Geometry Meets Vision: Revisiting Pretrained Semantics in Distilled Fields
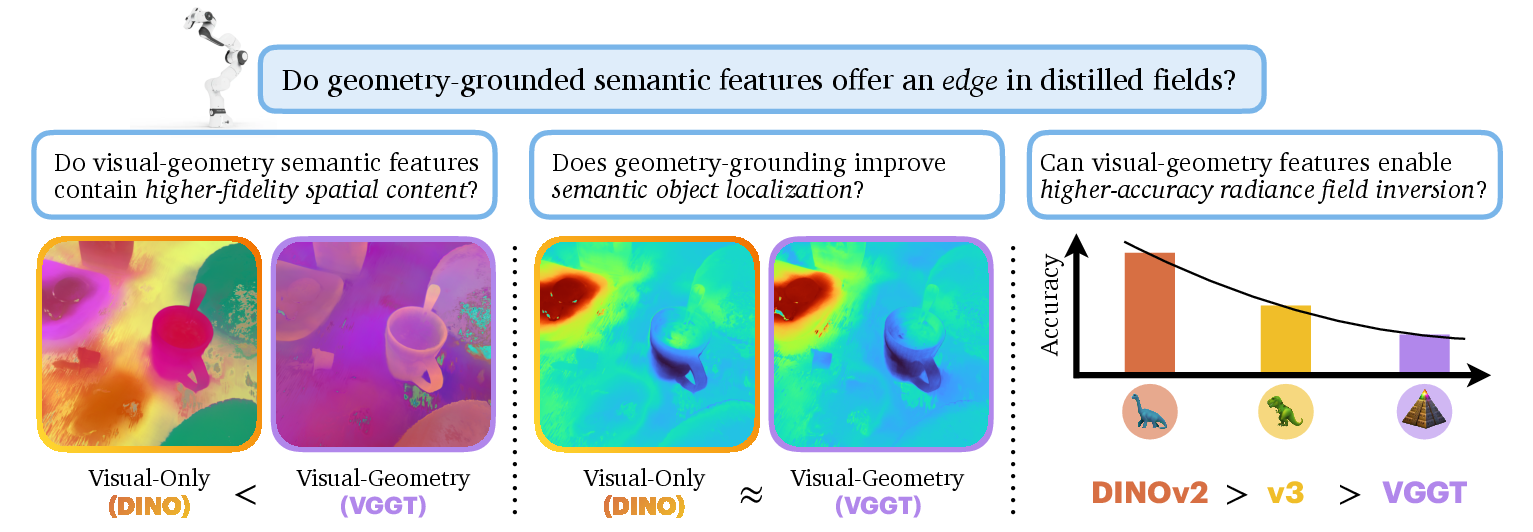
Abstract: Semantic distillation in radiance fields has spurred significant advances in open-vocabulary robot policies, e.g., in manipulation and navigation, founded on pretrained semantics from large vision models. While prior work has demonstrated the effectiveness of visual-only semantic features (e.g., DINO and CLIP) in Gaussian Splatting and neural radiance fields, the potential benefit of geometry-grounding in distilled fields remains an open question. In principle, visual-geometry features seem very promising for spatial tasks such as pose estimation, prompting the question: Do geometry-grounded semantic features offer an edge in distilled fields? Specifically, we ask three critical questions: First, does spatial-grounding produce higher-fidelity geometry-aware semantic features? We find that image features from geometry-grounded backbones contain finer structural details compared to their counterparts. Secondly, does geometry-grounding improve semantic object localization? We observe no significant difference in this task. Thirdly, does geometry-grounding enable higher-accuracy radiance field inversion? Given the limitations of prior work and their lack of semantics integration, we propose a novel framework SPINE for inverting radiance fields without an initial guess, consisting of two core components: coarse inversion using distilled semantics, and fine inversion using photometric-based optimization. Surprisingly, we find that the pose estimation accuracy decreases with geometry-grounded features. Our results suggest that visual-only features offer greater versatility for a broader range of downstream tasks, although geometry-grounded features contain more geometric detail. Notably, our findings underscore the necessity of future research on effective strategies for geometry-grounding that augment the versatility and performance of pretrained semantic features.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Geometry Meets Vision: Revisiting Pretrained Semantics in Distilled Fields”
1) What is this paper about?
This paper looks at how robots can understand and use 3D scenes by combining two things:
- “Radiance fields,” which are 3D models that can make realistic pictures from different camera angles.
- “Pretrained semantics,” which are smart features learned by big vision models (like CLIP or DINO) that know what things are in an image (dogs, cups, tables, etc.) without needing special labels for each new task.
The authors ask: If we train vision models to understand 3D geometry better (not just 2D appearance), does that help robots do spatial tasks—like finding objects or figuring out where a camera is—inside these 3D radiance fields?
2) What questions did the researchers try to answer?
They focus on three clear questions:
- Do geometry-aware features (trained to understand 3D structure) hold more detailed shape information than regular visual features?
- Do these geometry-aware features help robots find objects more accurately in a 3D scene?
- Do these features help solve the “inverse” problem—guessing the camera’s position and angle from a single picture—more accurately?
Short answers:
- Yes, geometry-aware features contain sharper and richer shape details (like edges and outlines).
- No, they don’t improve object finding compared to regular visual features.
- Surprisingly, no—geometry-aware features actually made camera pose estimation worse in their tests.
