- The paper introduces D-Gating, a method that achieves structured sparsity via differentiable overparameterization, eliminating the need for specialized optimization routines.
- It details how decomposing group weights into primary vectors and scalar gating factors enables smooth L2 regularization, ensuring convergence to non-smooth sparsity penalties.
- Experimental results demonstrate that D-Gating outperforms traditional pruning techniques by offering superior performance-sparsity tradeoffs in linear regression and neural network tasks.
Differentiable Sparsity via D-Gating: Simple and Versatile Structured Penalization
Introduction
The paper "Differentiable Sparsity via D-Gating: Simple and Versatile Structured Penalization" addresses a significant challenge in structured sparsity regularization for neural networks. The non-differentiability of traditional sparsity penalties can inhibit compatibility with conventional optimization methods like SGD, necessitating specialized solutions. This paper proposes a novel method named D-Gating, which introduces a differentiable structured overparameterization strategy. This approach aims to effectively achieve structured sparsity in neural networks using standard SGD without additional complexity.
Methodology
D-Gating Mechanism: The core of this research is the D-Gating method, which differentiates itself by decomposing each group weight into a primary weight vector and multiple scalar gating factors. This decomposition facilitates the application of smooth L2 regularization on these components, thus inducing the desired non-differentiable sparsity penalty. The differentiability of this approach is critical as it allows D-Gating to be seamlessly integrated into existing architectures and training regimes.
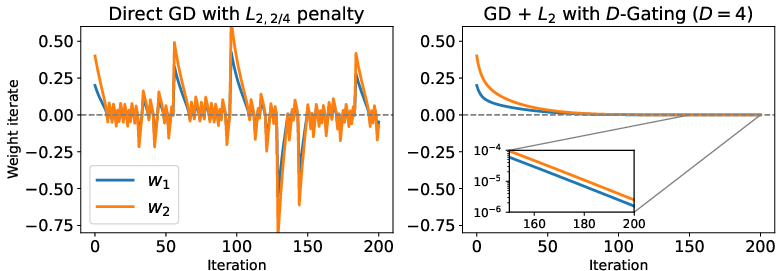
Figure 1: Parameter trajectories showing the failure of direct GD and convergence using D-Gating.
Theoretical Equivalence and Optimization Dynamics: The authors establish the theoretical equivalence between the local minima of the D-Gating objective and the original non-smooth sparsity regularization. They prove that any local minimum with D-Gating corresponds to a local minimum of non-smooth structured L2,2/D penalization. Additionally, the paper demonstrates that the loss associated with the D-Gating objective converges exponentially to the L2,2/D-regularized loss in the gradient flow limit.
Numerical Experiments
The experiments validate D-Gating across various domains, consistently showing superior performance-sparsity tradeoffs compared to traditional methods. Notably, D-Gating outperforms baselines like direct optimization of structured penalties and conventional pruning techniques. This performance is highlighted in various applications including linear regression tasks, where D-Gating achieves better regularization paths and improved generalization.

Figure 2: Evolution of imbalance during SGD training for varying D-Gating depths.
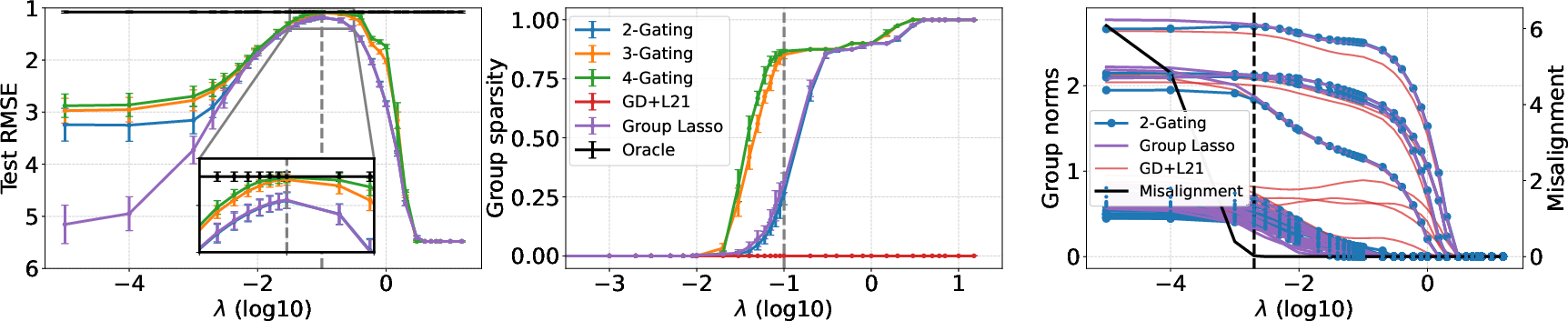
Figure 3: Comparison of regularization paths in sparse linear regression using D-Gating.
Implications and Future Work
The implications of this work are twofold. Practically, D-Gating reduces the complexity associated with achieving structured sparsity in large neural networks, potentially leading to more efficient models with reduced computational overhead and better interpretability. Theoretically, it opens new pathways in the study of differentiable optimization techniques applicable to non-smooth problems, potentially influencing future neural network design and training methodologies.
Future work could explore the integration of D-Gating into various architectures, including more complex networks like Transformer models, as well as its application in real-time and embedded systems where efficiency is paramount. An interesting direction would be examining the interplay between D-Gating and other optimization techniques to improve learning dynamics further.
Conclusion
Differentiable sparsity via D-Gating offers a promising and practical approach to inducing structured sparsity in deep learning models. By leveraging differentiable overparameterization, it eschews the need for specialized optimization routines and additional pruning steps, simplifying implementation while maintaining robust theoretical underpinnings. The experiments underscore its versatility and effectiveness across diverse tasks, marking it as a valuable tool in the arsenal of neural network optimization techniques.
