- The paper introduces a novel framework integrating multi-modal large language models with reinforcement learning to detect AI-generated videos and provide chain-of-thought explanations.
- It constructs a curated 140,000 video pair dataset and employs GRPO variants to detect temporal and quality artifacts, ensuring robust, semantic evaluation.
- Experimental results show state-of-the-art accuracy, zero-shot generalization, and enhanced interpretability compared to conventional CNN and Transformer methods.
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Motivation and Context
The proliferation of high-fidelity AI-generated videos, enabled by advanced generative models such as Sora, HunyuanVideo, and CogVideoX, has introduced significant challenges for content authenticity verification. Existing detection methods, primarily designed for DeepFake-style facial forgeries or relying on spatial-temporal consistency, are insufficient for open-domain, multi-scene videos and often lack interpretability. VidGuard-R1 addresses these limitations by leveraging multi-modal LLMs (MLLMs) and reinforcement learning (RL) to deliver both accurate detection and interpretable, chain-of-thought (CoT) explanations.

Figure 1: Overall framework of VidGuard-R1, integrating MLLMs with chain-of-thought reasoning for video authenticity detection.
Dataset Construction and Annotation
VidGuard-R1 introduces a curated dataset of 140,000 real and AI-generated video pairs. Real videos are sourced from InternVid and ActivityNet, while fake counterparts are generated using HunyuanVideo and CogVideoX, conditioned on the first frame and a textual caption to ensure semantic alignment. This design eliminates superficial cues (e.g., duration, resolution) and forces models to focus on intrinsic visual realism. CoT annotations are generated using Qwen2.5-VL-72B, targeting motion consistency, lighting, texture artifacts, and physical plausibility violations, with ground-truth labels provided to guide the annotation process.
Model Architecture and Training Pipeline
VidGuard-R1 employs Qwen2.5-VL-7B as the base MLLM. The training pipeline consists of two stages:
- Supervised Fine-Tuning (SFT): The model is trained on the VidGuard-R1-CoT-30k subset to mimic annotated CoT rationales, establishing foundational reasoning and cross-modal alignment.
