- The paper proposes the SCoT framework that integrates chain-of-thought reasoning into full-duplex spoken dialogue systems to improve conversational coherence.
- It employs CTC-based forced alignments to generate intermediate reasoning paths, enabling simultaneous listening and speaking without explicit VAD.
- Experiments on Switchboard and Fisher datasets demonstrate reduced latency and enhanced semantic quality compared to traditional turn-by-turn systems.
Chain-of-Thought Reasoning in Streaming Full-Duplex End-to-End Spoken Dialogue Systems
Introduction
The paper introduces a novel framework called Streaming Chain-of-Thought (SCoT) for enhancing full-duplex end-to-end spoken dialogue systems (SDS). Traditional SDS rely on voice activity detection (VAD) for turn-taking, but often struggle to differentiate between speaker pauses and turn completions. The SCoT framework proposes a streaming approach that processes user input and generates responses in a blockwise manner, improving coherence and interpretability while supporting simultaneous listening and speaking without explicit VAD.
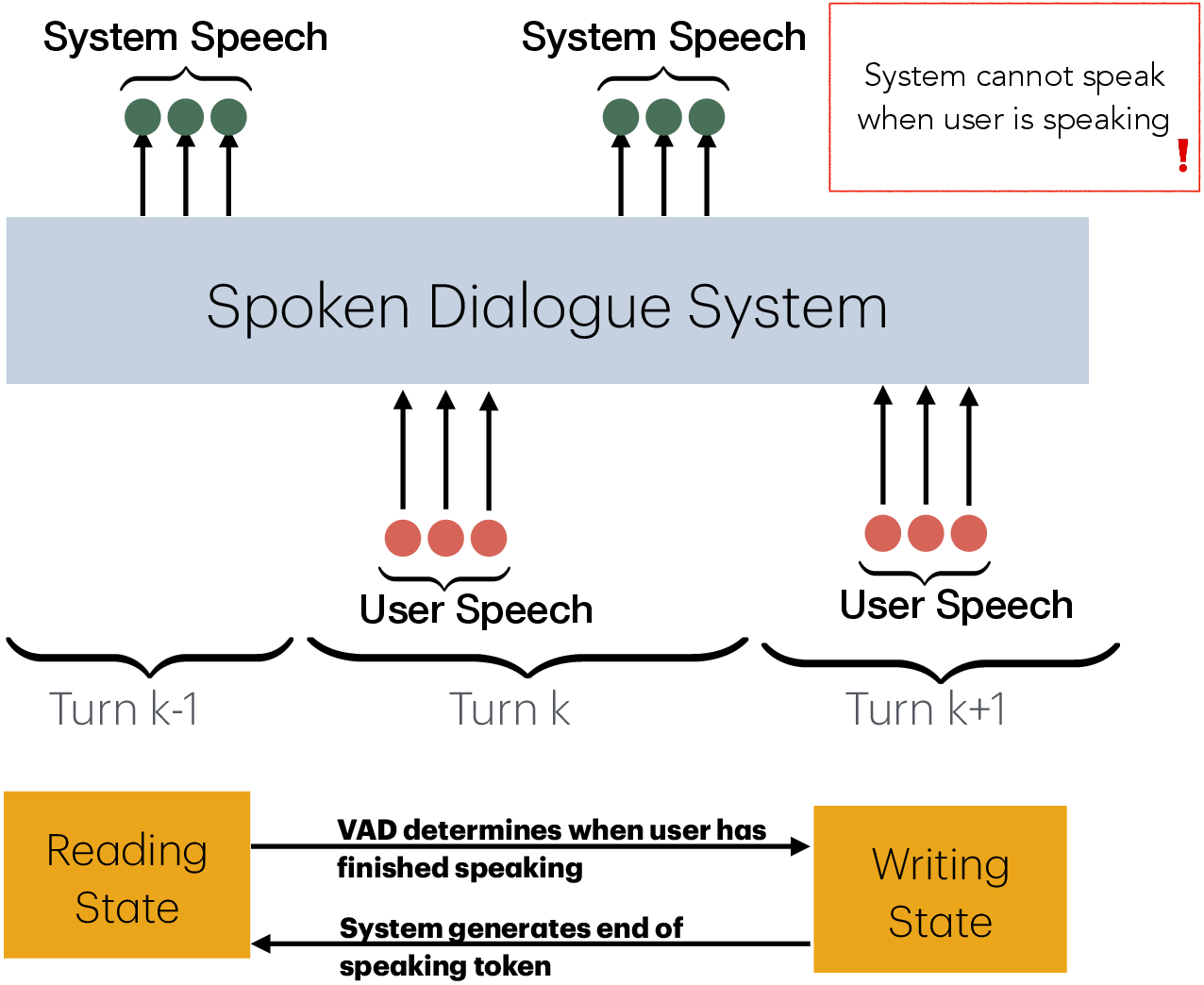
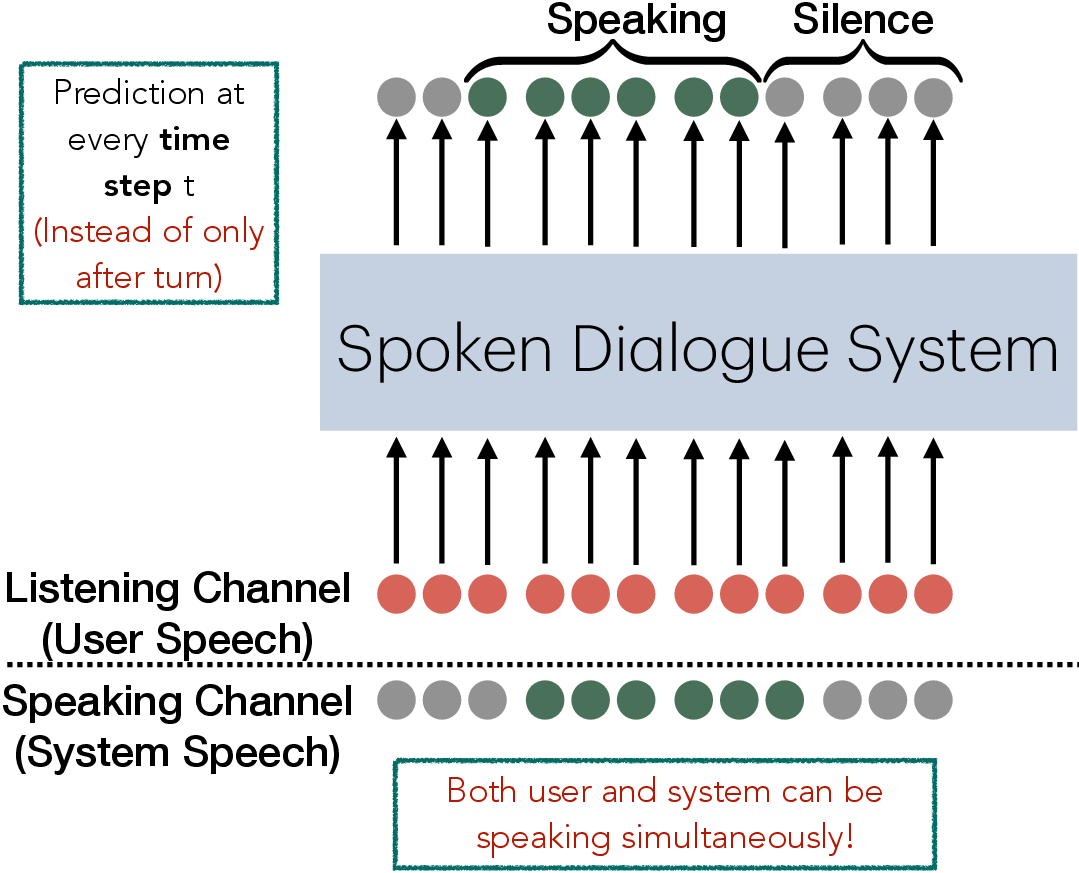
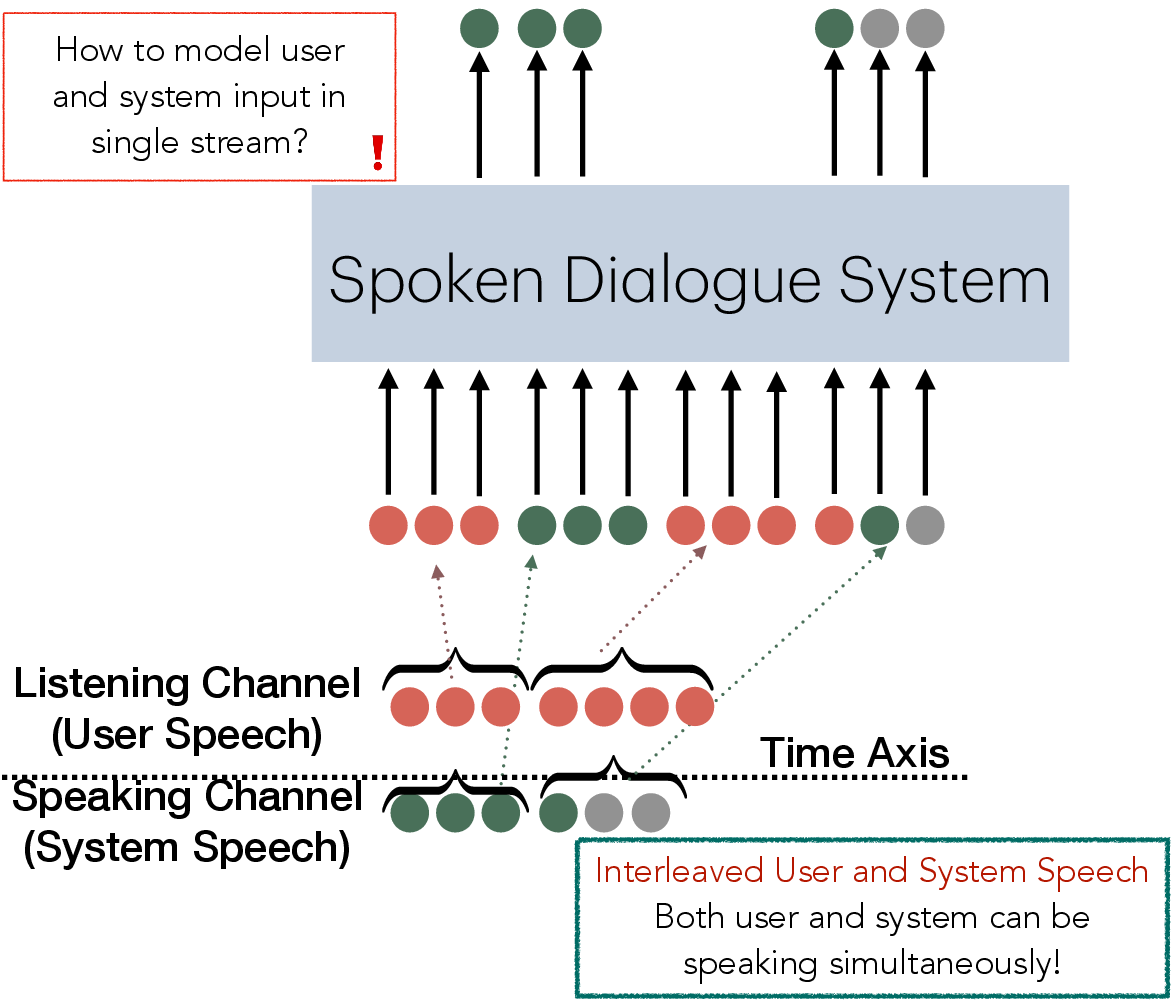
Figure 1: Turn-by-turn SDS.
Background and Motivation
SDS aim to facilitate natural conversational interactions by processing continuous audio streams and generating corresponding spoken responses. The introduction of LLMs and speech+text LLMs has allowed end-to-end SDS to directly generate responses from speech inputs. However, these models fail to capture the complexity of conversational semantics and are often modeled using the turn-by-turn paradigm, dependent on VAD modules. Prior works have addressed these limitations by introducing duplex systems that predict output continuously.
Duplex spoken dialogue systems seek to overcome the limitations of traditional turn-by-turn interaction by allowing simultaneous listening and speaking. This requires estimating the posterior distribution of the system's output under conditions of both simplex (listening or speaking) and duplex (listening and speaking simultaneously). A key challenge is managing the transition between listening and speaking while effectively modeling intermediate reasoning paths.
