MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Abstract: We introduce MinerU2.5, a 1.2B-parameter document parsing vision-LLM that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MinerU2.5, a smart computer system that can read and understand complex documents like PDFs and scanned pages. It focuses on “document parsing,” which means finding different parts of a page (like titles, paragraphs, tables, and formulas) and turning them into clean, editable text and structure. MinerU2.5 aims to be both very accurate and very fast, even on big, high-resolution pages with lots of content.
Key Questions the Paper Tries to Answer
Here are the main problems the researchers wanted to solve:
- How can we read high-resolution, busy pages quickly without missing tiny details?
- How can we avoid “hallucinations,” where the model makes up content that isn’t there?
- How can we handle tricky parts of documents—like rotated tables, long multi-line formulas, and mixed languages—reliably?
- How can we build a model that’s accurate but still small enough to run efficiently?
How MinerU2.5 Works
Think of parsing a page like exploring a giant picture:
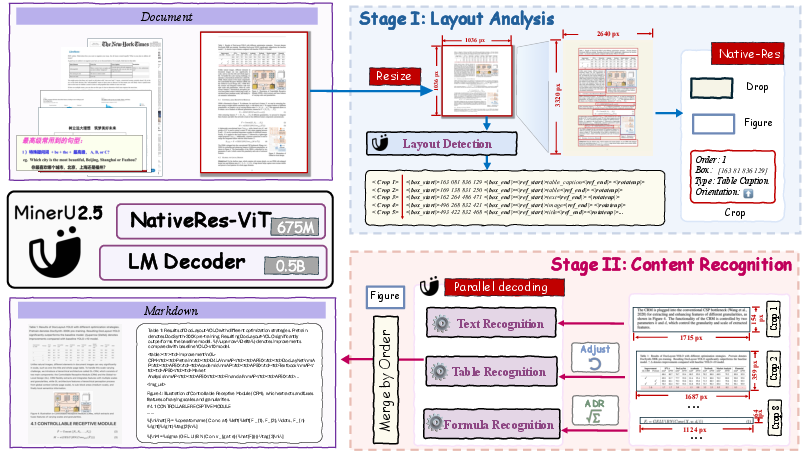
- Stage I is like looking at a zoomed-out map: the model analyzes a smaller version of the page to find the layout—where the titles, text blocks, tables, images, and formulas are located, and the order you should read them in.
- Stage II is like using a magnifying glass: the model zooms into each important area at the original high resolution and reads the content carefully (text, formulas, tables), keeping tiny details intact.
The Model’s Parts (in simple terms)
- Vision-LLM: A program that understands both images and text together.
- Vision encoder: The “eyes” that turn picture patches into numbers the model can understand. MinerU2.5 uses NaViT, which can handle images of many sizes without squishing or warping them.
- LLM: The “brain” that turns those numbers into words, LaTeX (for math), or table structures.
- Patch merger: A smart compressor that groups nearby image patches so the system runs faster without losing important detail.
Why Two Stages?
Big pages have lots of empty space (margins, gaps) that waste time if you process the whole image at full resolution. The two-stage approach:
- Saves time by only zooming in where needed.
- Keeps the global “big picture” of how the page is organized.
- Reduces mistakes and hallucinations.
- Makes the system easier to improve, because layout and reading can be tuned separately.
Training and Data: How They Made It Good
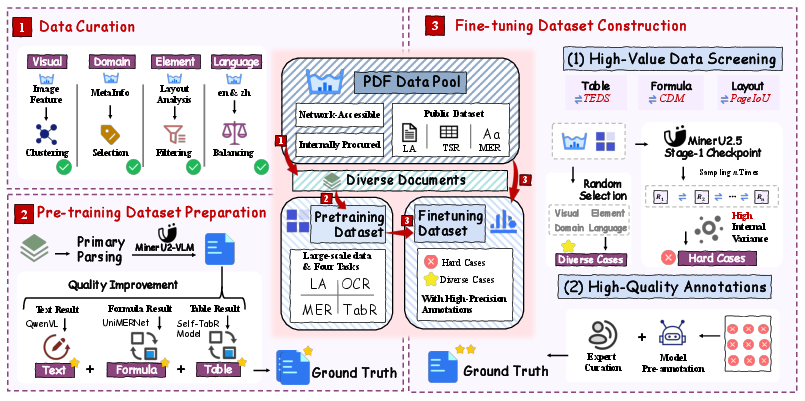
The team built a careful “data engine” to train MinerU2.5:
- Data curation: They selected a diverse set of documents in English and Chinese, balancing different layouts and types (papers, reports, books).