- Reinforcement Learning (RL) Fine-Tuning: The model is further refined on VidGuard-R1-RL-100k using Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO). DPO leverages pairwise preference data, while GRPO generalizes RLHF to group-level comparisons, enabling nuanced reward assignment.
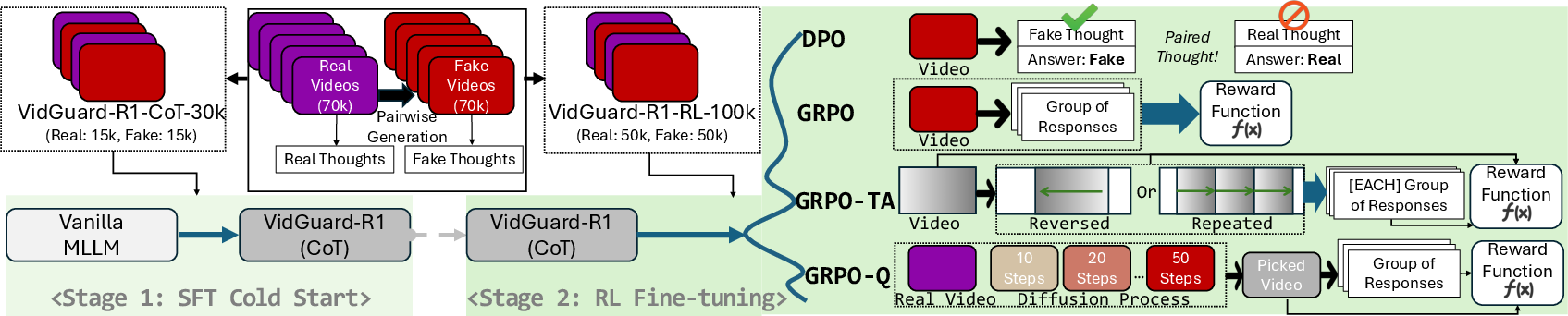
Figure 2: The overall training framework of VidGuard-R1, illustrating SFT for CoT initialization and RL-based fine-tuning for deeper reasoning.
GRPO Variants
- GRPO-TA (Temporal Artifacts): Temporal manipulations (segment repetition, frame reversal) are introduced to promote temporal reasoning. Rewards are asymmetrically assigned based on the difficulty of detecting artifacts in real vs. fake videos, with additional rewards contingent on correct predictions and group accuracy thresholds.
- GRPO-Q (Quality Evolutionary Videos): Diffusion-based generation is exploited by varying the number of reverse diffusion steps, producing videos of distinct quality levels. The reward function assigns partial credit based on the proximity of predicted and ground-truth diffusion steps, enabling fine-grained quality assessment.
Implementation Details
Training is conducted on four NVIDIA A100 GPUs (80GB). Videos are represented by up to 16 frames, resized to 28×28 and mapped to 128 feature channels. GRPO training samples 8 responses per input, with additional responses for temporally manipulated variants in GRPO-TA. SFT is performed for one epoch, followed by RL for approximately 2,000 steps.
Experimental Results
VidGuard-R1 variants outperform CNN and Transformer baselines, with GRPO-Q achieving the highest accuracy (86.17% on HunyuanVideo). SFT alone yields substantial gains over base MLLMs, but RL-based methods provide further improvements, especially with temporal and quality-aware reward modeling.
Benchmark Evaluation
On GenVidBench and GenVideo, VidGuard-R1 (GRPO) achieves mean Top-1 accuracy exceeding 97% and F1 scores up to 0.96, surpassing prior SOTA methods by over 15% in cross-source and cross-generator settings. Zero-shot generalization is demonstrated by pretraining on GenVideo and evaluating on GenVidBench.
Explanation Quality
LLM-as-a-Judge evaluations indicate that VidGuard-R1 (GRPO) variants consistently produce higher-quality rationales (scores >8.0) compared to baseline MLLMs, confirming the effectiveness of RL-based fine-tuning for interpretability.
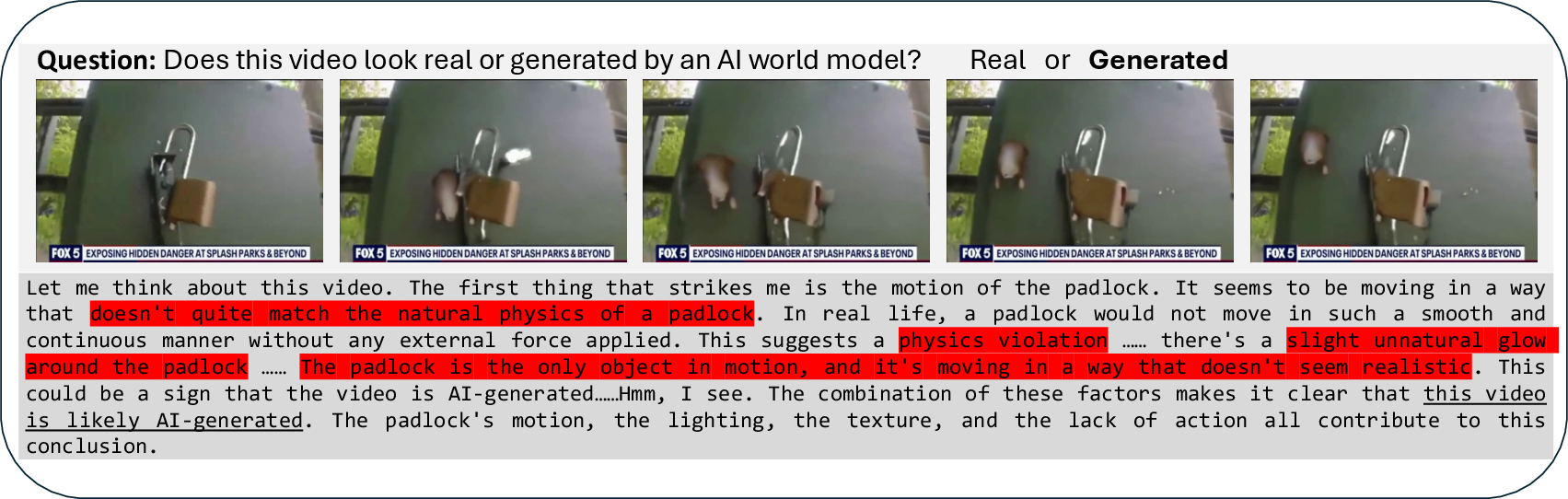
Figure 3: Example of VidGuard-R1's reasoning process, discriminating a fake video using multi-modal visual and temporal cues.