3) How did they do it? (Methods explained simply)
Here are the key ideas and tools, described in everyday language:
- Radiance fields: Think of a 3D scene as a “cloud” that stores color and visibility everywhere. You can “look” at it from any angle to render a realistic image.
- NeRF (Neural Radiance Fields): A neural network learns the 3D scene so it can render images from any viewpoint.
- Gaussian Splatting: Instead of a neural network, the scene is built from lots of tiny 3D blobs (“Gaussians”) that are fast to render.
- Pretrained semantics: Big vision models like DINO and CLIP learn general features from huge amounts of images (and in CLIP’s case, text too). These features help identify and describe objects in images.
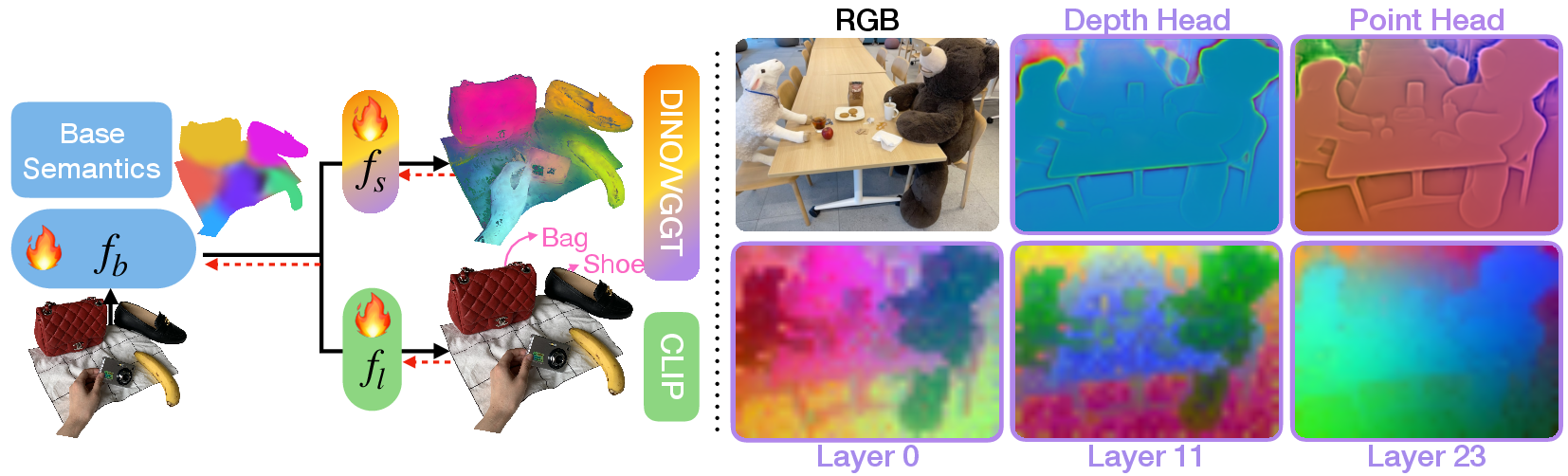
- Geometry-grounding: A newer model (VGGT) is trained to also understand 3D geometry (like depth and camera motion). The hope is that having true 3D awareness will help with spatial tasks.
- Distillation: The team “bakes” these features (DINO or VGGT, plus CLIP for language) into the 3D radiance field, so every point in the 3D scene has semantic meaning (e.g., “this point is part of a mug”).
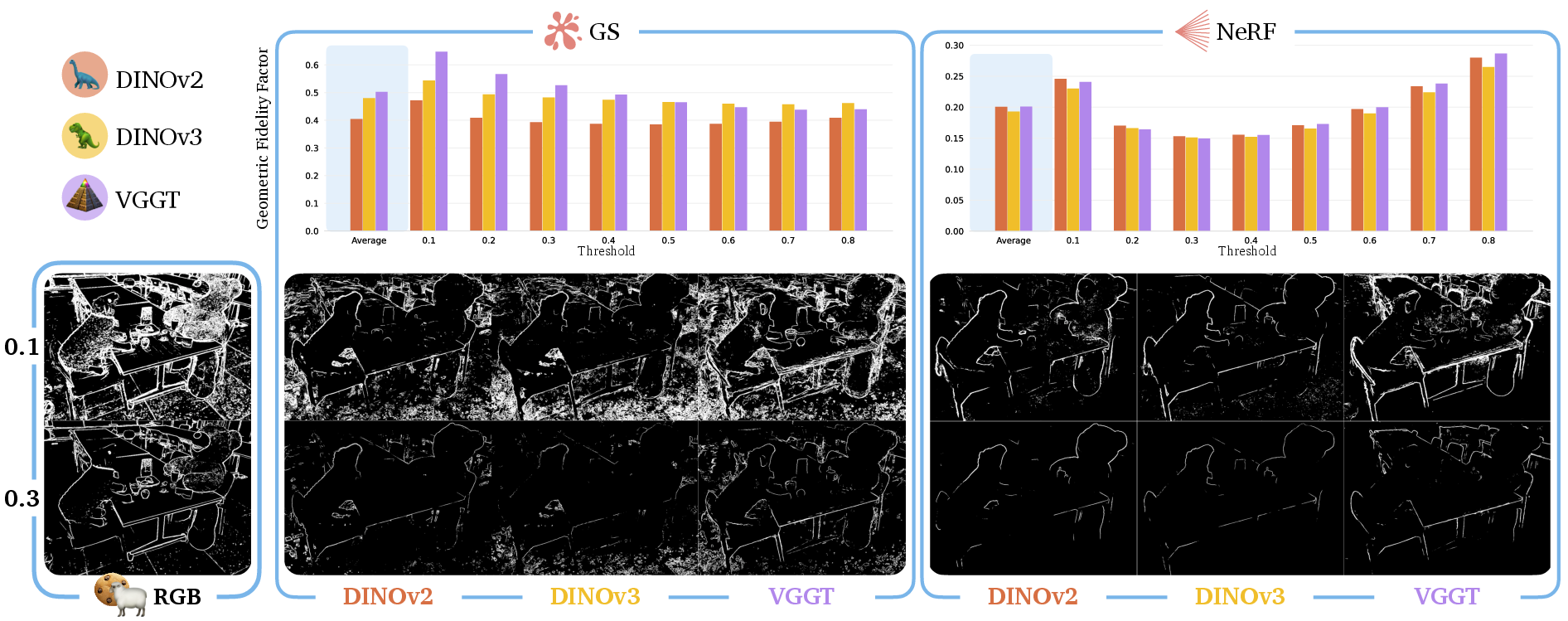
- Measuring shape detail: They project the complex features down to 3 colors (for visualization) and then count edges using a simple edge detector. This gives a “geometric fidelity factor” (GFF), which tells how much shape detail is present in the features.
