- The paper introduces the HAVIR model, a hierarchical framework that decouples structural and semantic processing to achieve superior fMRI-to-image reconstruction.
- It employs a Structural Generator and a Semantic Extractor whose outputs are fused via a pre-trained Versatile Diffusion model guided by CLIP, achieving top metrics like PixCorr and Inception Score.
- Ablation studies and cross-subject adaptability demonstrate HAVIR’s capability to maintain detailed spatial layouts and semantic accuracy, setting a new standard in brain decoding.
Hierarchical fMRI-to-Image Reconstruction via CLIP-Guided Versatile Diffusion: The HAVIR Model
Introduction
The HAVIR model introduces a hierarchical approach to reconstructing visual stimuli from fMRI data, leveraging the biological organization of the human visual cortex. By explicitly separating structural and semantic processing pathways, HAVIR addresses the limitations of prior methods in decoding complex scenes, where low-level features are heterogeneous and high-level features are semantically entangled. The framework integrates a Structural Generator and a Semantic Extractor, whose outputs are fused via a pre-trained Versatile Diffusion (VD) model guided by CLIP embeddings. This design enables HAVIR to achieve superior reconstruction fidelity, both in terms of spatial structure and semantic content, as demonstrated on the NSD dataset.
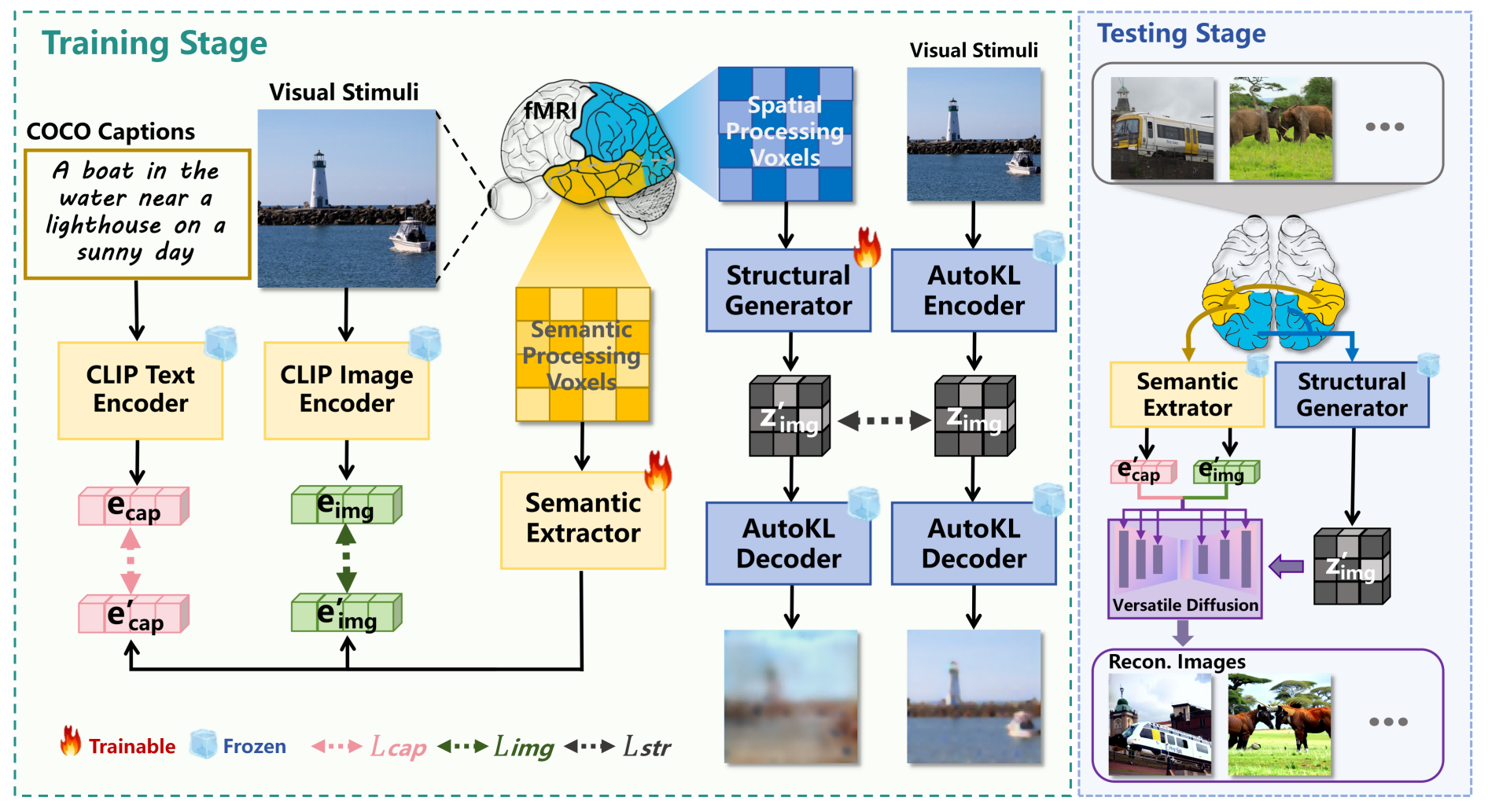
Figure 1: Overall framework of HAVIR. Different data are used for training and testing.
