- The paper presents an unsupervised forking mechanism that scores and dynamically allocates latent computation to tackle token complexity.
- It leverages adaptive parallel computation to lower perplexity and outperform matched baselines on datasets like OpenWebText.
- The architecture dynamically adjusts computational resources based on token entropy, enhancing autoregressive modeling and multi-step reasoning.
Thoughtbubbles: An Unsupervised Method for Parallel Thinking in Latent Space
Introduction
The paper "Thoughtbubbles: an Unsupervised Method for Parallel Thinking in Latent Space" presents a novel architecture for transforming the conventional computational paradigm in Transformers. The approach, called Thoughtbubbles, introduces a mechanism enabling adaptive parallel computation through dynamic forking and deletion of residual streams. Unlike traditional methods requiring explicit chain-of-thought tokens, Thoughtbubbles operates natively within the latent space, allowing them to be integrated during pretraining without additional annotated data.
Methodology
The core innovation presented in the paper is the forking mechanism within the Thoughtbubbles architecture. This mechanism allows dynamic creation and deletion of residual streams based on a cumulative scoring system, enabling the network to allocate additional computation to complex tokens efficiently. Forking and pruning decisions are integrated within the scoring mechanism which assigns scores to residual streams to determine whether to duplicate or discard them. This score-based system enables the unsupervised identification of computationally demanding tokens, forming "bubbles" of computation as required by the complexity of the input data.
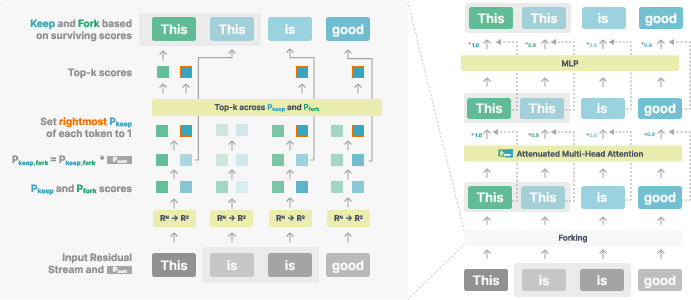
Figure 1: Forking procedure. Token "is" has two forks, one of which will get deleted; the token "this" creates a new fork; we show a score-attenuated transformer block after a forking operation.
Experimental Results
The paper reports comprehensive experimental evaluations using benchmarks like OpenWebText and peS2o datasets. Thoughtbubbles demonstrated superior performance in terms of perplexity across various model scales. Notably, it outperformed computation and parameter-matched baselines on both datasets, indicating effective utilization of adaptive parallel computation.
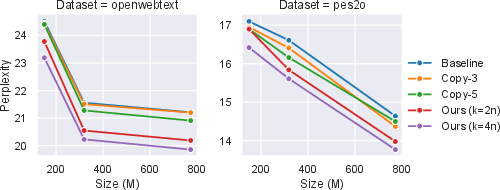
Figure 2: Dev-set perplexity of our approach and various baselines as a function of model scale on both OpenWebText and peS2o datasets. Lower is better.
Furthermore, analyses of regions where additional computation is allocated revealed that Thoughtbubbles inherently focus on zones with higher entropy, which are typically associated with increased uncertainty. This reflects the capability of the architecture to dynamically adapt to varying computational demands without explicit supervision.
