Prompt Curriculum Learning for Efficient LLM Post-Training
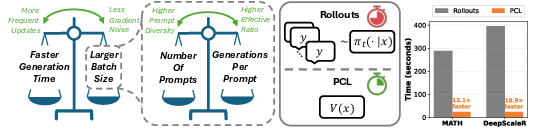
Abstract: We introduce Prompt Curriculum Learning (PCL), a lightweight reinforcement learning (RL) algorithm that selects intermediate-difficulty prompts using a learned value model to post-train LLMs. Since post-training LLMs via RL remains sensitive to batching and prompt selection strategies, we first conduct a series of systematic experiments where we (1) determine the optimal training batch size that balances generation efficiency and gradient quality and (2) establish the importance of focusing on prompts of intermediate difficulty for the policy. We build upon these results to design PCL, which identifies prompts of intermediate difficulty for the current policy in an on-policy manner by using a value model that is concurrently updated based on the current policy. By focusing on informative prompts that yield high effective ratios, PCL achieves either the highest performance or requires significantly less time to reach comparable performance to its counterparts. Compared to rollout-based filtering methods, PCL avoids costly rollouts and achieves $12.1\times$ and $16.9\times$ faster speed on identifying intermediate-difficulty prompts when training on MATH and DeepScaleR, respectively. We further demonstrate that our value model accurately predicts prompt difficulty and allows PCL to focus on progressively more challenging prompts during RL. Our results present a new methodology that delivers improved tradeoff between upper-bound performance and efficiency for reasoning-focused RL.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper shows an easier, faster way to train LLMs to get better at step‑by‑step reasoning (like solving math problems). The main idea is simple: practice works best when the questions are not too easy and not too hard. The authors build a training method that automatically picks “just‑right” prompts for the model and proves this makes learning both faster and better.
What questions the researchers asked
They focused on two practical questions:
- How big should each training batch be so that training is both fast and effective?
- Which prompts (questions) help the model learn the most: easy, hard, or in‑between ones?
Then they asked: Can we design a training method that keeps choosing those “just‑right” prompts without wasting time?
How they did it (methods explained simply)
Think of training an LLM like coaching a student:
- A “prompt” is a question you give the student.
- A “generation” is the student’s answer.
- A “reward” is 1 if the final answer is correct and 0 if it’s wrong.
They studied three knobs the coach can turn during practice:
- Batch size: how many question‑answer pairs are used before adjusting the model.
- Number of prompts (m): how many different questions are included in that batch.
- Generations per prompt (n): how many answers the model tries for each question.
Two key ideas behind why these knobs matter:
- If the batch is too small, each update is noisy; if too large, generating all those answers takes too long. There’s a “sweet spot.”
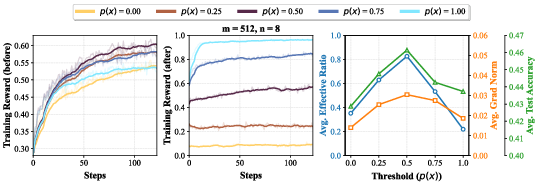
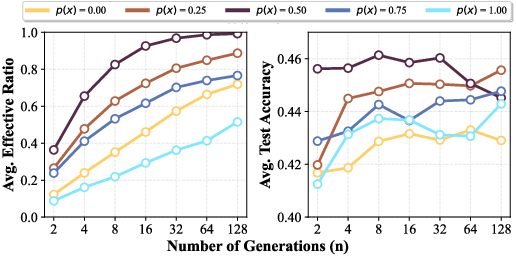
- Questions that are too easy or too hard don’t teach much. The best learning happens when the model gets a question right about half the time (around 50% success). That’s where the learning signal is strongest.
Based on this, they created Prompt Curriculum Learning (PCL):
- They add a small helper model called a “value model.” Its job is to quickly guess how hard a prompt is for the current main model—kind of like a coach estimating difficulty without making the student solve it first.
- At each step, PCL looks at a larger pool of candidate prompts, uses the value model to predict difficulty, and picks the ones closest to “just‑right” (about 50% chance of being correct).
- Then the main model practices on those prompts and updates.
- The value model also learns and improves as training goes on, using only the results from the prompts the main model actually tried.
