- The paper introduces LLMTrace, a bilingual corpus supporting binary classification and character-level localization of AI-generated text in mixed-authorship scenarios.
- It employs diverse generation scenarios and rigorous quality metrics, achieving over 98% F1 scores for classification and strong interval detection performance.
- Implications span forensic analysis, academic integrity, and content moderation, setting a new benchmark for AI text detection research.
LLMTrace: A Corpus for Classification and Fine-Grained Localization of AI-Written Text
Motivation and Contributions
The proliferation of LLM-generated text has rendered human detection unreliable, necessitating robust automated systems for distinguishing AI-generated content. Existing datasets for AI text detection are limited by outdated model outputs, English-centricity, and a lack of resources for mixed human-AI authorship, especially with precise localization. LLMTrace addresses these gaps by introducing a large-scale, bilingual (English and Russian) corpus supporting both binary classification and fine-grained interval detection of AI-generated text, with character-level annotations for mixed-authorship scenarios.
Dataset Design and Curation
LLMTrace comprises two primary components: a classification dataset and a detection dataset. The classification dataset is constructed from a diverse suite of 38 LLMs across nine domains, using a variety of prompt types to generate challenging examples. The detection dataset introduces character-level annotations for mixed-authorship texts, enabling precise localization of AI-generated segments.
The curation pipeline ensures domain and length diversity, generator model heterogeneity, and realistic generation scenarios. Human corpora are sourced from extensive open datasets, while AI corpora are generated using prompt templates for creation, summarization, expansion, and stylistic modification. Mixed texts are produced via automated gap-filling, AI continuation, and manual human editing of AI outputs.

Figure 1: Example annotations from the LLMTrace English dataset, showing a sample from the classification dataset (left) and the detection dataset (right).
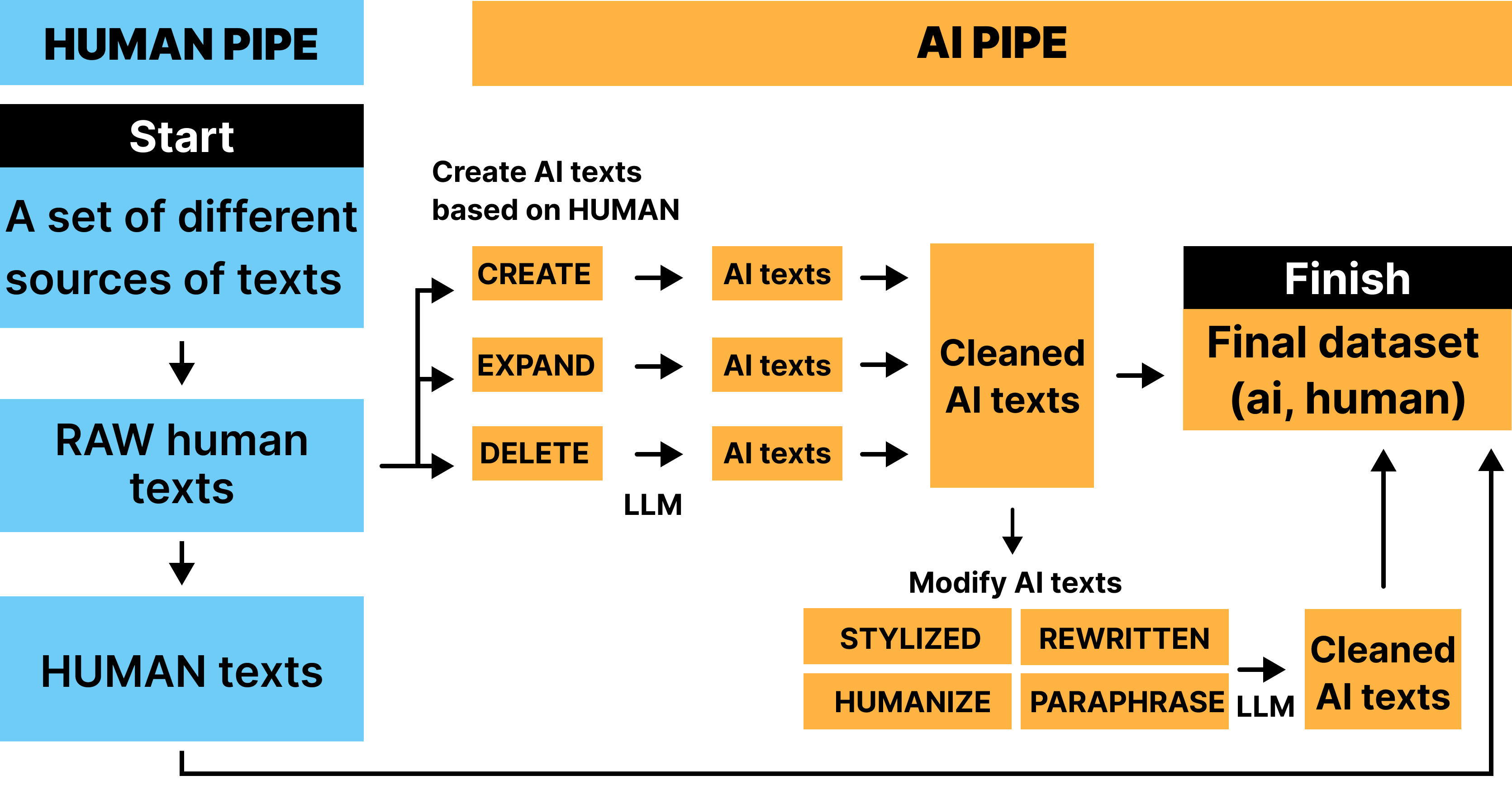
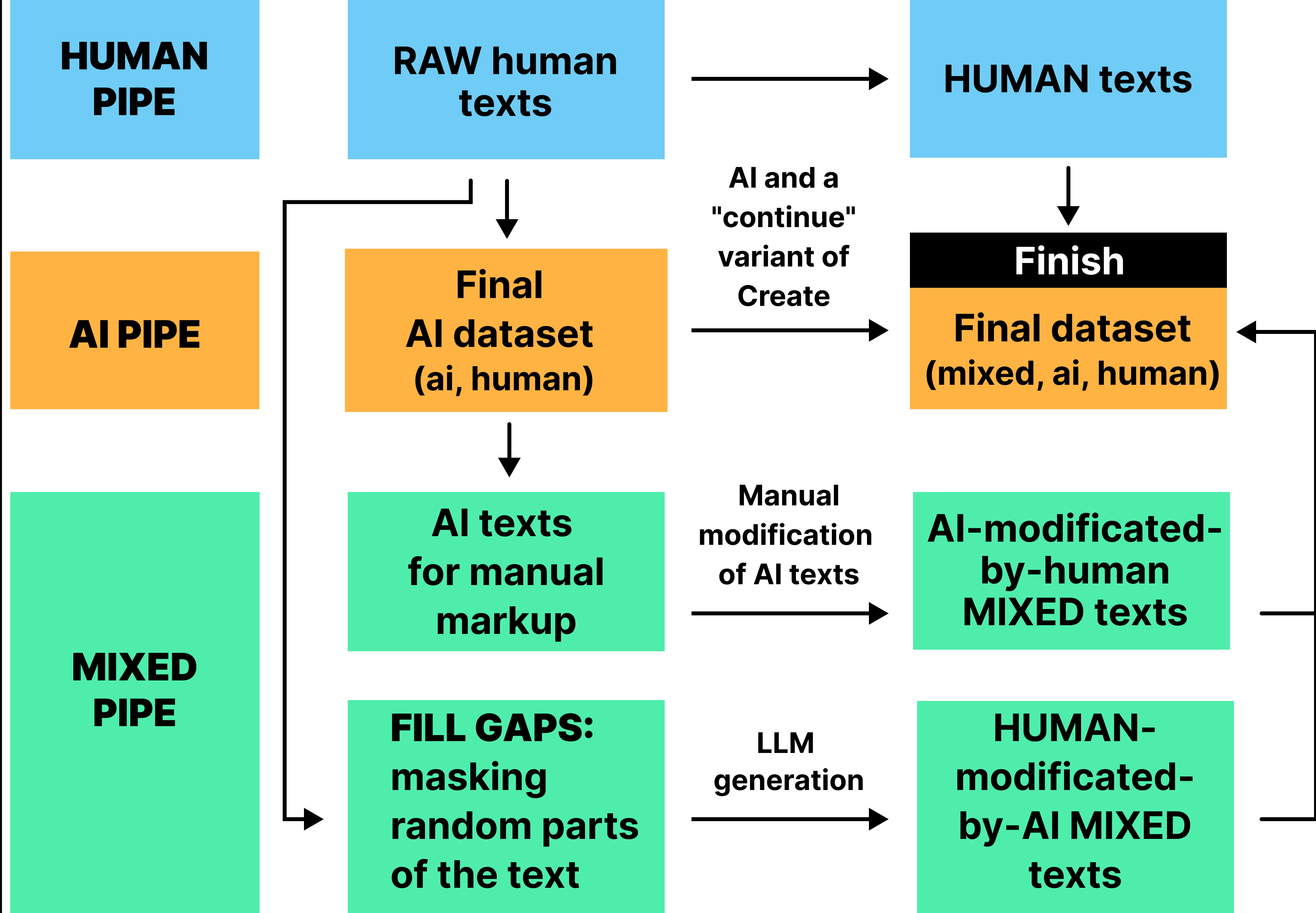
Figure 2: Classification dataset.

Figure 3: The automated mixed-text generation process: sentences in a human text are masked and then filled in by an LLM, resulting in a text with annotated AI-generated intervals.
Dataset Statistics and Structural Complexity
LLMTrace contains approximately 589k classification samples and 79k detection samples, with a substantial representation of both English and Russian texts. The dataset is balanced across word count ranges and domains, minimizing spurious correlations and enhancing generalizability.
