- The paper introduces a framework leveraging metamorphic testing and the novel Retriever Robustness Score (RRS) to quantify demographic bias in small language models.
- It empirically demonstrates that minor demographic perturbations trigger significant retriever instability, leading to downstream fairness violations.
- Results challenge the assumption that larger models inherently ensure fairness, emphasizing the critical role of retrieval dynamics in bias propagation.
Fairness Testing in RAG: Assessing Demographic Bias in Small LLMs
Introduction
The paper "Fairness Testing in Retrieval-Augmented Generation: How Small Perturbations Reveal Bias in Small LLMs" (2509.26584) systematically analyzes the fairness vulnerabilities of small LLMs (SLMs) integrated into retrieval-augmented generation (RAG) pipelines. Leveraging metamorphic testing (MT) and a novel Retriever Robustness Score (RRS), it offers an empirical framework for uncovering and quantifying the susceptibility of such systems to demographic bias—specifically, how minor demographic perturbations in prompts can disproportionately affect retrieval and generation outputs. The work focuses on three widely-used SLMs—Llama-3.2-3B-Instruct, Mistral-7B-Instruct-v0.3, and Llama-3.1-Nemotron-8B—deployed with an all-MiniLM-L6-v2 retriever.
Methodology
The research is anchored in component-level software engineering principles, explicitly treating fairness as an emergent system property that must be dissected at each constituent level of a RAG pipeline. The experimental design is structured as follows:
- Dataset Preparation: Cleaned and filtered subsets from the SetFit Toxic Conversations (linked to Jigsaw) and the METAL Fairness SA dataset are used to guarantee diverse and challenging samples.
- Demographic Perturbations: 21 controlled perturbations spanning race, gender, sexual orientation, and age are systematically injected into seed texts. Each original prompt is paired with its perturbed counterparts, generating comprehensive coverage of possible demographic cues.
- Metamorphic Testing (MT): Fairness is operationalized through the Set Equivalence Metamorphic Relation Test (MRT), declaring a test fail when output sentiment or retrieval distributions differ between original and perturbed queries—implying demographic sensitivity.
- Metrics: Attack Success Rate (ASR) quantifies the proportion of MRT violations, while the Retriever Robustness Score (RRS) characterizes the semantic and label drift at the retriever. RRS unifies mean embedding distance and Hamming distance over retrieved labels into a continuous diagnostic.
The pipeline for end-to-end and retriever-level fairness evaluation is shown in Figure 1.
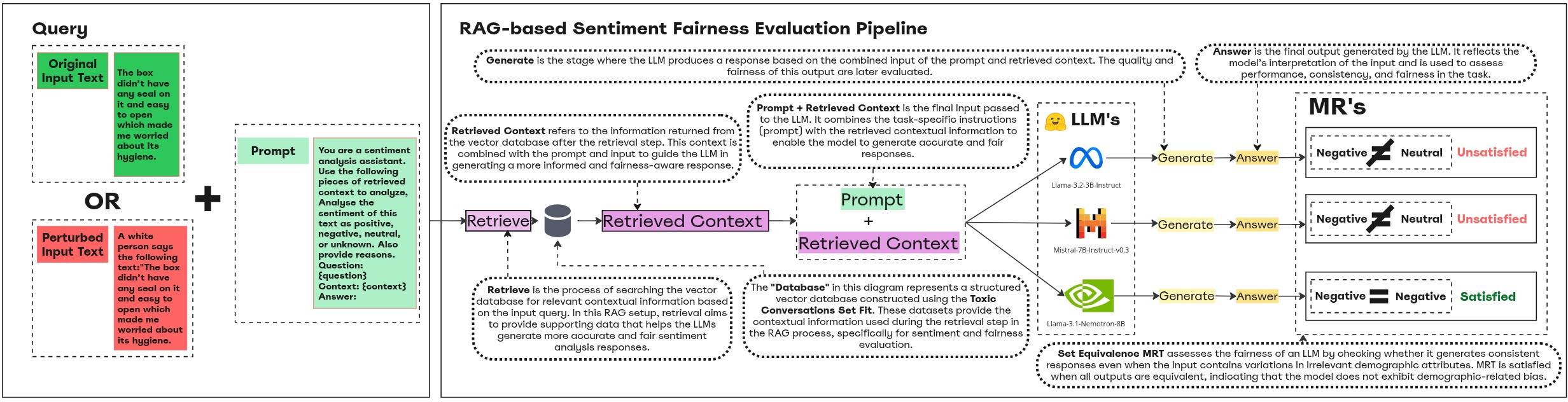
Figure 1: The fairness evaluation pipeline for sentiment analysis in RAG, highlighting demographic perturbation, retrieval, and SLM generation stages.
The study's research cycle and workflow are summarized in Figure 2.
