- The paper presents a hierarchical framework that composes distinct RL policies to achieve long-horizon basketball control with robust skill transitions.
- It introduces an intermediate policy for Type C transitions, enabling smooth integration between disparate motions like dribbling and shooting.
- Experiments demonstrate high success rates (98.3% ball catching, 91.8% shot percentage) and outperformance over baselines via soft routing.
Policy Composition for Long-Horizon Basketball Control
Introduction and Motivation
This work addresses the challenge of synthesizing physically plausible, long-horizon basketball behaviors in simulated agents by composing heterogeneous motor skills via reinforcement learning (RL). The central technical problem is the seamless integration of distinct skills—such as dribbling, gathering, and shooting—where intermediate transitions are ill-defined and cannot be handled by standard skill chaining or mixture-of-experts approaches. The authors propose a hierarchical policy integration framework that enables robust transitions between skills, even when the initial and terminal state distributions of subtasks are disjoint or ambiguous. The framework is demonstrated on a suite of basketball tasks, including shoot-off-the-dribble, catch-and-shoot, and multi-agent interactions.
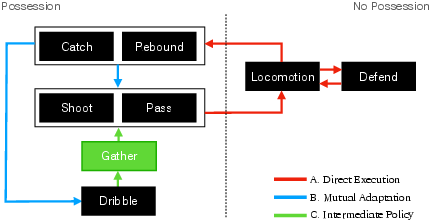
Figure 1: The simulated character executes seven basketball skills, with transitions categorized by increasing difficulty; the most challenging (Type C) requires an intermediate policy to bridge incompatible skills.
Transition Taxonomy and Policy Integration
The paper introduces a taxonomy of skill transitions:
- Type A (Direct Execution): Succeeding policy can be executed directly from the terminal state of the preceding policy.
- Type B (Mutual Adaptation): Both policies are adapted to each other's state distributions.
- Type C (Intermediate Policy): An explicit intermediate policy is required to bridge incompatible state distributions.
The focus is on Type C transitions, exemplified by the dribble-to-shoot maneuver, where the agent must gather the ball from arbitrary dribbling states and prepare for a shot. The proposed solution is to:
- Train primitive policies for well-defined subtasks (e.g., dribbling, shooting) independently.
- Train the intermediate policy (e.g., gathering) using:
- The terminal states of the preceding policy as the initial state distribution.
- The value function of the succeeding policy for reward shaping.
- Simultaneously adapt the succeeding policy (e.g., shooting) to the state distribution induced by the intermediate policy, updating its value function in tandem.
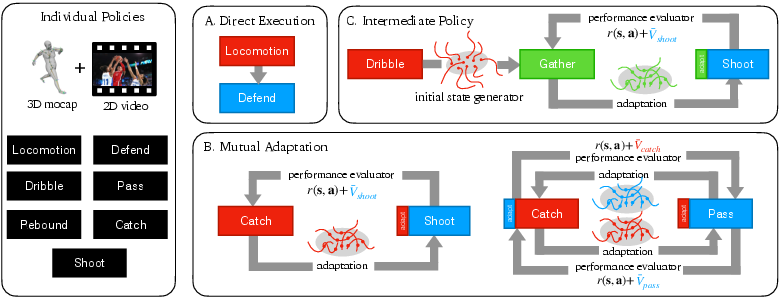
Figure 2: Illustration of transition types; Type C requires an intermediate policy trained with initial states from the preceding policy and reward shaping from the succeeding policy’s value function.
This approach is generalizable: Type A transitions require no adaptation, Type B transitions require only mutual adaptation and value-based reward shaping, and Type C transitions require explicit intermediate policy learning.
Learning from Unstructured Motion Data
A significant contribution is the ability to learn robust primitive policies from unstructured, heterogeneous motion data, including 3D mocap, 2D video, and hand-only recordings, without requiring ball trajectory references or correspondence between body and hand motions. The system architecture decouples full-body motions into body and hand components, enabling flexible imitation learning via adversarial RL (AMP/ICC-GAN style) and multi-objective reward functions.
