- The paper introduces a bifurcated pretraining strategy that separates long-tail and common knowledge using hierarchical memory banks.
- It details a memory retrieval system based on hierarchical clustering that minimizes interference when storing rare knowledge.
- Empirical results show that a small anchor model with hierarchical memory augmentation can match the performance of larger models with fewer parameters.
Pretraining with Hierarchical Memories: Separating Long-Tail and Common Knowledge
Introduction
This paper proposes a novel approach to pretraining LLMs that involves augmenting small LLMs with large hierarchical memory banks. This approach aims to offload long-tail knowledge into expandable memory parameters, while the core model acts as an anchor for common knowledge and general reasoning. This bifurcation allows efficient deployment and operation on edge devices with memory constraints.
Model Architecture
The architecture comprises small base models called anchor models which contain compact common knowledge and reasoning capabilities. These are supplemented by large hierarchical memory banks that store long-tail knowledge needed for specific tasks. The memories are accessed in a context-dependent manner through a learned retriever mechanism.
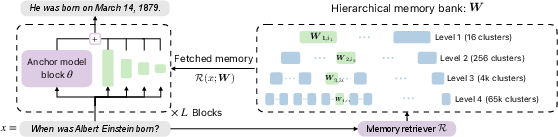
Figure 1: Proposed architecture: Memory retrieval based on hierarchical clustering of pretraining data.
Pretraining Strategy
The pretraining strategy involves two main components: hierarchical clustering of data to organize memory access, and a training objective that minimizes forgetting by associating memory parameters with clusters of semantically related documents. This approach seeks to improve the retention of rare knowledge by reducing interference from destructively updated gradients.
Hierarchical Memories and Retrieval
Memory parameters are organized into hierarchical clusters. This structure allows efficient retrieval by aligning with hardware memory hierarchies (e.g., RAM, flash storage). During inference, only a relevant subset of these parameters is fetched and used alongside the anchor model, keeping computational overhead minimal.
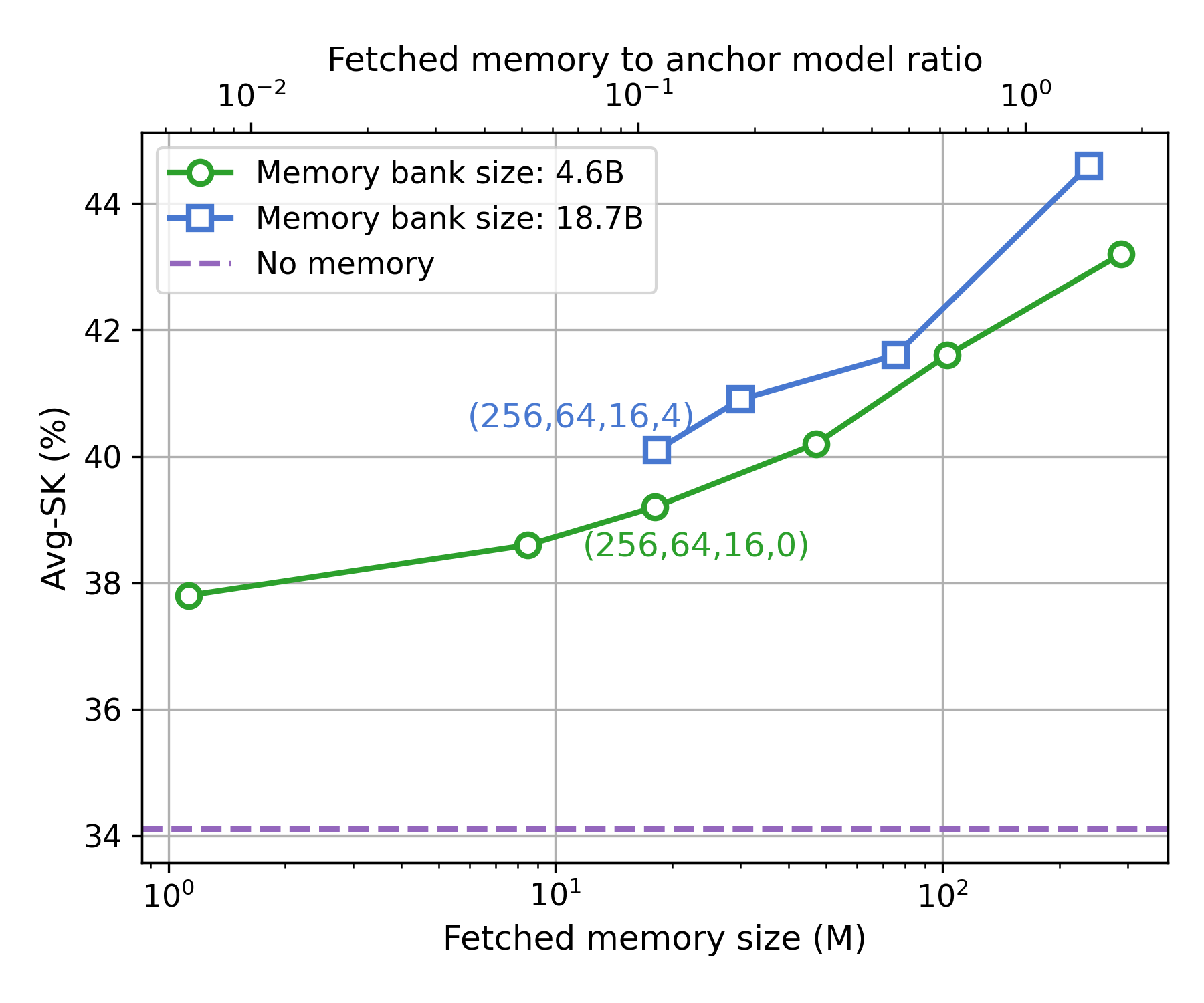
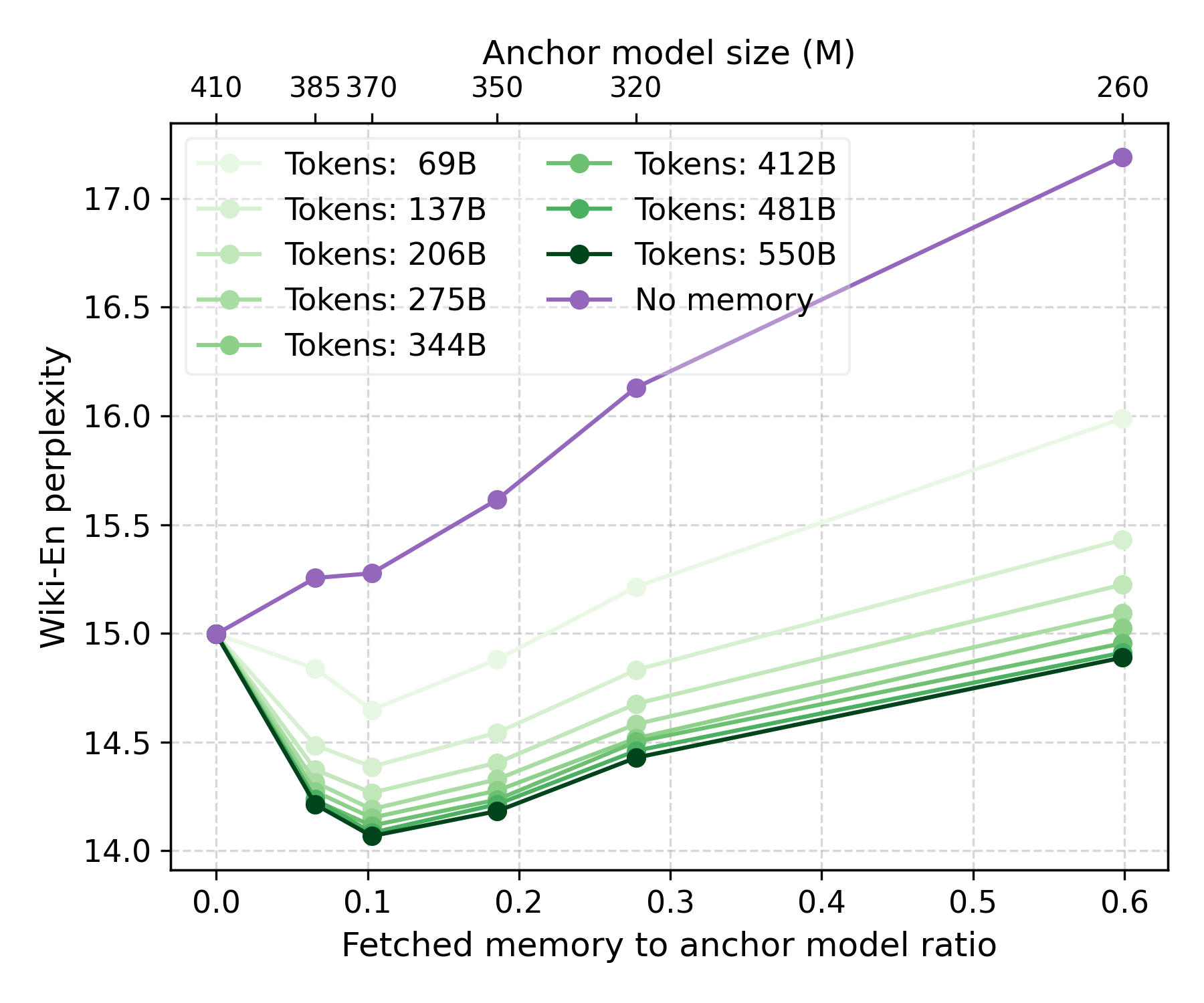
Figure 2: Performance gains with larger bank sizes and fetched memory sizes in hierarchical setups.
Empirical Evaluation
