- The paper presents the RoT framework which efficiently reuses reasoning steps through a thought graph to reduce computational load.
- It dynamically assembles problem-specific templates using sequential and semantic edges, achieving a 40% reduction in tokens and an 82% reduction in latency.
- The approach incorporates reward-guided retrieval with minimal overhead, offering scalable improvements for large reasoning models' inference costs.
Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts
Introduction
The paper "Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts" presents an innovative framework aimed at improving inference-time efficiency in Large Reasoning Models (LRMs). By proposing the Retrieval-of-Thought (RoT) framework, the authors demonstrate a method of reusing prior reasoning steps to solve new problems efficiently. RoT leverages a thought graph, which organizes reasoning steps into nodes and uses retrieval-based methods to dynamically assemble templates for problem-solving. This approach significantly reduces the number of output tokens required, thereby lowering latency and cost, while maintaining high accuracy.
Thought Graph and Dynamic Template Assembly
Central to the RoT framework is the construction of a thought graph, which encodes reusable reasoning steps as nodes within a directed, weighted graph. Nodes are interconnected by two types of edges: sequential edges, which capture the natural order of steps within templates, and semantic edges, which link semantically similar steps across different templates (Figure 1).
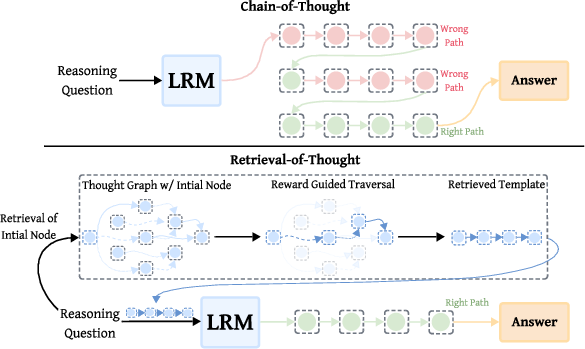
Figure 1: The figure contrasts Chain-of-Thought (CoT) inference in LRMs with our Retrieval-of-Thought (RoT) approach.
Semantic edges are established using cosine similarity between step embeddings, facilitating the retrieval of relevant reasoning steps for a given query. By leveraging a combination of reward-guided traversal and retrieval techniques, the RoT framework dynamically assembles problem-specific templates during inference (Figure 2).
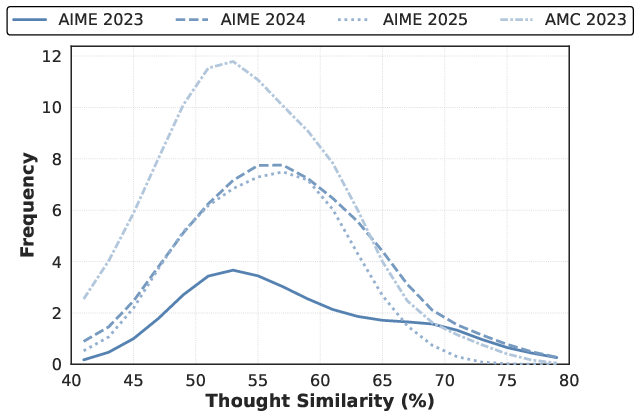
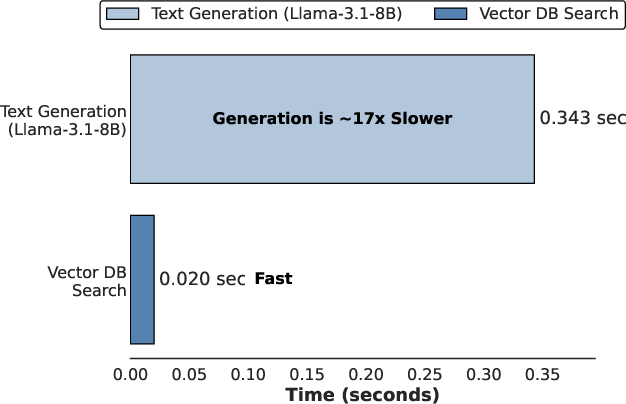
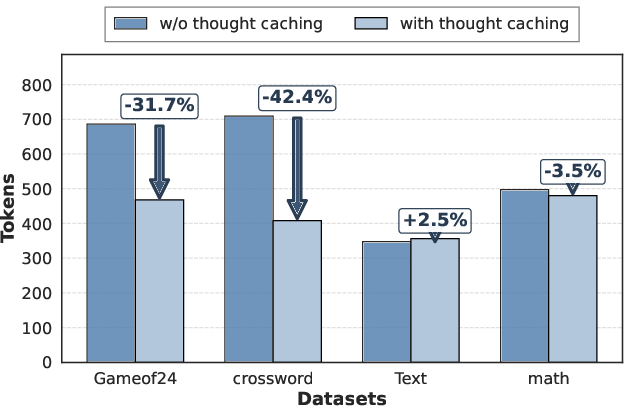
Figure 2: Key observations motivating the RoT framework.
The paper highlights substantial efficiency gains achieved through the RoT framework. Evaluations conducted across various reasoning benchmarks showed that RoT can reduce output tokens by up to 40%, inference latency by 82%, and cost by 59% while maintaining accuracy. Specifically, comparison with traditional Chain-of-Thought (CoT) methods shows that RoT consistently achieves higher efficiency by navigating directly to promising reasoning paths, thereby reducing unnecessary exploration and path switching (Figure 3).

