SCOPE: Semantic Conditioning for Sim2Real Category-Level Object Pose Estimation in Robotics
Abstract: Object manipulation requires accurate object pose estimation. In open environments, robots encounter unknown objects, which requires semantic understanding in order to generalize both to known categories and beyond. To resolve this challenge, we present SCOPE, a diffusion-based category-level object pose estimation model that eliminates the need for discrete category labels by leveraging DINOv2 features as continuous semantic priors. By combining these DINOv2 features with photorealistic training data and a noise model for point normals, we reduce the Sim2Real gap in category-level object pose estimation. Furthermore, injecting the continuous semantic priors via cross-attention enables SCOPE to learn canonicalized object coordinate systems across object instances beyond the distribution of known categories. SCOPE outperforms the current state of the art in synthetically trained category-level object pose estimation, achieving a relative improvement of 31.9\% on the 5$\circ$5cm metric. Additional experiments on two instance-level datasets demonstrate generalization beyond known object categories, enabling grasping of unseen objects from unknown categories with a success rate of up to 100\%. Code available: https://github.com/hoenigpeter/scope.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, actionable list of gaps the paper leaves unresolved that future work could address.
- Sensitivity to detection/segmentation quality is unquantified: the pipeline assumes reliable masks/boxes (precomputed or YOLOv8), but there is no analysis of how pose accuracy degrades with localization errors, partial masks, or class misdetections; design controlled perturbation studies on mask IoU and box shift/scale.
- Depth/normal noise modeling is simplistic: Perlin noise and dropout on normals may not capture real sensor artifacts (structured light vs. ToF vs. stereo, multipath interference, temporal flicker); evaluate across multiple sensor types and noise profiles (e.g., Azure Kinect, RealSense, ZED) and calibrate augmentation accordingly.
- Limited category breadth during training (6 CAMERA categories) constrains semantic diversity: claims of “beyond category-level” generalization are not validated on large-vocabulary datasets (e.g., HouseCat6D, Omni6D, Phocal); run end-to-end experiments on >50 categories to stress-test the semantic prior.
- Canonical frame consistency for unseen categories is not defined or audited: the method predicts NOCS for objects outside training semantics, but lacks criteria to ensure canonical axes are stable and consistent across instances/categories; add quantitative checks for canonical orientation consistency and drift.
- Symmetry handling is asserted but not rigorously evaluated: the claim of “implicit symmetry” from diffusion/PDE foundations lacks dedicated tests on symmetric objects (e.g., bowls, bottles, gears) with controlled rotations; build a symmetry benchmark and measure pose ambiguity resolution.
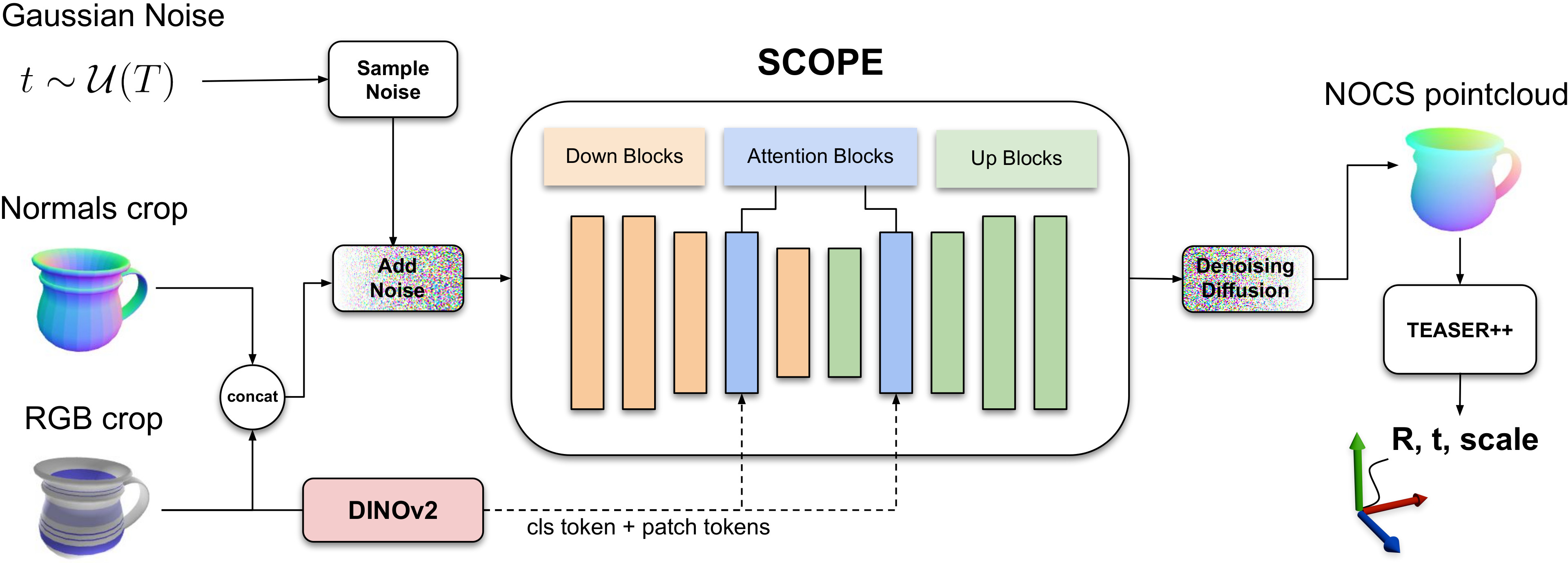
- TEASER++ dependence is unexamined under heavy occlusion/outliers: registration robustness to point sampling choices, outlier rates, and correspondence errors is not characterized; compare TEASER++ with alternative robust estimators and differentiable registration, and analyze failure modes under 70–90% occlusion.