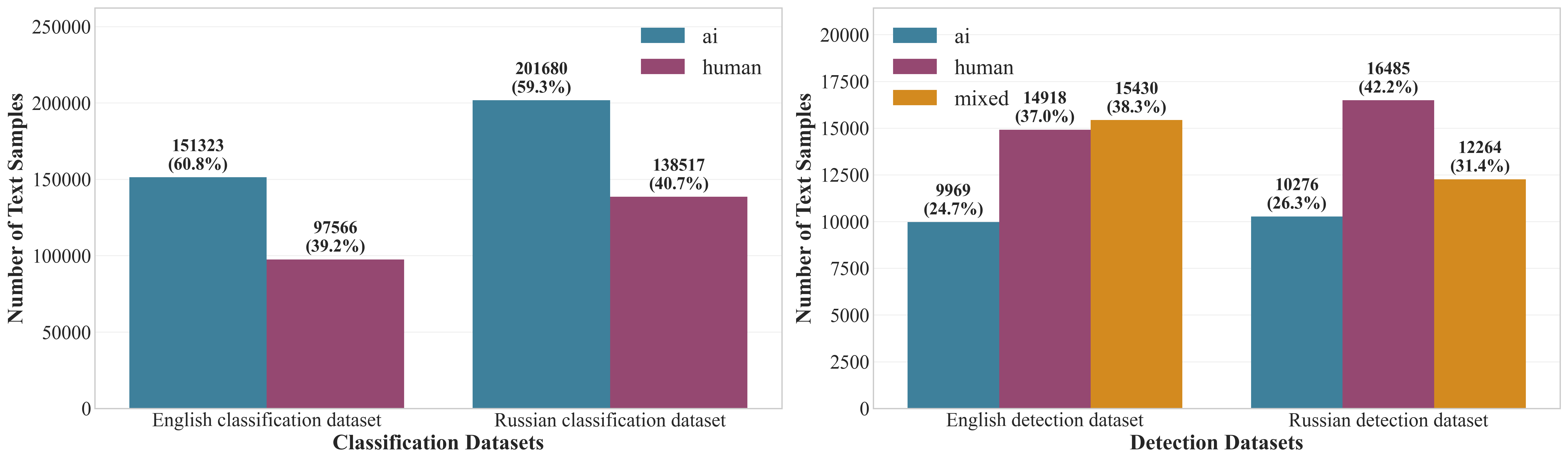
Figure 4: The number of samples for each label in the LLMTrace dataset.
