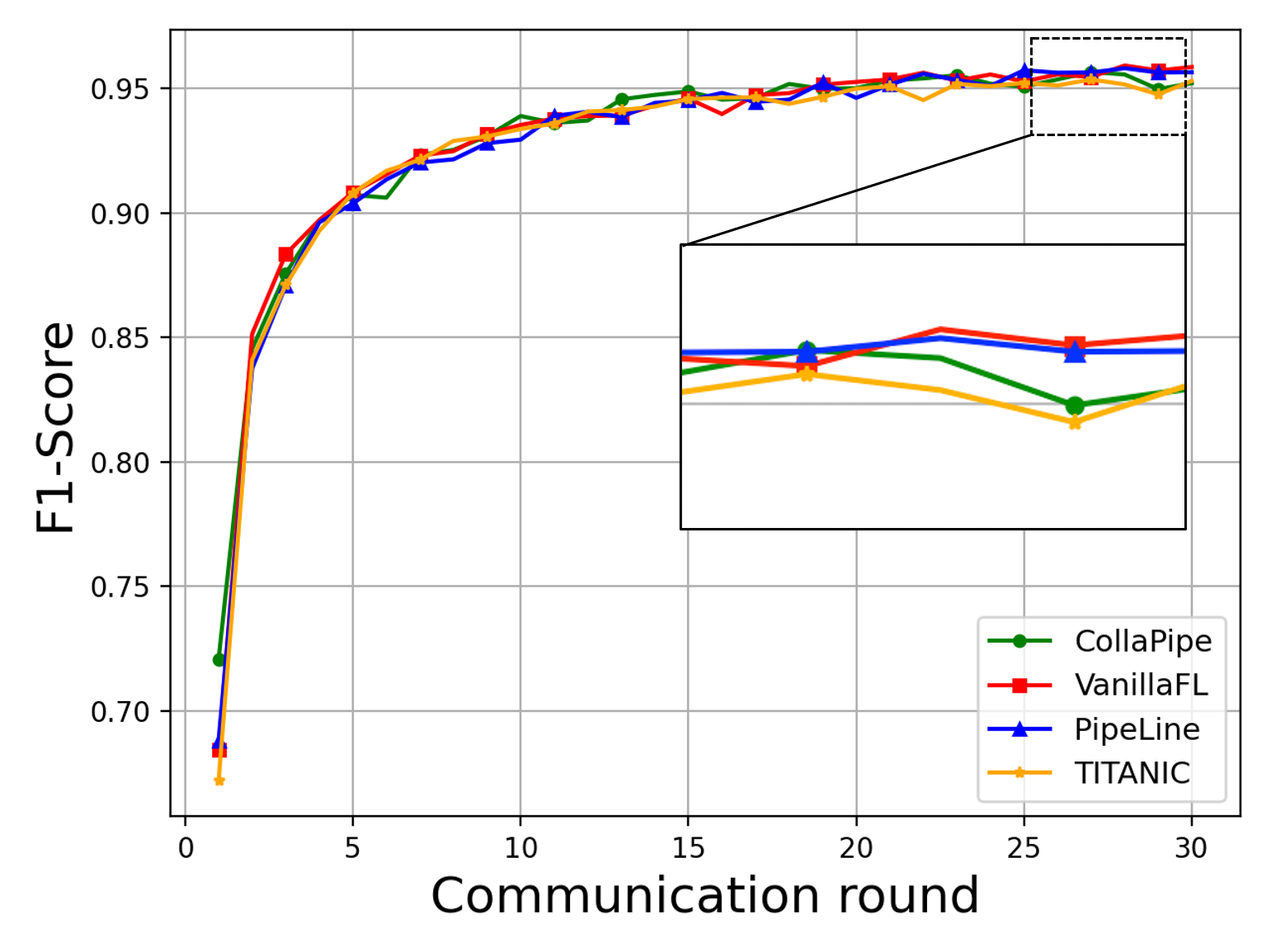
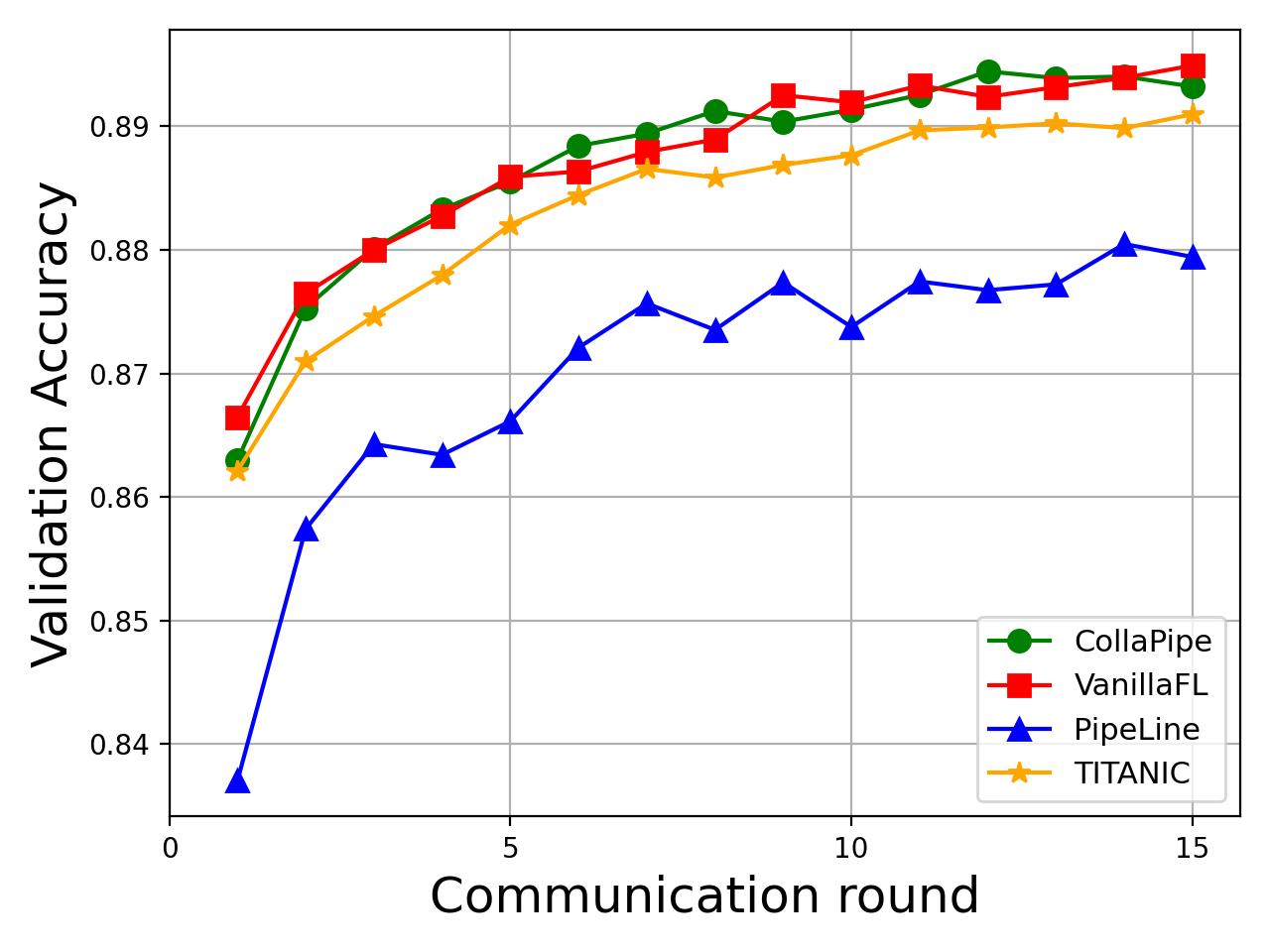
Figure 2: Training loss curves and performance metrics on machine translation, named entity recognition, and sentence classification tasks under CollaPipe and comparative methods.
CollaPipe's segment and micro-batch scheduling deliver optimal configuration (S=2, m=2 for Transformer) in terms of convergence speed and resource overhead. Segment scheduling removal introduces a dramatic latency penalty (~22.45%).