Model Architecture
Structural Generator
The Structural Generator maps spatial-processing voxels from early visual cortex regions to latent diffusion priors. The architecture consists of linear projections, LayerNorm, SiLU activation, Dropout, and residual MLP blocks, followed by upsampling and GroupNorm. The output is a latent vector zimg′ aligned with the AutoKL-encoded latent representation of the ground truth image. Training objectives combine MSE loss for global alignment and Sobel loss for edge-aware consistency, ensuring preservation of spatial topology and high-frequency details.
The Semantic Extractor processes semantic-processing voxels from anterior visual cortex regions, projecting them into CLIP image and text embedding spaces. The network employs linear mapping, normalization, activation, dropout, and residual MLP blocks, with separate heads for image and text modalities. Training utilizes a combination of SoftCLIP contrastive loss and MSE loss to align predicted embeddings with those from pretrained CLIP encoders, mitigating artifacts from batch-wise soft labels and ensuring robust semantic mapping.
Versatile Diffusion Integration
The VD model synthesizes the final image by integrating the structural prior and semantic constraints. Initialization starts from zimg′ with controlled noise addition, parameterized by a structural strength coefficient. Semantic conditioning is imposed via cross-attention mechanisms, guiding the UNet at each denoising step with both image and text CLIP embeddings. The iterative denoising process progressively refines the latent representation, balancing structural fidelity and semantic accuracy.
Experimental Results
Reconstruction Quality