- Pre-training: They used large amounts of automatically labeled data—then improved those labels using strong expert models for text, tables, and formulas.
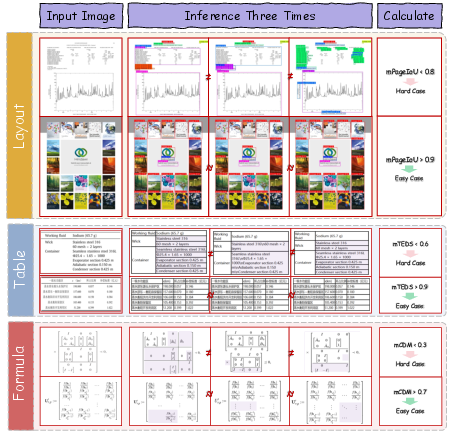
- Fine-tuning: They focused on “hard cases” (especially tricky pages) found using a method called IMIC. IMIC runs the model multiple times; if its answers don’t agree, that sample is likely challenging and worth careful human annotation.
Special Upgrades for Tough Tasks
MinerU2.5 doesn’t just do basic OCR. It has smart designs for specific hard problems:
- Layout analysis: It predicts position, category, rotation angle, and reading order together in one go. It uses a unified tagging system that includes headers, footers, page numbers, references, lists, code blocks, captions, and more—so the page is well-structured for downstream use.
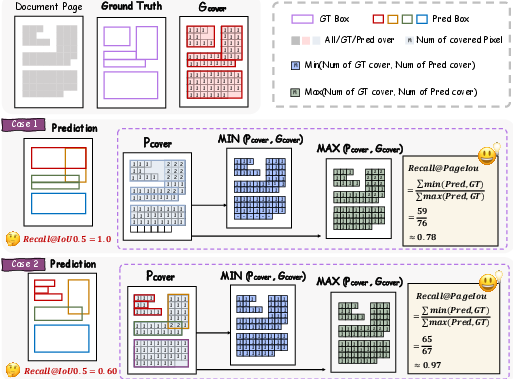
- PageIoU metric: Instead of only using box-matching scores, PageIoU measures how well the predicted areas cover the page like a colored overlay—this aligns better with what humans consider “good” layout detection.
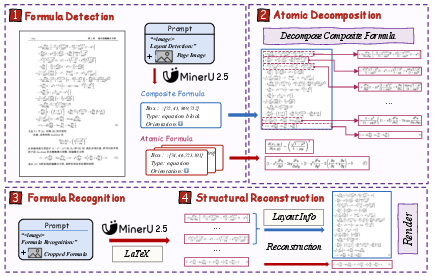
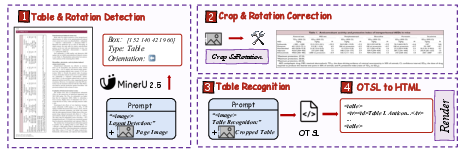
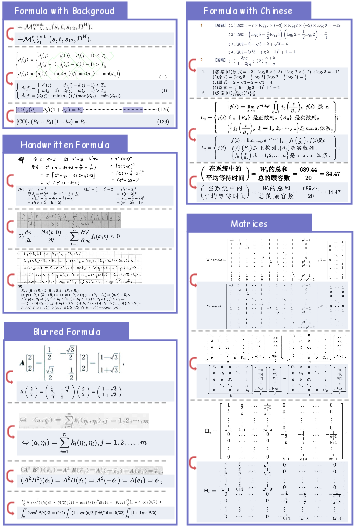
- Formula recognition (ADR framework): It breaks long, multi-line formulas into smaller “atomic” pieces, recognizes each piece, then stitches them back together. This reduces confusion and keeps complex math correct.