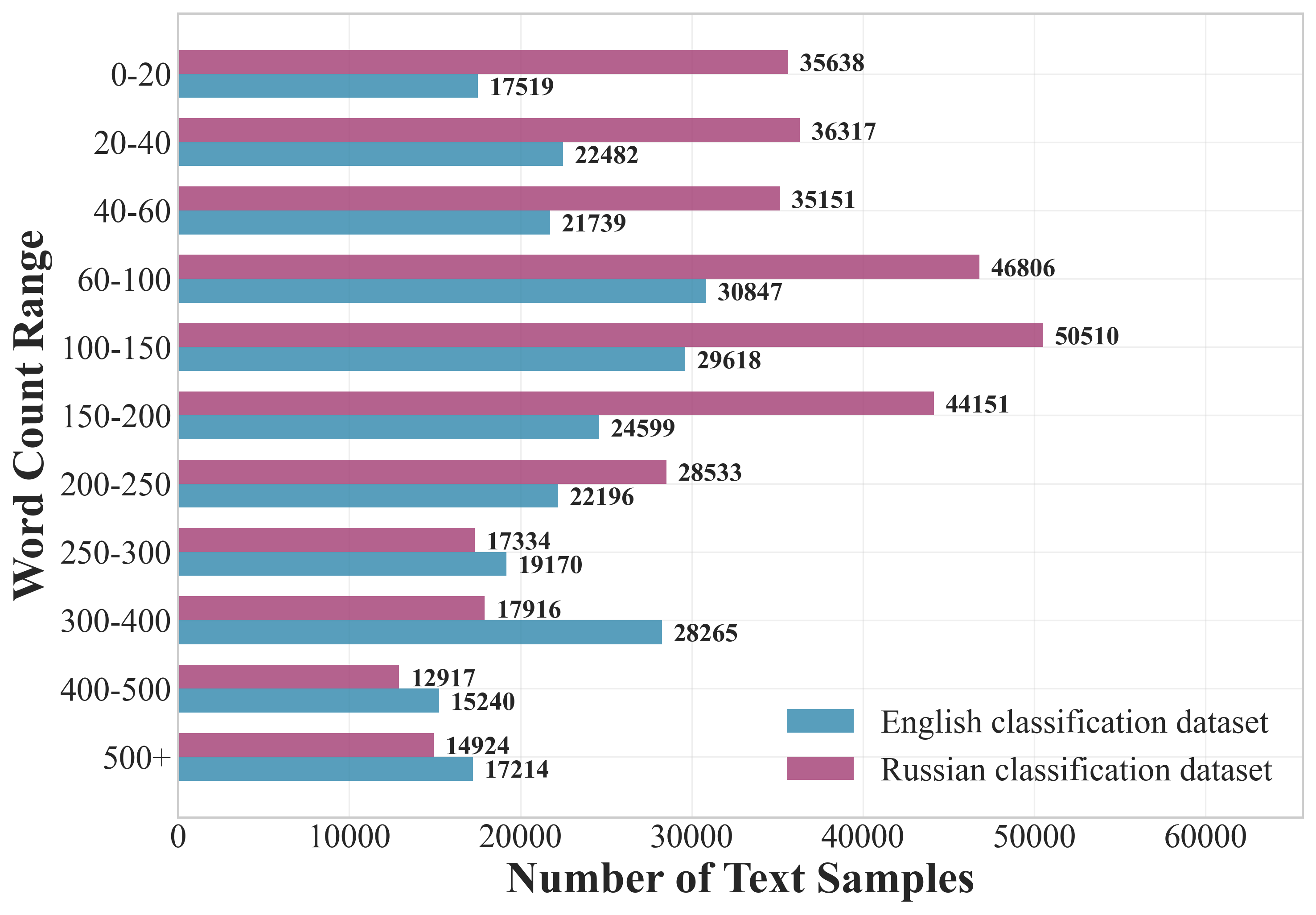
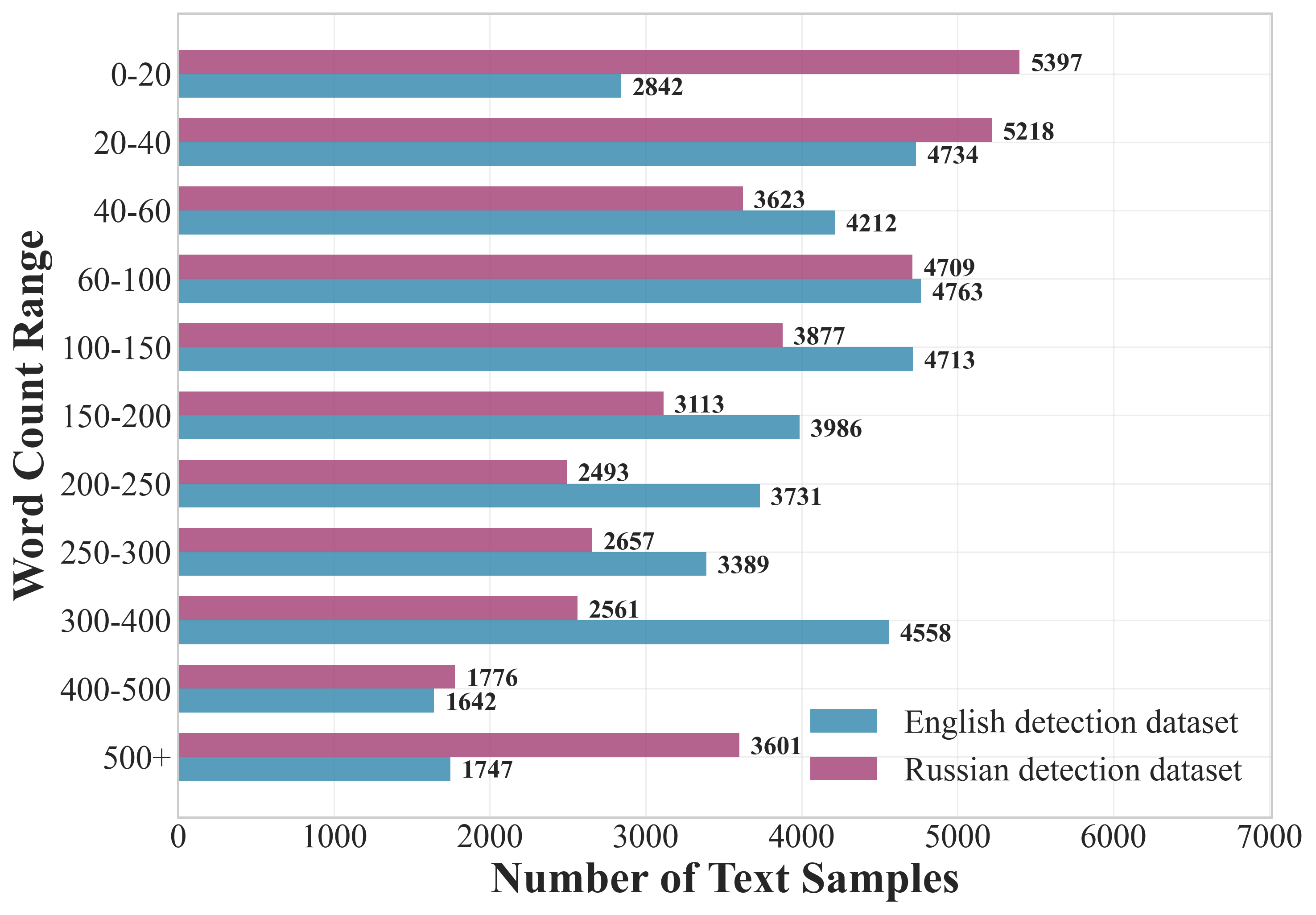
Figure 5: Classification datasets.