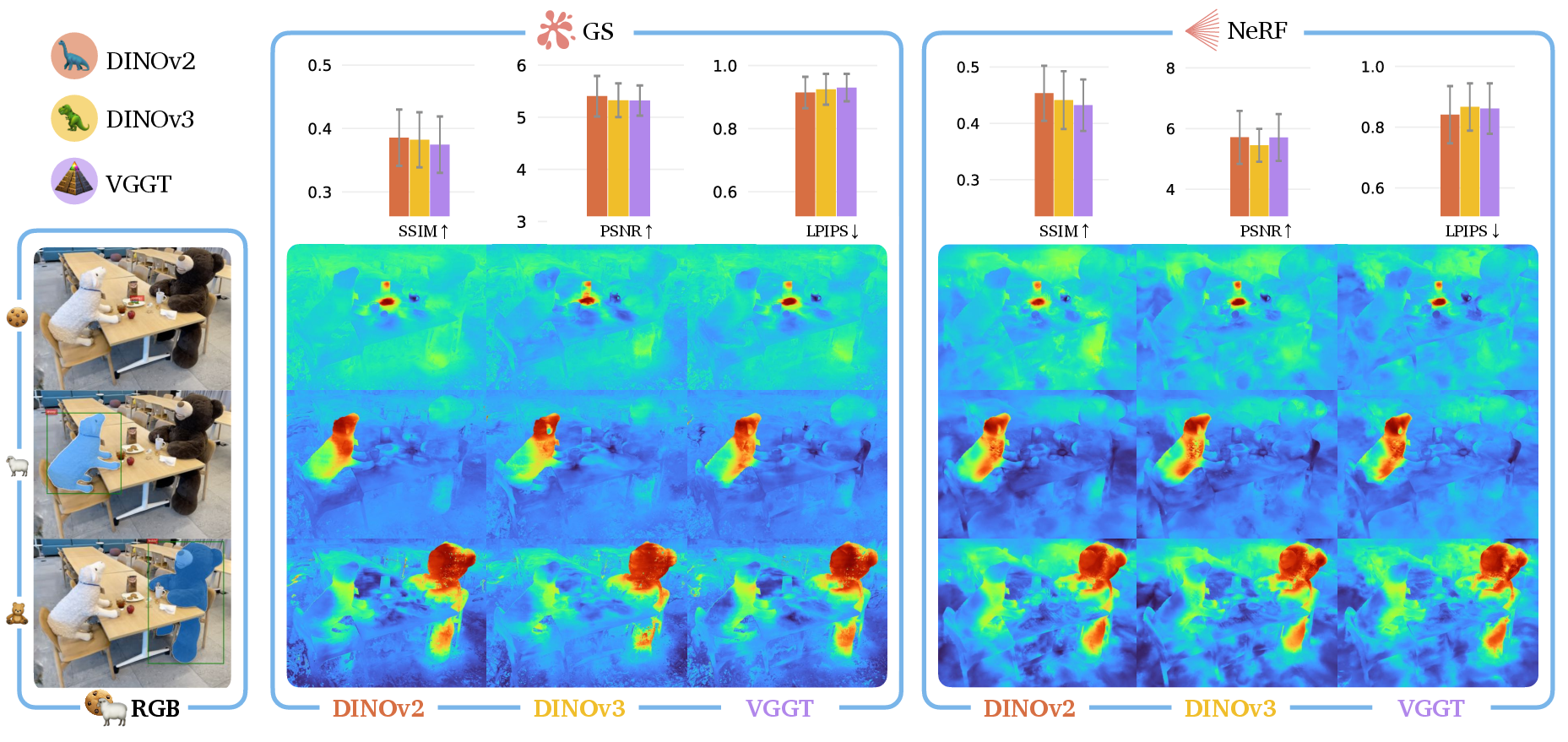
- Finding objects (“semantic localization”): Given a short text like “mug,” they use CLIP to score how well each part of the scene matches that word and make a “heatmap.” They compare this to a ground-truth segmentation mask using common image quality scores (SSIM, PSNR, LPIPS).
- Inverting radiance fields (figuring out camera pose from a single image): They introduce a new two-step method called SPINE:
- Step 1 (coarse): Use distilled semantics to get an initial guess of the camera’s position and angle.
