- The paper presents an LLM-assisted active learning approach that significantly cuts down on manual annotations in Arabic sentiment analysis.
- It employs rigorous text preprocessing and evaluates multiple LLMs alongside traditional deep learning models like LSTM, GRU, and RNN.
- Experimental results demonstrate up to 93% accuracy using considerably fewer labeled samples, highlighting enhanced efficiency.
LLM-in-the-Loop Active Learning for Arabic Sentiment Analysis
This essay summarizes the notable work titled "From Human Annotation to Automation: LLM-in-the-Loop Active Learning for Arabic Sentiment Analysis" (2509.23515). The paper presents a novel framework that leverages active learning to enhance the efficiency of Arabic sentiment analysis, a task traditionally impeded by limited annotation resources and linguistic complexity.
Introduction
Arabic sentiment analysis is critical for gaining insights across domains like marketing and customer service, yet it lags due to a dearth of annotated datasets and linguistic diversity. This research introduces an active learning framework specifically designed for Arabic sentiment tasks to mitigate annotation burdens. The study contrasts human annotation with LLM assistance, testing architectures including LSTM, GRU, and RNN on datasets featuring both modern standard Arabic and varying dialects.
Methodology
The research involves a structured approach across distinct phases:
- Data Preprocessing: The datasets undergo rigorous preprocessing, involving text normalization and tokenization, tailored for the rich morphological variations of Arabic.
- Model Evaluation: Five LLMs—GPT-4o, Claude 3 Sonnet, Gemini 2.5 Pro, DeepSeek Chat, and LLaMA 3 70B Instruct—are evaluated to select the best performer for each dataset, based on classification accuracy.
- Baseline Comparison: Prior to active learning, deep learning models, including LSTM, GRU, and RNN, are trained conventionally to establish benchmark performance.
- Active Learning Integration: The active learning loop employs uncertainty sampling, iteratively refining model accuracy with LLM-generated or human annotations, seeking to achieve baseline performance metrics with reduced labeled instances.
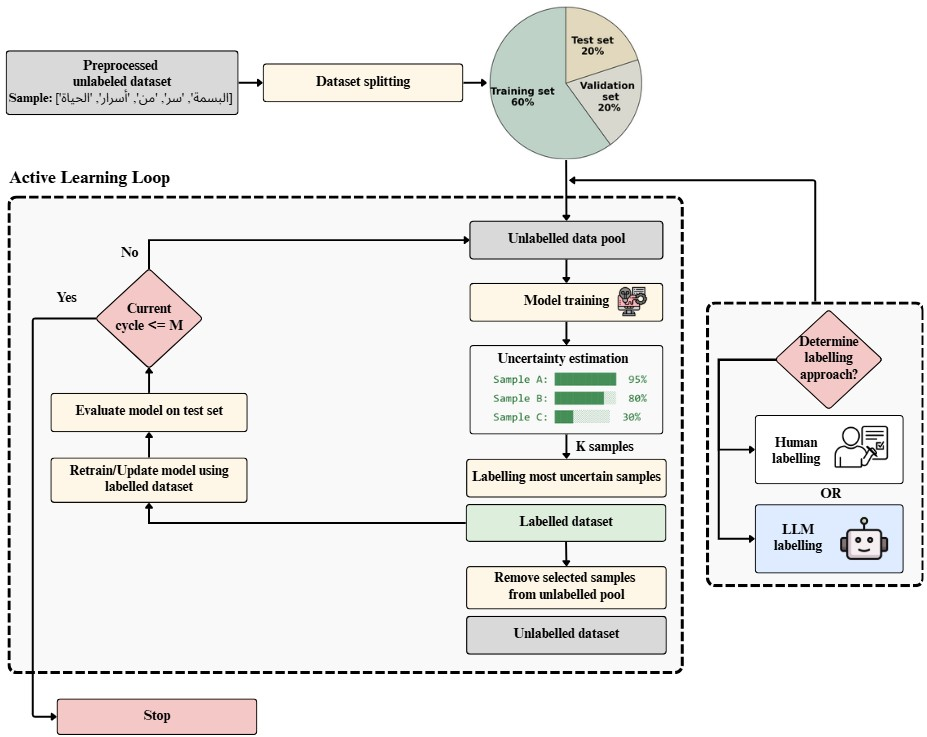
Figure 1: The proposed active learning framework for Arabic sentiment analysis begins with data preprocessing and splitting, followed by the selection of a labeling source, either an LLM or human annotators, before entering the active learning loop.