Why this is efficient: Other methods estimate difficulty by making the main model try lots of answers first (expensive “rollouts”), even for prompts they later throw away. PCL predicts difficulty in one quick pass, so it avoids most of that wasted work.
What they found and why it matters
Here are the main takeaways:
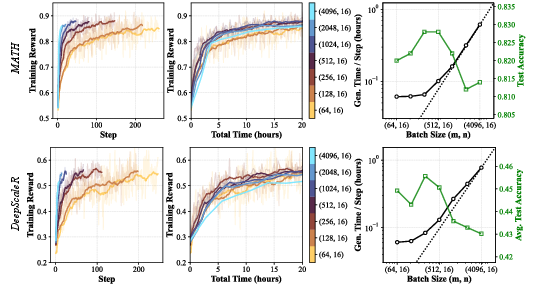
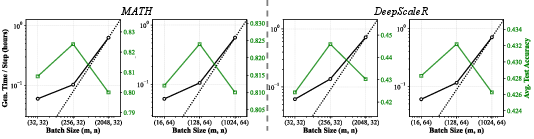
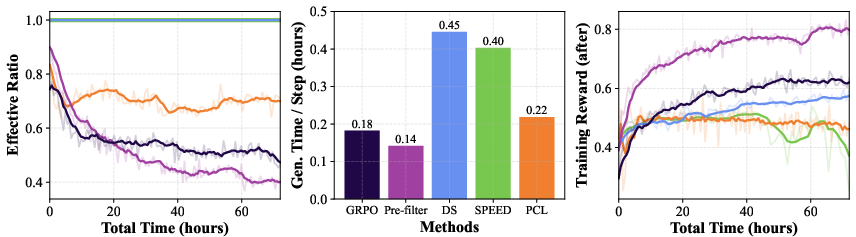
- There’s an optimal batch size “sweet spot.” As you increase batch size, generation time first grows slowly (good), then starts growing linearly (bad). The fastest training happens right at the transition between these two phases. In their tests, this sweet spot was around 8,000 total question‑answer pairs per update (but the exact number depends on hardware and setup).
- Medium‑difficulty prompts teach the most. Prompts where the model is right about half the time give the strongest “learning push,” need fewer samples to be useful, and lead to higher test scores than always‑easy or always‑hard prompts.
- PCL is faster at finding the right prompts. Its difficulty predictor replaces expensive trial‑and‑error. In filtering prompts, PCL was about 12.1× faster on one math dataset (MATH) and 16.9× faster on another (DeepScaleR).
- PCL reaches higher or equal accuracy in less time. Across several models and math benchmarks (like MATH500, Minerva, AMC, and AIME), PCL either achieved the best scores or matched strong methods with notably less training time.
- As the model improves, PCL naturally “raises the bar.” Even with a fixed target (aiming for ~50% difficulty), the set of “just‑right” problems gradually shifts to harder ones, so the curriculum progresses on its own.
Why this could matter going forward
This work offers a practical recipe for training reasoning‑focused LLMs more efficiently:
- It shows how to pick batch sizes that maximize progress per hour.
- It confirms that “just‑right” difficulty is best for learning—now backed by careful measurements.
- It introduces a light, cheap way (PCL) to keep the model practicing at the right level without wasting compute.
In plain terms: smarter problem selection leads to faster, better learning. While the paper focuses on math with “correct/incorrect” rewards, the idea can extend to other skills and to graded (non‑binary) rewards by aiming for a middle‑range difficulty. The authors also note limits: they tested in a specific (on‑policy, synchronous) setup, with modest context lengths and training time. Even so, the approach is broadly useful—a promising step toward making big models learn tough skills faster and more reliably.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is formulated to be concrete enough to guide future research.
- Lack of a formal theory linking intermediate prompt difficulty to learning efficiency: provide a rigorous derivation showing why maximizes gradient norm, effective ratio, and convergence speed under the chosen RL objective and sampling scheme, and quantify conditions under which this holds (e.g., reward noise, variance of returns).
- No predictive model for the “optimal batch size” transition: develop a general analytical framework that predicts the sublinear-to-linear generation-time transition point from hardware, rollout engine, context length, and model size, and validates it across diverse infrastructures.