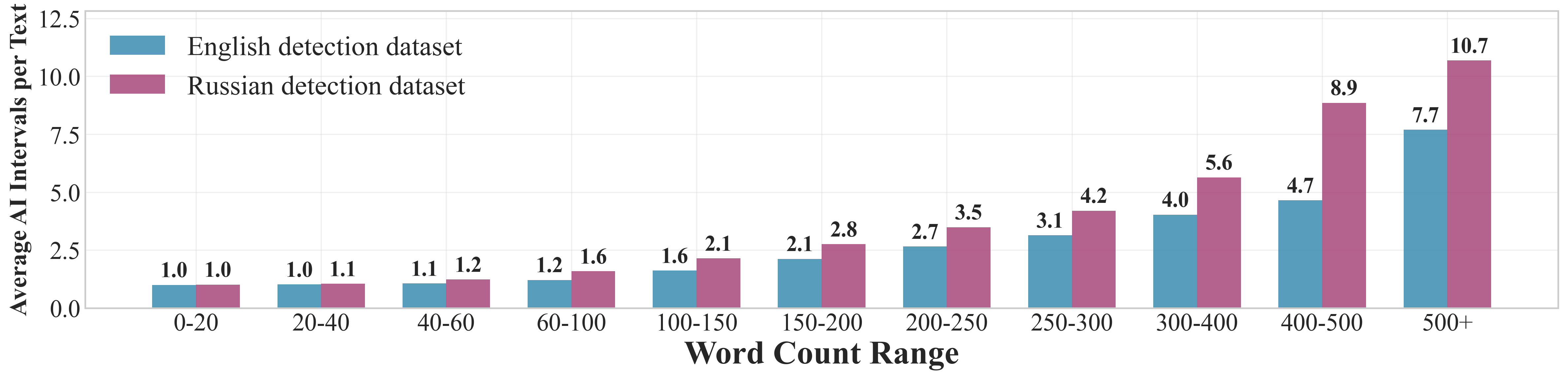
Figure 6: Average number of AI intervals per text in each word count range for the detection datasets.
The detection dataset features a variable number of AI intervals per text, with complexity increasing for longer texts, providing challenging scenarios for interval localization models.
Quality and Complexity Assessment
LLMTrace's quality is evaluated using topological (PHD, KL-TTS), perturbation ($\Delta_{\text{shift}$), and textual similarity metrics (METEOR, BERTScore, n-gram, Levenshtein, MAUVE). The KL-TTS scores for English (0.0189) and Russian (0.0032) classification datasets are competitive with or superior to existing benchmarks, indicating high structural similarity between human and AI texts. The detection dataset achieves exceptionally low KL-TTS between mixed and human texts (0.0017 for EN, 0.0332 for RU), confirming the challenge posed by mixed-authorship examples.
Embedding shift distributions after synonym-based perturbation show near-zero $\Delta_{\text{shift}$, demonstrating robustness and indistinguishability. Textual similarity metrics further confirm high semantic and lexical overlap, with global BERTScore (EN: 0.6964) and METEOR (EN: 0.2665) surpassing prior benchmarks.
Experimental Baselines
Baseline models are established for both tasks: a fine-tuned Mistral-7B for classification and a DN-DAB-DETR for interval detection. Classification models achieve F1 scores above 98% for both AI and human classes, with mean accuracy exceeding 98% and TPR@FPR=0.01 near 98%. Interval detection models reach [email protected] of 0.87–0.89 and [email protected]:0.95 of 0.75–0.79, demonstrating strong localization performance.
Implementation Details
- Classification: Mistral-7B-v0.3, LoRA rank=8, bf16 precision, batch size 64, AdamW optimizer, 20 epochs.
- Detection: DN-DAB-DETR with frozen Mistral-7B features, 45 queries, 3 encoder/decoder layers, 150 epochs, mAP evaluation with IoU thresholds.
- Data Filtering: Strict language filtering, duplicate removal, normalization, and artifact filtering.
- Prompt Diversity: Four generation scenarios (Create, Delete, Expand, Update) ensure stylistic and structural variety.