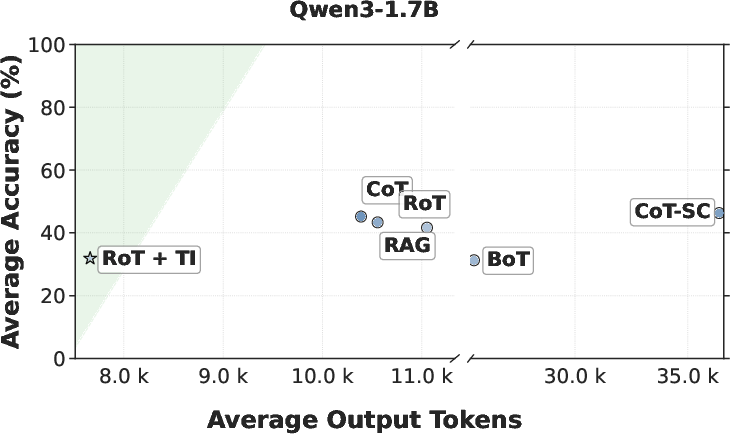
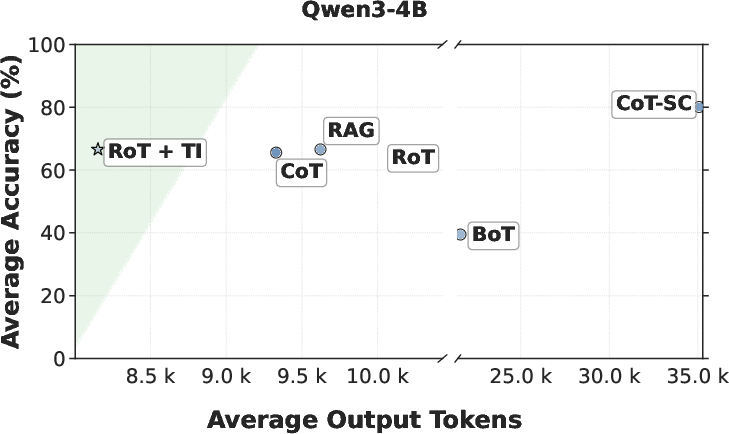
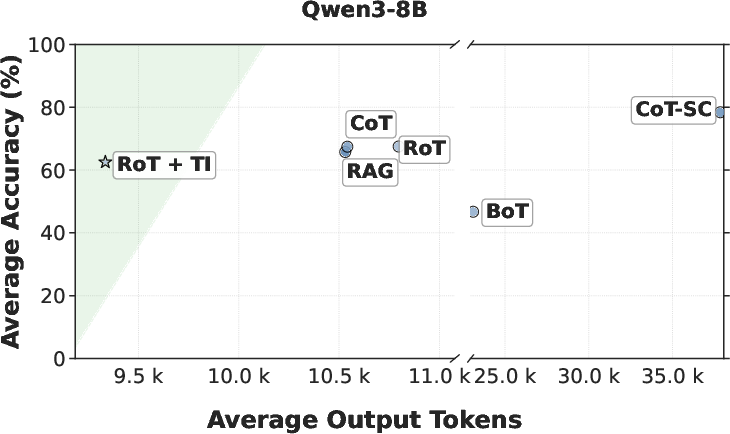
Figure 3: Average accuracy versus output tokens across Qwen3 models (1.7B, 4B, 8B).
Implementation of RoT involves low memory overhead and negligible latency contribution from the retrieval process, making it suitable for deployment alongside existing LRM infrastructures. The thought graph's scalability is demonstrated by increasing template numbers, showing performance improvements as graph size increases (Figure 4).
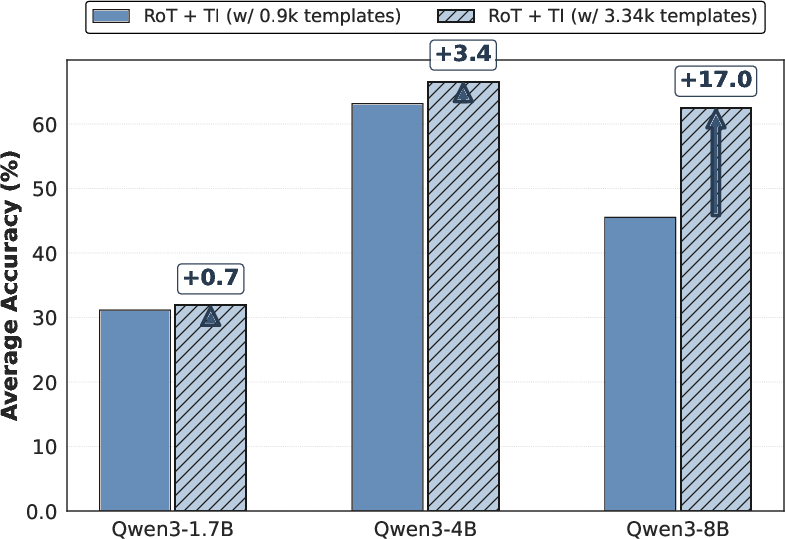
Figure 4: Template scalability analysis of RoT+TI.
Implications and Future Developments
The RoT framework offers a scalable foundation for efficient LRM reasoning, suggesting potential extensions beyond current mathematical domains. Its innovative use of dynamic retrieval and template assembly can provide a robust solution to the growing computational demands of reasoning-intensive AI applications. Future developments may focus on enhancing the adaptability of the thought graph across broader domain applications and refining the underlying retrieval mechanisms to further optimize performance metrics.
Conclusion
The Retrieval-of-Thought paradigm presents a promising advancement in efficient reasoning within Large Reasoning Models. By reusing structured reasoning steps as dynamically composable templates, RoT achieves significant reductions in output tokens and inference latency without sacrificing accuracy. The work provides a practical and scalable approach to addressing the high computational costs associated with reasoning-heavy inference, paving the way for broader applicability and refinement in intelligent systems.