- Step 2 (fine): Render an image from that guess, match features between the real and rendered images, and refine the camera pose using a robust math method (PnP with RANSAC), which helps ignore bad matches.
SPINE is important because many older methods need a good initial guess. SPINE works without one.
4) What did they find, and why does it matter?
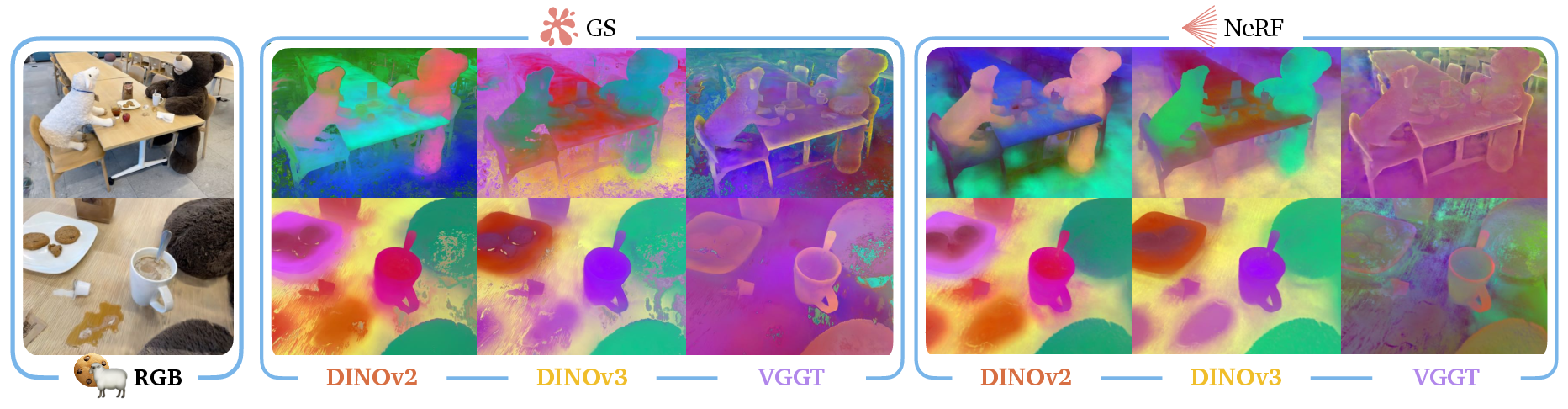
- Geometry-aware features (VGGT) really do capture sharper shapes—edges, outlines, and structure look clearer than with regular visual features (DINO).
- For object finding, geometry-aware features did not beat regular visual features. Both worked about the same for locating things in the scene.
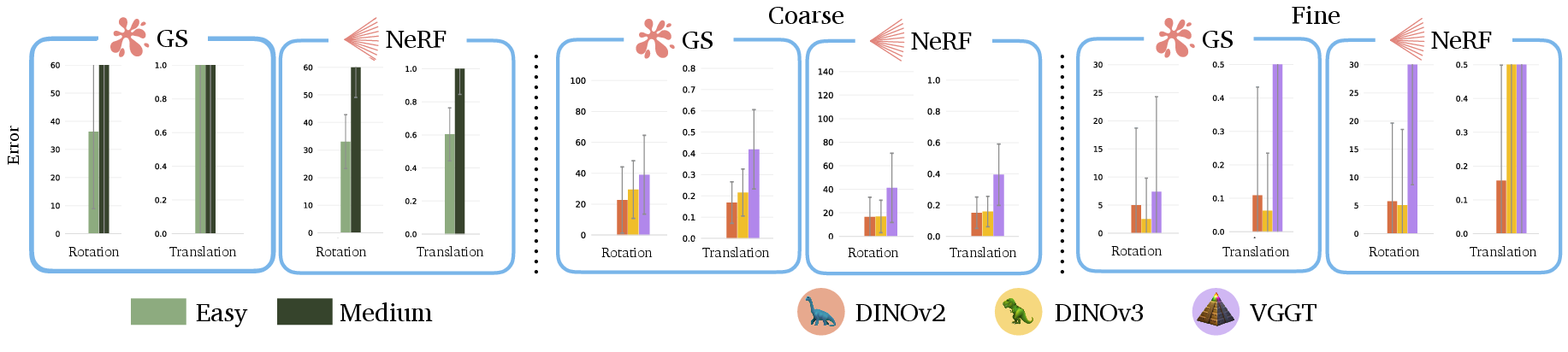
- For camera pose estimation (the inverse problem), geometry-aware features performed worse than regular visual features. In their new SPINE system, DINO-based features gave better initial camera guesses and led to more accurate final results.
Why it matters:
- Many robot tasks depend on finding objects and knowing where the camera or robot is in space. You might expect “more 3D-aware” features to help—but they didn’t here.
- Regular visual features (DINO) seem more “versatile” for these tasks today.
- SPINE itself is useful: it can recover camera pose without an initial guess, which is a big practical improvement.
5) What’s the big takeaway and future impact?
- Right now, geometry-grounded features give nicer shape detail but don’t necessarily help with common robot tasks in 3D radiance fields, and can even hurt pose estimation.
- This suggests we need better ways to teach geometry to vision models so they keep their flexibility and usefulness for many tasks.
- The authors point to future directions:
- More effective training strategies (possibly self-supervised) for geometry grounding.