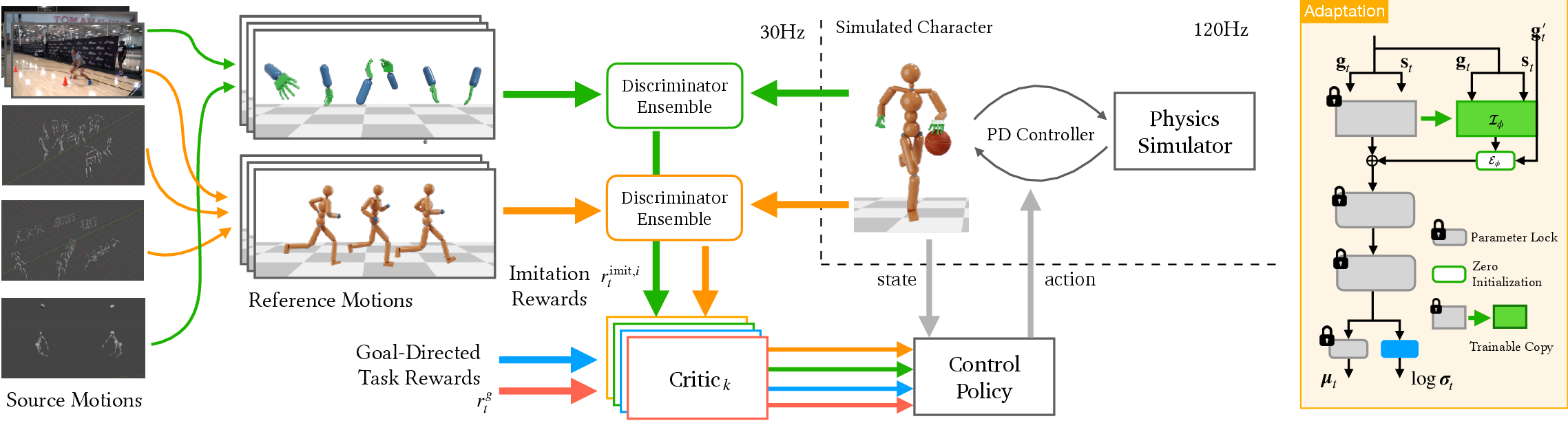
Figure 3: System architecture for primitive policy learning; body and hand motions are decoupled, and RL is used to imitate unstructured motions from disparate sources.
The dribbling policy is trained with a combination of navigation and dribbling rewards, with explicit violation detection for basketball rules (e.g., traveling, invalid contacts). The shooting policy is trained with full-body imitation and task-specific rewards for shot accuracy and ball-holding.
High-Level Soft Routing for Policy Composition
To automate transitions and avoid brittle, heuristic switching, a high-level soft routing policy is introduced. This policy takes as input the user command, current state, and goal vector, and outputs weights for a linear combination of the primitive policy actions. The routing policy is trained to encourage one-hot-like weights, ensuring that at each timestep, a single primitive policy dominates, but allowing for smooth blending during transitions.
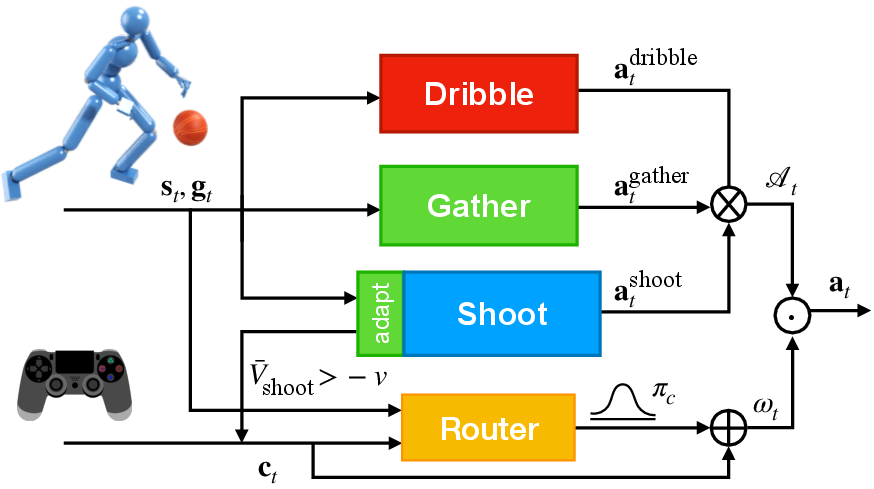
Figure 4: High-level routing policy architecture; user commands and state are mapped to weights for soft composition of primitive policy actions.