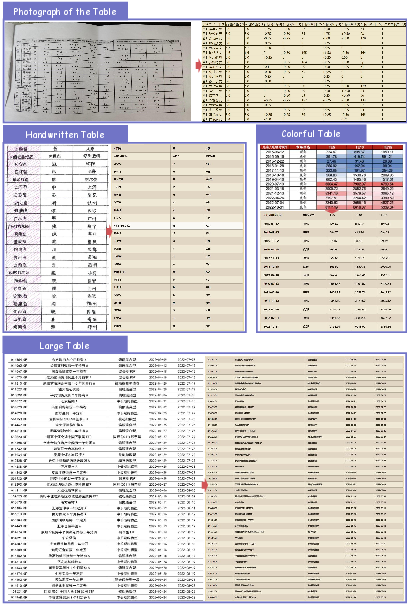
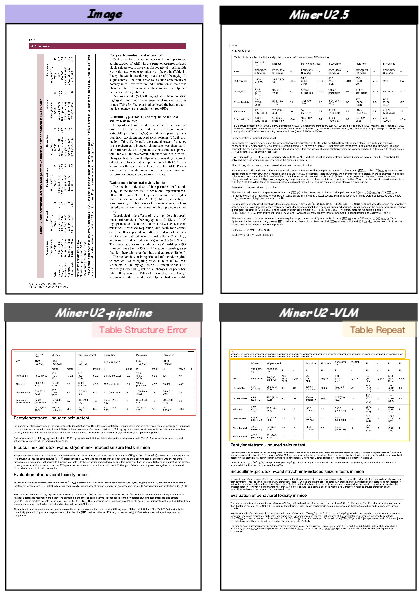
- Table recognition (OTSL): Instead of generating complex HTML directly, it first creates a simpler table-language called OTSL, which uses fewer tokens and matches table structure more directly. Then it converts OTSL to HTML.
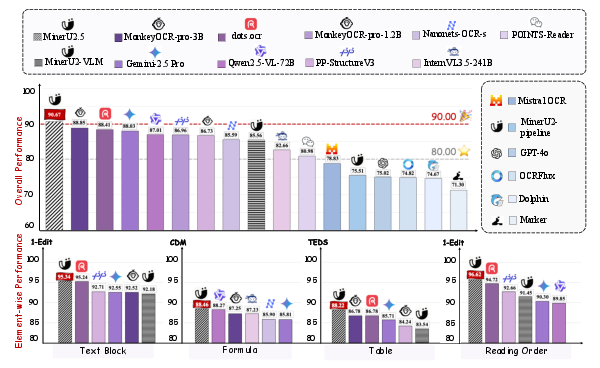
Main Results and Why They Matter
MinerU2.5 achieves state-of-the-art accuracy on multiple benchmarks, including OmniDocBench. It beats large, general models (like Gemini and GPT-4o) and specialized OCR models on:
- Text recognition
- Formula recognition
- Table recognition
- Reading order prediction
It is also fast. Even with a relatively small size (about 1.2 billion parameters), it processes pages at a high speed and uses fewer computing resources compared to bigger models. On standard hardware, it reads more pages per second than several popular systems.
This means MinerU2.5 is both powerful and practical.
What This Means for the Real World
- Faster digitization: It can turn PDFs and scans into clean, structured text and data more quickly.
- Better search and RAG: Because it organizes the page reliably (including headers, footers, captions, references), systems that use documents to answer questions can find better information.
- Reliable math and tables: Complex formulas and tricky tables become more accurate and easier to reuse or analyze.
- Lower costs: Because it runs efficiently, organizations don’t need huge servers to get great results.
- Fewer mistakes: The decoupled approach reduces hallucinations and makes results more trustworthy.
In short, MinerU2.5 shows that smart design—first finding the layout, then reading the details—can make document understanding both accurate and fast, helping schools, researchers, and businesses work with complex documents more easily.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to be actionable for future research:
- Two-stage sensitivity and error propagation: No quantitative analysis of how Stage I layout errors (mislocalized boxes, wrong class, rotation, or reading order) degrade Stage II recognition; no uncertainty propagation, confidence calibration, or fallback strategies (e.g., auto-escalation to bigger crops or whole-page parsing).
- Thumbnail and crop hyperparameters: The fixed Stage I thumbnail size (1036×1036) and Stage II crop upper bound (“2048 × 28 × 28”) are justified qualitatively but lack systematic tuning and sensitivity studies across diverse page sizes, densities, and layouts.