- Better ways to combine geometry and visual cues so they truly help object finding and pose estimation.
- Faster, lighter geometry-aware models so robots can use them in real time.
If you’re building robot systems today, the results suggest sticking with strong visual features like DINO (plus CLIP for language) might be the safer, more reliable choice—while research continues to improve geometry-aware models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or left unexplored, framed to guide concrete follow-up research.
- Mechanistic understanding of the performance gap: Why do geometry-grounded features (VGGT) carry richer geometric detail yet underperform visual-only features (DINO) in semantic localization and radiance field inversion? Identify causal factors via controlled ablations (e.g., loss forms, co-supervision coupling, backbone capacity, overfitting to geometric tasks, domain mismatch).
- Alternative geometry-grounding strategies: Evaluate self-supervised, multi-task, and contrastive 3D objectives (e.g., photometric + geometric consistency, cross-view contrastive learning) to reduce inductive biases of supervised grounding while preserving object-level semantics.
- Backbone and encoder diversity: Extend comparison beyond VGGT and DINO to other spatially grounded/visual models (e.g., DepthAnything, SAM-derived features, LoFTR, Uni3D) and language encoders (CLIP ViT-L/14, SigLIP). Quantify effects of embedding dimension, layer selection, and head choice (depth, point, tracking) on downstream tasks.
- Cross-modal fusion design: The shared hashgrid “base semantics” coupling CLIP with VGGT/DINO may bias content. Ablate separate vs shared encodings, cross-attention/FiLM fusion, and late vs early fusion to assess whether alternative architectures improve synergy between geometry and language semantics.
- Loss function choices and weighting: Current distillation uses Frobenius + cosine similarity; it excludes contrastive (InfoNCE), triplet, and cross-modal alignment losses. Systematically evaluate loss formulations, temperature scaling, and modality-specific weighting to enhance semantic alignment and retention of object-level cues.
- Validity of the geometric fidelity factor (GFF): Sobel edge fraction is a coarse proxy and can be confounded by texture, noise, lighting, and view-dependent effects. Benchmark geometric content against ground-truth or estimated depth/normal maps, multi-view 3D consistency metrics, learned edge/structure detectors, and analyze threshold sensitivity.
- Threshold-free semantic localization metrics: Reliance on SSIM/LPIPS/PSNR bypasses IoU but weakly measures semantic overlap. Develop threshold-free probabilistic IoU (calibrated via uncertainty), precision-recall curves with learned thresholding, or calibration metrics (ECE) for relevancy maps; report sensitivity to canonical prompt selection.
- Canonical prompts design: The negative prompt set (“object,” “stuff,” “things”) is ad hoc. Perform systematic prompt engineering/optimization (prompt ensembling, learned prompts, category-specific negatives) and quantify its impact on localization accuracy across scenes and object types.
- Dataset scope and generalization: The nine scenes are static, mostly indoor, and limited in diversity. Test larger-scale, outdoor, high-dynamic-range, highly reflective/textureless, occluded, and dynamic scenes (moving objects, lighting changes), including severe domain shifts (robot-mounted cameras vs smartphone).
- Representation-dependent effects: Differences between Gaussian Splatting and NeRF are reported but not deeply analyzed. Ablate the influence of explicit vs implicit representation, training schedules, depth quality, rasterization vs volumetric rendering, and regularization on semantic distillation and inversion outcomes.
- Inverse model specification clarity: The pose “distribution” and GMM are mentioned without explicit parameterization, training objective, or uncertainty handling. Specify p_ψ architecture, output distribution family (e.g., mixture components, covariance), loss functions (NLL vs MSE), and calibration methods; compare to alternatives (diffusion models, retrieval-based estimators).
- Coarse-to-fine inversion robustness: Fine-stage success depends on coarse error magnitude, but convergence basins and failure modes are not quantified. Characterize error thresholds for success, analyze sensitivity to occlusion/texture, and explore more robust refinements (joint bundle adjustment, differentiable PnP, photometric + geometric joint optimization).
- Feature matching details: The correspondence extraction between query and rendered images is unspecified. Compare matching backbones (DINO, VGGT tracking head, SuperPoint/SuperGlue, LoFTR), descriptor normalization, and RANSAC settings; quantify their impact on PnP robustness and final pose accuracy.
- Camera intrinsics assumptions: Fine inversion assumes known intrinsics K. Assess sensitivity to calibration errors and develop joint intrinsics/extrinsics estimation or self-calibration variants within SPINE.
- Temporal and multi-view extensions: The study focuses on single-image inversion. Extend SPINE to multi-view/sequences (using tracklets or temporal priors) and quantify gains from temporal consistency and VGGT’s tracking head.
- Computational efficiency and deployment: Geometry-grounded backbones are compute-heavy. Quantify training/inference costs, memory overhead for dual semantic fields, and real-time feasibility; investigate lightweight grounded backbones, student-model distillation, pruning/quantization, and edge-device deployment.
- Teacher-feature preprocessing: Precomputing VGGT features may introduce domain mismatch and stale supervision. Compare online vs offline feature extraction, domain-adaptive fine-tuning of the teacher, and data augmentation strategies; evaluate robustness to noise and out-of-distribution inputs.
- Metric-task correlations: It is unclear whether higher GFF correlates with better downstream performance. Establish statistical or causal links between geometric fidelity and localization/inversion accuracy; identify thresholds or regimes where geometry-grounding helps.
