Investigating Security Implications of Automatically Generated Code on the Software Supply Chain
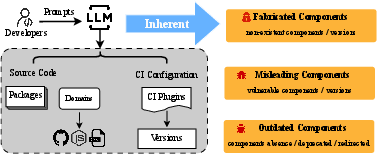
Abstract: In recent years, various software supply chain (SSC) attacks have posed significant risks to the global community. Severe consequences may arise if developers integrate insecure code snippets that are vulnerable to SSC attacks into their products. Particularly, code generation techniques, such as LLMs, have been widely utilized in the developer community. However, LLMs are known to suffer from inherent issues when generating code, including fabrication, misinformation, and reliance on outdated training data, all of which can result in serious software supply chain threats. In this paper, we investigate the security threats to the SSC that arise from these inherent issues. We examine three categories of threats, including eleven potential SSC-related threats, related to external components in source code, and continuous integration configuration files. We find some threats in LLM-generated code could enable attackers to hijack software and workflows, while some others might cause potential hidden threats that compromise the security of the software over time. To understand these security impacts and severity, we design a tool, SSCGuard, to generate 439,138 prompts based on SSC-related questions collected online, and analyze the responses of four popular LLMs from GPT and Llama. Our results show that all identified SSC-related threats persistently exist. To mitigate these risks, we propose a novel prompt-based defense mechanism, namely Chain-of-Confirmation, to reduce fabrication, and a middleware-based defense that informs users of various SSC threats.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at what can go wrong when programmers use AI tools (like ChatGPT or Llama) to write code. Modern software is built from many outside parts made by other people—think of it like building with lots of LEGO pieces from different boxes. If the AI suggests a bad or fake piece, or an old, risky one, attackers can sneak in. The authors study how often this happens and how dangerous it can be, then suggest ways to reduce the risk.
What questions did the researchers ask?
The paper focuses on simple but important questions:
- Do AI code generators make up outside parts that don’t exist (like fake packages or websites)?
- Do they point to parts that are known to be unsafe or have security bugs?
- Do they suggest old or abandoned parts that can break projects or be hijacked later?
- How often do these problems appear in code and in build files (the instructions that run automatic tests and builds)?
- Can we reduce these problems with better prompts or tools?
How did they study it?
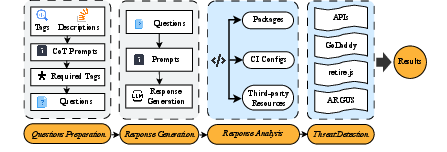
The researchers built a tool called SSCGuard and ran a large test:
- They collected many real programming questions from Stack Overflow (a popular Q&A site for coders).
- They turned these into about 439,000 prompts (questions) and asked four popular AI models (two from OpenAI’s GPT series and two from Meta’s Llama family) to generate code and build instructions.
- They checked the AI’s answers for risky references to outside parts.
Key terms explained in everyday language:
- Software supply chain: All the outside parts (packages, libraries, services) and steps (like automated building and testing) used to create software.
- Packages/libraries: Reusable code someone else wrote, like a ready-made LEGO piece you can plug in.
- CI (Continuous Integration): An automated “assembly line” that builds and tests your code whenever you make changes. It uses “workflows” (step-by-step instructions) and “plugins” (reusable tools) to do common tasks.
- Hallucination (in AI): When the AI makes something up that sounds real but isn’t—like inventing a package name or a version that doesn’t exist.
- Versioning: Labels like v1.2.3 that say which release of a tool you’re using. Using the wrong or risky version can be dangerous.
- CDNs: Services that host files (like JavaScript libraries) on fast servers around the world so websites can load them quickly.
What did they find?
