- The paper demonstrates that reusing register tokens enhances spatial reasoning in VLA models.
- It introduces a Spatial Context Injection mechanism that converts tokens into key-value pairs for improved action generation.
- Experimental results show a success rate improvement from 50.3% to 67.4% in complex robotic tasks.
RetoVLA: Reusing Register Tokens for Spatial Reasoning in Vision-Language-Action Models
Introduction
The paper "RetoVLA: Reusing Register Tokens for Spatial Reasoning in Vision-Language-Action Models" presents the RetoVLA architecture aimed at enhancing the efficiency and capability of Vision-Language-Action (VLA) models. These models, although effective in their tasks, face challenges related to size and computational demands, hindering their deployment in resource-constrained environments. The novel aspect of RetoVLA lies in its innovative use of Register Tokens, previously considered artifacts destined for removal, repurposed to enhance spatial reasoning capabilities in robotic systems.
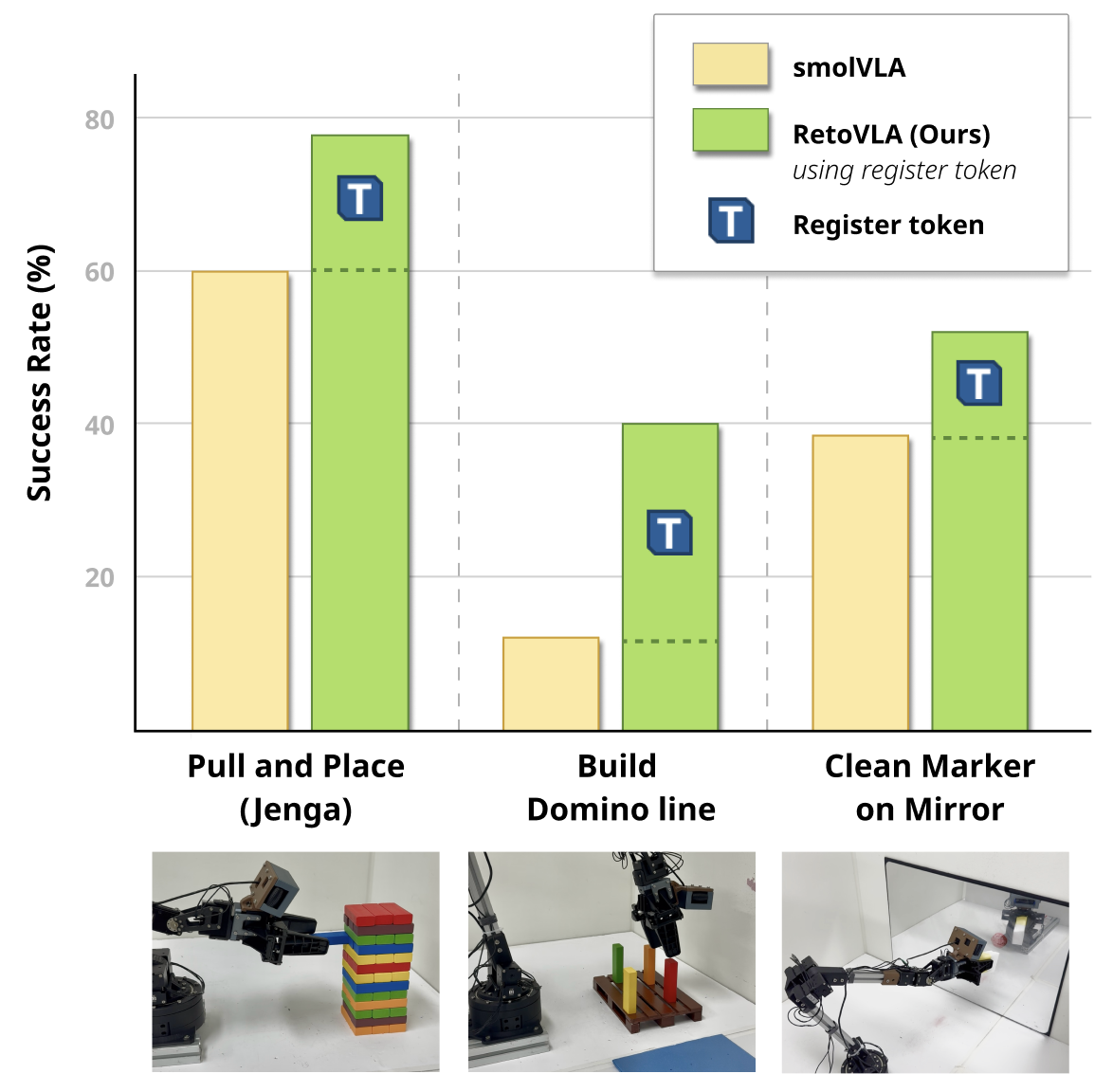
Figure 1: Comparison of RetoVLA and the SmolVLA baseline on challenging real-world tasks. (Top) Our model, RetoVLA (green), significantly outperforms the baseline (yellow). (Bottom) This performance gain comes from reusing the Register Token.