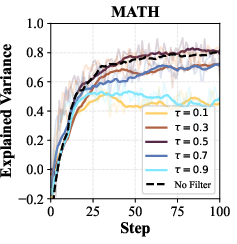
- Fixed threshold τ=0.5 is not systematically optimized: explore adaptive or policy-conditioned threshold schedules (e.g., τ tracking current average accuracy, per-domain τ, or entropy-based τ) and study when deviating from 0.5 improves convergence or generalization.
- Candidate-pool size k is underexplored: ablate k (km prompts per step) to measure its impact on prompt-selection accuracy, compute overhead, and overall training speed; derive an optimal k given value-model error and dataset size.
- Static m/n decomposition despite policy changes: design and evaluate adaptive strategies that choose number of prompts (m) and generations per prompt (n) per step (or per prompt) based on predicted difficulty, effective ratio, and prompt diversity targets.
- Value model architecture and size choices are not fully justified: investigate smaller or specialized value models (e.g., shallow transformers, MLPs, linear probes), pretraining strategies, and cross-model transfer to balance accuracy, latency, and memory at larger scales.
- Prompt-only value inputs may be insufficient in non-math domains: test conditioning the value model on partial rollouts, short scratchpads, or retrieved context to better estimate difficulty when it depends on solution approach or external information.
- Non-binary reward generalization is asserted but untested: evaluate PCL on scalar or dense rewards (e.g., code execution metrics, faithfulness scores, program synthesis test suites) and study how τ should be defined or scheduled for non-binary reward distributions.
- Domain generalization beyond math remains open: test PCL on coding, logical reasoning with tools, multimodal tasks, and tasks without perfectly verifiable rewards; quantify sensitivity to reward noise and checker errors.
- Sensitivity to reward-checker imperfections is not measured: characterize how math-verify false positives/negatives affect value-model calibration, prompt selection, and final performance; propose robust training against noisy verifiable rewards.
- Prompt-level generalization assumption is unproven: perform controlled experiments that hold out very hard prompts entirely to test whether training on intermediate prompts alone transfers to harder ones and quantify any performance gap.
- Exploration vs. exploitation trade-off is not addressed: add mechanisms (e.g., scheduled hard/easy sampling, bandit-style exploration) and test whether occasional inclusion of very hard prompts improves long-term capability without harmful compute overhead.
- Risk of oversampling near-τ prompts in scarce regimes: analyze datasets where few prompts sit near τ, measure overfitting/duplication risk, and design diversity-aware sampling constraints or debiasing mechanisms.
- Value-model calibration and uncertainty are not leveraged: measure calibration (e.g., ECE/Brier scores), add uncertainty estimates, and use them to control selection aggressiveness, set per-prompt n, or downweight low-confidence predictions.
- Unclear robustness to distribution shift during training: study how value-model accuracy degrades as policy changes, and evaluate techniques (e.g., online recalibration, EMA targets, meta-learning) to maintain on-policy fidelity without heavy rollouts.
- Integration with standard RL objectives is missing: replicate results under PPO/GRPO variants with KL regularization, clipping, advantage normalization, and credit-assignment refinements (e.g., VinePPO), to establish whether PCL’s benefits persist under common pipelines.
- Asynchronous RL pipelines are not supported: extend PCL to distributed asynchronous setups (with stale policies and delayed updates), and propose corrections (e.g., importance weighting, off-policy value estimation) that maintain selection quality.
- Long-context regimes remain unevaluated: test PCL with 16k–128k contexts and very long CoT, measure how generation-time scaling changes, whether the optimal batch grows, and whether truncation or context overflow alters selection efficacy.
- Scaling to larger models is untested: evaluate PCL on 14B–70B+ models to verify speed–performance trade-offs, value-model feasibility, and memory/latency constraints when policy and value model sizes grow.
- Best-checkpoint selection may inflate reported gains: adopt held-out validation splits or report averages across recent checkpoints to mitigate test-set overfitting via repeated evaluation and checkpoint selection.
- Baseline comparability needs strengthening: re-run baselines (e.g., SPEED) with stable implementations to avoid crash-induced artifacts; normalize compute budgets to account fairly for filtering overheads and failed runs; publish reproducible configs.