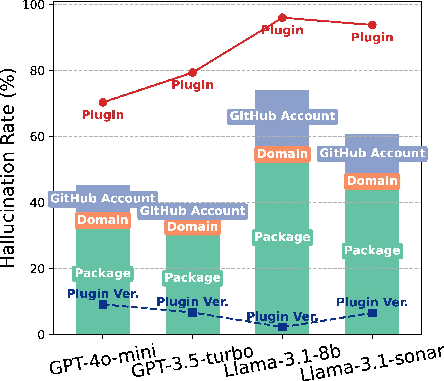
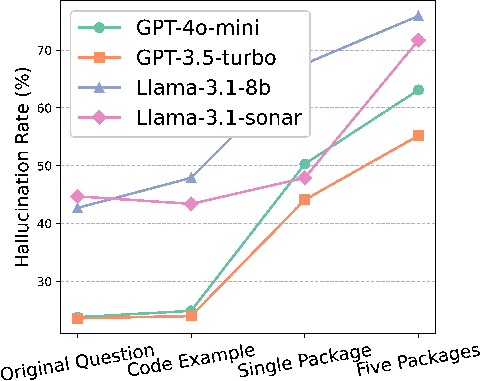
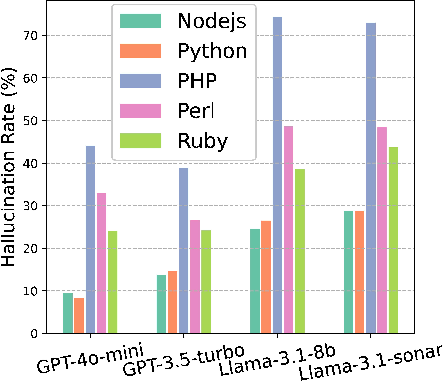
The problems were common across all four AI models they tested. The risks showed up both in code and in CI build files. They also got worse when the prompt asked the AI to recommend external parts.
Here are examples of risks they saw:
- Fake parts (hallucinations)
- Fake packages: The AI suggests a package name that doesn’t exist. Attackers can quickly create a package with that name and sneak in malicious code.
- Fake domains: The AI gives a URL under a domain (website) that doesn’t exist. Attackers can buy that domain and host harmful files.
- Fake GitHub accounts: The AI references a GitHub account that isn’t real. Attackers can register it and publish malicious code there.
- Fake CI plugins or versions: The AI suggests a CI plugin (a build tool) or a version that doesn’t exist. Attackers can create that version or repo and take over the build process.
- Risky versions and configurations
- Vulnerable versions: The AI recommends real parts, but specific versions known to have security bugs (for example, old JavaScript libraries with known flaws).
- CI workflow bugs: The AI generates build scripts that can allow “code injection” (attackers slipping commands into the build via untrusted input).
- Version reuse in CI plugins: Some CI plugin versions can be replaced without changing the version label (like swapping the contents of a box but keeping the same sticker), which can trick users.
- Outdated or abandoned parts
- Removed or missing resources: The AI points to files that no longer exist, breaking features and causing hidden issues.
- Deprecated packages: The AI suggests packages that are no longer maintained, making future fixes and security patches unlikely.
- Redirection hijacking: If a GitHub account was renamed, the old address may auto-forward to the new one—until someone re-registers the old name and hijacks traffic.
Why is this important?
- Developers may trust AI-generated code or build files and paste them into real projects.
- Attackers can watch for these AI-suggested fake names and quickly claim them, slipping malware into many projects at once.
- Even when parts are real, recommending known-vulnerable or outdated versions can put users at risk.
What can we do about it?
The authors propose two defenses:
- Chain-of-Confirmation (prompt-based): Ask the AI not just to suggest parts, but first to verify they exist and are safe, then regenerate the code. In tests, this cut package hallucinations about in half while still returning useful suggestions.
- Middleware checker (SSCGuard): A tool that sits between the AI and the developer. It scans AI-generated code and build files, flags fake, vulnerable, or outdated parts, and warns the user before they copy anything into their project.
Takeaway
AI can speed up coding, but it can also confidently suggest fake, unsafe, or outdated pieces—especially when asked to recommend external components. These mistakes create real openings for attackers to hijack software and build systems. With smarter prompts and automated checking tools, we can keep the convenience of AI while lowering the risk.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and open directions that remain unresolved and could guide follow-on research:
- Real-world exploitability validation: No end-to-end demonstrations that hallucinated packages, domains, GitHub accounts, or CI plugins suggested by LLMs were actually registered/replicated by adversaries and led to successful compromise of downstream users.
- Severity and impact quantification: The study does not estimate the downstream risk (e.g., likelihood that developers copy and ship the suggestions, expected affected user count, install/download volumes, or potential financial impact).