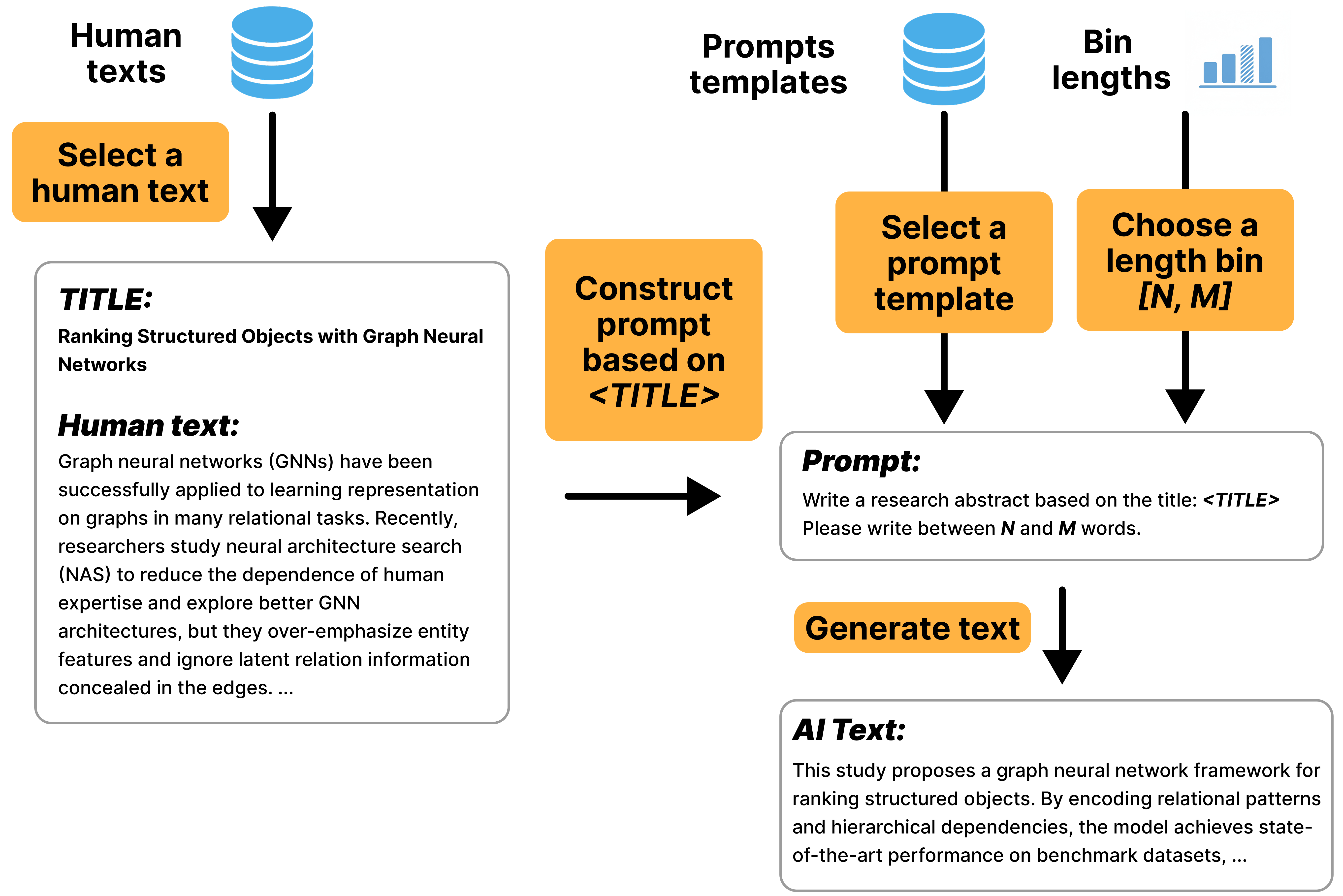
Figure 7: Example of the Create generation pipeline, where a research abstract is generated from a title.
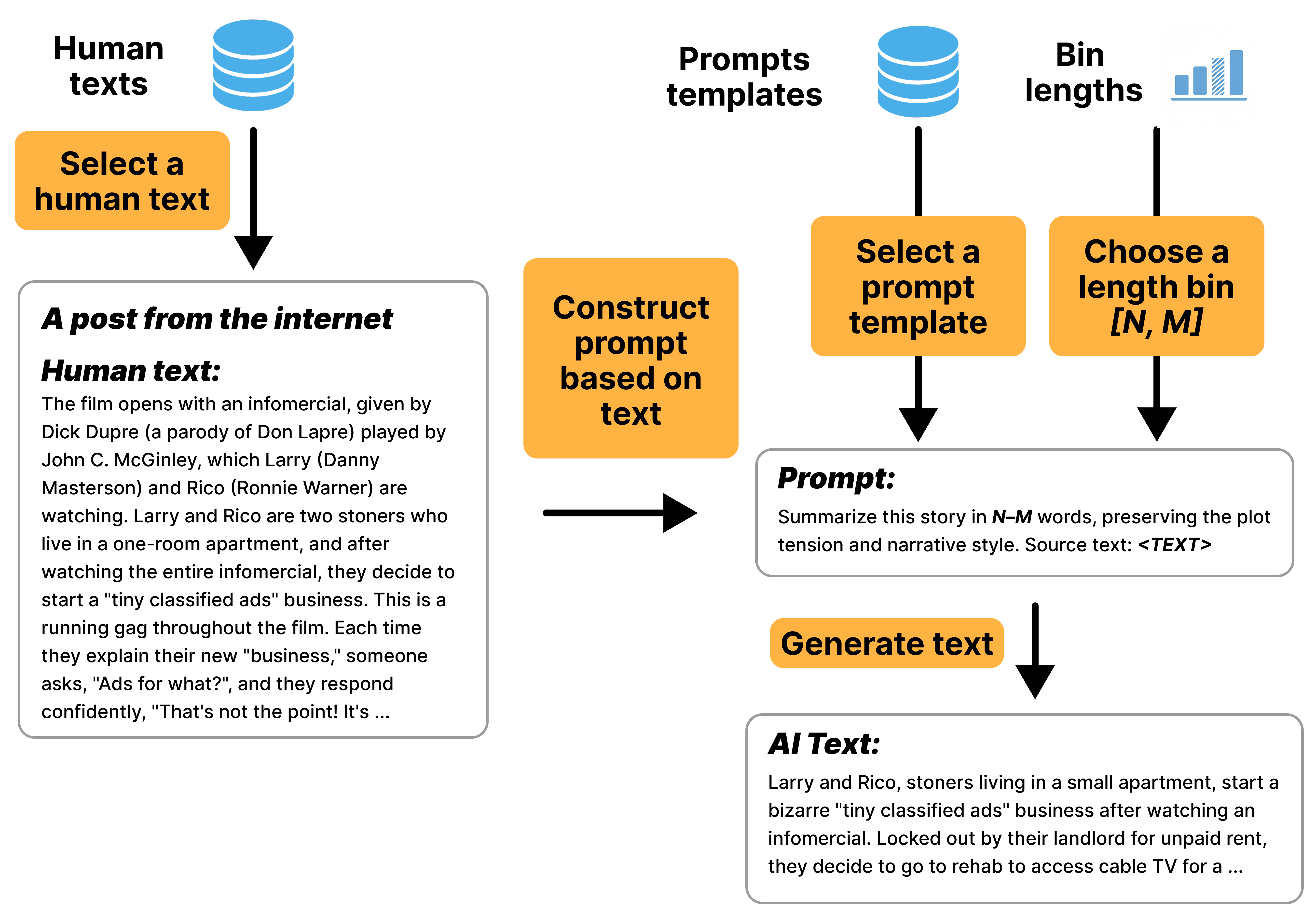
Figure 8: Example of the Delete generation pipeline, where a long post is summarized.
