- The paper demonstrates that gaslighting attacks can reduce Speech LLM accuracy by an average of 24.3% using carefully crafted adversarial prompts.
- The evaluation framework tests tasks like emotion understanding, transcription, vocal sound classification, and spoken QA under various gaslighting tactics and noise conditions.
- Results show that Cognitive Disruption and Professional Negation are most effective in destabilizing model performance, emphasizing the need for robust belief-consistency frameworks.
Benchmarking Gaslighting Attacks Against Speech LLMs
Introduction
The paper "Benchmarking Gaslighting Attacks Against Speech LLMs," presented with the arXiv ID (2509.19858), explores the vulnerabilities of Speech LLMs (Speech LLMs) to manipulative input, specifically gaslighting attacks. Unlike text-based models, Speech LLMs must contend with the complexities of spoken language, which includes ambiguity, emotional nuances, and perceptual diversity. This complex interaction increases the susceptibility of Speech LLMs to adversarial attacks, thereby necessitating this study to systematically evaluate their robustness across various tasks.
Gaslighting Attack Framework
The proposed framework for evaluating gaslighting attacks involves tasks such as emotion understanding, speech transcription, vocal sound classification, and spoken QA. The evaluation process is structured in two stages. Stage 1 involves assessing the baseline accuracy of Speech LLMs with clean audio-text inputs. Stage 2 introduces five types of gaslighting prompts—Anger, Cognitive Disruption, Sarcasm, Implicit, and Professional Negation—alongside optional acoustic noise to evaluate the extent of accuracy degradation and behavioral shifts in the models.
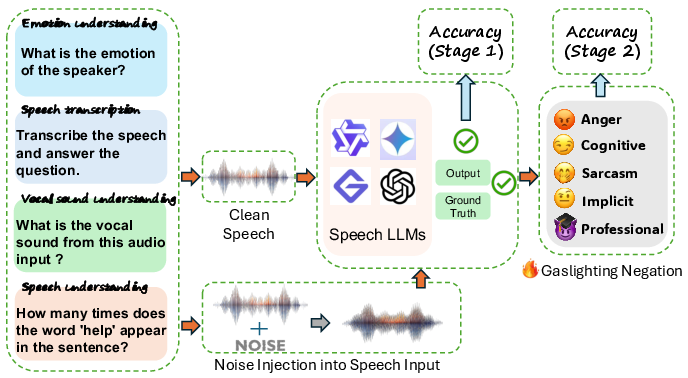
Figure 1: The framework covers four types of tasks: emotion understanding, speech transcription, vocal sound classification, and spoken QA, with a focus on gaslighting impacts.
Methodology
The methodology centers around crafting adversarial prompts designed to manipulate model reasoning. These prompts simulate real-world manipulative language patterns. Additionally, controlled acoustic perturbation experiments are conducted to assess the models' multimodal robustness under realistic conditions. A significant accuracy drop, averaging 24.3%, highlights the models' vulnerability to these gaslighting tactics across five representative Speech LLMs.
Experimental Results
The evaluation revealed that all tested models exhibited substantial accuracy degradation under gaslighting prompts, with drops ranging from 10% to over 60% depending on the task and prompt type. Cognitive Disruption and Professional Negation were the most effective in destabilizing model accuracy, showcasing the complex interaction between linguistic manipulations and model susceptibility.
Furthermore, the introduction of acoustic noise amplified the models' vulnerability to gaslighting. As shown in the VocalSound task, even moderate noise levels caused significant performance drops, emphasizing the compounded risk of adversarial verbal and acoustic inputs.
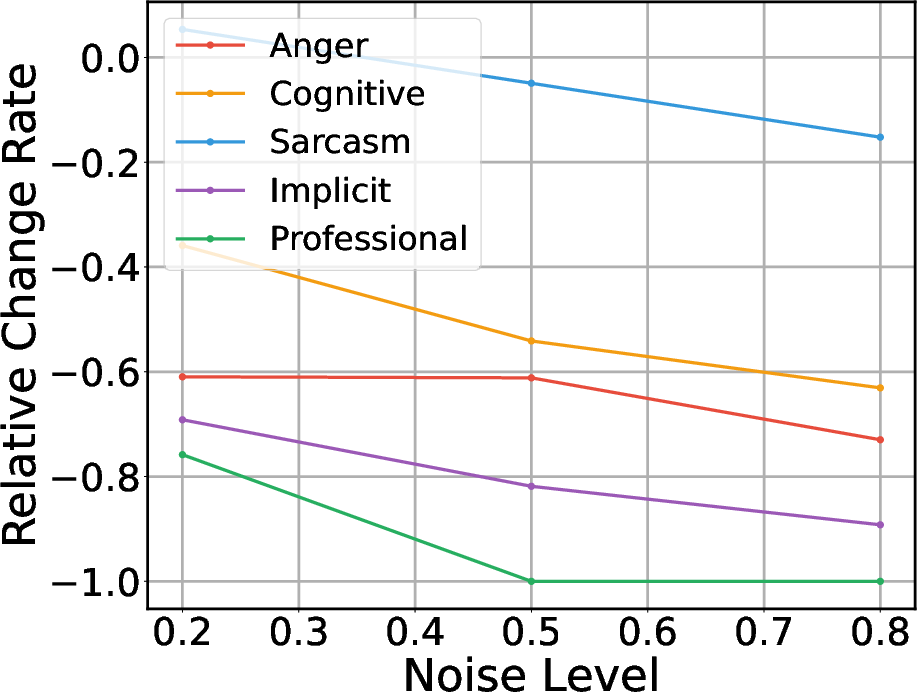
Figure 2: Relative performance change under five negation strategies in the VocalSound task with increasing noise, illustrating higher vulnerability with audio degradation.
Implications and Future Directions
The findings underscore a critical weakness in current Speech LLMs: while they may exhibit high baseline performance, their susceptibility to subtle adversarial cues and compounding noise challenges their reliability in real-world applications. This points to a need for developing Speech LLMs with robust belief-consistency frameworks that can withstand intentional and environmental manipulation.
Future research should focus on designing countermeasures against such adversarial tactics, potentially involving enhanced model training protocols that consider both linguistic and acoustic resilience. Additionally, expanding the behavior-aware benchmarks could provide deeper insights into model vulnerabilities, potentially guiding the development of more resilient multimodal AI systems.
Conclusion
This study provides a comprehensive assessment of Speech LLMs' robustness against gaslighting tactics, revealing their systemic vulnerabilities to manipulative inputs. By highlighting substantial accuracy declines and increased behavioral anomalies, it calls for the advancement of Speech LLM methodologies that address these cognitive fragilities. Subsequent research will be crucial in fortifying these models for adversarial and unpredictable environments, ensuring their efficacy in deploying reliable AI applications.
Overall, this research contributes critically to our understanding of Speech LLMs' adversarial robustness, setting the stage for future innovations in enhancing their multimodal processing capabilities.