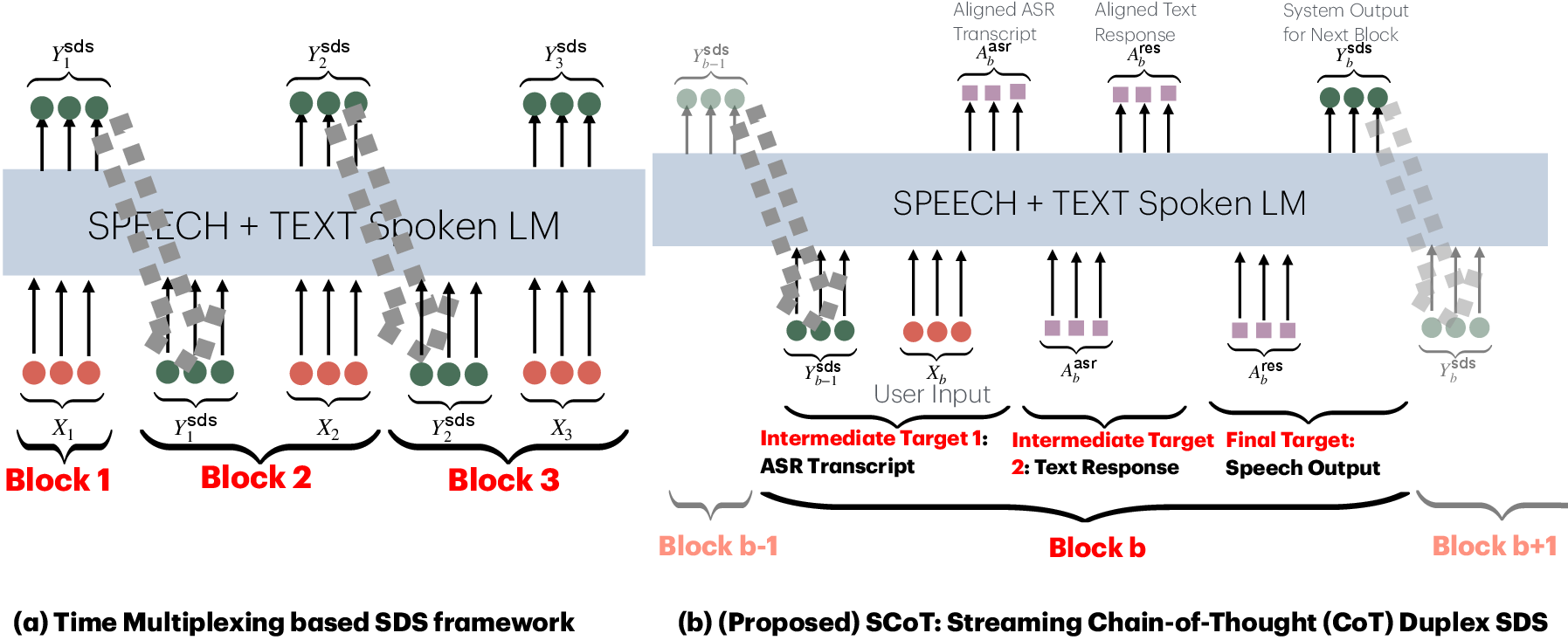
Figure 2: Overview of SCoT: the proposed Streaming Chain-of-Thought (CoT) Duplex SDS architecture.
Our Chain-of-Thought Duplex SDS
SCoT extends the Turn-by-turn CoT SDS framework into a duplex setting, introducing intermediate targets such as aligned user transcripts and system responses. It utilizes CTC-based forced alignments to generate these intermediate representations, which allows for real-time, CoT-based reasoning during speech generation. The paper proposes three variants: SCoT-ASR, SCoT-Response, and SCoT-Full, each exploring different intermediate reasoning paths for efficiency and coherence.
Experiments and Results
The model was evaluated on the Switchboard and Fisher datasets, demonstrating improved semantic quality and interaction latency compared to existing Duplex E2E models. SCoT significantly enhances both semantic coherence and emotional alignment, while achieving lower latency and enabling overlapping speech generation, aligning more closely with natural conversational dynamics.
Conclusion
The SCoT framework provides a logical extension of the chain-of-thought reasoning paradigm into duplex spoken dialogue systems. It successfully balances semantic coherence, interaction fluidity, and computational efficiency, positioning it as a significant advancement in the field of spoken dialogue systems. Future research may focus on optimizing block size for improved performance and further refining reasoning paths for diverse conversational contexts.