- The paper demonstrates that improved Hessian approximations significantly enhance the accuracy of influence functions, as evidenced by higher LDS scores.
- It methodically evaluates GGN, block-diagonality, and Kronecker factorisation strategies to isolate primary error sources in curvature computation.
- Findings indicate that deeper networks are more sensitive to approximation errors, guiding targeted improvements in second-order approximation techniques.
Detailed Summary of "Better Hessians Matter: Studying the Impact of Curvature Approximations in Influence Functions"
Introduction
The paper "Better Hessians Matter: Studying the Impact of Curvature Approximations in Influence Functions" investigates the critical role Hessian approximations play in the performance of influence functions used for data attribution in deep learning models. Influence functions enable researchers to attribute changes in model predictions to specific training examples without necessitating retraining. However, the challenge lies in computing Hessian-vector products efficiently, given that exact computations are infeasible due to the Hessian's size and ill-conditioning. Therefore, the paper focuses on assessing how different Hessian approximations like Generalised Gauss-Newton (GGN) and Kronecker-Factored Approximate Curvature (K-FAC) impact the accuracy of these influence-based attributions.
Key Contributions
The study methodically decomposes and evaluates three specific approximation strategies used in influence functions—GGN substitution, block-diagonality, and Kronecker factorisation. The paper conducts controlled experiments to discern:
- If high-fidelity Hessian approximations improve influence score quality.
- The approximation layer most responsible for errors in influence computations.
- The sensitivity of influence fidelity to errors in different Hessian approximation layers.
Experimental Framework
The experiments consider various architectures and tuning settings to systematically evaluate approximation fidelity and influence quality. Key variations include training duration, network depth, and width. Metrics such as the Linear Data-modelling Score (LDS) are used alongside approximation error calculations to gauge the impact of different methods.
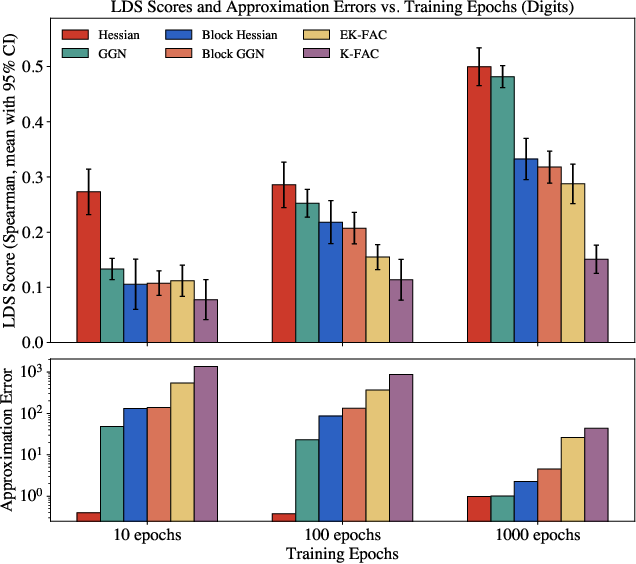
Figure 1: Attribution quality vs. Hessian approximation error across training duration, demonstrating the relationship between LDS and various approximation layers.
Results and Findings
Impact of Hessian Approximations on Influence Score
The experimental results demonstrate a clear positive correlation between improved Hessian approximation fidelity and influence score quality. Notably, as training epochs increase, the methods using more accurate approximations show superior LDS scores. This relationship holds across models of different depths and widths, emphasizing that as models become more complex, the precision of Hessian approximations becomes increasingly crucial.
Approximation Layer Contributions to Error
The study isolates that the dominant source of error in Hessian approximations stems from the Kronecker factorisation step (especially the transition from EK-FAC to K-FAC). This step consistently accounts for a significant portion of the cumulative error across various experimental settings, highlighting a potential area for focused improvement in approximation techniques.
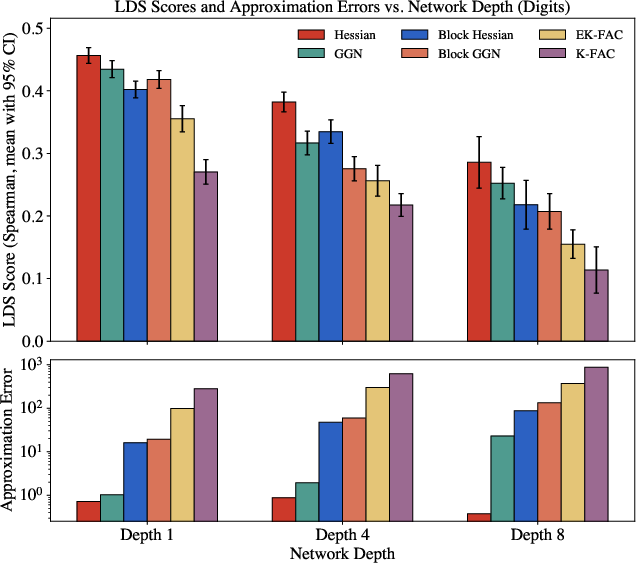
Figure 2: Attribution quality vs. Hessian approximation error across various network depths.
Sensitivity to Approximation Errors
Influence fidelity shows heightened sensitivity to the quality of Hessian approximations, particularly in deeper models. While early-stage errors primarily arise from GGN substitutions, deeper networks suffer more from inaccuracies in block-diagonal and Kronecker-factored approximations.
Theoretical and Practical Implications
The findings suggest that improving Hessian approximation techniques, particularly addressing the errors introduced by Kronecker factorizations, could significantly enhance data attribution methods used in machine learning. On a theoretical level, it underscores the importance of accurate second-order approximation techniques in machine learning, while practically, it guides resource allocation toward improving curvature approximation algorithms.
Conclusion
The paper offers a comprehensive analysis of Hessian approximations, identifying major error sources and their impacts on influence function efficacy. These insights not only help in refining current data attribution methods but also chart out future research directions for more sophisticated approximation techniques. By doing so, the work empowers researchers to deploy more accurate and computationally efficient influence functions in the quest for better understanding and harnessing model behaviors.