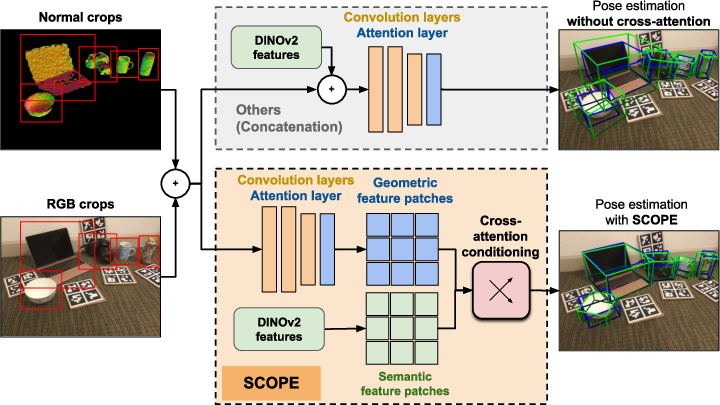
- Cross-attention design choices are not ablated: attention is injected at the 5th down and 2nd up blocks without justification; evaluate multi-scale insertion points, number of heads, patch-token vs. CLS-token usage, and attention sparsity/pruning for efficiency.
- Frozen DINOv2 features may be suboptimal for robotics domains: investigate fine-tuning/adapters for DINOv2 on pose-specific tasks, multi-modal conditioning (image+text via CLIP), or 3D-aware backbones (e.g., point cloud foundation models) to reduce domain shift.
- Absence of uncertainty estimation/calibration: diffusion outputs and TEASER++ registrations lack pose uncertainty quantification; integrate and calibrate epistemic/aleatoric uncertainty to inform grasp planning and risk-aware motion.
- Occlusion regime coverage is unclear: training mentions cropping objects with <50% 2D visibility, potentially biasing against severe occlusion; report occlusion-stratified results and include heavy occlusion training/evaluation splits.
- Runtime scalability for multi-object scenes and edge hardware is not studied: per-object inference (≈0.193 s on RTX 3090) may bottleneck multi-object manipulation; profile end-to-end pipeline (detection+SCOPE+registration+planning) on embedded platforms and optimize batching/parallelization.
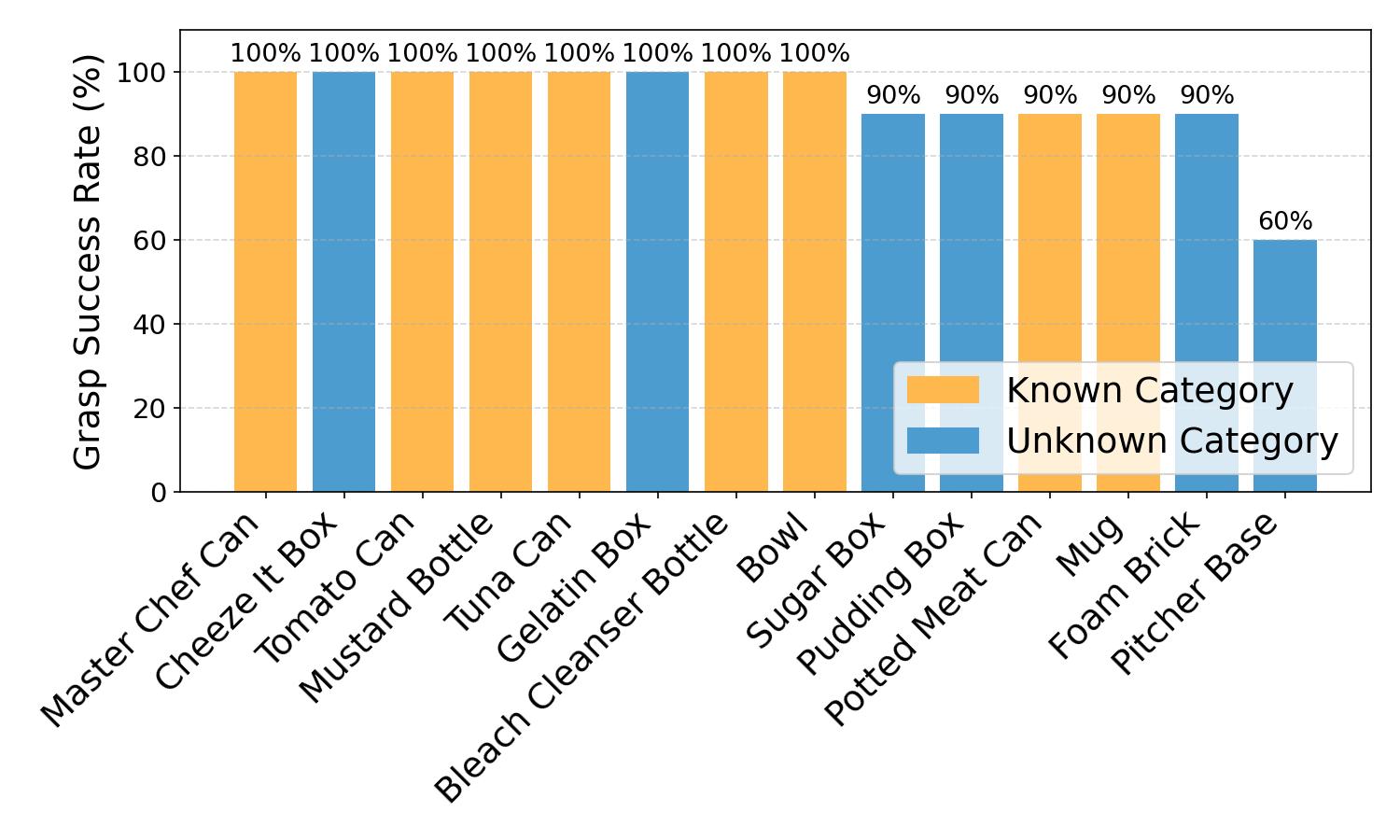
- Failure analysis is limited: the pitcher-base grasp failures suggest sensitivity to small rotation errors on handle-like geometries; systematically analyze per-category failure cases, error distributions (rotation/translation/scale), and geometry-specific sensitivities (thin parts, concavities, specular materials).
- No evaluation under photometric extremes and specular/transparent objects: TYOL/YCB-V contain limited photometric challenges; test on Phocal or similar datasets to measure robustness to glare, translucency, and domain shifts in appearance.
- Input resolution constraints are unexplored: U-Net at 160×160 may limit fine-grained geometry; ablate input resolution and patch size to quantify the trade-off between accuracy and speed/memory.
- End-to-end integration with detection is absent: conditioning on “an arbitrary detector” sidesteps joint optimization; investigate jointly trained detection+segmentation+pose pipelines and feature-sharing to improve robustness.
- OOD detection and semantic confidence are missing: when semantics are far from training manifold, SCOPE provides no explicit OOD signal; add OOD scoring based on DINOv2 embedding distances or attention entropy to gate downstream actions.