- Dynamics and editability: The pipeline assumes static scenes. Evaluate robustness under dynamic objects, scene edits, and changing illumination; test whether geometry-grounded features assist under motion or scene editing scenarios.
- Broader open-vocabulary tasks: Beyond localization and inversion, assess impacts on manipulation planning (grasp affordances, contact-rich actions), scene graph construction, and language-conditioned control to identify tasks where geometry-grounding offers clear benefits.
- Reproducibility and specification gaps: Some equations contain typos/missing terms (e.g., loss definition, SE(3) error computation, distribution parameters). Provide fully specified objectives, hyperparameters, training schedules, and ablation protocols to enable faithful replication and fair comparisons.
Practical Applications
Practical Applications Derived from the Paper’s Findings and Methods
Below are actionable use cases and opportunities that leverage the paper’s results, the SPINE framework, and the semantic distillation pipeline. Each item is categorized as an Immediate Application (deployable now) or a Long-Term Application (requiring further research or scaling), with sector links and feasibility notes.
Immediate Applications
- Robotics (manipulation and navigation)
- Use visual-only (DINOv2/DINOv3) distilled semantics in Gaussian Splatting/NeRF to enable open-vocabulary object localization (“find the mug,” “go to the toaster”) for home, warehouse, and lab robots.
- Workflow: train GS/NeRF with co-supervised CLIP + DINO features; compute continuous relevancy masks using canonical prompts; integrate with task planners and motion controllers.
- Sectors: robotics, logistics, consumer robotics.
- Assumptions/dependencies: static scenes or slow dynamics; camera poses for training; CLIP/DINO checkpoints; GPU for training; performance degrades under occlusions or poor coverage.
- Rapid camera pose bootstrapping without an initial guess (SPINE)
- Deploy SPINE to recover camera pose from a single query image for AR anchoring, robot relocalization, and photogrammetry when SLAM/VO fail.
- Workflow: compute semantic embedding of the query image → coarse pose via semantics-conditioned inverse model pψ → fine pose via rendering + correspondences + PnP with RANSAC.
- Sectors: AR/VR, robotics (drones/UGVs), mapping.
- Tools/products: Nerfstudio plugin, ROS node for SPINE, integration with existing SLAM stacks as a fallback.
- Assumptions/dependencies: trained radiance field and semantic field; known camera intrinsics; sufficient texture and scene coverage; fine inversion success depends on coarse error magnitude.
- Semantic search and content retrieval inside 3D scenes
- Natural-language search over radiance fields to find objects, parts, or regions (“fire extinguisher,” “electrical panel”).
- Sectors: AEC/BIM, facility operations, industrial inspection.
- Products: semantic retrieval panels in digital twin viewers; facility management dashboards.
- Assumptions/dependencies: high-quality CLIP embeddings; object categories present in pretraining; robust canonical prompts; prebuilt radiance fields.
- Assisted data annotation and labeling
- Use continuous relevancy masks to generate pseudo-labels and accelerate multi-view segmentation; human-in-the-loop refinement.
- Sectors: ML data ops, dataset curation.
- Assumptions/dependencies: consistent CLIP/DINO performance across views; view-dependent thresholding may be needed; quality control required.
- Backbone selection policy using the Geometric Fidelity Factor (GFF)
- Apply the GFF metric to choose between VGGT (edge-rich, contour fidelity) vs DINO (more versatile for object-level semantics and pose inversion).
- Sectors: ML engineering, academia.
- Assumptions/dependencies: GFF computed via Sobel thresholding; task-dependent; not a universal proxy for downstream performance.
- Scene editing and AR content placement
- Use open-vocabulary localization to place virtual content or perform object-centric edits (e.g., replace textures, annotate items) within GS/NeRF scenes.
- Sectors: media, gaming, visualization.
- Assumptions/dependencies: static or quasi-static scenes; semantic and visual fidelity of the radiance field.
- Robotics planning/localization fallback in safety-critical workflows
- Integrate SPINE as a fallback when odometry or GPS-denied localization fails (e.g., indoor drones).
- Sectors: robotics, emergency response.
- Assumptions/dependencies: access to trained scene radiance fields; current SPINE may not be real-time; needs camera intrinsics and sufficient scene coverage.
- Education and research training
- Use PCA visualization and GFF to teach students and practitioners how semantic features differ (object-level vs geometry-rich) and how to assess them.
- Sectors: education, academia.
- Assumptions/dependencies: GPU access; standard datasets (LERF, 3D-OVS).
- Immediate benchmarking and methodology adoption
- Adopt the paper’s evaluation pipeline (SSIM/LPIPS/PSNR for localization; so(3) error for pose; GFF for edge fidelity) and canonical prompt strategy to standardize open-vocab radiance field benchmarking.
- Sectors: research policy, academic consortia.
- Assumptions/dependencies: community coordination; shared datasets and code bases.
Long-Term Applications
- Self-supervised geometry-grounded pretraining that preserves versatility
- Develop spatial grounding strategies that avoid the observed trade-offs, retaining object-level semantics while embedding geometric detail (improving over VGGT-like fully supervised approaches).
- Sectors: ML research, foundation models.
- Products: new vision backbones with improved geometry-vision synergy; lightweight variants for deployment.
- Dependencies: large-scale multi-view datasets; substantial compute; curriculum and augmentation design.
- Dexterous manipulation and fine-grained robotic tasks
- Exploit geometry-rich features (edges, subparts) for precision grasps, micro-assembly, or surgical robotics without sacrificing semantic understanding.