- User behavior and adoption: Absent user studies on how developers consume LLM-generated suggestions (trust levels, verification habits, copy-paste rates) and how defenses (e.g., middleware or prompts) change developer behavior and productivity.
- Temporal dynamics: No longitudinal analysis of how hallucination/vulnerability/outdatedness rates evolve over time as models and ecosystems update or as domains/packages lapse/are reclaimed.
- Ecosystem coverage: Evaluation is limited to Node.js, Python, Ruby, PHP, and Perl; excludes major ecosystems (e.g., Java/Maven/Gradle, Go modules, Rust/Cargo, .NET/NuGet, R/CRAN, Julia/General, Swift/CocoaPods/SPM) and OS/container/package sources (e.g., apt/yum/homebrew/chocolatey, DockerHub/base images).
- CI/CD breadth: Focuses on GitHub Actions; omits GitLab CI, Jenkins, CircleCI, Azure Pipelines, Bitbucket Pipelines, and reusable workflow marketplaces—threat patterns and versioning risks may differ.
- Third-party component scope: Limited treatment of other high-impact artifacts (e.g., Terraform modules, Helm charts, Kubernetes manifests, mobile SDKs, browser extensions, VS Code extensions, IaC modules, fonts, datasets).
- Transitive dependencies: No analysis of hallucinations/vulnerabilities in transitive dependencies (e.g., LLM recommending a package that pulls risky transitives) or how pinned lockfiles change outcomes.
- Domain-level risks: Domain hallucination lacks systematic measurement of takeover feasibility (registrar policies, redemption periods, IDN homographs, lookalike/homoglyph risks, CDN subdomain hijacks, DNS caching behavior).
- Existence verification fidelity: Unclear how SSCGuard reliably distinguishes non-existent vs temporarily unavailable/private/unindexed components (risk of false positives due to rate limits, case sensitivity, org vs user namespace collisions, CDN cache misses).
- Vulnerability mapping rigor: Not specified which advisories (NVD, GHSA, Snyk, OSV) and matching heuristics were used, or how to resolve CVE-to-version mapping, vulnerable ranges, forks, and backports—potentially impacting precision/recall.
- CI security breadth: The CI vulnerability analysis is limited; missing coverage of common misconfigurations (untrusted checkout, pull_request_target misuse, permissions hardening, artifact poisoning, cache poisoning, secret handling, path injection, unpinned external tools).
- Version pinning practices: No systematic evaluation of whether LLMs can be steered to pin CI actions by immutable commit SHAs (vs tags/branches) and to enforce trust policies (verified publishers, provenance, signature checks).
- Redirection hijacking prevalence: The study cites the risk but does not quantify how often LLMs recommend redirected/renamed plugins/repos nor measure the real hijack window and breakage conditions.
- Prompt generation bias: Question transformation (e.g., replacing Java with Python/Node.js, standardizing CI to GitHub Actions) may create unnatural prompts; external validity of results to organic developer questions is unclear.
- Model/update variability: Results may be non-reproducible across model updates; no sensitivity analysis for temperature/top-p, system prompts, tool use (browsing/RAG), or code-assistant UIs (e.g., Copilot, CodeWhisperer, Cursor).
- Non-English and localization: No evaluation with non-English prompts, localized ecosystems, or internationalized identifiers (IDNs), which could alter hallucination and typosquatting risks.
- Adversarial prompt injection: Assumes benign LLM usage; does not examine how retrieval-augmented browsing or context ingestion (README/docs/issue pages) enables prompt injection to steer insecure suggestions.
- Ethics and responsible testing: The paper does not document whether and how potentially dangerous actions (e.g., domain/package registration) were ethically handled, disclosed, or mitigated with registries/CDNs.
- Defense coverage gaps: Chain-of-Confirmation primarily targets existence; it does not verify safety (known vulnerabilities), maintenance status, redirections, version immutability, or integrity (e.g., SRI hashes for CDNs).
- Defense robustness: No analysis of time-of-check-to-time-of-use races (an attacker publishing after “confirmation”), adversarial evasion (fabricated mirrors, typos), API availability/rate limits, or offline developer scenarios.