Experimental Results
Among the tested LLMs, GPT-4o excelled on the Hunger Station and MASAC datasets, while Claude 3 Sonnet performed best on AJGT, assisting in reducing annotation needs while maintaining competitiveness with human annotations.
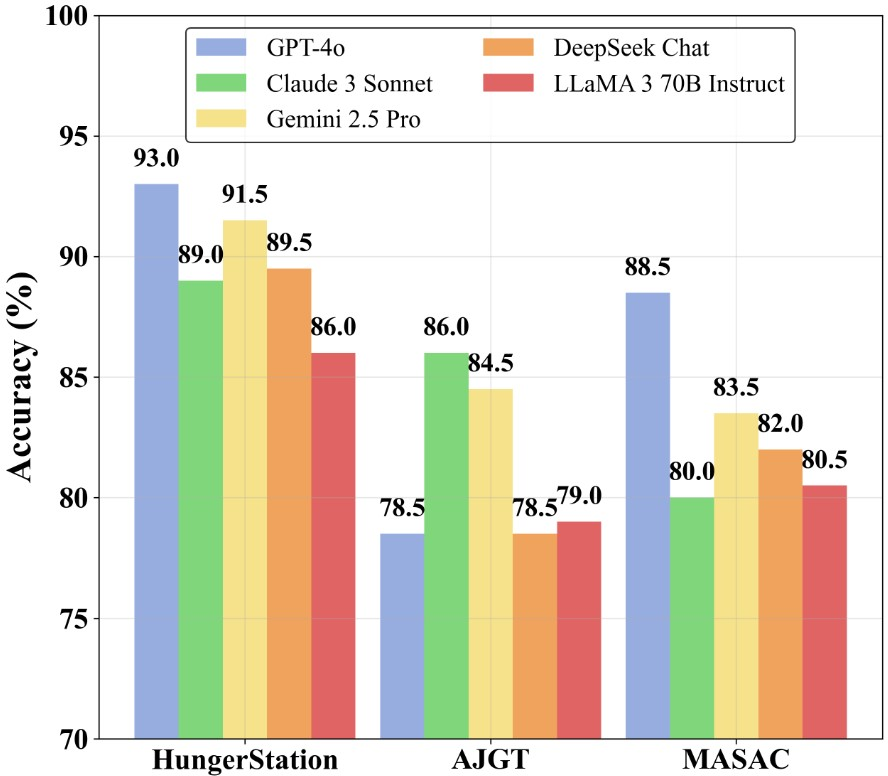
Figure 2: LLMs accuracy (\%) across all sentiment datasets.
Active Learning Outcomes
With active learning, the LSTM model, when combined with active learning, achieved performance analogous to the baseline using considerably fewer labeled samples. On the Hunger Station dataset, the LSTM reached 93% accuracy using only 450 GPT-4o-labeled samples, compared to the original 2700 manually labeled instances.
- Human vs. LLM Annotation: In most settings, LLM-assisted annotation not only reduced human effort but also preserved, or in some instances, enhanced, model accuracy across datasets like MASAC, reaching 82% accuracy with half the labeled samples required by conventional methods.
Implications and Future Directions
The findings highlight the viability of integrating LLMs with active learning frameworks in under-resourced linguistic contexts. Practically, this approach reduces manual labor and speeds up data annotation processes. Theoretically, it opens avenues for refining active learning strategies, such as incorporating advanced uncertainty quantification or exploring cross-dataset generalization capabilities.
Looking forward, potential research could explore domain-specific pre-training of LLMs to adapt better to Arabic linguistic nuances or expand datasets to include more dialectal variety, thus enhancing generalizable sentiment models.
Conclusion
This research advances Arabic sentiment analysis by innovatively combining active learning with LLM-driven annotations, demonstrating substantial improvements in labeling efficiency and model performance. Such advancements promise broader applicability in NLP tasks, setting a compelling precedent for integrating automation within linguistically diverse and resource-constrained environments.