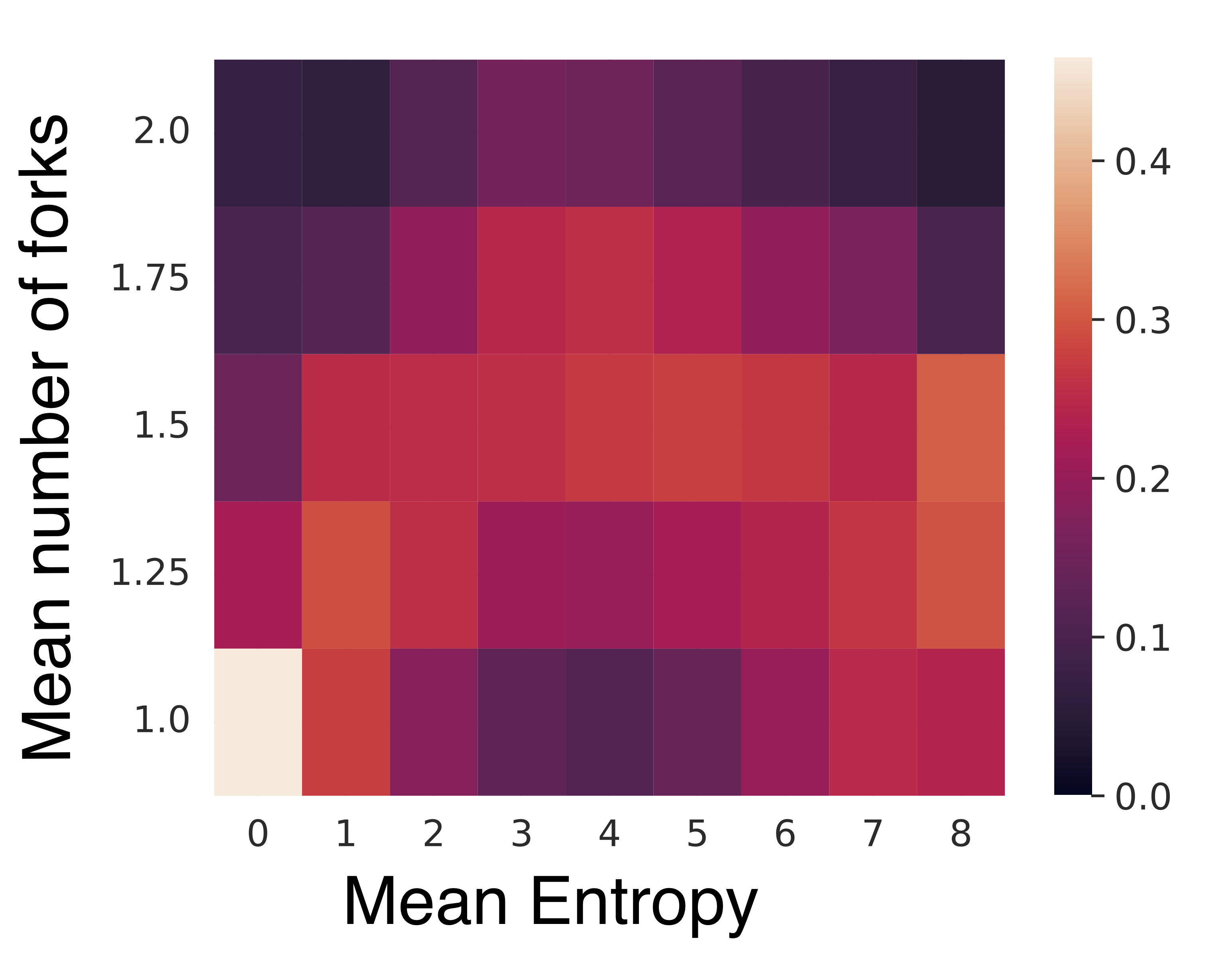
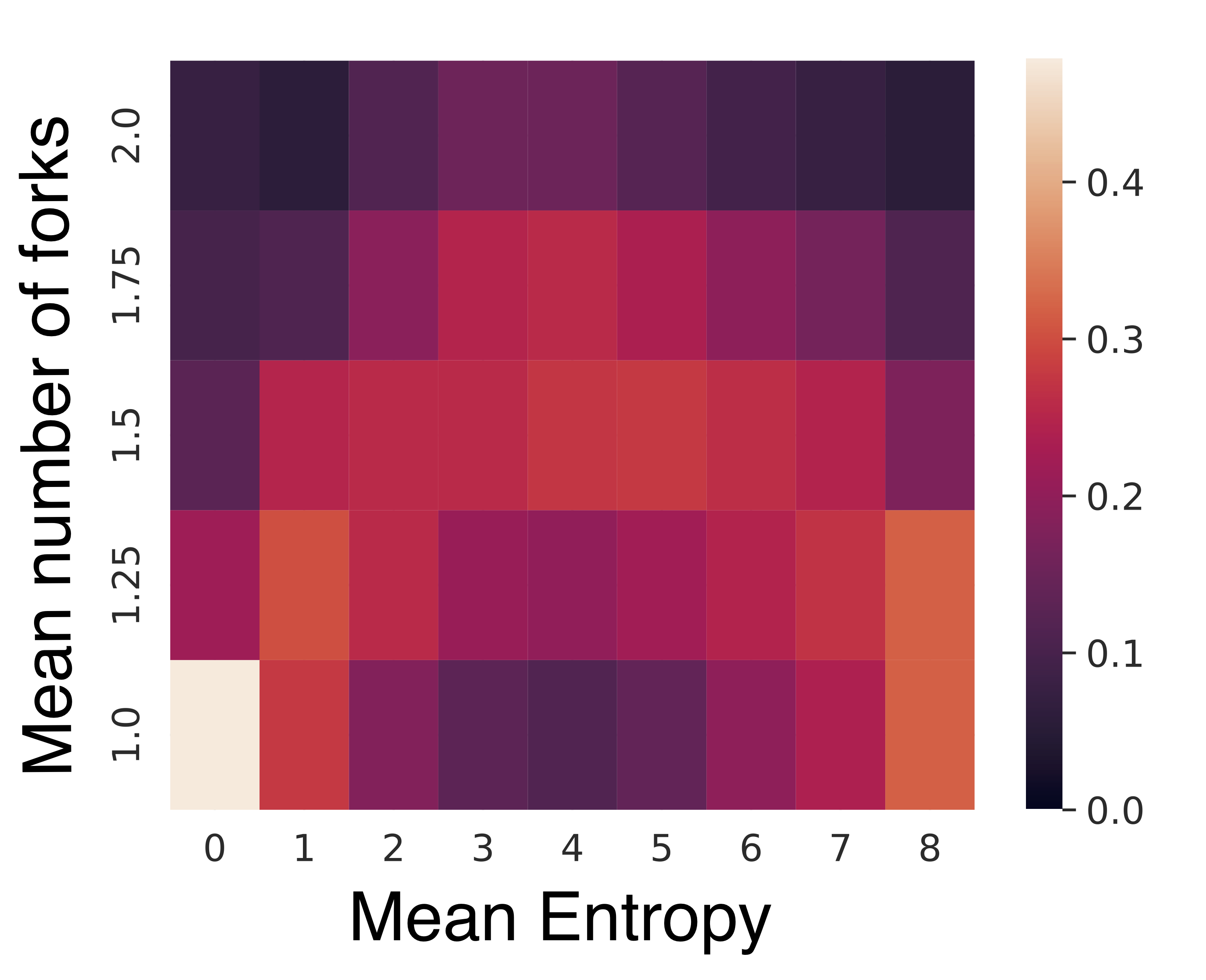
Figure 3: Normalized number of forks in the final layer across a window of 4 tokens as a function of the mean entropy of those 4 tokens on OpenWebText.
Autoregression and Perplexity
The architecture supports both blockwise and autoregressive language modeling scenarios. In autoregressive generation, Thoughtbubbles maintain competitive performance with strategies to adjust the forking budget proportional to input size to mitigate distributional shifts between testing and deployment environments. This adaptability is crucial for models seeking to maintain performance across varying input lengths.
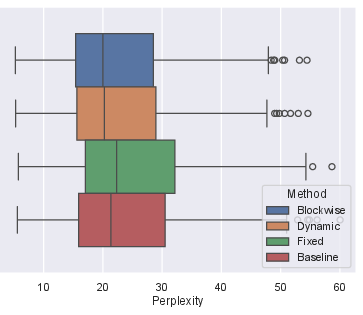
Figure 4: Perplexity distribution and mean perplexity of our 772M (κ = 2L) model over a smaller subset of OpenWebText dev set between blockwise forward versus autoregression. Lower is better.
Theoretical and Practical Implications
Thoughtbubbles offer a significant advancement in neural architecture design by ensuring efficient resource utilization based on task complexity recognized at runtime. This allows models to scale computational effort in a targeted manner, potentially transforming the approach to multi-step reasoning tasks within LLMs, particularly where latent computation can be more flexibly leveraged as opposed to pre-allocated computational budgets.
Conclusion
The methodology showcased in Thoughtbubbles provides a foundation for more flexible and adaptive machine learning architectures capable of dynamic parallel computation within a Transformer framework. As such, it supports the developmental trajectory toward more intelligent, resource-aware, and robust artificial reasoning models. Future work could explore further enhancements to the forking mechanism and investigate the applications of Thoughtbubbles in more complex tasks and larger-scale datasets.