- Middleware evaluation: Lacks false positive/negative rates, latency/cost overhead, scalability, integration pathways (IDEs, CLI, CI gates), and data-privacy implications for scanning code and prompts.
- Registry- and platform-level mitigations: Open questions on systemic countermeasures (e.g., name reservation, stricter version immutability, provenance/SLSA, mandatory SRI for CDN scripts, Git tag protection, redirect hardening).
- Training-time mitigations: Not explored how to reduce SSC-risky generations via curation of training data, safety fine-tuning, preference optimization, or knowledge-grounded generation with live registry/CDN/CI APIs.
- Broader risk classes: Unaddressed categories include license non-compliance in suggestions, install-time script abuse (postinstall), unsafe privilege/permission recommendations, secret handling patterns, and unsafe shell practices.
- Developer-centric UX: Unclear how to present warnings and alternatives without alert fatigue; lacks A/B testing of guardrails, actionable remediation suggestions, and “secure-by-default” prompt templates.
- Reproducibility artifacts: The paper does not state whether datasets, prompts, code, and detection rules are publicly available, versioned, and documented for independent replication.
- Economic incentives: No modeling of attacker economics (cost/time to exploit hallucinations or redirections) or defender economics (costs of scanning, false alarms, and remediation).
- Policy and governance: Open questions on best practices and standards for LLM vendors, IDEs, CI platforms, and registries to coordinate SSC-safe generation and consumption of external components.
These gaps suggest opportunities for rigorous, real-world attack simulations, broader ecosystem coverage, stronger verification pipelines (tool-assisted and platform-enforced), developer-centered safety UX, and systemic mitigations across registries and CI platforms.
Practical Applications
Immediate Applications
Below are actionable, real-world uses that can be deployed now, organized by sector and noting key dependencies.
- DevSecOps middleware for AI-generated code (software, cloud/DevOps, security)
- What: Insert an SSCGuard-like intermediary that scans LLM output for risky external references (packages, domains, CDN URLs, GitHub accounts, GitHub Actions plugins/versions) before code lands in repos.
- How: IDE extensions (e.g., VS Code), CLI wrappers, pre-commit hooks, PR bots, CI gates.
- Outputs: Warnings and fixes for package/domain existence, deprecations, known vulnerabilities (OSV/NVD), redirected/hijackable CI plugins, tag/branch reuse, unsafe YAML patterns.
- Dependencies/assumptions: Access to registry/CDN/GitHub APIs, vulnerability feeds (OSV/NVD), organizational buy-in for policy enforcement, acceptable latency in development flow.
- CI/CD hardening and linting (software, cloud/DevOps)
- What: Enforce best practices highlighted by the paper for GitHub Actions and other CI: pin to commit SHAs (not tags/branches), avoid mixed branch/tag reuse, sanitize run inputs to prevent code injection, least-privilege permissions, trusted reusable workflows.
- How: Expanded action-lint rules; policy-as-code with OPA/Conftest; GitHub App that blocks unpinned actions; reusable secure workflow templates.
- Dependencies: GitHub Actions or mapped equivalents in GitLab/Jenkins, developer adherence to gating policies.
- Chain-of-Confirmation for LLM assistants (software/AI vendors)
- What: Wrap code-generation with verification steps that check component existence/versions in real time; regenerate or back off when fabrication is detected.
- How: Tool-use to query registry/CDN/GitHub APIs; retrieval-augmented checks; user-visible warnings.
- Dependencies: Model tool-use or middleware, API quotas, tolerance for added latency; continuous refresh to reduce outdated responses.
- Registry/marketplace protective measures (package registries, CDNs, platforms)
- What: Monitor for frequently hallucinated names; warn or quarantine installs of newly created packages that match flagged patterns; “recently created” risk prompts; CDN warnings for non-existent/vulnerable versions.
- How: Name-watchlists, install-time banners, moderator workflows.
- Dependencies: Willingness from npm/PyPI/RubyGems/Packagist/CPAN/CDNs; careful tuning to minimize false positives.
- Redirection hijacking checks for CI plugins (cloud/DevOps)
- What: Detect action references to renamed/deleted orgs/repos; validate redirections; alert if original namespace is re-registrable or has been re-registered.