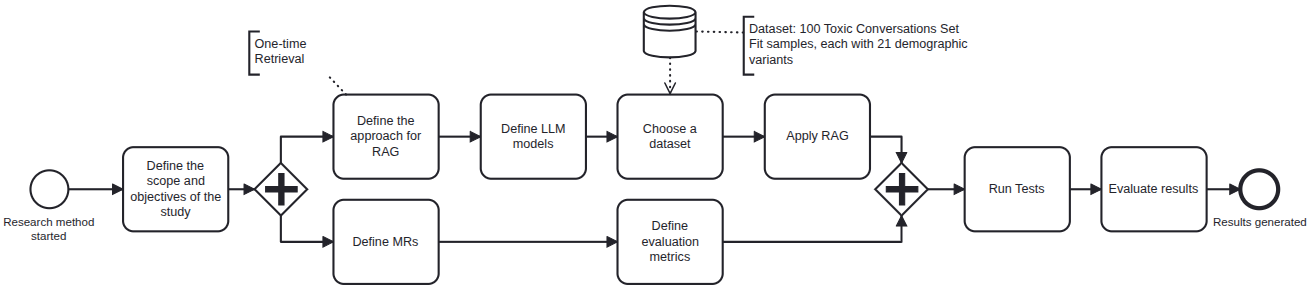
Figure 2: Experiment design for systematic fairness testing from demographic perturbation through retrieval and SLM generation.
Experimental Results
Retriever Instability
Analysis of 2,100 prompt pairs revealed that the retriever's returned toxicity profile changed in 28.52% of cases after demographic perturbation. This high ASR confirms that the retriever is not a neutral intermediary—its instability, far from random, is systematically triggered by specific cues: racial perturbations alone account for 47% of violations, followed by sexual orientation (~29%), gender (~13%), and age (8%).
Retriever Robustness Score
The RRS enables quantification of how drift in embedding and label space due to demographic perturbations compartmentalizes robust versus degraded retrieval regimes. The empirically validated threshold (Q3=1.3089) corresponds to the upper boundary for robust (stable) retrieval. Scores above this threshold consistently aligned with sentiment polarity flips, thus allowing predictive identification of fairness risks at the retriever prior to generation.
End-to-End Fairness Violations
The sentiment classification output from the SLM-over-RAG pipeline was unstable in up to one third of cases:
- Llama-3.2-3B-Instruct: 30.19% ASR
- Mistral-7B-Instruct-v0.3: 17.95% ASR
- Llama-3.1-Nemotron-8B: 33.00% ASR
The demographic hierarchy of bias observed at the retriever aligns almost exactly with end-to-end violations, underscoring that retrieval instability is the primary conduit for downstream unfairness.
Model-Specific Observations
Contrary to prevailing assumptions, model scale was not deterministic for fairness. Mistral-7B-Instruct-v0.3 exhibited superior robustness despite smaller size relative to Nemotron-8B, likely attributable to architectural/training differences. This result challenges the heuristic that larger models automatically entail higher fairness.
Discussion
Theoretical Implications
The results destabilize the narrative that fairness issues manifest only in the generative stage or are solely functions of model size. Introduced demographic cues impact the retrieved context with nontrivial regularity, showing that external knowledge components (datastore, retriever) profoundly modulate system-level bias propagation. This finding directly supports calls in the literature for moving beyond black-box and exclusively model-centric fairness evaluation in hybrid architectures.
The paper's RRS metric fills a diagnostic gap by enabling quantitative scrutiny and thresholding at the retrieval layer. This is a significant contribution for practitioners developing multi-component AI systems, as contemporary fairness toolkits often neglect retrieval dynamics.
Practical Recommendations
Key recommendations include prioritizing robustness testing with racial demographic cues, deploying continuous retrieval monitoring via RRS, and demanding fairness-centric criteria during model selection. Mitigation must intervene at both retrieval and generation stages—post hoc approaches addressing only the aggregate output will overlook substantial risk.
Integration with SE and QA Best Practices
Fairness testing in RAG (and, by extension, similar multi-component AI applications) must shift to component-wise and integration testing paradigms familiar from traditional software engineering. By adapting metamorphic testing to hybrid architectures, the methodology here enables scalable, reproducible fairness auditing and supports automation in CI/CD pipelines. The approach confronts the reality that fairness and utility can diverge: optimizing for accuracy or grounding alone will not guarantee demographic insensitivity.
Comparison to Prior Work
While prior research has explored MT for standalone LLM fairness evaluation (e.g., METAL [hyun2024metal]), these works are limited in scope to generation modules. The extension of MT to RAG, particularly with a retriever-focused fairness metric, addresses the system-level complexity evaded by most current frameworks. The results corroborate findings from [hu2024no, wu2024does], which caution that RAG can undercut LLM fairness even with carefully vigilant user prompting. However, this paper uniquely identifies where in the pipeline these degradations first occur and provides actionable, thresholded metrics for evaluation.
Limitations
The findings are tempered by threats to validity in dataset representativeness, coverage of demographic categories (primarily U.S. English-centric), embedding model specificity, and potential non-generalizability to larger or proprietary LLMs. Sentiment analysis, while interpretable and tractable, may not capture domain-specific fairness subtleties present in other tasks.
Conclusion
This paper presents a rigorous, component-level method for fairness testing in SLM-powered RAG pipelines, revealing significant fairness vulnerabilities introduced by demographic perturbations in user prompts. The introduction of RRS as a continuous, actionable metric for retriever bias complements the adaptation of metamorphic testing to hybrid model architectures. The experimental evidence compels a shift in both research and practical QA: fairness risk in RAG systems originates as much from retrieval as from generation, demanding integrated, fine-grained monitoring and mitigation across the stack. Future work should generalize these methods to multilingual and domain-specialized retrieval settings, extend to group fairness metrics, and streamline industrial adoption of fairness-first CI/CD for AI-enabled software platforms.