This soft routing approach outperforms both hard routing (discrete switching) and heuristic rule-based switching, yielding higher ball catching rates and shot percentages.
Experimental Results
Quantitative Evaluation
The framework is evaluated on the shoot-off-the-dribble task, with two primary metrics:
- Ball Catching Rate: Success in gathering and holding the ball after a shooting command.
- Shot Percentage: Ratio of successful field goals to attempts, including failures due to unsuccessful transitions.
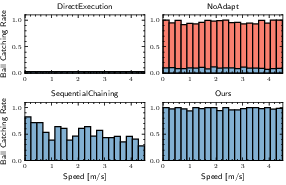
Figure 5: Ball catching rates as a function of dribbling speed; the proposed method achieves consistently high rates, outperforming all baselines.
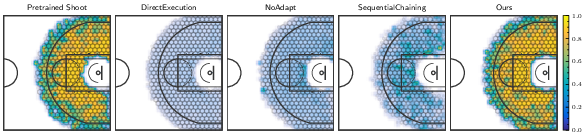
Figure 6: Heatmap of shot percentages across court positions and approach directions; the proposed method achieves 91.8% accuracy, nearly matching the vanilla shooting policy initialized from reference states.
The method achieves a 98.3% ball catching rate and 91.8% shot percentage across a wide range of dribbling speeds and approach directions, substantially outperforming baselines such as Direct Execution, NoAdapt, and SequentialChaining. Notably, direct application of the pretrained shooting policy to dribbling states yields catastrophic failure (<2% shot percentage), highlighting the necessity of the proposed integration strategy.
Qualitative Results and Multi-Agent Scenarios
The system demonstrates robust transitions for a variety of skills, including rebounding, passing, catching, and defending, as well as multi-agent cooperative and competitive behaviors.

Figure 7: Cooperative behaviors between two characters, including passing-off-the-dribble and shooting-off-the-catching, achieved via policy adaptation and composition.

Figure 8: Four characters controlled by human players via the learned policies in a real-time 2-on-2 competition.
Ablation Studies
Ablation experiments confirm the necessity of:
- State-value-based reward shaping for intermediate policy training.
- Simultaneous adaptation of the succeeding policy during intermediate policy training.
- Soft routing in the high-level policy for effective composition.
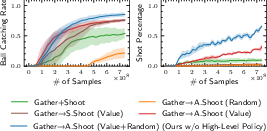
Figure 9: Learning performance with different intermediate policy training strategies; value-based transfer and adaptation yield superior results.
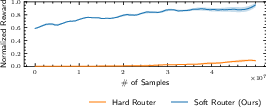
Figure 10: Soft routing outperforms hard routing and heuristic switching in learning performance.
Implementation Considerations
- RL Algorithm: PPO is used for all policy training, with adversarial imitation learning for motion imitation.
- Data Requirements: The approach is robust to unstructured, partial, and heterogeneous motion data, reducing the need for curated datasets.
- Computational Resources: Training requires large-scale parallel simulation (e.g., 512+ environments in IsaacGym), but inference is efficient, especially after policy distillation.
- Policy Distillation: The hierarchical policy can be distilled into a single network for deployment without loss of performance.
Limitations and Future Directions
The synthesized motions, while robust and plausible, do not yet match the fluidity and skill of expert human players, primarily due to limited reference data and simplified hand models. The approach is agnostic to character morphology and can be extended to different body types and skill levels via appropriate reference data. Future work could incorporate biomechanically accurate hand models and leverage LLMs for high-level tactical planning in multi-agent scenarios.
Conclusion
This paper presents a hierarchical policy integration framework for composing RL policies in long-horizon, multi-phase tasks with ill-defined intermediate transitions, demonstrated on complex basketball behaviors. The method achieves high success rates in challenging transitions, is robust to unstructured motion data, and generalizes to multi-agent settings. The approach advances the state of the art in skill composition for physics-based character control and provides a foundation for future research in dynamic, interactive environments.