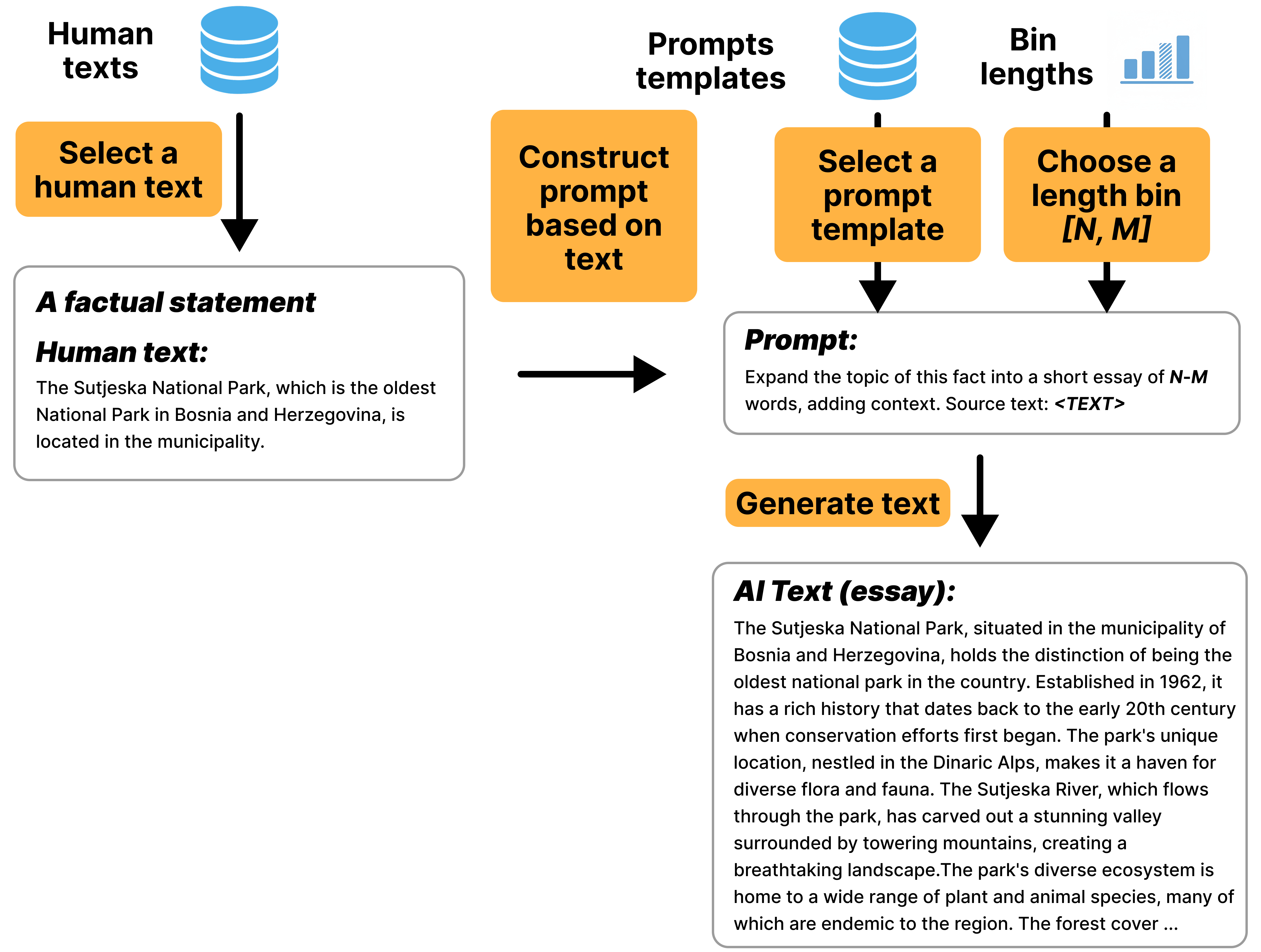
Figure 9: Example of the Expand generation pipeline, where a factual statement is expanded into an essay.