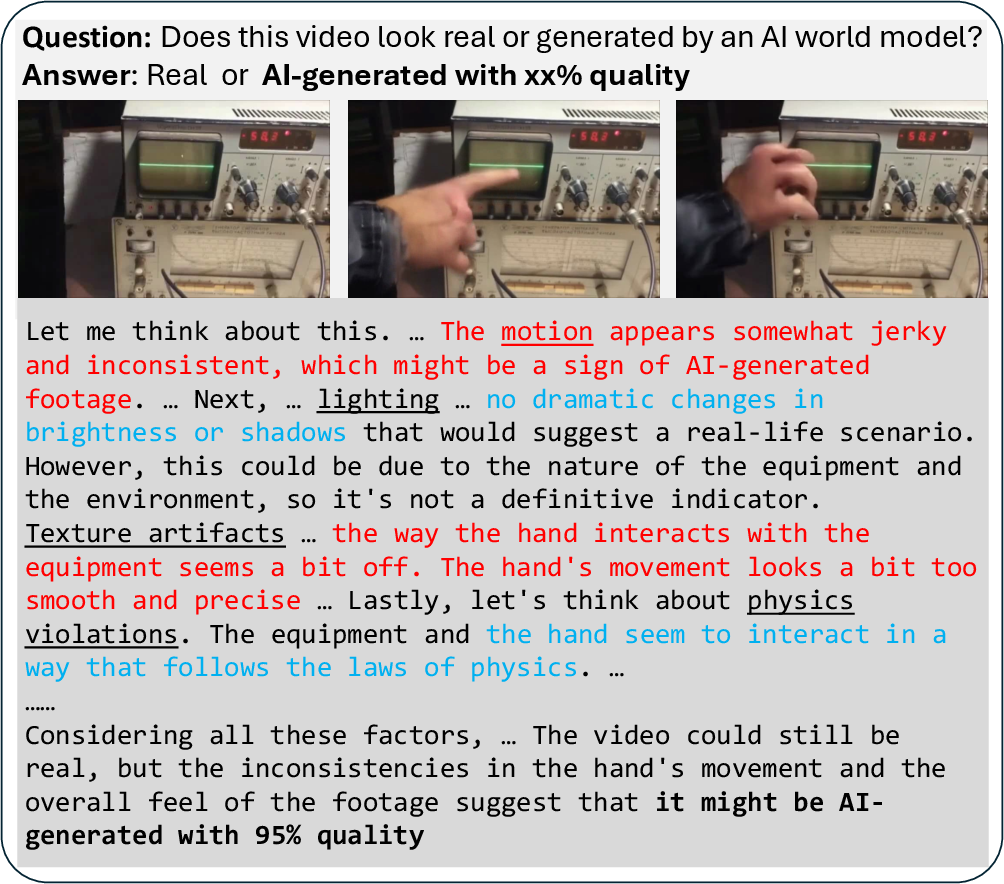
Figure 4: VidGuard-R1 (GRPO) reasoning about an origami folding sequence, highlighting multi-faceted evidence accumulation.
Ablation Studies
Reward parameter tuning in GRPO-TA and the number of diffusion steps in GRPO-Q directly impact detection accuracy, with optimal settings identified for both. Length-based reward strategies further promote concise and informative reasoning.
Case Studies
VidGuard-R1 demonstrates robust multi-factor reasoning, integrating cues from motion, lighting, texture, and physics. The model avoids reliance on single artifacts, instead accumulating evidence across frames and revising judgments as new information emerges.

Figure 5: Prompt for identifying realism cues in real videos across four categories.

Figure 6: Prompt for identifying artifacts in AI-generated videos across four categories.

Figure 7: LLM-as-a-Judge Prompt for Rationale Quality Evaluation.

Figure 8: VidGuard-R1 (GRPO) inference on a MuseV-generated video.

Figure 9: VidGuard-R1 (GRPO) inference on a Sora-generated video.
Limitations and Future Directions
The current dataset is limited to fake videos generated by HunyuanVideo and CogVideoX. Expanding to a broader range of generative models will enhance generalizability. Further research should explore reward modeling for more complex artifacts and extend the approach to real-world, adversarial scenarios.
Conclusion
VidGuard-R1 establishes a new paradigm for AI-generated video detection by integrating MLLMs with RL-based fine-tuning, achieving state-of-the-art accuracy and interpretable reasoning. The framework's modular reward design and robust generalization across benchmarks position it as a foundation for future research in multi-modal video forensics and explainable AI.