- Ablations of architectural choices: Missing controlled ablations for key design decisions (NaViT vs. window attention; M-RoPE vs. 1D-RoPE; 2×2 pixel-unshuffle patch merger; dynamic repetition penalties; asynchronous scheduling) to quantify their individual impact on accuracy, speed, and stability.
- Efficiency–accuracy trade-offs: No explicit scaling laws or curves showing token reduction vs. accuracy across page complexity, number of crops, and crop sizes; unclear if the approach still becomes impractical for extremely dense or long documents.
- Multi-page and cross-page structures: Reading order and layout analysis appear page-bound; open question on handling cross-page elements (tables continued across pages, figure–caption separation, multi-page references), and document-level reading order.
- Language coverage beyond Chinese–English: Unclear robustness to non-Latin scripts (Arabic/Hebrew RTL, Devanagari, Thai), vertical writing, mixed scripts, and low-resource languages; no multilingual benchmarks reported.
- Handwritten and cursive content: No evaluation or strategy for handwritten notes, annotations, or mixed print–handwriting documents common in reports, forms, and archival scans.
- Figures, charts, and chemical structures content: While categories exist in layout tags, there is no content extraction (e.g., chart data recovery, diagram-to-structured representation, caption–figure linking) evaluation or pipeline.
- Table cell text OCR quality: Structure recognition (OTSL→HTML) is addressed, but end-to-end evaluation of cell text accuracy, cell alignment semantics, header hierarchies, merged cells, multi-line cell content, and numeric formatting is missing.
- OTSL→HTML fidelity and edge cases: No quantitative assessment of conversion correctness for complex spanning patterns, nested headers, nested tables, footnotes anchored to cells, or rotated/vertical text within cells.
- Formula ADR recombination fidelity: No evaluation of whether line-wise LaTeX recombination preserves mathematical semantics (alignment anchors, equation numbering/tags, environments, interline references, multi-column equations).
- Metrics coverage and validation: PageIoU is proposed but lacks broader validation (correlation with human judgements, sensitivity to box granularity, class-specific analyses) and comparison to alternative layout metrics; formula CDM and table TEDS usage lacks explicit error taxonomies.
- Reading order evaluation: The paper claims improvements but does not detail standardized metrics, benchmarks, or error analyses for reading order quality (especially in multi-column, figure–caption interleaving, or list/algorithm blocks).
- Hallucination mitigation evidence: Claims of reduced hallucination are not backed by quantitative measures (e.g., hallucination rate per task, qualitative taxonomy, correlation with confidence estimates).
- Robustness to real-world degradations: Although augmentations are defined, there is no stress testing under real-world conditions (camera-captured pages, skew, warping, folds, extreme blur/noise, glossy reflections) nor ablations on augmentation contributions; notably, spatial transforms are excluded for layout training without empirical justification.
- IMIC hard-case mining validation: The stochastic consistency criterion may select noisy/ambiguous samples; there is no study of threshold selection, precision/recall of “hardness,” diversity of mined cases, or measured gains vs. random sampling; risk of overfitting to idiosyncratic ambiguities remains.
- Data engine bias and provenance: Heavy reliance on proprietary/foundation models (Qwen2.5-VL-72B, Gemini-2.5 Pro) for refinement introduces label bias; no quantification of label noise, inter-model disagreement, or downstream bias; limited transparency on licensing, privacy, and release of training data for reproducibility.
- Generalization across domains: Evaluation is largely on OmniDocBench; missing tests on business documents (invoices, receipts, forms), legal contracts, medical records, financial statements, historical archives, educational exams, and presentation slides in diverse formats.
- Deployment on constrained hardware: Throughput is evaluated on high-end GPUs (A100/H200/4090 48G); no results on consumer GPUs with 8–24GB VRAM, CPU-only environments, mobile/edge devices, memory footprint, or energy consumption.
- End-to-end latency accounting: vLLM startup overhead is excluded and pipeline latency breakdowns (cropping, rotation correction, I/O, scheduling) are not reported; lack of tail-latency and batch-size sensitivity analyses for production SLAs.