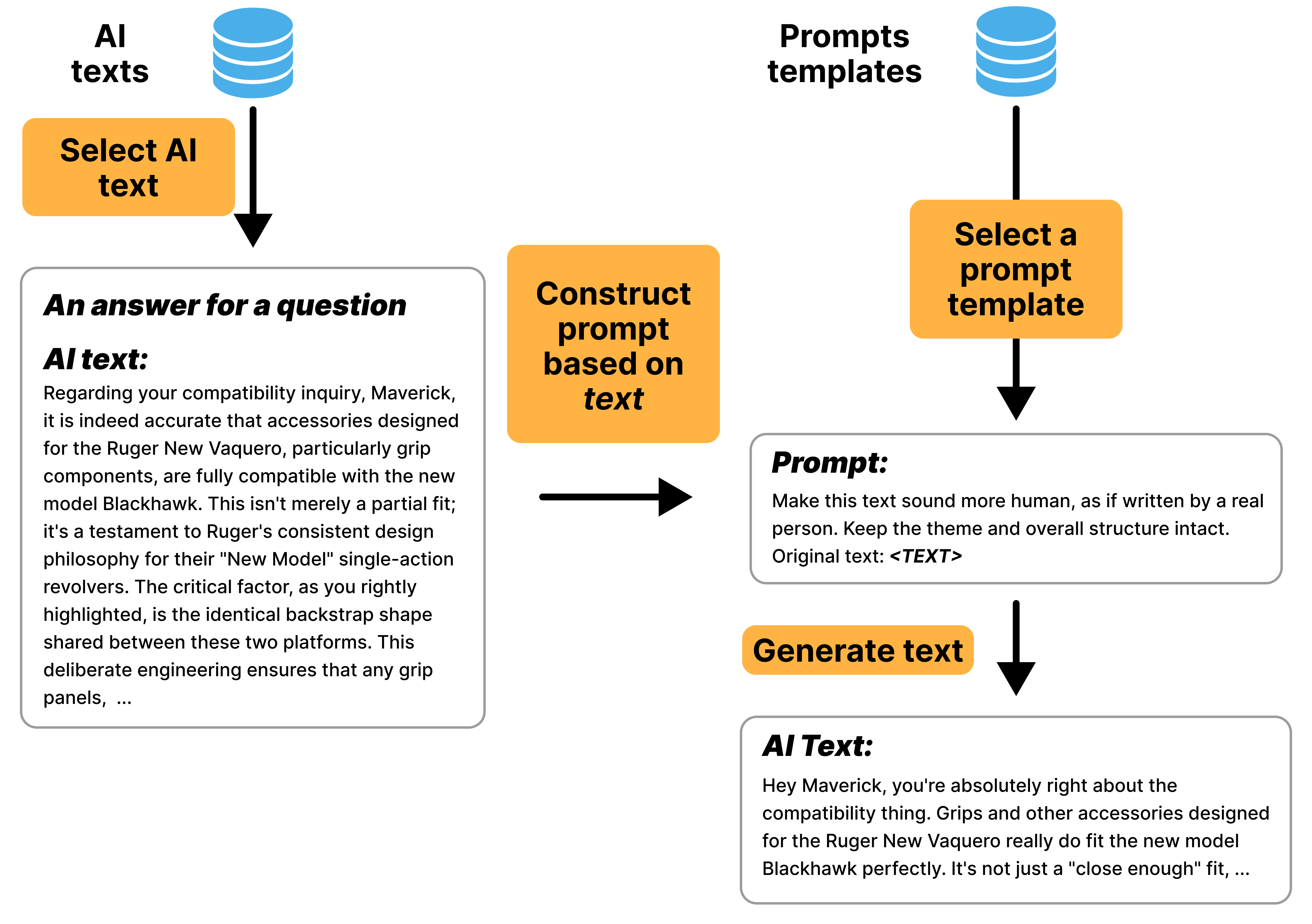
Figure 10: Example of the Update generation pipeline, where an AI-generated text is modified to sound more human.
Implications and Future Directions
LLMTrace sets a new standard for AI text detection datasets by supporting both binary and fine-grained interval detection, with bilingual coverage and character-level annotations. The dataset's complexity and diversity enable the development of robust detectors capable of handling nuanced mixed-authorship scenarios and generalizing across domains and languages.
Practically, LLMTrace facilitates the training of models for forensic analysis, academic integrity, and content moderation, especially in multilingual and collaborative environments. Theoretically, the dataset enables research into the limits of AI-human indistinguishability, adversarial robustness, and the development of new detection paradigms.
Future work may extend LLMTrace to additional languages, domains, and modalities, incorporate more sophisticated human-AI collaboration scenarios, and explore unsupervised or self-supervised detection approaches leveraging the fine-grained annotations.
Conclusion
LLMTrace provides a comprehensive, high-quality resource for AI text detection, addressing critical gaps in multilinguality, model diversity, and mixed-authorship localization. Its strong baseline results and challenging examples will drive advances in detection models and support rigorous evaluation of future systems. The dataset's public availability ensures its impact on both practical applications and foundational research in AI-generated text detection.