- How: GitHub App or CI step querying the GraphQL/REST API; PR comments with remediation (update to new org/repo and pin to SHA).
- Dependencies: GitHub API; ability to block or fail builds on risk.
- SCA/SAST extensions for SSC threats (security tooling)
- What: Extend scanners to detect dangling or hallucinated references (domains/packages), outdated/deprecated components, vulnerable versions, and YAML injection sinks.
- How: New rulesets for CI YAML, CDN URLs, action references; integration with Dependabot/Renovate.
- Dependencies: Vulnerability/deprecation feeds; URL/domain health checks; policy engine.
- SBOM enrichment with external references (compliance, risk)
- What: Include CDN URLs, domains, action references, and reusable workflows in SBOMs with risk annotations (deprecated, redirected, unpinned, vulnerable).
- How: CycloneDX/Syft plugins; SBOM checks in CI.
- Dependencies: SBOM tooling support; processes to consume and act on annotations.
- Organizational policies and governance updates (policy, enterprise)
- What: Update secure SDLC to require verification of external components in AI-generated code, commit-SHA pinning for actions, allowlists/denylists, approvals for new third-party resources/services.
- How: Engineering handbooks, code review checklists, merge gates.
- Dependencies: Leadership mandate; enforcement tooling.
- Developer training and awareness (education; daily life)
- What: Practical modules and labs on LLM-induced SSC risks (package/domain hallucination, CI injection, version reuse, deprecated components).
- How: Internal courses, brown-bags, “fix-the-YAML” workshops; cheat-sheets.
- Dependencies: Security champions; time for training.
- Incident response playbooks for SSC (operations, security)
- What: Procedures to detect and roll back malicious action versions, hijacked packages, or redirected plugins; monitoring pipelines for unexpected action/version changes.
- How: Runtime telemetry; alerts on action reference diffs; rapid pinning/rollback steps.
- Dependencies: Logging/observability; pre-approved rollback mechanisms.
- Personal projects and small teams (daily life)
- What: Simple verification routine before adopting LLM code: search packages (npm/pip/gem/composer/cpan), check deprecation/vulns, prefer official org repositories, avoid pasting CI YAML without pinning to SHAs; prefer Subresource Integrity (SRI) for scripts.
- How: Small scripts (e.g., npm view, pip search), browser extensions warning on pasted code with external references.
- Dependencies: Basic CLI proficiency; awareness.
- Academic and benchmarking uses (academia, AI)
- What: Use SSCGuard-style prompt suites to benchmark LLMs on SSC safety metrics; evaluate defenses (prompting, tool-use).
- How: Reproduce datasets; report KPIs (hallucination rate, vulnerable/outdated references).
- Dependencies: Access to models/APIs; reproducible pipelines.
Long-Term Applications
These opportunities likely require further research, ecosystem changes, scaling, or standardization.
- Platform defaults and guardrails for CI marketplaces (platforms)
- What: Enforce commit SHA pinning by default; signed/immutable tags; marketplace vetting; prevent re-registration of previously redirected orgs that are in widespread use.
- Dependencies: GitHub and comparable platforms’ product changes; backward compatibility plans.
- Cross-ecosystem “component gate” (tooling vendors)
- What: Unified verification layer across npm/PyPI/RubyGems/Packagist/CPAN/CDNs/GitHub Actions that blocks builds on non-existent, deprecated, vulnerable, redirected, or unpinned external components.
- Dependencies: Standard APIs and policy DSL; IDE/build-system integration.
- Threat intelligence feeds for hallucinated names (security intel, registries)
- What: Curated feeds of frequently hallucinated package names, domains, and action references; shared with registries, CDNs, browsers, and enterprises.
- Dependencies: Data sharing agreements; governance to mitigate abuse and false positives.
- LLM training and alignment for SSC safety (AI, research)
- What: Train/evaluate models to avoid fabricating external components; integrate live registry/CDN/GitHub tools; incorporate SSC-aware reward models.
- Dependencies: Model training access; continuous retrieval integration; evaluation benchmarks (e.g., SSCGuard-derived).