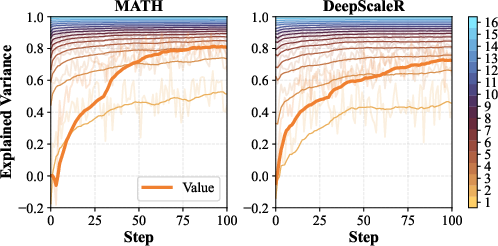
- Ground-truth difficulty proxy is limited: replace the 16-rollout estimate with statistically grounded estimators (confidence intervals, variance-aware bounds) and quantify explained-variance dependence on n to guide practical difficulty estimation.
- Hard-prompt coverage is only indirectly inferred via πref: measure difficulty shift using the evolving policy itself (e.g., pπt(x) trajectories) and quantify eventual coverage and success on the hardest prompts, not just on πref’s assessment.
- Importance-sampling correction for value lag was inconclusive: explore alternative lag-compensation strategies (e.g., doubly robust estimators, lightweight rollouts for reweighting) that could reduce bias without incurring high compute cost.
- Safety and alignment implications are unexplored: in RLHF settings, study whether filtering toward intermediate difficulty affects safety training dynamics (e.g., preference violations) and propose selection rules that preserve safety while improving efficiency.
- Multi-task and multi-objective extensions are open: design τ schedules and value-model conditioning for multi-task training, and assess whether per-task thresholds or hierarchical curricula outperform a single global τ.
- Real-time autotuning of batch configuration is missing: build controllers that learn the optimal batch size and factorization online from telemetry (generation latency, effective ratio, gradient noise), and validate their impact on end-to-end convergence.
Practical Applications
Overview
This paper proposes Prompt Curriculum Learning (PCL), a lightweight, on-policy RL algorithm for LLM post-training that (a) selects prompts of intermediate difficulty using a learned value model and (b) exploits an empirically identified sweet spot in total batch size at the transition from sublinear to linear generation-time scaling. PCL avoids costly rollout-based filtering, achieves 12.1×–16.9× faster prompt-selection than rollout filtering, and reaches equal or better performance with less wall-clock time on multiple reasoning benchmarks. Below are practical applications derived from these findings.
Immediate Applications
The following applications can be deployed now with existing tooling and datasets, especially where rewards are verifiable (e.g., math, coding, constrained generation).
- Efficient RL post-training for verifiable tasks (software, education)
- Use case: Train math/coding LLMs with rule-based rewards (math-verify, unit tests) by replacing rollout-based filtering (e.g., DS/SPEED) with PCL to cut prompt-selection costs and shorten time-to-quality.
- Workflow/tools: Integrate a prompt-only value head into the policy’s architecture, sample km prompts, select m prompts closest to τ≈0.5, then generate n rollouts per prompt; implement in Verl/TRLx with vLLM/SGLang backends.
- Assumptions/dependencies: Binary or scalar verifiable rewards; stable on-policy training loop; value model co-trained online.
- Batch-size auto-tuning for throughput vs. gradient quality (MLOps, training platforms)
- Use case: Add a profiler to identify the optimal total batch size at the “knee” where generation time transitions from sublinear to linear scaling; use that batch size for maximal convergence per wall-clock hour.
- Workflow/tools: One-time profiling harness that measures generation time vs. batch size; simple heuristic/policy to cap batch size at the knee; logs integrated into training dashboards.
- Assumptions/dependencies: Same rollout engine/hardware across profiling and production; stable sequence length distribution.
- Effective-ratio monitoring and control (MLOps)
- Use case: Track proportion of samples with non-zero advantage (effective ratio) and keep it high without oversampling per prompt; emphasize prompts with p(x)≈0.5 to get strong gradients with fewer generations per prompt (higher m for diversity).
- Workflow/tools: Monitoring hooks that compute effective ratio and gradient norm per step; alerting and auto-adjustment of m:n decomposition.
- Assumptions/dependencies: On-policy advantages; accurate reward computation; consistent logging.
- Prompt Difficulty Estimator service (software tooling, platform teams)
- Use case: Provide a lightweight service that predicts pπ(x) via a prompt-only value model to filter/select intermediate-difficulty prompts for any verifiable-reward task.
- Workflow/tools: Small model or head deployed alongside the trainer; batched inference API; caching; A/B switch vs. rollout-based filters.
- Assumptions/dependencies: Value head stays well-calibrated one step behind policy; periodic recalibration if distribution shifts.