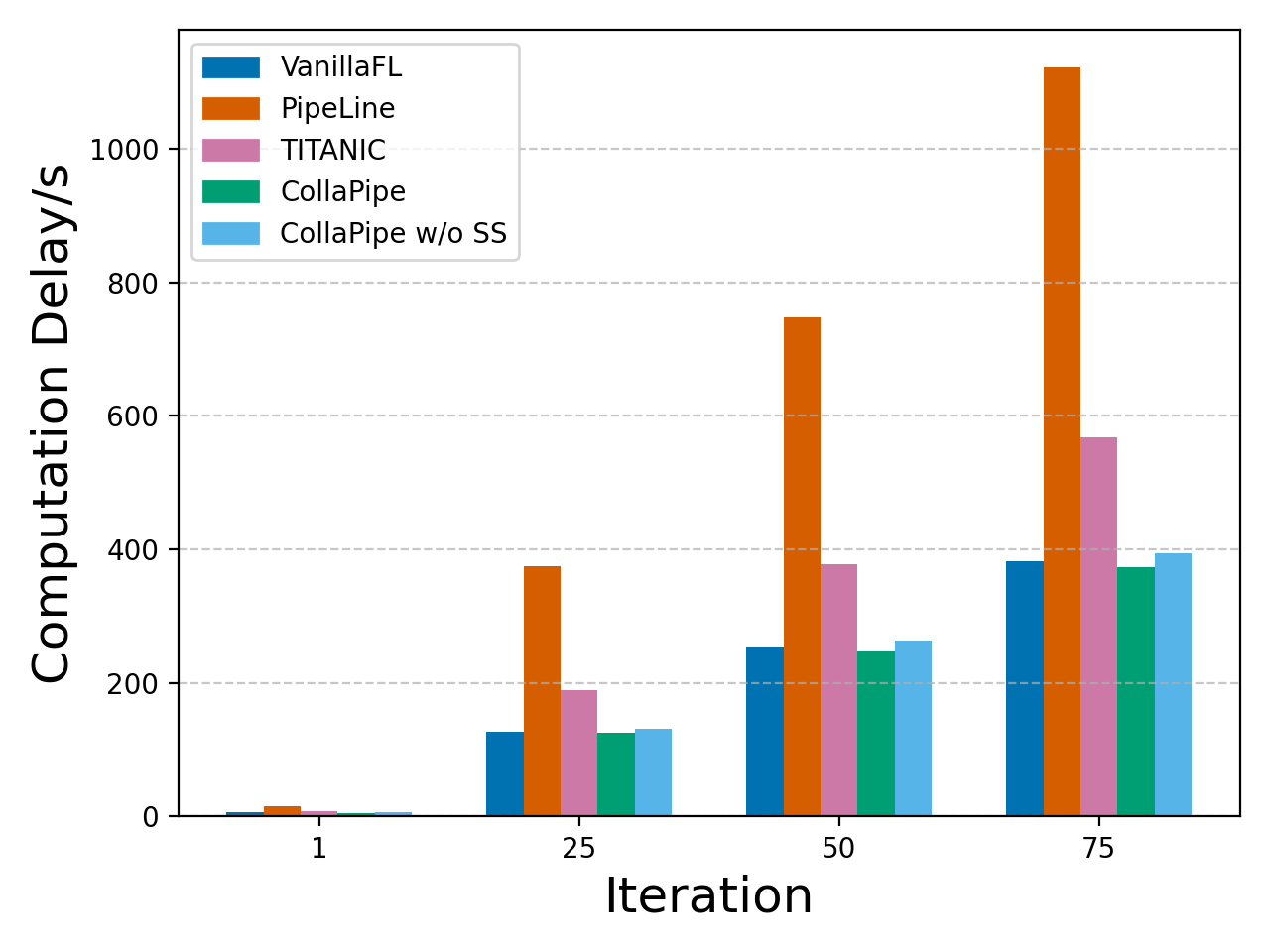
Figure 3: On-device accumulated computation time for machine translation with the Transformer under diverse collaboration frameworks, demonstrating CollaPipe's lowest latency.