- Confidence and quality control: No per-element confidence scores, calibration, or QA hooks to drive human-in-the-loop review, selective re-parsing, or automated rejection for low-confidence outputs.
- Security and privacy: Use of commercially procured documents and human annotation raises unanswered questions on PII handling, anonymization, access controls, and compliance; absent threat-model or privacy-preserving training/inference strategies.
- Downstream task impact: Claims of benefits for RAG and intelligent document analysis lack empirical demonstrations (e.g., RAG answer accuracy, retrieval recall, auditability) with parsed outputs vs. baselines.
- Standardization of tags and interoperability: The proposed tagging system’s interoperability with existing schemas (e.g., DocAI, TEI, PDF standards) is not explored; migration pathways and tool support for broader adoption remain open.
- Error taxonomy and qualitative analysis: No systematic breakdown of failure modes per task (layout, table, formula, text), their frequencies, and targeted mitigation strategies informed by error analyses.
- Reproducibility of training recipe: Key training datasets (6.9M pre-training samples, 630K fine-tuning) and curation details are not fully public; open question on replicability of results with accessible data and models.
These gaps suggest concrete directions for future work, including rigorous ablations, multilingual and multi-page evaluations, comprehensive end-to-end metrics, confidence-calibrated pipelines, and broader domain coverage under realistic deployment constraints.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, supported by the paper’s demonstrated performance, open-source release, and deployment details.
- Enterprise document ingestion and RAG pipelines (software, finance, legal, insurance)
- What: High-throughput parsing of PDFs and scans into structured JSON/HTML, including reading order, tables (HTML/CSV via OTSL), and LaTeX for formulas; ingestion into vector databases and knowledge graphs.
- Why now: Proven state-of-the-art accuracy and 2–4× throughput gains vs. strong baselines; decoupled layout→content recognition reduces hallucinations and token waste in long, high-res documents.
- Tools/workflows: MinerU2.5 service (vLLM backend), ETL jobs, REST API for batch pages, table OTSL→HTML/CSV converter, formula LaTeX generator; dynamic sampling penalties tuned by element type as described.
- Assumptions/dependencies: GPU inference (e.g., RTX 4090 48G, A100/H200) for best throughput; strongest results in Chinese/English; quality depends on input scan resolution; licensing of model/data must align with enterprise policies.
- Contract analytics and compliance review (legal, finance, procurement)
- What: Preserve headers/footers/page numbers and reading order for accurate clause extraction, cross-references, and redaction workflows.
- Why now: The unified tagging system captures non-body elements often missed by pipelines; two-stage design improves reliability on dense, multi-column layouts.
- Tools/workflows: Clause extraction + RAG; layout-aware redaction tool; audit trails from Stage I/II outputs.
- Assumptions: Domain adaptation may be needed for non-standard forms/handwriting; privacy governance for on-prem deployment.
- Scientific publishing and archive conversion (academia, publishing, open science)
- What: PDF-to-LaTeX/HTML conversion with high-fidelity formula extraction (ADR), robust table parsing (OTSL), and clean reading order for long/complex papers.
- Why now: Demonstrated breakthroughs in formula parsing and table recognition (rotated/borderless/partial borders).
- Tools/workflows: Automated arXiv/publisher backfile conversion; LaTeX equation recovery; structured references and lists extraction.
- Assumptions: Images/figures still require specialized figure/diagram understanding if semantic extraction is needed.
- Accessibility enhancement for screen readers (education, public sector, publishing)
- What: Generate linearized HTML with correct reading order, identify captions/footnotes, and convert formulae to MathML (via LaTeX) to improve assistive technologies.
- Why now: Decoupled layout analysis yields reliable reading order and non-body element capture.
- Tools/workflows: PDF→Accessible HTML pipeline; ARIA tagging postprocessor; alt-text LLM integration optional.
- Assumptions: MathML generation step required (LaTeX→MathML converter); accessibility review still recommended.
- Financial operations and back-office automation (finance, logistics, retail)
- What: Structured extraction from invoices, statements, manifests, and catalogs, including robust tables even when rotated or borderless.
- Why now: OTSL-based parsing halves sequence length vs HTML targets, improving accuracy and speed for large/complex tables.