- Faster curriculum for test-driven code agents (software engineering)
- Use case: In code RL loops with unit-test rewards, pick functions/problems where the model’s pass@1 rate is near 50% to maximize gradient signal and avoid wasting compute on trivial/hopeless cases.
- Workflow/tools: Unit-test harness; lightweight value head trained on prompt + test outcomes; τ≈0.5 filtering per step.
- Assumptions/dependencies: Reliable unit tests; sufficient prompt diversity; test time fits compute budget.
- Adaptive practice in learning apps using PCL principles (education, daily life)
- Use case: For math-practice/tutoring apps, replace rule-of-thumb difficulty targeting with a learned “value” predictor and select exercises near a ~50% predicted success probability to accelerate learning.
- Workflow/tools: Train a per-learner value model from historical correctness; sample candidate items and select those near τ; simple bandit wrapper to ensure exploration.
- Assumptions/dependencies: Logged outcomes per student; cold-start handling; alignment with pedagogy and content coverage.
- Compute- and carbon-aware training policies (industry, policy)
- Use case: Adopt PCL and batch-size knee selection to reduce GPU-hours for reasoning RL, supporting internal sustainability goals and external reporting.
- Workflow/tools: Cost dashboards tracking GPU-hours, effective ratio, and CO2e; procurement playbooks recommending PCL for verifiable-reward pipelines.
- Assumptions/dependencies: Verifiable rewards; buy-in from infra teams to change batch policies.
- Evaluation set construction near the decision boundary (R&D, QA)
- Use case: Build benchmark slices with intermediate-difficulty items (via value head or few-shot estimates) to better detect real training gains and regressions.
- Workflow/tools: Difficulty-stratified dataset curation; dashboards that track performance by difficulty band.
- Assumptions/dependencies: Difficulty estimator generalizes to held-out; avoids overfitting to boundary items.
Long-Term Applications
These require additional research, engineering, or validation beyond strictly verifiable math/coding setups.
- Generalization to non-binary, learned rewards (RLHF, helpfulness/safety)
- Use case: Use a reward model r(x,y)∈[0,1] and a value model V(x)=Ey[r(x,y)] to target τ near the reward distribution’s midpoint, extending PCL beyond correctness-only domains.
- Workflow/tools: Joint training of policy, reward model, and value model; drift detection for RM calibration; τ scheduling.
- Assumptions/dependencies: Reliable, unbiased reward models; careful handling of reward hacking and off-policy bias.
- Asynchronous and distributed RL orchestration (infrastructure)
- Use case: Adapt PCL to multi-actor, asynchronous rollouts where policy lag is larger; incorporate importance weighting or periodic value-model refresh to maintain selection accuracy.
- Workflow/tools: Replay buffers with freshness labels; policy-lag-aware value training; scalable parameter server support.
- Assumptions/dependencies: Robustness to stale policies; overhead of corrections doesn’t erase PCL speed gains.
- Multi-skill, multi-task curricula (foundation models, MoE)
- Use case: Train per-skill value heads and select intermediate-difficulty prompts per capability (algebra, geometry, coding subdomains), balancing m:n across skills to maximize overall progress.
- Workflow/tools: Skill tagging; per-skill τ and km; scheduling policies that avoid mode collapse; MoE routers informed by difficulty.
- Assumptions/dependencies: Accurate skill taxonomy; enough data per skill; cross-skill generalization holds.
- Robotics and embodied agents with success/failure signals (robotics)
- Use case: In sim, use a state/task-conditioned value estimator to select tasks with ~50% success for data-efficient policy improvement; gradually shift to harder tasks as competence grows.
- Workflow/tools: Scenario generators; success verifiers; curriculum scheduler; sim-to-real validation.
- Assumptions/dependencies: Reliable simulation fidelity; transferable skills; safety and reset costs considered.
- Tool-use and program synthesis agents with verifiable subgoals (software, data ops)
- Use case: For multi-tool workflows (retrieval, code, SQL), assign verifiable checks (tests, schema constraints) to substeps; apply PCL at the subgoal level.
- Workflow/tools: DAG-of-tools with validators; subgoal value heads; τ per node; end-to-end orchestration.
- Assumptions/dependencies: Well-defined, automatable checks; low coupling between subgoals.