Extensive experiments demonstrate that models with hierarchical memories significantly outperform traditional large models for specific knowledge tasks. For instance, a 160M parameter model with an 18M parameter memory fetch can perform equivalently to a model with more than double the total parameters.
Deployment Considerations
The hierarchical memory structure allows models to exploit existing memory hierarchies in hardware for faster deployment. Models can remain small during runtime, with the flexible memory allowing specific data privacy and editing capabilities.
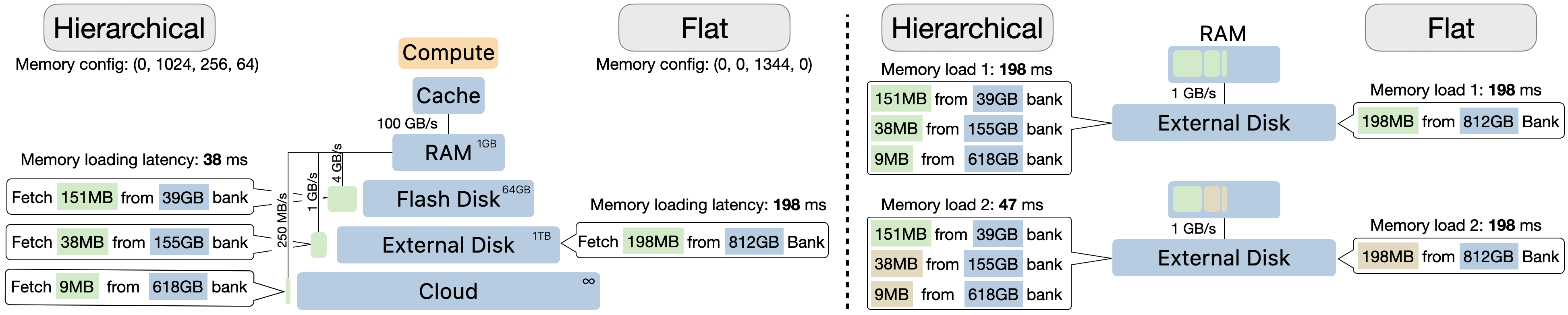
Figure 3: Deployment advantages of hierarchical memories, showing reduced latency and improved compositional efficiency.
Results and Discussion
The paper reports comprehensive results across various benchmarks, demonstrating notable improvements in specific knowledge tasks while maintaining competitive performance in common knowledge tasks. The reduction in perplexity on Wikipedia datasets further highlights the efficacy of this approach. Moreover, the hierarchical memories can be adapted post-hoc to different models, enhancing their flexibility and applicability.
