- The paper introduces Hyper-Kernel Ridge Regression (HKRR), which integrates classical kernel methods with neural network components to learn Multi-Index Models.
- It provides a detailed theoretical analysis of sample complexity, demonstrating exponential sample size dependency on transformation dimension and polynomial dependency on input dimension.
- Experimental results show that HKRR, optimized via VarPro and AGD, outperforms traditional methods by effectively mitigating the curse of dimensionality.
Learning Multi-Index Models with Hyper-Kernel Ridge Regression
Introduction
The paper "Learning Multi-Index Models with Hyper-Kernel Ridge Regression" (2510.02532) introduces a methodology that combines classical kernel methods with concepts from neural networks, aiming at learning Multi-Index Models (MIMs). This approach, termed Hyper-Kernel Ridge Regression (HKRR), exploits the compositional structure of data where a linear transformation is followed by a nonlinear function, allowing adaptive learning that circumvents the curse of dimensionality typically associated with high-dimensional data analysis.
Theoretical Framework
Sample Complexity Analysis:
HKRR is designed to perform well in high-dimensional spaces by learning MIMs whose structure involves a linear data transformation followed by a smooth nonlinearity. The paper provides theoretical insights into the sample complexity of HKRR, showing that it adapts to the transformation dimension rather than the input dimension. Specifically, the dependency on sample size through dimensionality is exponential in the transformation dimension divided by smoothness and polynomial in the input dimension, thereby addressing the curse of dimensionality efficiently.