- Standards and frameworks updates (standards bodies, policy)
- What: Extend SLSA, SSDF, and NIST guidance to cover AI-generated code and external-component verification; CycloneDX/SBOM extensions for CI plugins/URLs; registry-level advisories for deprecations/redirections.
- Dependencies: Multi-stakeholder consensus; versioned specs; vendor adoption.
- Proactive reservation and “safety squatting” programs (registries, enterprises)
- What: Reserve high-risk or frequently hallucinated names to prevent adversarial takeovers; enterprise-internal namespaces for packages/actions.
- Dependencies: Policy and cost management; processes to release/curate reservations.
- Automated CI/YAML repair systems (software tooling)
- What: Synthesize secure replacements automatically: convert tag/branch to SHA, sanitize run steps, replace redirected actions with canonical references, pin CDN URLs with SRI.
- Dependencies: Reliable program transformation; continuous ruleset updates.
- Secure AI coding assistants with verifiable citations (AI products)
- What: Assistants that cite registry/marketplace sources, include SRI for scripts, show deprecation/vulnerability badges and risk scores; block or ask confirmation for risky suggestions.
- Dependencies: Product design, UX, and up-to-date data pipelines.
- Education and certification programs (education, workforce)
- What: Add LLM-SSC safety modules to university curricula, professional certifications, and secure coding bootcamps.
- Dependencies: Curriculum development; collaboration with industry.
- Regulatory and procurement requirements (government, critical infrastructure, finance)
- What: Mandate commit-SHA pinning, SCA with AI-aware checks, and CI hardening for suppliers; audits of AI-generated code controls for regulated sectors.
- Dependencies: Policy development, industry consultation, certification frameworks.
- Cyber insurance risk scoring (finance)
- What: Premium adjustments or requirements based on SSC hygiene with AI-generated code (e.g., pinning rates, deprecation use, redirect risks).
- Dependencies: Actuarial models; verifiable controls evidence.
- Broader ecosystem coverage (software, cloud-native)
- What: Extend analyses and defenses to Maven/Go modules/Docker images/Helm charts/Terraform modules and CI systems beyond GitHub Actions.
- Dependencies: Research expansion; API coverage; community tooling support.
Key Assumptions and Dependencies Across Applications
- Technical data access: Reliable APIs from registries (npm, PyPI, etc.), GitHub (Actions, repos, redirects), CDNs, and vulnerability databases (OSV/NVD).
- Ecosystem cooperation: Platforms and registries must accept changes (e.g., pinning mandates, name reservations).
- Organizational readiness: Teams must accept stricter policies and possible friction (latency from verification steps, blocked builds).
- Model/tool capabilities: LLMs or wrappers need tool-use for real-time verification; prompt defenses like Chain-of-Confirmation benefit from retrieval.
- Scope constraints: Current evidence covers five interpreted language ecosystems and GitHub Actions; other ecosystems may need tailored rules.
- False positives/negatives: Verification and heuristics must be tuned to minimize developer fatigue while catching material risks.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- Branch-tag mix reuse attack: A Git-based supply-chain attack where a malicious maintainer reuses a version name across a branch and tag to silently change code referenced by CI. "This introduces another security risk, enabling malicious plugin maintainers to create a branch with the same name as an existing tag, resulting in a branch-tag mix reuse attack~\cite{li2024toward}."
- Chain-of-Confirmation: A prompt-based defense technique that asks an LLM to verify the existence of referenced components before regenerating code. "To mitigate these risks, we propose a novel prompt-based defense mechanism, namely Chain-of-Confirmation, to reduce fabrication"
- Chain-of-Thought (CoT): A reasoning-based prompting strategy used to guide LLMs through multi-step decisions. "SSCGuard employs a Chain-of-Thought (CoT) reasoning-based prompting strategy to narrow the tags of interest."
- CI Plugin Hallucination: The fabrication of non-existent CI plugins by an LLM, potentially enabling adversarial takeover. "CI Plugin Hallucination"
- CI Plugin Version Hallucination: The fabrication of non-existent versions for real CI plugins, which adversaries can later create to appear legitimate. "CI Plugin Version Hallucination"
- CI Plugin Version Reuse: Reusing a Git branch or tag name for a plugin version to alter code without changing the version identifier. "branches and tags can be deleted and recreated, allowing malicious plugin maintainers to modify the code associated with a specific version without changing the version (i.e., version reuse)."
