- The paper introduces a post-training pipeline that leverages two-stage Curriculum SFT and offline on-policy KD to bolster small language models.
- It employs diverse, high-quality datasets to enhance reasoning and rapid-response capabilities while addressing computational constraints.
- Results reveal that optimized SFT and KD configurations enable SLMs to achieve benchmark performance comparable to larger models.
Revealing the Power of Post-Training for Small LLMs via Knowledge Distillation
The paper "Revealing the Power of Post-Training for Small LLMs via Knowledge Distillation" presents a systematic approach to enhancing the capabilities of small LLMs (SLMs) using post-training techniques. The focus is on achieving competitive performance on edge devices without the computational burden associated with LLMs.
Introduction and Background
LLMs have established a dominant presence in AI due to their capacity to learn complex patterns and semantic relationships through self-attention and extensive pre-training. Despite their capabilities, the deployment of LLMs in edge environments, where computational resources are limited, presents a significant challenge. This necessitates the development of efficient SLMs that maintain high accuracy while being resource-efficient.
SLMs typically undergo a two-phase training process: pre-training and post-training. The former establishes basic capabilities, while the latter, which requires fewer resources, focuses on enhancing these capabilities. The paper emphasizes the significance of post-training, particularly through techniques like curriculum-based Supervised Fine-Tuning (SFT) and Knowledge Distillation (KD). These methodologies aim to bolster the performance of SLMs to levels on par with much larger counterparts, specifically targeting deployment within Ascend edge devices.
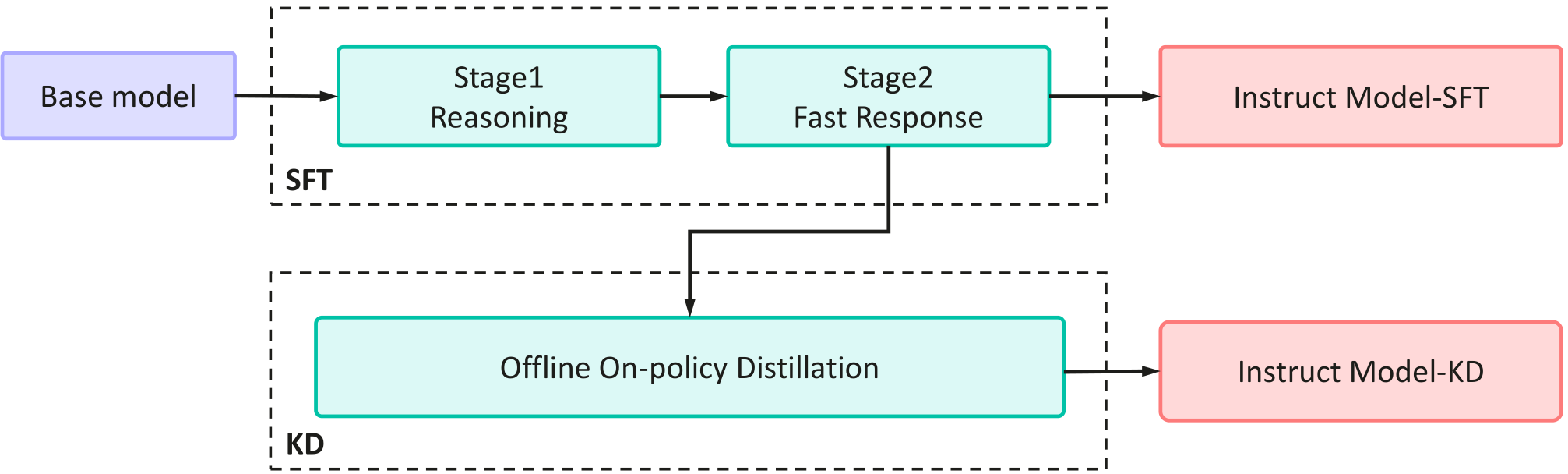
Figure 1: An illustration of the post-training pipeline. The pipeline consists of two primary stages: Two-Stage Curriculum SFT and Offline On-policy Knowledge Distillation.
Post-Training Strategy
Data Selection and Preparation
The post-training dataset is designed with an emphasis on high-quality, diverse, and complex data, particularly those that enhance reasoning capabilities. The dataset integrates multiple data sources, including open-source instruction datasets, real-world queries from domains like finance and healthcare, and synthetic problems from pre-training corpora. The data is divided into reasoning and non-reasoning tasks, with the former prioritized to enhance generalization and reasoning accuracy.
Two-Stage Curriculum SFT
The curriculum SFT is inspired by cognitive science principles, focusing on developing robust reasoning skills before transitioning to fast-response scenarios. In the first stage, the model is trained with data requiring explicit reasoning, which is then followed by a focus on examples that test quick thinking. This structure facilitates the development of implicit reasoning abilities that improve the model's response accuracy and efficiency across various tasks.
Offline On-policy Knowledge Distillation
Knowledge Distillation is leveraged to compress the model, enabling SLMs to achieve high performance by mimicking the outputs of a larger teacher model. Drawing from on-policy KD methodologies, the paper proposes an offline variant to address computational challenges. The approach involves generating student-driven responses, followed by conditioning the teacher model's logits on these responses to align the student more closely with the input distribution it will encounter in practice.
Evaluation and Results
Supervised Fine-Tuning (SFT)
The paper outlines the success of the two-stage curriculum strategy over baseline methods that directly focus on fast-response tuning. The results from expansive benchmark tests indicate that the curriculum-based approach effectively enhances reasoning abilities and overall task performance.
Knowledge Distillation
The study explores various configurations of KT strategies and finds that conditioning teacher logits on student-generated responses yields the best performance outcomes. This alignment minimizes distribution mismatch and ensures effective knowledge transfer.
Post-Training Pipeline Efficacy
Multiple configurations of SFT and KD are tested to find the optimal sequence, achieving significant performance improvements across language, mathematics, reasoning, and code-generation benchmarks. The final results demonstrate that the proposed pipeline allows the model to achieve top-tier performance comparable to models with significantly larger parameter counts while maintaining efficient deployment criteria.
Conclusion
This research highlights the potential of a structured post-training pipeline to enhance small LLMs' performance through methods like Two-Stage Curriculum SFT and offline on-policy Knowledge Distillation. The findings underscore the capability of SLMs to achieve state-of-the-art results on edge devices with resource constraints. This work signifies a step toward optimizing AI deployments for practical, real-world applications, without sacrificing performance. Future research directions hinted at involve expanding these methods to accommodate broader application scenarios and further refining the efficiency and scalability of such models.