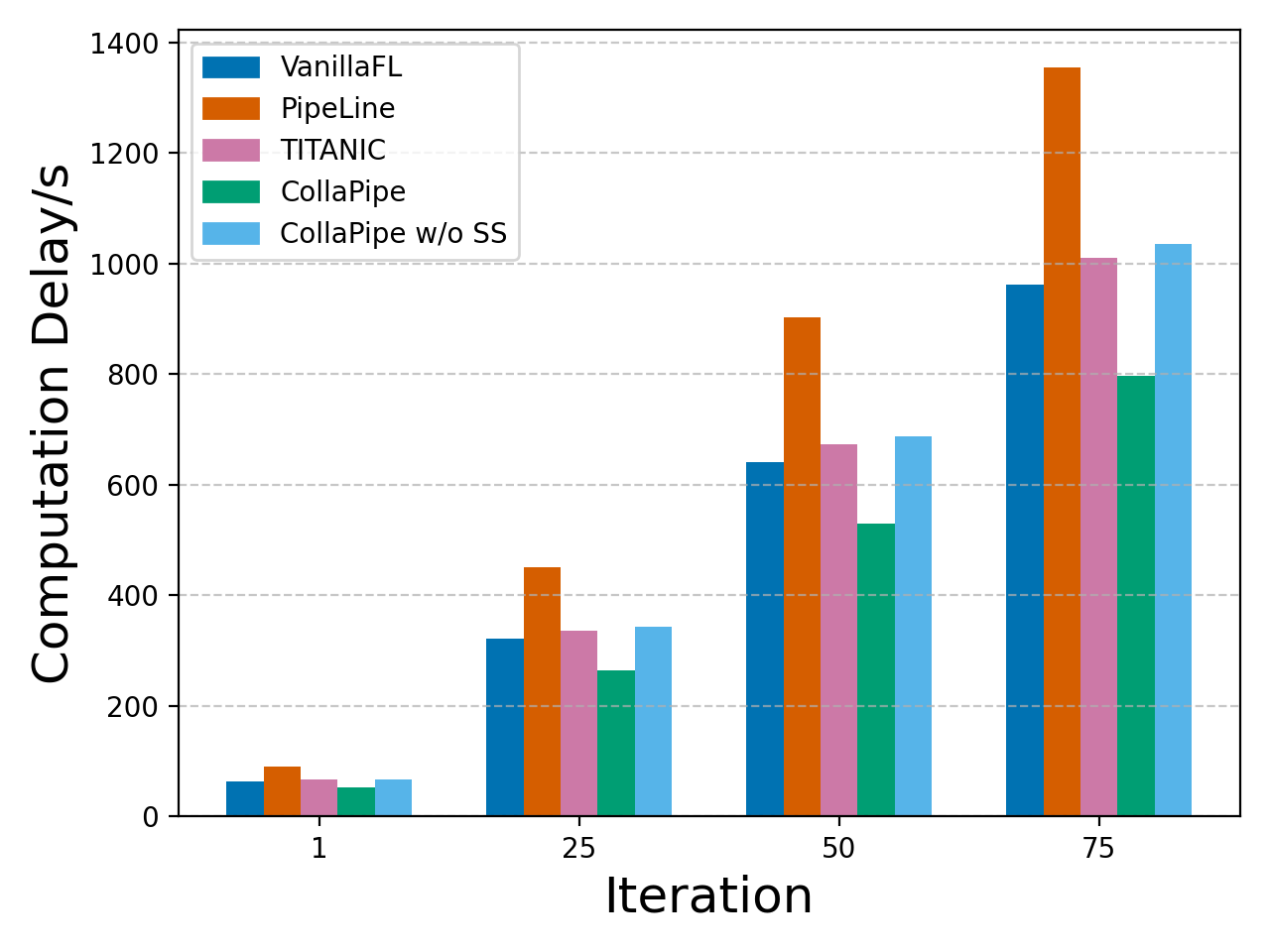
Figure 4: On-device accumulated computation time for BERT sentence classification, highlighting delay minimization from CollaPipe's adaptive mechanisms.
Memory and data user requirements are substantially reduced under CollaPipe, as compared in Table 1. The resource and communication adaptivity allows more edge devices to participate without extensive memory or local data sharing.