- Sectors: manufacturing, healthcare robotics.
- Products: grasp planners and controllers that leverage enhanced contour-aware features.
- Dependencies: improved spatial grounding strategies; tactile/force feedback integration; real-time inference constraints.
- Real-time, onboard SPINE for mobile platforms
- Embedded inference stacks that run coarse-to-fine pose inversion on drones/UGVs/AR headsets with limited compute, enabling robust relocalization on the edge.
- Sectors: robotics, AR devices.
- Products: hardware-accelerated SPINE; lightweight semantic fields; optimized rasterization + correspondence pipelines.
- Dependencies: efficient model architectures; hardware acceleration (DSP/NPU); energy constraints.
- Scene-agnostic, zero-shot radiance field inversion
- Generalizable inverse models that work across scenes without per-scene training; quickly align a query image to an unknown environment.
- Sectors: AR/VR, mapping, robotics.
- Products: meta-learned inverse models; pretraining with large-scale diverse radiance fields.
- Dependencies: robust cross-domain generalization; handling intrinsics variability; data and privacy considerations.
- Dynamic radiance fields (4D) with open-vocabulary semantics
- Extend semantic distillation to dynamic scenes (traffic, crowds), enabling open-world understanding for autonomous driving and surveillance.
- Sectors: automotive, security, smart cities.
- Products: 4D NeRF/GS with semantic layers; streaming scene understanding.
- Dependencies: efficient dynamic modeling; temporal consistency; privacy and compliance frameworks.
- Urban-scale semantic radiance maps for navigation and wayfinding
- Large-area semantic radiance fields supporting language-conditioned navigation (“go to the nearest AED”), public safety, and maintenance operations.
- Sectors: smart cities, public sector.
- Products: city-scale semantic twins; operator dashboards; AR wayfinding.
- Dependencies: scalable capture pipelines; storage/bandwidth; regulatory governance and privacy.
- Standardized datasets and evaluation protocols for geometry-grounding and semantics synergy
- Community benchmarks that measure both object-level and geometric fidelity, including tasks like pose inversion, localization, and manipulation readiness.
- Sectors: research policy, standards bodies.
- Dependencies: multi-institution collaboration; sustained funding; open tooling.
- Radiance-field-as-a-service platforms
- Hosted pipelines for building, querying, editing, and inverting semantic radiance fields; integrations with CAD/BIM and asset management systems.
- Sectors: software/SaaS, AEC, digital twins.
- Products: APIs for semantic search, inversion, and editing; enterprise integrations.
- Dependencies: cloud GPU provisioning; data governance; cost optimization.
- Safety and compliance frameworks for semantics-driven robotics
- Certification processes that validate semantic localization and inversion reliability in safety-critical tasks (e.g., healthcare, industrial handling).
- Sectors: regulatory, healthcare, industrial robotics.
- Dependencies: rigorous validation protocols; traceability; adversarial robustness testing.
- Interoperable toolchains integrating SPINE with SLAM/VO
- Cross-vendor APIs that allow SLAM/VO stacks to call SPINE for recovery, semantic hints, or cross-checking pose estimates.
- Sectors: robotics software, middleware.
- Dependencies: API standardization; vendor cooperation; reference implementations.
Key Assumptions and Dependencies Across Applications
- Scene properties: Most pipelines assume static or slow-moving scenes and good coverage (sufficient views, texture, lighting).
- Training data: Radiance fields require multi-view images and camera poses; semantic fields need CLIP/DINO/VGGT backbones and per-scene training.
- Camera intrinsics: Required for accurate inversion and PnP refinement.
- Compute: GPU resources for training; real-time deployment needs lightweight models or hardware acceleration.
- Generalization: Domain shifts (lighting, materials, device sensors) can impact performance; canonical prompts and thresholds may require tuning.
- Robustness: Fine inversion success depends on coarse pose accuracy; occlusions and feature sparsity can degrade correspondences.
- Privacy/policy: Large-scale semantic radiance maps and dynamic scenes introduce privacy and governance considerations.
These applications translate the paper’s contributions—comparative insights on geometry-grounded vs visual-only semantics, the SPINE inversion framework, the co-supervision and evaluation methodology (PCA, GFF, canonical prompts)—into concrete pathways for industry deployment, academic benchmarking, policy-setting, and everyday tools.
Glossary
- Canonical prompts: Generic or negative text prompts used to disambiguate semantic matches when computing relevancy. "We use canonical prompts such as:
object,''stuff,'' and ``things.''" - CLIP: A vision-language foundation model whose embeddings enable open-vocabulary semantics in radiance fields. "We train a semantic field for CLIP features to enable downstream open-vocabulary tasks."
- Cosine similarity: A measure of embedding similarity based on the angle between vectors; used in loss functions and matching. "and represents the cosine-similarity function."