- Curriculum controllers for long-context and multi-turn reasoning (foundation models)
- Use case: Extend the batch-size knee heuristic to long contexts and multi-turn traces; tune m:n and τ as sequence lengths grow to sustain effective ratio and throughput.
- Workflow/tools: Context-aware profilers; segment-level rewards; adaptive truncation/checkpointing.
- Assumptions/dependencies: Longer contexts shift the knee; memory/IO bottlenecks; reward sparsity in long chains.
- Education at scale: principled ZPD engines (education policy, EdTech)
- Use case: National/state digital learning platforms adopt “intermediate difficulty targeting” with verifiable micro-assessments; publish difficulty-stratified progress metrics.
- Workflow/tools: Federated modeling for privacy; difficulty calibration across curricula; equity/fairness audits.
- Assumptions/dependencies: Data privacy frameworks; stakeholder alignment; content coverage and pacing constraints.
- Safety/tuning pipelines with difficulty-aware sampling (AI governance)
- Use case: In red-teaming and safety tuning, select scenarios where model failure is ~50% to generate high-signal data; accelerate hardening cycles.
- Workflow/tools: Threat library with difficulty labels; value heads trained on failure outcomes; τ targeting around safety decision boundaries.
- Assumptions/dependencies: Reliable failure labeling; guard against optimizing to tests rather than capabilities.
- Serving-time self-improvement loops (productization)
- Use case: Lightweight on-device/cloud-side value head prefilters user prompts for targeted self-play or background RL updates on prompts likely to be informative.
- Workflow/tools: Shadow training services; privacy-preserving logging; budget controllers for background learning.
- Assumptions/dependencies: Legal/privacy constraints; user consent; guardrails to prevent drift.
- Standards and reporting for efficient RL (policy, industry consortia)
- Use case: Require reporting of batch-size knee, effective ratio, and difficulty distribution of training data in model cards; encourage difficulty-aware sampling for energy efficiency.
- Workflow/tools: Best-practice checklists in procurement; auditor guidelines; shared benchmarks stratified by difficulty.
- Assumptions/dependencies: Community consensus; compatibility with diverse pipelines; risk of gaming metrics mitigated.
Notes on feasibility across applications:
- PCL’s strongest gains currently rely on verifiable rewards; extension to subjective rewards hinges on robust reward models and careful bias control.
- The assumption of prompt-level generalization (training on mid-difficulty helps both easy and hard) is most plausible in structured domains like math/coding; validation is needed for open-ended dialogue and multimodal tasks.
- The batch-size knee depends on rollout engine, hardware, and sequence lengths; re-profile when these change.
- Value model calibration is critical; monitor explained variance vs. rollout-based estimates and retrain/refresh as policies evolve.
Glossary
- Advantage: The difference between the received reward and the expected reward under the current policy, used to weight gradients in policy optimization. "and as the advantage."
- Advantage regularization: A stabilization technique that regularizes advantage estimates, often via their standard deviation. "without standard deviation-based advantage regularization"
- AIME: A competition-level math benchmark (American Invitational Mathematics Examination) used to evaluate reasoning performance. "including AMC 23, AIME 24, and AIME 25."
- AMC: A competition-level math benchmark (American Mathematics Competitions) used to evaluate reasoning performance. "including AMC 23, AIME 24, and AIME 25."
- Autoregressive generation: Generating tokens sequentially, each conditioned on previous tokens and the prompt. "generated autoregressively from a policy , i.e., ."
- Binary reward function: A reward function that outputs 1 for correct responses and 0 otherwise. "We assume a binary reward function "
- Chain-of-thought (CoT): Explicit reasoning steps produced by LLMs to solve problems. "long chain-of-thought (CoT) solutions"
- Clipping heuristics: Heuristics that limit update magnitudes (e.g., PPO clipping) to stabilize training. "eliminate the off-policyness during updates, clipping heuristics, and additional hyperparameters"
- Curriculum Learning: A training strategy that orders or selects data by difficulty to improve learning efficiency. "Curriculum Learning~\citep{10.1145/1553374.1553380}"
- DeepScaleR: A large math reasoning dataset used for training and evaluation. "training on MATH and DeepScaleR respectively."