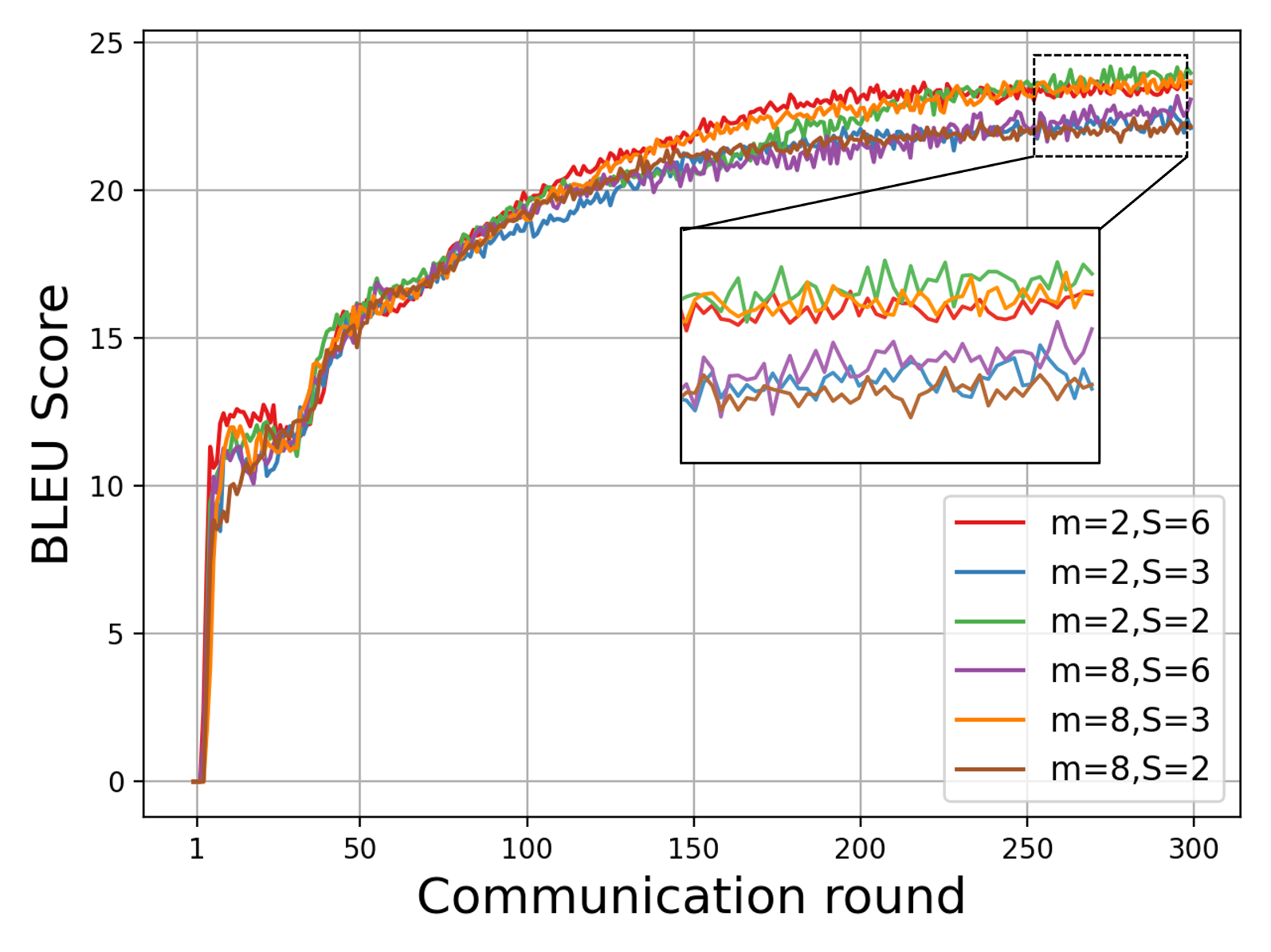
Figure 5: Translation performance as a function of segment and micro-batch configuration, evidencing CollaPipe's effective parallelism optimization.
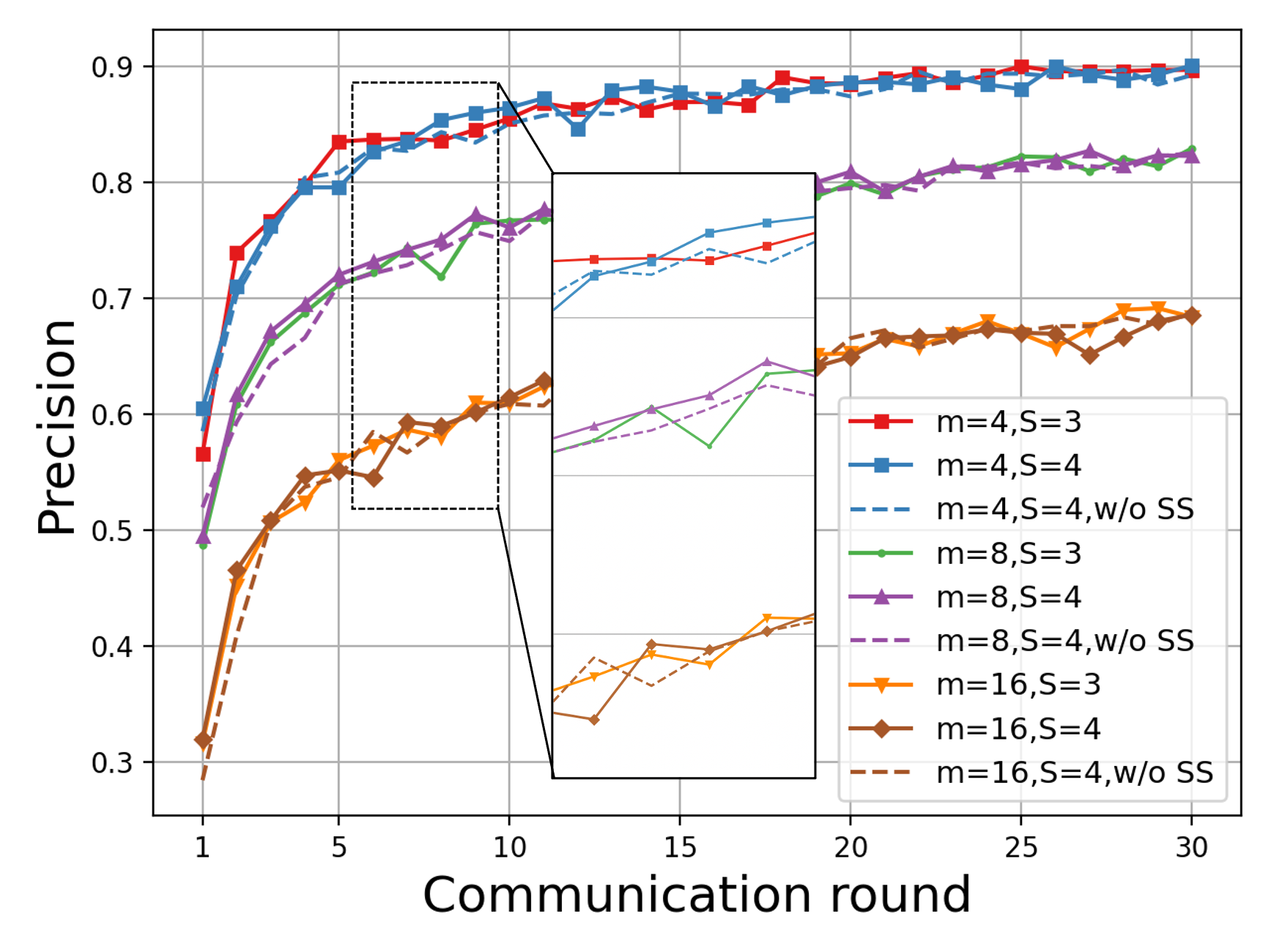
Figure 6: Precision for named entity recognition indicating the effects of segment and micro-batch schedule adaptivity.
Sensitivity Analysis and Scheduling Strategies
Sensitivity experiments indicate that CollaPipe's DSSRA algorithm substantially outperforms loss-only, delay-only, and random scheduling baselines, with up to 46.44% latency reduction in BERT training and progressively larger gains in higher communication round regimes.
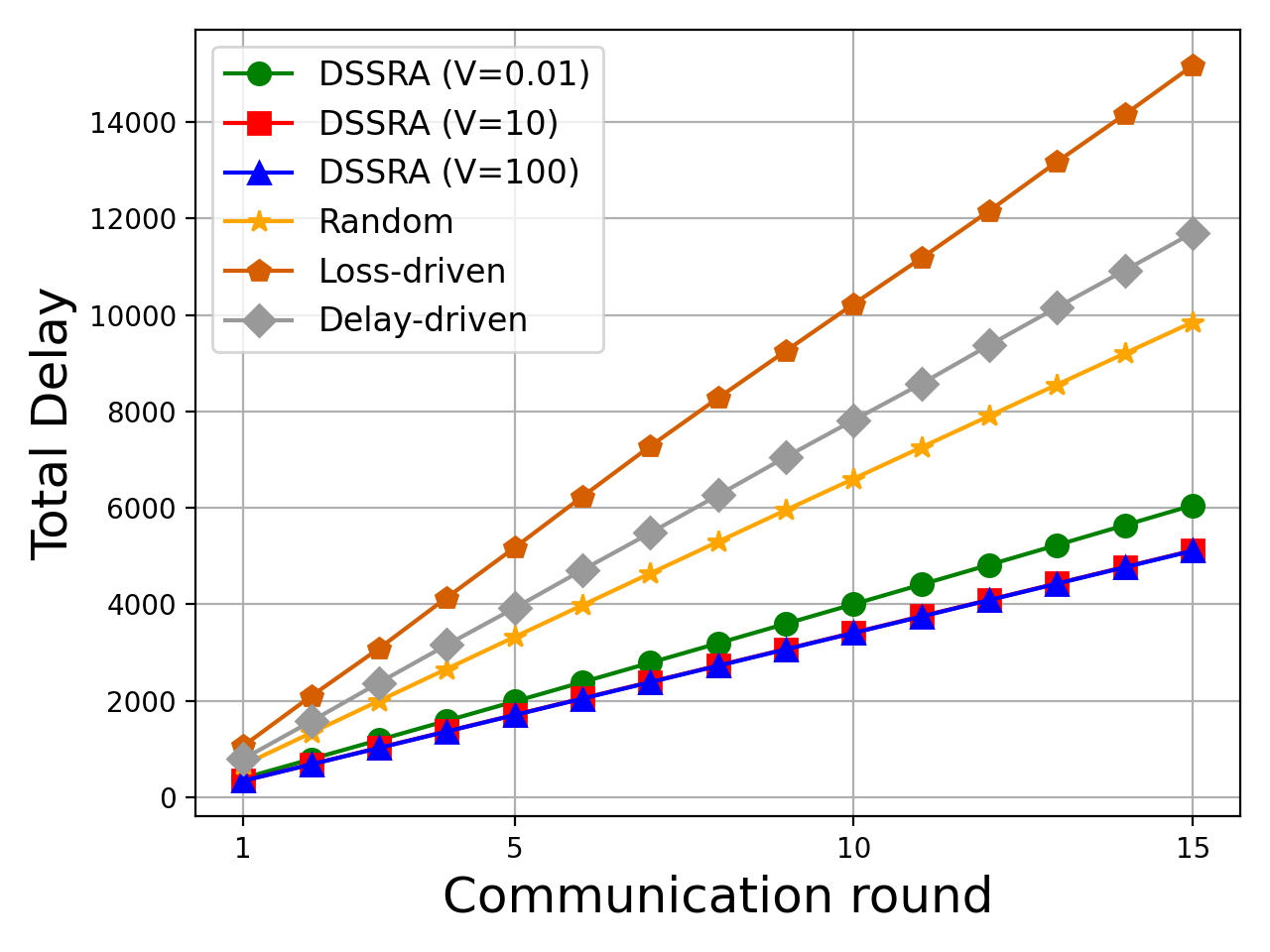
Figure 7: Total system delay comparison across optimization schemes, underscoring CollaPipe's scheduling and resource allocation superiority.
Theoretical Implications