- Tools/workflows: OCR microservice returning JSON+CSV; confidence scoring via sampling consistency; exception routing.
- Assumptions: Domain layouts vary; limited handwriting support; ensure currency/locale normalization.
- E-discovery and records management (legal, public sector)
- What: Bulk parsing of scanned records preserving headers/footers/page numbers; reading order reconstruction for accurate downstream search and summarization.
- Why now: High page throughput enables timely case processing; PageIoU metric can monitor layout coverage quality at-scale.
- Tools/workflows: Batch ingestion, PageIoU-based QC dashboards, legal hold pipelines.
- Assumptions: Severe degradations (fax/noise) may require pre-cleaning; privacy and chain-of-custody constraints.
- Rapid enterprise QA/summarization on policy and procedure documents (software, HR, operations)
- What: Low-latency extraction of structured sections and lists to feed policy chatbots and compliance checks.
- Why now: vLLM optimizations and decoupled stages reduce end-to-end latency and hallucination risk.
- Tools/workflows: Section-aware summarizers; retrieval built on structured segments; per-element sampling penalties as in deployment section.
- Assumptions: Guardrails still needed for downstream generation.
- Localization/translation with layout preservation (localization, publishing)
- What: Extract text by blocks with layout metadata and reflow post-translation while preserving math (via LaTeX) and table structures (OTSL/HTML).
- Why now: Fine-grained tagging (captions, lists, code, algorithms) supports targeted translation policies.
- Tools/workflows: CAT/MT pipeline with structure-preserving post-editing; formula passthrough.
- Assumptions: Non-Latin scripts beyond Chinese/English may need adaptation; QA for typography/line-breaking.
- Data curation and model improvement loops (ML ops in academia/industry)
- What: Use IMIC to mine “hard cases” via inference consistency and prioritize human annotation; use Dingo-like QA tooling for efficient review.
- Why now: IMIC is directly applicable with MinerU2.5 outputs; improves dataset quality without exhaustive labeling.
- Tools/workflows: Active-learning pipeline with PageIoU (layout), TEDS (tables), CDM (formulas).
- Assumptions: Annotation workforce; governance over source data; storage for intermediate artifacts.
- Benchmarking and evaluation modernization (academia, standards bodies)
- What: Adopt PageIoU to better align layout evaluation with human judgment at page level.
- Why now: Clear mismatch of IoU-based metrics shown; PageIoU is simple to compute from coverage maps.
- Tools/workflows: Replace/augment mAP dashboards; evaluate reading-order and rotation jointly per the multi-task paradigm.
- Assumptions: Community/organization buy-in; metric standardization process.
- Developer products and APIs (software)
- What: Offer a MinerU2.5-powered “Document to Structured JSON” API; microservices for Table (OTSL→HTML/CSV) and Formula (LaTeX via ADR).
- Why now: Open model and code available; straightforward deployment via vLLM with suggested scheduling parameters.
- Tools/workflows: Containerized services; SDKs for Python/JS; batch and streaming endpoints.
- Assumptions: GPU availability; cost modeling for throughput tiers.
- Personal knowledge management and study aids (daily life, education)
- What: Convert lecture PDFs/notes into searchable, structured notes; extract LaTeX for practice; clean tables to CSV for analysis.
- Why now: Efficient on single-GPU workstations; robust on dense academic PDFs.
- Tools/workflows: Desktop app with local inference; Obsidian/Notion importers.
- Assumptions: Consumer GPUs for best UX; privacy-sensitive content stays local.
Long-Term Applications
These require further research, scaling to additional domains/languages, or engineering for broader deployment footprints.
- Multilingual, handwriting, and low-resource scripts expansion (education, public sector, global enterprises)
- What: Extend MinerU2.5 to diverse scripts (Arabic, Devanagari, Cyrillic, etc.) and handwriting-heavy documents.
- Dependencies: Additional data curation via IMIC, targeted augmentation, and fine-tuning; potential specialized handwriting modules.
- Mobile and edge deployment (software, field operations, logistics)
- What: On-device parsing for mobile scanning apps and edge appliances.
- Dependencies: Aggressive quantization, distillation of the 1.2B model, optimized runtimes (WASM/NNAPI), CPU/ARM kernels; memory-aware crop orchestration.