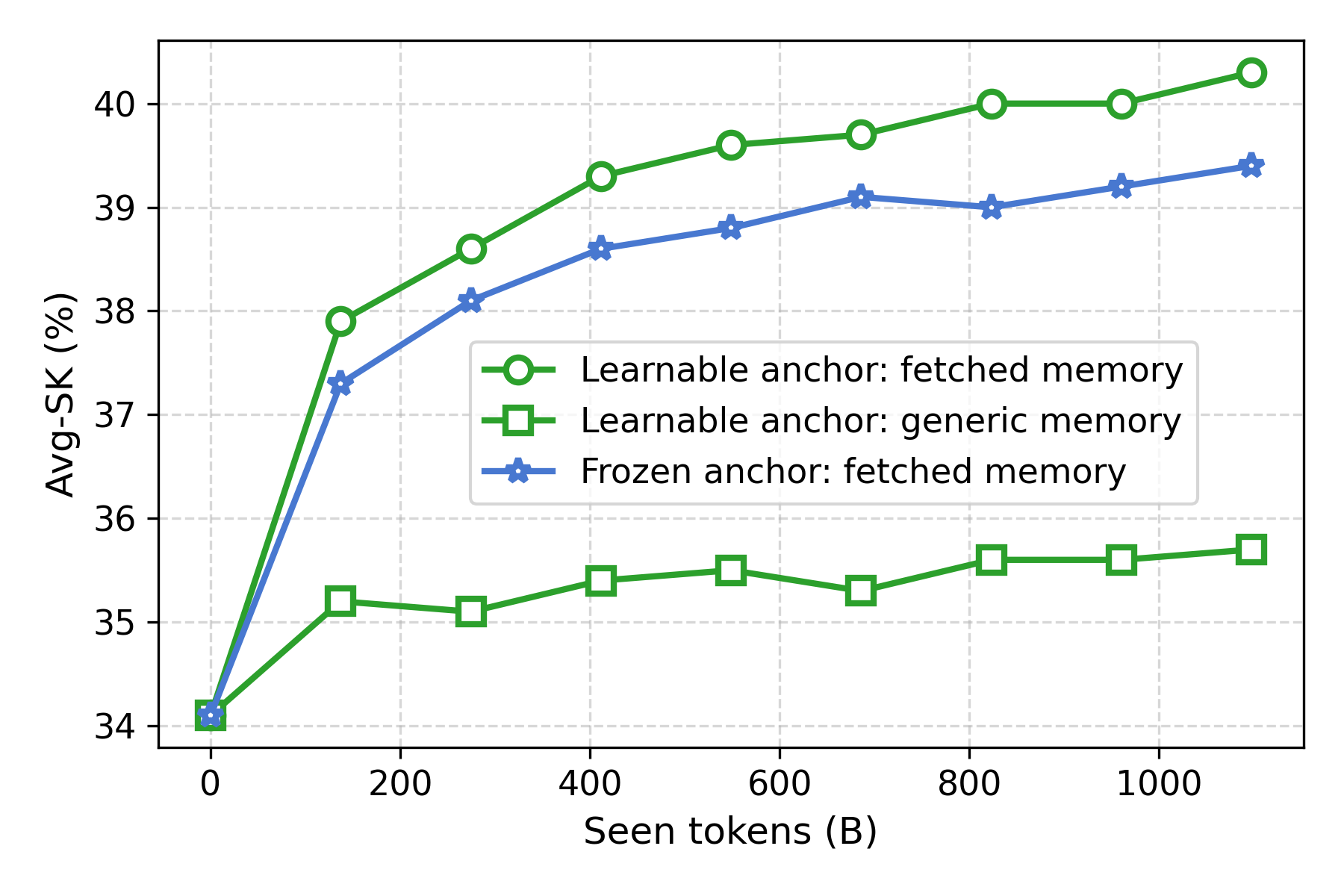
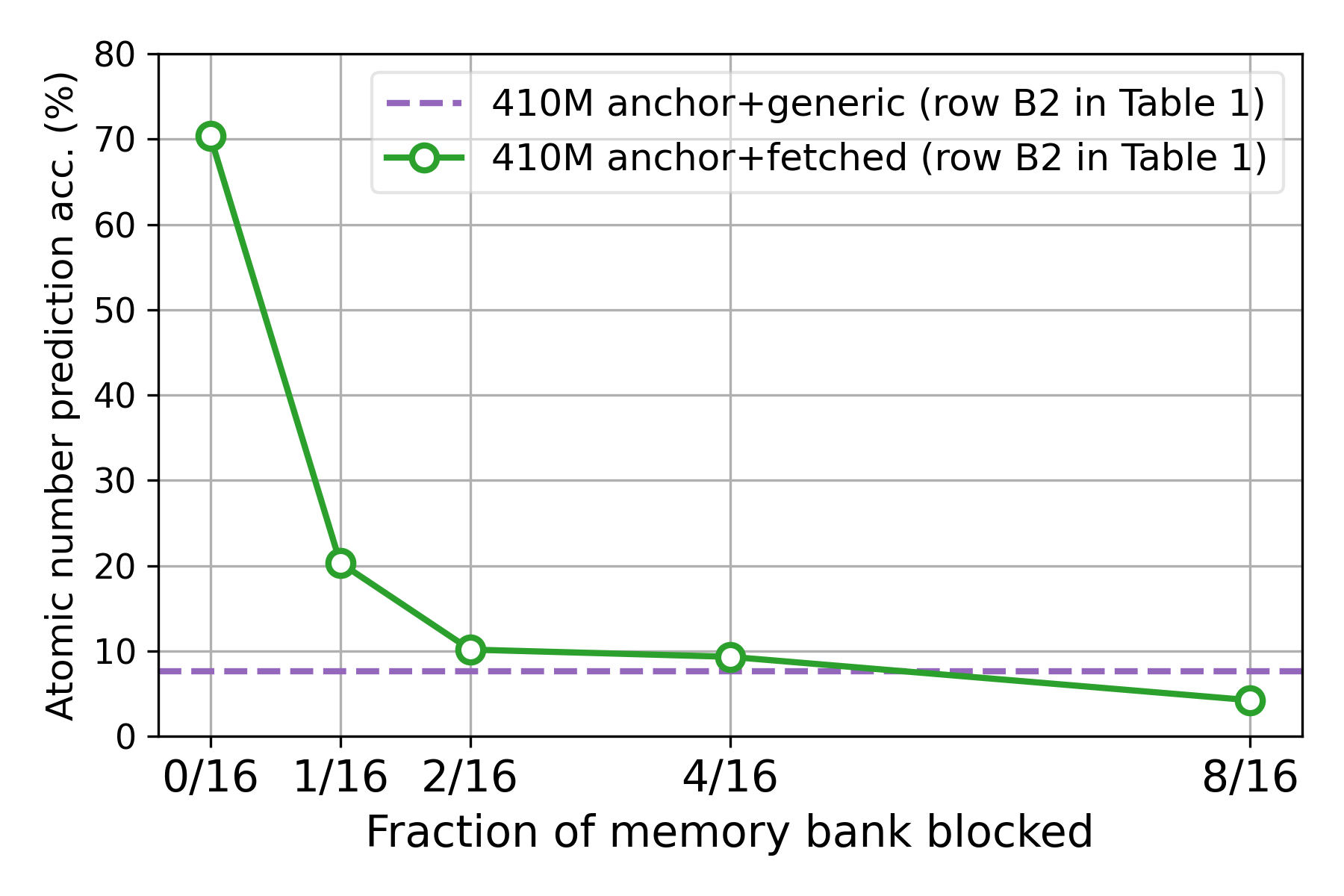
Figure 4: Co-training effects of hierarchical memories and anchor model parameters.
Conclusion
The paper presents compelling evidence for the superiority of memory-augmented architectures in managing long-tail and common knowledge separately. This setup not only enables efficient execution on limited-resource devices but also aligns well with privacy-centric applications where selective memory access is paramount.
Future research could explore scaling laws for memory learning, optimizing anchor model architectures, and extending this framework to other data modalities and multilingual contexts. The integration of hierarchical memories into existing LLM frameworks opens new directions for optimizing both training and inference efficiencies.
In summary, hierarchical memory augmentation offers a promising avenue for developing more efficient and capable LLMs within the constraints of practical deployment scenarios.