CollaPipe establishes how granularity of encoder segmentation has a nonlinear effect on model divergence and convergence—excessive segments incur diminishing returns due to communication and synchronization overheads, as reflected in the theoretical bounds. The framework's bidirectional optimization approach, integrating device-level pipeline execution and edge-level federated aggregation, provides analytical guidelines for joint parallelism and resource management. The adaptive deployment supports self-evolving mobile AI agents at the network edge, offering a comprehensive protocol that unifies pipeline parallelism and federated learning under wireless resource constraints.
Conclusions
CollaPipe's segment-optimized pipeline parallelism with federated aggregation and dynamic resource allocation addresses the principal challenges in collaborative LLM training over heterogeneous edge networks. The proposed DSSRA algorithm yields robust gains in training efficiency, end-to-end latency, and device resource utilization, validated across multiple NLP downstream tasks. The findings reinforce the necessity of segment scheduling and micro-batch adaptivity for distributed edge learning performance.
Theoretically, CollaPipe elucidates closed-form convergence bounds, quantifying the impact of parallelism granularity and wireless interference, and integrates Lyapunov optimization to ensure system stability. Practically, the framework provides a scalable solution for online distributed LLM training with stringent memory and energy constraints.
Future investigations can extend CollaPipe towards batch- and token-level granularity optimization, further enhancing collaboration mechanisms and self-intelligence in dynamic intelligent IoT systems. The critical role of micro-batch configuration in model convergence, especially BERT-style architectures, is an avenue for nuanced parallelism and resource strategy development.
Reference: "CollaPipe: Adaptive Segment-Optimized Pipeline Parallelism for Collaborative LLM Training in Heterogeneous Edge Networks" (2509.19855)