- Domain-specific parsing of technical drawings and hybrid pages (engineering, energy, manufacturing)
- What: Integrate layout+content parsing with figure/diagram understanding (CAD schematics, P&IDs, charts).
- Dependencies: Additional vision modules for vector graphics/diagrams; expanded tagging schema and metrics.
- Healthcare document understanding with regulatory compliance (healthcare)
- What: Robust parsing for scanned medical records, lab reports, and guidelines; structure-preserving de-identification.
- Dependencies: HIPAA/GDPR-compliant on-prem deployments; strong noise/scan robustness; medical vocabularies and forms; human-in-the-loop validation.
- Chemistry and materials literature mining (pharma, materials)
- What: Combine chemical_structure tags with formula and table parsing for reaction conditions and property tables.
- Dependencies: Chemical OCR/diagram recognition integration; entity normalization; domain ontologies.
- Standardization of evaluation metrics and schemas (policy, standards bodies)
- What: Institutionalize PageIoU and unified layout tagging in procurement and compliance benchmarks.
- Dependencies: Community consensus, reference implementations, inter-annotator agreement studies.
- Autonomous document process orchestration (RPA + structured OCR)
- What: End-to-end workflows that trigger actions (filing, approvals, payments) based on parsed structure and content.
- Dependencies: Robust error detection via IMIC-like uncertainty; guardrails; integration with BPM/RPA systems.
- Math-aware knowledge bases and search (academia, edtech)
- What: Build large-scale, clean math corpora with faithful LaTeX and aligned text for math-aware retrieval and tutoring.
- Dependencies: ADR scaled to very long derivations; LaTeX→semantic MathML conversion; evaluation datasets.
- Privacy-preserving collaborative data engines (ML ops)
- What: Federated IMIC pipelines to mine hard cases without centralizing sensitive documents.
- Dependencies: Federated learning infrastructure; privacy-preserving metrics/aggregation; policy alignment.
- Increased robustness to extreme degradations and layout anomalies (archives, government)
- What: Handle torn pages, bleed-through, heavy skew, marginalia, stamps.
- Dependencies: Augmentation and specialized pre-processing; adaptive crop strategies; uncertainty-aware fallbacks.
- Cost-optimized cloud services at scale (software)
- What: Multi-tenant services with dynamic batching, elastic scaling, and SLA tiers.
- Dependencies: Scheduler advances beyond current vLLM tuning; autoscaling logic; cost/performance simulators.
Cross-Cutting Assumptions and Dependencies
- Compute: Best-in-class throughput achieved on high-memory GPUs (4090 48G, A100/H200). CPU-only or low-VRAM scenarios need optimization.
- Languages: Strongest results in Chinese/English; other languages and handwriting need data and fine-tuning.
- Input quality: Very low-quality scans may require pre-processing (deskew, denoise).
- Governance: Data licenses, PII handling, and regulatory compliance must be addressed for production.
- Integration: Downstream systems benefit from the two-stage outputs (layout JSON + per-crop recognition), but require adapters into existing ETL, RPA, and search stacks.
- Reliability: While the decoupled approach reduces hallucinations, production systems should incorporate confidence thresholds, IMIC-driven active learning, and human review for high-stakes use.
Glossary
- 1D-RoPE: One-dimensional Rotary Position Embedding used to encode token positions in sequence models. "replace the original 1D-RoPE~\cite{su2024roformer} with M-RoPE~\cite{wang2024qwen2}"
- 2D-RoPE: Two-dimensional Rotary Position Embedding for encoding spatial positions in image tokens. "and employs 2D-RoPE for positional encoding"
- ADR (Atomic Decomposition and Recombination): A multi-stage formula recognition framework that decomposes compound formulas into atomic lines, recognizes them, and recombines the results structurally. "The Atomic Decomposition {paper_content} Recombination (ADR) Framework."
- Atomic Formulas: Indivisible semantic units of mathematical expressions that form the basic components of compound formulas. "Atomic Formulas: The smallest, indivisible semantic units with a tight 2D topology (e.g., a single fraction, a matrix)."
