- The paper introduces a novel multimodal framework that formulates sounding object detection and sounding action discovery in egocentric videos.
- It employs slot attention-based visual encoding and object-aware masking to enhance performance on large-scale datasets like Ego4D and Epic Kitchens.
- Experimental results reveal top-1 accuracies up to 49.6% and improved AUC-ROC scores, highlighting the framework's applicability in robotics and assistive technologies.
Learning Object Sounds from Real-World Interactions: A Multimodal Object-Aware Framework
Introduction
The paper "Clink! Chop! Thud! -- Learning Object Sounds from Real-World Interactions" (2510.02313) presents a multimodal object-aware framework for associating object interactions in egocentric videos with their characteristic sounds. The authors introduce the sounding object detection task, which requires models to identify the specific objects responsible for producing sounds in a scene, and complement this with the sounding action discovery task, which determines whether an action is responsible for the observed sound. The approach leverages large-scale egocentric datasets (Ego4D, Epic Kitchens), automatic object mask annotation, and slot attention-based visual encoding to achieve state-of-the-art performance on both tasks.
The sounding object detection task is defined as follows: given a set of object regions (segmentation masks) in a video frame and the corresponding audio, the model predicts which object(s) are directly involved in producing the sound. This formulation differs from traditional audiovisual localization, focusing on semantic object-sound relationships rather than precise spatial boundaries. The evaluation metric is top-1 accuracy, emphasizing correct object identification over boundary alignment.
For sounding action discovery, the model performs binary classification to determine if the action depicted in the video is responsible for the sound, leveraging visual, audio, and language modalities. The benchmark includes manually annotated segmentation masks for ground truth objects, enabling rigorous evaluation.

Figure 1: Examples of annotated frames from Ego4D from the benchmark, visualizing segmentation masks (red and green) of ground truth objects.
Model Architecture and Object-Aware Representation
The framework consists of modality-specific encoders for vision (slot attention-based), audio (AST), and language (CLIP). The visual encoder is initialized from a slot attention model pretrained on MS COCO, which compresses image features into slot vectors, each attending to distinct object regions. Object segmentation masks are used to guide the model's focus during training, applied at the embedding level rather than the input level to preserve contextual background information.
The object-aware visual features are constructed by patchifying both the image and the mask, computing per-patch objectness scores, and pooling the relevant patch embeddings into a single visual embedding vector. This process ensures that the model attends to the most informative regions associated with object interactions.
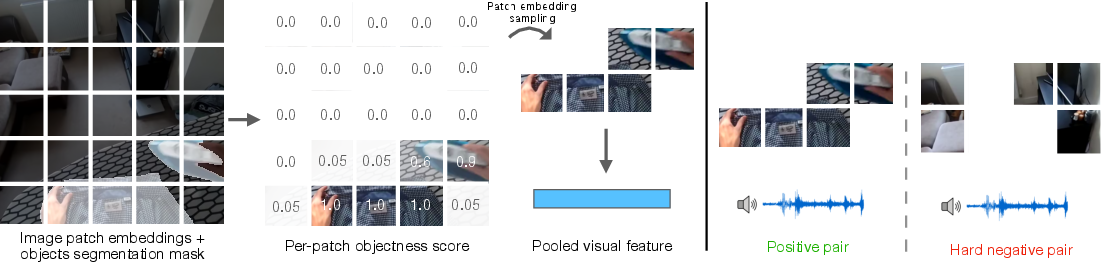
Figure 2: Left: Object-aware visual features using segmentation masks to select patch embeddings. Right: Hard negatives paradigm in finetuning, sampling negatives from non-interaction regions.
Training Framework
The training procedure consists of three stages:
- Align Stage: Contrastive alignment of modality embeddings using InfoNCE loss, bringing together embeddings from the same sample and pushing apart those from different samples.
- Refine Stage: Multimodal consensus coding loss penalizes disagreement among modality similarity scores within a sample, enforcing consistent cross-modal alignment.
- Finetune Stage: Hard negatives contrastive loss is introduced for sounding object detection, sampling negatives from background regions within the same image to encourage localized understanding.
The model is pretrained on large-scale automatically annotated data and finetuned on manually annotated benchmarks. The slot attention encoder and object-aware masking are empirically validated to provide significant performance gains.
Experimental Results
Sounding Object Detection
The proposed model achieves top-1 accuracy of 49.6% on Epic Kitchens and 43.9% on Ego4D, outperforming previous state-of-the-art methods (SoundingActions, SLAVC, SSLAlign, DenseAV) by substantial margins (up to 11.8% improvement). Ablation studies demonstrate that both slot attention and object-aware masking independently improve performance, but their combination yields the best results.
Qualitative results show that the model can accurately rank object regions by their audiovisual similarity scores, effectively identifying the sounding object even in complex scenes.

Figure 3: Qualitative results for sounding object detection, showing original frame, ground truth mask, and audiovisual similarity scores for object regions.
Sounding Action Discovery
On the sounding action discovery task, the model achieves AUC-ROC of 0.617 (audio-vision) and 0.630 (audio-language), surpassing foundational multimodal models (ImageBind, LanguageBind) and previous state-of-the-art. The object-aware approach provides a measurable boost even for global reasoning tasks, indicating the value of localized, object-centric representations.
Clustering analysis of visual embeddings reveals that the model learns to group diverse visual scenes by their associated sounds, e.g., frames with the sound of flowing water, regardless of background appearance.

Figure 4: Frames from the same cluster of visual embeddings, all corresponding to the sound of flowing water.
Implementation Considerations
- Computational Requirements: Training is performed on four A40 GPUs with batch size 128. The slot attention encoder is frozen except for the decoder, reducing memory overhead.
- Automatic Annotation: Object masks are generated using hand-object interaction detection and SAM 2, enabling scalable training without manual annotation.
- Deployment: The model can be applied to real-world egocentric video streams for object-sound association, with inference requiring only a single frame, audio segment, and candidate object masks.
- Limitations: The approach assumes the presence of hand-object interactions and may be less effective for non-manipulated objects or ambiguous audio cues.
Implications and Future Directions
The framework demonstrates that object-aware multimodal learning, guided by segmentation masks and slot attention, is critical for associating subtle object interactions with their sounds. This has implications for robotics (action understanding, manipulation feedback), assistive technologies (audio-visual scene analysis), and multimodal foundation models.
Future work may explore:
- Extending to non-egocentric or third-person videos.
- Incorporating temporal dynamics for sequential action-sound reasoning.
- Improving automatic mask annotation for non-hand-centric interactions.
- Scaling to more diverse environments and object categories.
Conclusion
This work establishes a robust multimodal object-aware framework for learning the relationship between object interactions and their sounds in real-world egocentric videos. By integrating slot attention-based visual encoding and object-aware masking, the model achieves state-of-the-art performance on both sounding object detection and sounding action discovery tasks. The results highlight the necessity of localized, object-centric representations for fine-grained multimodal understanding and open avenues for further research in scalable, real-world multimodal learning.