Excess Risk Bound:
Under the assumption that the target function resides within a specified smooth subspace, the paper derives an excess risk bound. This shows that HKRR achieves an approximation error rate proportional to m−θζ, where ζ relates to smoothness and dimensionality ratio, and θ is a smoothness parameter.
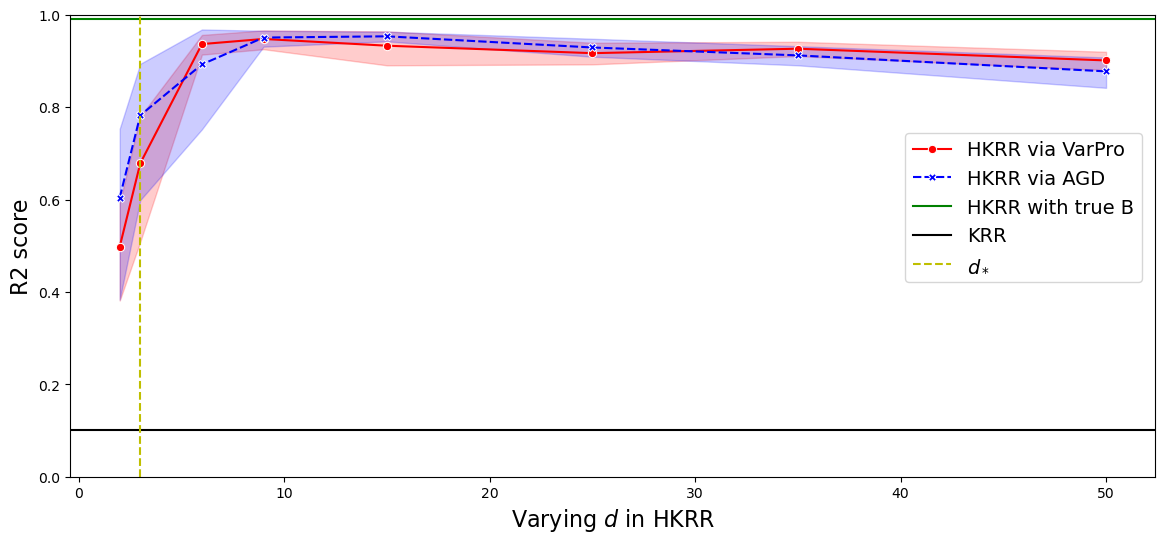
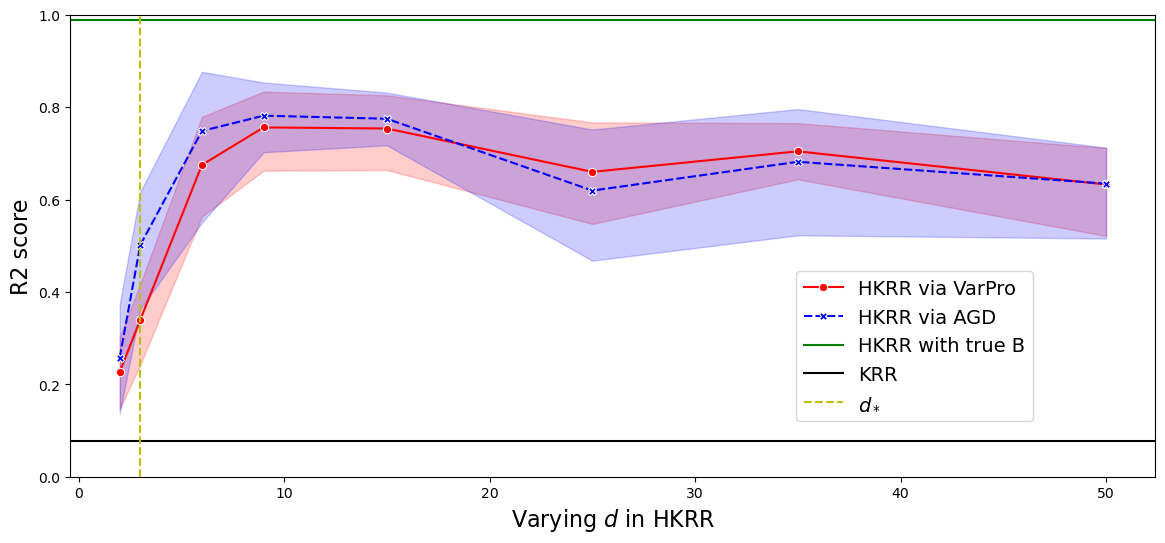
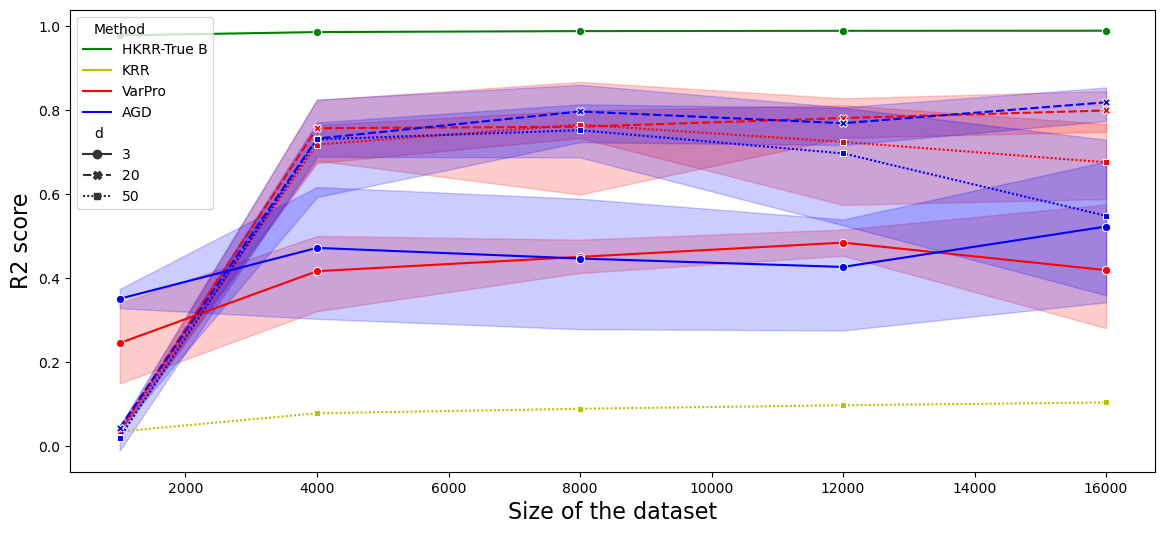
Figure 1: R2 score on test sets for B and alpha learned by VarPro and AGD, illustrating performance differences across various model sizes.
Optimization Algorithms
Variable Projection (VarPro) vs. Alternating Gradient Descent (AGD):
The optimization problem in HKRR is inherently non-convex due to the adjustable linear transformation matrix. Two algorithms are proposed to solve it: VarPro and AGD.
Numerical Experiments
In the numerical section, HKRR surpasses traditional kernel methods by exploiting compositional structure and reducing dimensionality impact. Results highlight:
Conclusion
HKRR provides a compelling framework that not only blends kernels and neural networks but also adapts these techniques to data structures that are compositional in nature. By doing so, it highlights a pathway to mitigating dimensionality-related challenges in machine learning, offering both theoretical understanding and practical tools to enhance model learning efficiency. Future work could focus on extending these principles to broader compositional structures beyond MIMs and refining algorithmic performance even further.