- Scale estimation reliability is not dissected: NOCS-based scaling via TEASER++ can drift for deformable/thin objects; measure scale error per object and add scale priors or constraints where appropriate.
- Fairness of the concatenation baseline depends on ChatGPT category mapping: the label assignment for unknown categories can be noisy/variable; provide deterministic mappings and sensitivity analysis to label-assignment errors.
- Grasping evaluation is constrained: grasps are hand-annotated (no grasp synthesis), and some objects are excluded due to flatness/payload; integrate learned grasp point prediction and evaluate closed-loop grasp refinement under pose uncertainty.
- Multi-view/temporal cues are not utilized: single-view inference limits robustness; explore multi-view fusion, temporal aggregation, and SLAM-integrated pose refinement to improve accuracy in cluttered scenes.
- Memory footprint and efficiency of cross-attention are not reported: measure GPU/CPU memory, latency, and energy, and evaluate lightweight attention variants (e.g., linear or sparse attention) for deployment on mobile robots.
- TEASER++ hyperparameter sensitivity is not analyzed: quantify how noise bound, iteration caps, and cost thresholds affect accuracy/runtime and derive auto-tuning heuristics per scene.
- Lack of per-category breakdown on REAL275/YCB-V/TYOL: aggregate metrics hide category-specific strengths/weaknesses; publish per-category tables and confusion analyses to guide targeted improvements.
- No comparison to physics-guided refinement or verification in the loop: integrate methods like VeREFINE to verify/refine poses and quantify gains, especially for borderline cases where grasp success is sensitive.
- Dataset release and reproducibility of CAMERA-BPR are unclear: ensure the synthetic domain-randomized dataset, augmentation recipes, and ChatGPT mappings are released with seeds for reproducibility.
- Potential over-reliance on DINOv2 spatial consistency: analyze cases where semantics dominate geometry (texture bias) and whether cross-attention misleads NOCS regression; add attention interpretability and counterfactual tests.
- Safety and collision robustness are not considered: beyond MoveIt planning, evaluate collision avoidance under pose uncertainty and introduce safety margins informed by calibrated errors.
Collections
Sign up for free to add this paper to one or more collections.