- The paper introduces a conformal risk control mechanism that provides probabilistic assurances for LLM outputs to mitigate issues like hallucinations.
- It employs Batched Bootstrap CRC and Randomized Weighted-Average CRC to improve calibration stability and reduce computational costs.
- Semantic quantification via Gram matrix geometry enables label-free, interpretable assessments of model outputs, enhancing factual accuracy in QA tasks.
Introduction to CRC for LLMs
The paper introduces a method to manage the stochastic nature of LLMs by implementing a Conformal Risk Control (CRC) mechanism. This approach provides probabilistic assurances on output reliability, particularly in mitigating issues like hallucinations and evaluation inconsistencies. By employing a model-agnostic actuator at the API interface, CRC transforms the inherent randomness of LLMs into finite-sample guarantees without requiring explicit labels, thus ensuring vendor-independent control of variability.
The proposed Conformal Actuator (CA) is a monotonic gating mechanism that utilizes outputs' scalar scores to direct actions such as shipping, abstaining, or escalating responses. This mechanism grounded on CRC applies Batched Bootstrap CRC (BB-CRC) and Randomized Batched Weighted-Average CRC (RBWA-CRC) to enhance computational efficiency and threshold stability. With these methods, CRC reduces unnecessary recalibration calls and maintains statistical validity in finite samples.
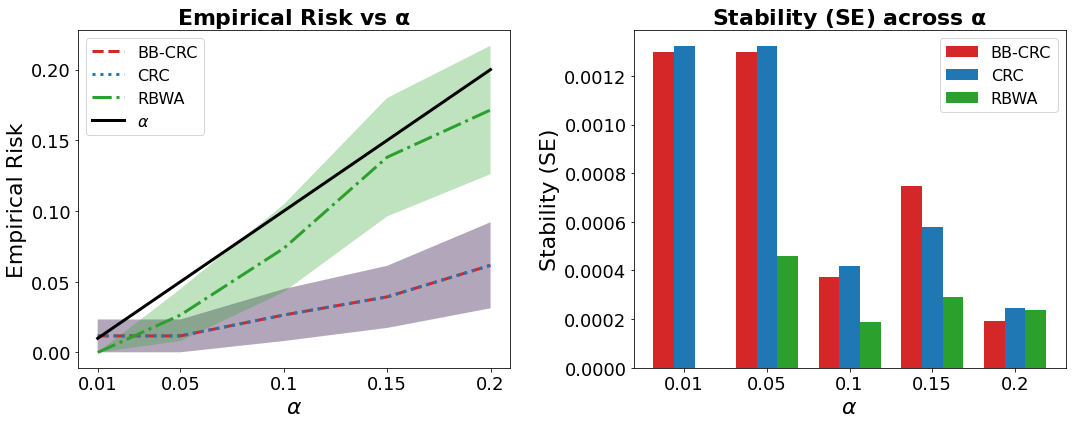
Figure 1: Calibration comparison. Left: Empirical risk at the calibrated threshold versus α. Right: Stability versus α. RBWA shows superior stability.
Gram Space Geometry for Output Evaluation
The paper introduces a semantic quantification approach based on Gram matrix geometry. Utilizing unit-norm embeddings of model outputs, the method derives interpretable metrics for assessing decision sufficiency and per-item uncertainty. Two core capabilities are highlighted: (1) semantic sufficiency via spectral-overlap decisions in leading Gram subspaces, and (2) per-item quantification using intrinsic energy scores. This theoretical approach provides an efficient and label-free mechanism for batch evaluations.
Implementation: BB-CRC and RBWA-CRC
BB-CRC and RBWA-CRC implement advanced calibration strategies that utilize either batch bootstrapping or randomized weights across batches. These methods uphold finite-sample bounds while reducing computational costs. Noteworthy, the RBWA-CRC increases calibration stability through unbiased smoothing and variance control, providing more consistent thresholding compared to standard CRC methods.
Experimental Evaluation
Experiments across multiple question-answering datasets, including ASQA and HotpotQA, exhibit the proposed framework's efficacy in improving factual accuracy. The GramQ policy, for instance, consistently reduced Factuality Severity (FS) across different datasets, highlighting its robustness against variation in model and provider settings.