- CDM: A metric used to assess consistency or similarity of mathematical formula outputs across runs. "consistency is assessed using the pairwise CDM~\cite{wang2025image}"
- Compound Formulas: Multi-line or composed mathematical expressions made from ordered atomic formulas. "Compound Formulas: An ordered set of atomic formulas composed vertically with specific alignment relationships (e.g., a multi-line derivation aligned at the equal signs)."
- frequency_penalty: A decoding parameter that reduces repetition by penalizing tokens proportional to their frequency in the output. "we dynamically adjust sampling parameters like frequency_penalty and presence_penalty in Stage~II"
- IMIC (Iterative Mining via Inference Consistency): A strategy to mine hard samples by measuring the consistency of multiple stochastic inference outputs. "we introduce the IMIC (Iterative Mining via Inference Consistency) strategy."
- mAP (mean Average Precision): A standard object detection metric summarizing precision-recall performance across classes and thresholds. "Layout analysis is typically evaluated with object detection metrics like mAP"
- M-RoPE: A modified Rotary Position Embedding variant enhancing generalization for varying resolutions/aspect ratios in vision-LLMs. "replace the original 1D-RoPE~\cite{su2024roformer} with M-RoPE~\cite{wang2024qwen2}"
- NaViT: A Vision Transformer variant that supports dynamic, native image resolutions and aspect ratios. "we employ a 675M-parameter NaViT~\cite{dehghani2023patch} initialized from Qwen2-VL."
- Native-resolution approaches: Methods that process images at their original resolution to preserve fine-grained details. "Native-resolution approaches~\cite{bai2025qwen2,guo2025seed1,dots.ocr,niu2025native} preserve fine-grained details"
- OCR 2.0: A unified OCR paradigm that jointly handles text, formulas, tables, and charts within one framework. "pioneered the OCR 2.0 paradigm"
- OTSL (Optimized Table-Structure Language): A compact intermediate representation for table structures that reduces token redundancy and sequence length. "we leverage the Optimized Table-Structure Language (OTSL)~\cite{lysak2023optimized}, an intermediate representation"
- PageIoU: A page-level coverage metric measuring spatial consistency between predicted and ground-truth layouts. "we introduce PageIoU, a page-level coverage metric"
- Patch Merger: A component that aggregates vision tokens (often with an MLP adaptor) to reduce token counts before feeding them to the LLM. "Only the two-layer MLP within the patch merger is trained"
- Pixel-unshuffle: An operation that rearranges pixels to merge neighboring patches, lowering spatial resolution while increasing channel depth. "uses pixel-unshuffle~\cite{shi2016real} on adjacent 2 × 2 vision tokens"
- presence_penalty: A decoding parameter that discourages reuse of previously generated tokens to increase output diversity. "we dynamically adjust sampling parameters like frequency_penalty and presence_penalty in Stage~II"
- RAG (Retrieval-Augmented Generation): A technique where external retrieved documents augment a model’s context to improve generation. "Retrieval-Augmented Generation (RAG)~\cite{lin2024revolutionizing,zhang2024ocr,zhao2024retrieval}"
- Reading order prediction: Determining the sequence in which document elements should be read to preserve semantic flow. "reading order prediction"
- Swin-Transformer: A hierarchical vision transformer using shifted windows for efficient local attention. "Dolphin \citep{feng2025dolphin} employs a Swin-Transformer VLM"
- TEDS (Tree-Edit-Distance-based Similarity): A similarity metric for table structure outputs based on tree edit distance. "we use the TEDS (Tree-Edit-Distance-based Similarity) score"
- Token redundancy: Excess visual tokens from low-information regions that inflate computation without improving accuracy. "token redundancy, arising from large blank or low-information regions within the document image."
- vLLM: A high-throughput inference and serving engine for LLMs. "We implement an efficient offline inference pipeline for MinerU2.5 based on vLLM~\citep{kwon2023efficient}."
- Visual Instruction Tuning: Fine-tuning a model to follow natural-language instructions for visual tasks. "Visual Instruction Tuning."
- Visual Question Answering (VQA): A task requiring models to answer questions about images, used here for modality alignment. "modality alignment training on Visual Question Answering (VQA) datasets."
- Window attention: An attention mechanism restricted to local windows to improve efficiency on high-resolution inputs. "adopts window attention to improve efficiency"
Collections
Sign up for free to add this paper to one or more collections.