- DINOv2: A self-supervised vision backbone providing visual-only features used for semantics distillation. "DINOv2 achieves the lowest rotation and translation errors"
- DINOv3: A newer self-supervised vision backbone for visual-only features used alongside DINOv2. "we observe that the DINOv2 and DINOv3 features for the bear and the sheep are strongly distinct from the table and chairs"
- Exponential map: A mapping from a Lie algebra to its Lie group used to convert rotation vectors to rotation matrices. "using the exponential map, i.e., "
- Foundation models: Large pretrained models that learn general-purpose features from internet-scale data. "Large foundation models have driven rapid advances in open-vocabulary robot policies"
- Frobenius norm: A matrix norm used for numerical stability in optimization objectives. "Although the Frobenius-norm term is not strictly required in the loss function"
- Gaussian Mixture Model (GMM): A probabilistic model of a mixture of Gaussians; here used to represent a distribution over poses. "We jointly optimize the parameters of the GMM and the visual and semantic attributes of the radiance field"
- Gaussian primitives: Explicit Gaussian (ellipsoidal) elements used to represent non-empty space in Gaussian Splatting. "Gaussian Splatting (GS) utilizes $2$D \citep{huang20242d} or $3$D \citep{kerbl20233d} Gaussian primitives to represent non-empty space"
- Gaussian Splatting (GS): An explicit scene representation with Gaussian primitives enabling fast rasterization and real-time rendering. "GS employs a tile-based rasterization procedure to efficiently project the Gaussian primitives to the image plane"
- Geometric Fidelity Factor (GFF): A metric quantifying the proportion of image edges preserved by distilled semantic features. "we introduce the geometric fidelity factor (GFF), which captures the edge information present in the semantic features relative to the physical scene"
- Geometry-grounding: Training vision backbones with 3D reconstruction objectives to produce spatially-aware features. "does geometry-grounding improve semantic object localization?"
- Hashgrid encodings: Multi-resolution spatial encodings used in neural fields to learn detailed semantics. "the VGGT and CLIP semantic fields share the same hashgrid encodings (i.e., base semantics)"
- Learned Perceptual Image Patch Similarity (LPIPS): A learned perceptual metric for image similarity used to evaluate localization and inversion. "learned perceptual image patch similarity (LPIPS)"
- Lie algebra SO(3): The vector space of 3D skew-symmetric matrices used to parameterize rotations for optimization. "the corresponding Lie algebra , the vector space of three-dimensional skew-symmetric matrices."
- Multilayer perceptron (MLP): A feedforward neural network used to parameterize NeRF color and density fields. "NeRFs learn separate density and color fields parameterized by multi-layer perceptrons"
- Neural radiance fields (NeRFs): Implicit volumetric representations that model scene color and density for rendering. "NeRFs learn implicit volumetric color and density fields"
- Novel-view synthesis: Rendering photorealistic images from unseen viewpoints using radiance fields. "achieving photorealistic image rendering and novel-view synthesis entirely from RGB images"
- Open-vocabulary robot policies: Robot controllers conditioned on natural language that operate over unconstrained vocabularies. "open-vocabulary robot policies, enabling robots to perform complex, multi-stage tasks"
- Perspective-n-point (PnP): A pose estimation method solving for camera pose from 2D–3D correspondences. "solve the perspective--point (PnP) problem to refine the coarse pose estimates"
- Photometric-based optimization: Refinement procedure minimizing image-level errors to improve pose estimates. "fine inversion using photometric-based optimization."
- Principal component analysis (PCA): A dimensionality reduction method used to visualize high-dimensional semantic embeddings. "via principal component analysis (PCA), resulting in three-dimensional features"
- Radiance field inversion: Recovering camera pose (and related parameters) from images using a trained radiance field. "radiance field inversion remains a challenging problem"
- Radiance Fields: Scene models that render images by mapping 3D points and directions to color and density. "Radiance Fields marked a notable breakthrough in $3$D scene reconstruction"
- RANSAC: A robust estimation technique used to solve PnP while mitigating outlier correspondences. "using RANSAC, mitigating the effects of outliers on the estimated pose."
- Ray-marching: A volumetric rendering technique integrating color and density along rays to synthesize images. "Using ray-marching to render images from and "
- Semantic distillation: Transferring pretrained semantic features from foundation models into radiance fields. "Through semantic distillation, prior work blends photorealistic novel-view synthesis from radiance fields"
- Semantic field: A neural field mapping 3D points to semantic embeddings (vision or language). "We learn a semantic field ${f_{s}: #1{R}^{3} \mapsto #1{R}^{d_{s}$"
- Semantic relevancy score: A CLIP-based score distinguishing confident matches from non-confident ones for localization. "The semantic relevancy score can be viewed as the pairwise softmax over a set of positive and negative queries"
- Singular value decomposition (SVD): A matrix factorization used in computing PCA projections of semantic features. "we compute the singular value decomposition (SVD) of "
- Sobel–Feldman operator: An edge detector approximating image intensity gradients via 3×3 convolutions. "We apply the SobelâFeldman operator to the RGB image"
- Spherical harmonics: Basis functions encoding view-dependent color in Gaussian Splatting. "and spherical harmonics (for view-dependent color) parameters."
- Structural Similarity Index Measure (SSIM): A perceptual metric for comparing structural content in images. "structural similarity index measure (SSIM)"
- Structure-from-Motion (SfM): A technique to estimate camera poses from images used to initialize NeRF/GS training. "which is typically computed via structure-from-motion"
- Tile-based rasterization: A GPU-efficient method to project primitives to the image plane used by GS. "GS employs a tile-based rasterization procedure to efficiently project the Gaussian primitives to the image plane"
- Visual Geometric Grounded Transformer (VGGT): A geometry-grounded vision backbone producing visual-geometry features. "We utilize the state-of-the-art Visual Geometric Grounded Transformer (VGGT)"
- Visual-geometry semantic features: Semantic embeddings enriched with spatial detail via geometry-grounded training. "visual-geometry semantic features underperform visual-only features, despite their greater spatial content."
Collections
Sign up for free to add this paper to one or more collections.