Methodology
RetoVLA Architecture
The RetoVLA architecture introduces a Spatial Context Injection mechanism into a standard VLA model. This pathway injects Register Tokens into the Action Expert, providing a global spatial context critical for task completion. Unlike the conventional approach, where these tokens are discarded post artifact removal, RetoVLA leverages them to boost spatial reasoning.
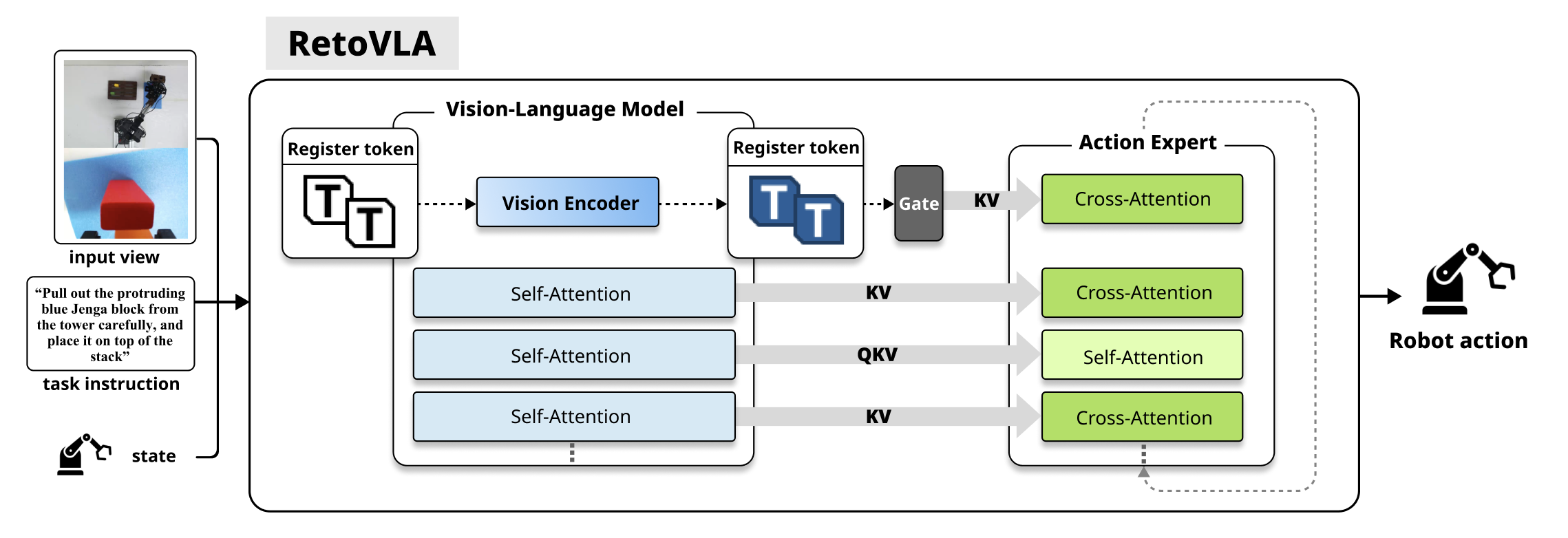
Figure 2: The RetoVLA architecture. Our key innovation is the Spatial Context Injection path (dashed arrow), which enhances a standard VLM-based policy.
Spatial Context Injection
RetoVLA's central enhancement is the injection of Register Tokens through a modified information flow mechanism. These tokens are amassed by a Spatial Context Aggregator, transforming them into Key-Value pairs integral to the Action Expert's decision-making process. The injection process enables the model to concurrently address both high-level semantic features and global spatial context, facilitating superior action generation.
Training Objective
The training employs a conditional flow matching objective, refining an Action Expert capable of transforming noisy actions into accurate task-executing sequences. This follows a vector field approach guiding action sequences from noise to ground-truth through a calculated flow, conditioned on visual and linguistic context inputs provided by the VLA.
Experimental Evaluation
Standardized Benchmark
The LIBERO benchmark served as the primary evaluation tool for RetoVLA, a suite designed to assay various manipulation capabilities. RetoVLA demonstrated modest gains in overall scores but excelled in tasks requiring intricate spatial reasoning, notably improving performance in categories demanding working memory and complex 3D spatial processing.

Figure 3: Overview of the experimental setups for real-world and simulation tasks.
Real-World Deployment
RetoVLA's efficacy was underscored in real-world experiments on a custom-built robot arm, especially in long-horizon tasks such as Build Domino Line and complex manipulations like Close Drawer, seeing a remarkable mean success rate improvement from 50.3% to 67.4%.