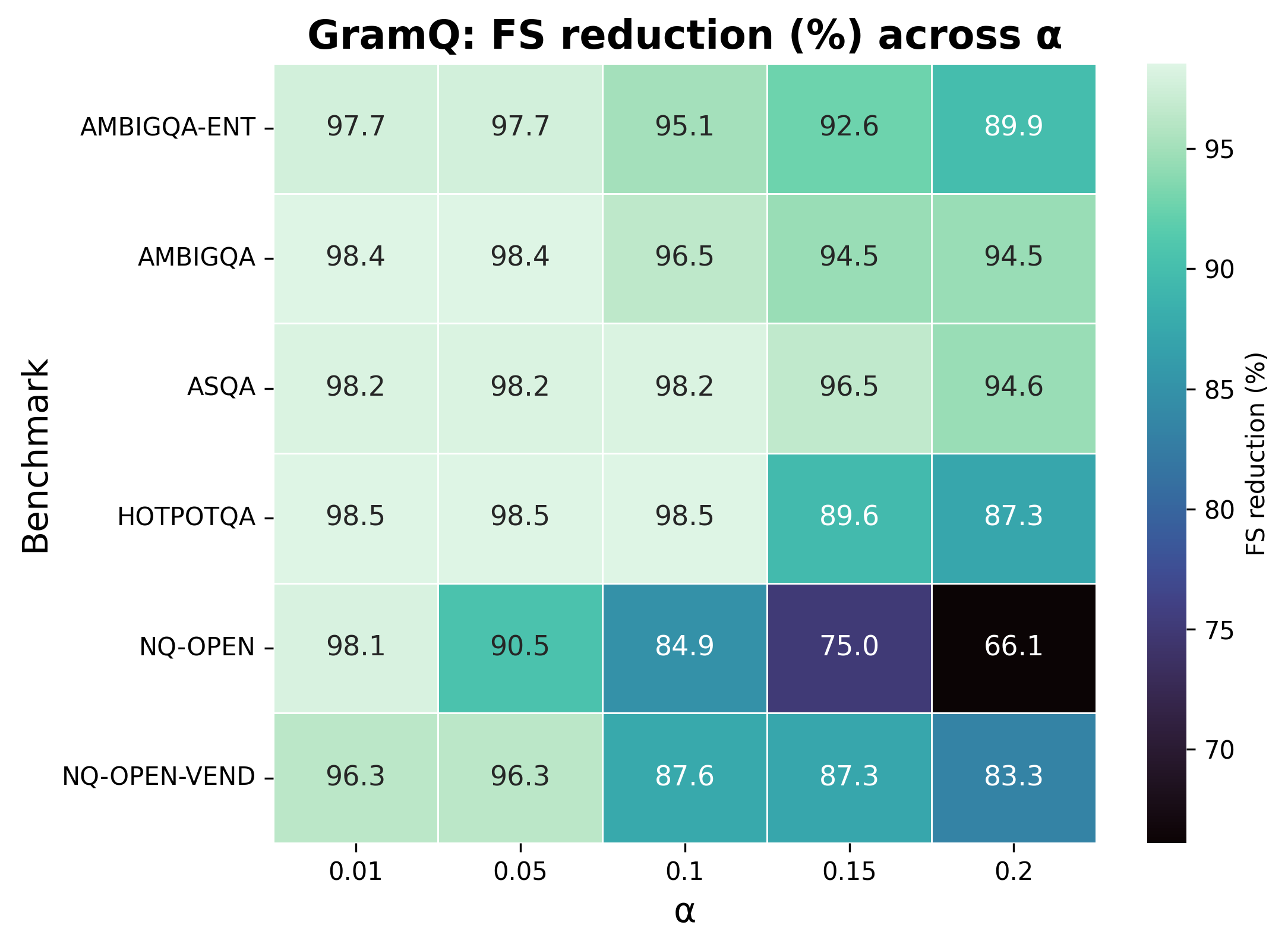
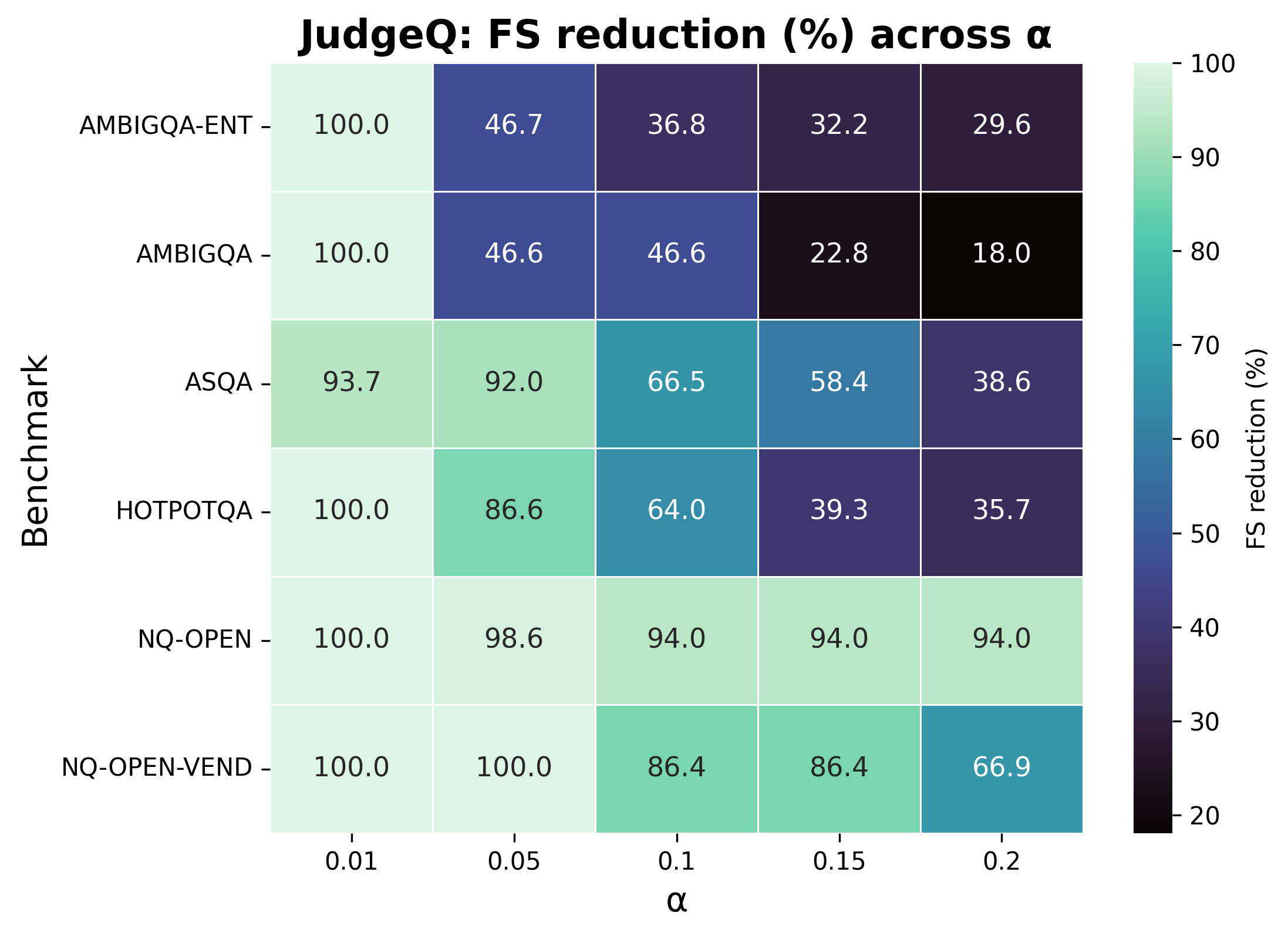
Figure 2: Policy QE: FS reduction (\%) per benchmark demonstrates high reductions and uniform outcomes across tasks.
Conclusion
The study demonstrates how CRC can significantly affect the reliability of LLM outputs by managing risks associated with their randomness. The integration of CRC with semantic quantification offers a systematic approach for deploying LLMs in safety-critical environments. The results advocate for further exploration of CRC's potential in broader contexts beyond language modeling, emphasizing its scalability and robustness.
The findings suggest that future work could relax the exchangeability assumptions to account for covariate shifts or extend the LLM-as-judge applications on a larger scale, addressing challenges in pairwise ranking and multi-judge systems.