- Code injection: A vulnerability where untrusted input is executed as code within a workflow or application. "code injection vulnerabilities~\cite{muralee2023argus}"
- Component redirection hijacking: Exploiting redirections (e.g., after account renames) to hijack references and serve malicious components. "e.g., component redirection hijacking, and distributing malicious versions of legitimate components"
- Content Delivery Network (CDN): A distributed infrastructure that serves cached files (e.g., JavaScript, CSS) from packages or repositories via URL. "CDNs, such as jsDelivr and UNPKG, provide a convenient mechanism for accessing static files directly from npm packages and GitHub repositories."
- Continuous Integration (CI): An automated process for building, testing, and integrating code changes within software projects. "To date, many organizations rely on Continuous Integration (CI) to integrate and build code efficiently."
- Dangling reference: A reference to a non-existent or expired package/domain that can be hijacked by attackers. "A dangling reference, similar to a dangling pointer in the use-after-free vulnerability, refers to an expired or non-existent package/domain that is still referenced by others (e.g., users or software)."
- Domain hallucination: The fabrication of non-existent domains in URLs for external resources/services suggested by an LLM. "Domain Hallucination"
- External Component Hallucination: The fabrication of non-existent external components (packages, domains, plugins) by an LLM in generated code. "External component hallucination refers to the phenomenon where LLMs fabricate components that do not actually exist."
- Git reference: A specific identifier (branch, tag, or commit hash) used to pin versions of a GitHub-hosted plugin or workflow. "The version can be specified via a Git reference (e.g., a branch or tag)."
- GitHub Account Hallucination: The fabrication of non-existent GitHub accounts whose repositories are referenced by LLM-generated code. "GitHub Account Hallucination"
- GitHub Actions: GitHub’s CI platform for running workflow tasks defined in repository configuration files. "Typically, CI platforms (e.g., GitHub Actions) execute the repository's CI workflows"
- LLM: A machine learning model trained on large corpora capable of generating code and text. "LLMs have achieved significant advancements in a wide range of tasks, including code generation."
- Middleware-based defense: An intermediary tool or layer that analyzes LLM output to inform users of potential SSC threats. "a middleware-based defense that informs users of various SSC threats."
- Package deprecation: The state of a package being marked as no longer maintained or recommended for use. "Package Deprecation"
- Package hallucination: The fabrication of non-existent package names or versions by an LLM that adversaries can later claim and publish. "One example is the package hallucination~\cite{spracklen2024we} threat:"
- Reusable workflow: A CI configuration that can be referenced by other workflows to share common tasks. "GitHub Actions supports reusable workflows, allowing one CI configuration to reference another."
- Semantic versioning: A versioning scheme (MAJOR.MINOR.PATCH) commonly used by packages to indicate compatibility and changes. "npm packages typically follow semantic versioning~\cite{npm_versioning}"
- Software supply chain (SSC): The ecosystem of third-party components, processes, and distribution channels involved in software development. "The software supply chain (SSC) involves a series of third-party components and processes that collectively contribute to software development."
- SSCGuard: An automated tool built by the authors to generate prompts, query LLMs, and detect SSC-related vulnerabilities in responses. "we design a tool, SSCGuard, to generate 439,138 prompts based on SSC-related questions collected online"
- Third-party Resources/Services Absence: A condition where referenced resources/services exist under a valid domain but the specific resource is missing. "Third-party Resources/Services Absence"
- Version reuse: A threat where the same version identifier is reused for different code, enabling silent malicious changes. "version reuse is a known threat in package management~\cite{gu2023investigating}."
- Vulnerable CI Configuration: A CI workflow with misconfigurations (e.g., unsafe input handling) that enable exploitation. "Vulnerable CI Configuration"
- Vulnerable Third-party Resources/Services Versions: The use of external libraries or services at versions known to contain security vulnerabilities. "Vulnerable Third-party Resources/Services Versions"
- YAML: A human-readable data serialization format used for CI workflow configuration files. "The tasks of a CI workflow are defined within a CI configuration file, which is typically written in YAML format."
Collections
Sign up for free to add this paper to one or more collections.