Custom Simulation
A custom simulation mirrored real-world conditions to validate RetoVLA's enhancements. The simulation results mirrored real-world outcomes, consolidating the theory that Register Token reuse significantly advances spatial reasoning capabilities without the expense of computational efficiency.
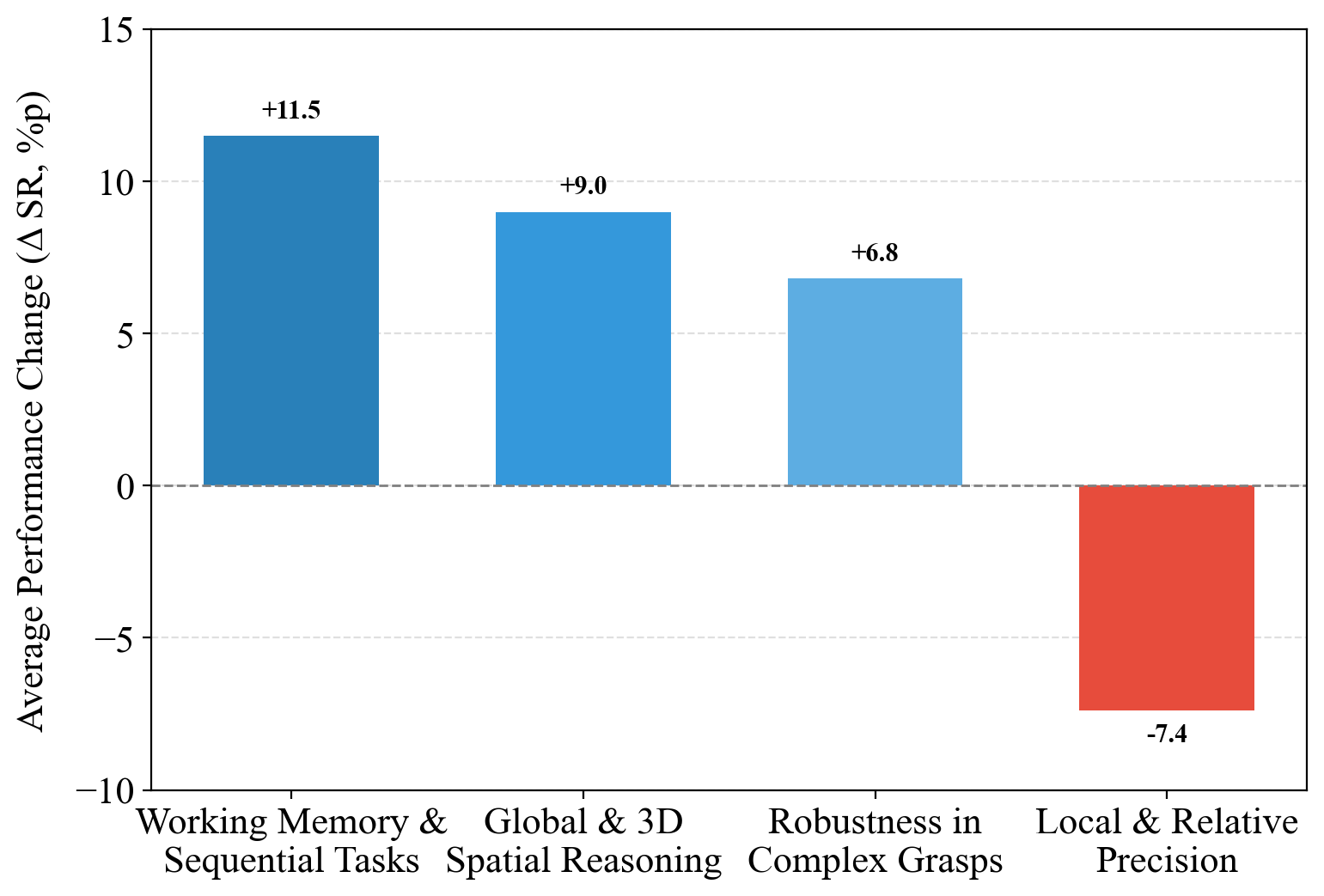
Figure 4: Performance analysis of RetoVLA grouped by core capabilities. Significant improvements in tasks requiring high-level reasoning are observed.
Conclusion
RetoVLA demonstrates that repurposed Register Tokens contribute substantially to improving the spatial reasoning capabilities of VLA models. This advancement is critical in scenarios requiring both computational efficiency and high-level reasoning. Although RetoVLA shows promise, further research is required to mitigate the trade-offs observed in precision-demanding tasks. Future experimentation will explore integration possibilities with larger VLA models and applications in dynamic, complex environments. The revelation that what was once discarded as noise can now be essential information challenges existing paradigms, opening new pathways in robotic intelligence design.