- Dictionary-based methods: Approaches that track historical rewards per prompt to filter or prioritize training examples. "much more on-policy than dictionary-based methods."
- Dynamic-sampling (DS): A baseline that estimates prompt difficulty by generating multiple rollouts per prompt and filters extremes. "Dynamic-sampling (DS)~\citep{yu2025dapoopensourcellmreinforcement} uses rollouts per prompt to estimate for prompts and filters out prompts with ."
- Effective ratio: The proportion of samples in a batch with non-zero advantage, i.e., that contribute useful gradient signal. "effective ratio, defined as the proportion of samples in the batch with non-zero advantages"
- Explained variance: A metric quantifying how much variance in ground-truth difficulty is captured by the value model’s predictions. "The explained variance is calculated as:"
- GRPO: An RL algorithm variant used for LLM training that operates on-policy and optimizes group-relative advantages. "we adopt the purely on-policy variant of GRPO"
- Greedy downsampling: Selecting a subset of prompts closest to a target difficulty by a greedy criterion. "We then perform greedy downsampling to select prompts"
- Importance sampling: A correction technique that reweights estimates to account for distribution mismatch between policies. "using importance sampling to correct for this lag by reweighting based on "
- Intermediate difficulty: Prompts that the current policy solves with about 50% success rate, yielding strong learning signals. "prompts of intermediate difficulty ()"
- KL regularization: Regularization that penalizes divergence from a reference policy via the KL divergence. "without KL regularization to a fixed reference policy $\pi_{\mathrm{ref}$"
- MATH500: A standard 500-problem split of the MATH dataset used for evaluation. "we evaluate on the standard MATH500 split."
- math-verify: A rule-based math solution checker used to define rewards. "rule-based reward function based on math-verify"
- Minerva Math: A quantitative reasoning math benchmark used for evaluation. "Minerva Math~\citep{lewkowycz2022solvingquantitativereasoningproblems}"
- Off-policyness: The mismatch when training or filtering relies on data not generated by the current policy. "eliminate the off-policyness during updates"
- OlympiadBench: A benchmark of Olympiad-level scientific problems for evaluating AGI-like reasoning. "OlympiadBench~\citep{he2024olympiadbenchchallengingbenchmarkpromoting}"
- On-policy: Training that uses data generated by the current policy at each step. "in an on-policy manner"
- Policy gradient: An RL method that optimizes the expected reward by gradient ascent on the policy parameters. "has the same gradient as policy gradient"
- PPO: Proximal Policy Optimization, a popular RL algorithm using clipped updates. "using algorithms such as PPO"
- Prompt Curriculum Learning (PCL): The proposed method that uses a learned value model to select intermediate-difficulty prompts efficiently. "We introduce Prompt Curriculum Learning (PCL)"
- Prompt diversity: The variety of unique prompts in a batch, which reduces gradient noise and stabilizes learning. "This quantity is closely related to the prompt diversity."
- Prompt filtering: Selecting prompts to train on based on estimated difficulty or informativeness. "train a value model online for prompt filtering."
- Reference policy: A fixed policy used for regularization or to estimate difficulty. "a fixed reference policy $\pi_{\mathrm{ref}$"
- Rollout: A generated trajectory or response from the policy used for training or evaluation. "rollouts from the current model"
- Rollout-based filtering: Filtering methods that rely on generating responses to estimate prompt difficulty. "Compared to rollout-based filtering methods, PCL avoids costly rollouts"
- SGLang: A rollout engine/framework used to generate model responses efficiently. "rollout engines (vLLM vs.~SGLang)"
- Synchronous training: A setup that alternates in lockstep between data generation and optimization phases. "a synchronous training setup that alternates between generation and optimization phases."
- Value model: A model that predicts the expected reward (difficulty) of a prompt under the current policy. "using a value model"
- Value network: The parameterized function approximator used to predict prompt values (expected rewards). "Initialize policy , value network $V^{\pi_{-1}$"
- Verl: A training framework used for synchronous RL pipelines in the experiments. "All experiments are implemented using Verl~\citep{Sheng_2025}, a synchronous training setup"
- vLLM: An inference engine that manages memory efficiently for large-scale generation. "using vLLM~\citep{kwon2023efficientmemorymanagementlarge}"
Collections
Sign up for free to add this paper to one or more collections.