HAVIR demonstrates robust reconstruction of complex scenes, accurately capturing both spatial layouts and semantic attributes across subjects. Qualitative results show preservation of ambient lighting, object positions, and key semantic features such as color and context.
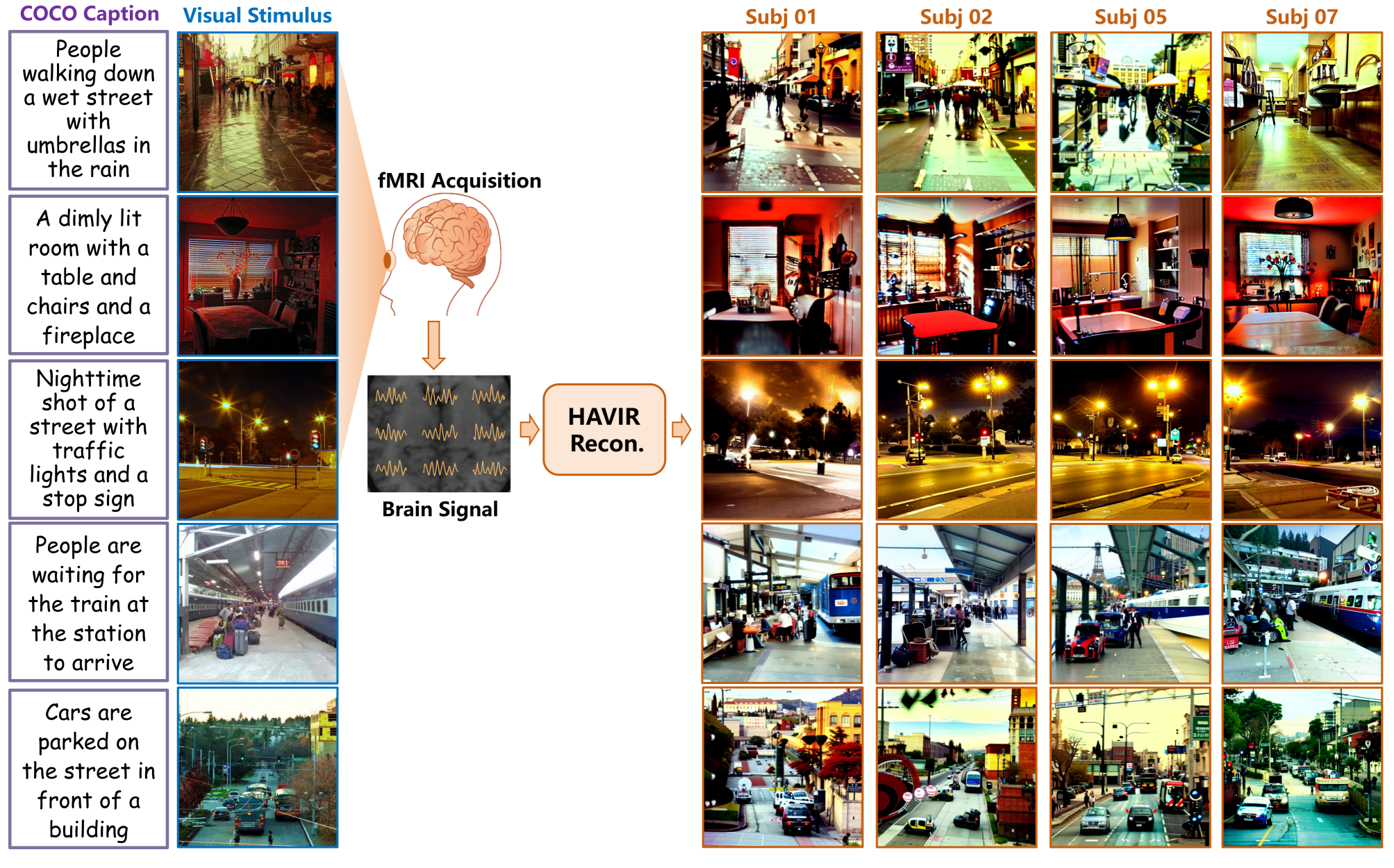
Figure 2: Examples of the reconstruction results from HAVIR.
Comparison with State-of-the-Art
HAVIR outperforms five recent SOTA methods (BrainGuard, NeuroPictor, Psychometry, MindBridge, MindEye) in both qualitative and quantitative evaluations. In challenging cases, HAVIR uniquely recovers fine-grained semantic details and spatial arrangements that other models fail to reconstruct.

Figure 3: Qualitative comparisons on the NSD test dataset. The results of HAVIR demonstrate superior reconstruction accuracy compared to the five recent SOTA methods.
Quantitative metrics show HAVIR achieves the highest PixCorr (0.327) and Inception Score (96.4%), and near-optimal AlexNet(5) feature similarity (98.1%). The model ranks third in SSIM (0.332), indicating strong structural preservation. High-level semantic metrics (CLIP, EffNet-B, SwAV) further confirm HAVIR's superior semantic fidelity.
Ablation Studies
Systematic ablation reveals the necessity of multimodal joint guidance. Removing CLIP guidance collapses semantic accuracy, while omitting structural priors degrades spatial fidelity. The full HAVIR model achieves balanced optimization across all metrics, validating the complementary roles of structural and semantic pathways.

Figure 4: Qualitative results of the full model and its ablated configurations
Interpretability and Cross-Subject Adaptability
Voxel-wise contribution mapping demonstrates that HAVIR dynamically adapts to individual neuroanatomical and functional variability. The model assigns distinct weights to different brain regions for each subject, enabling personalized decoding pathways and stable reconstruction performance.
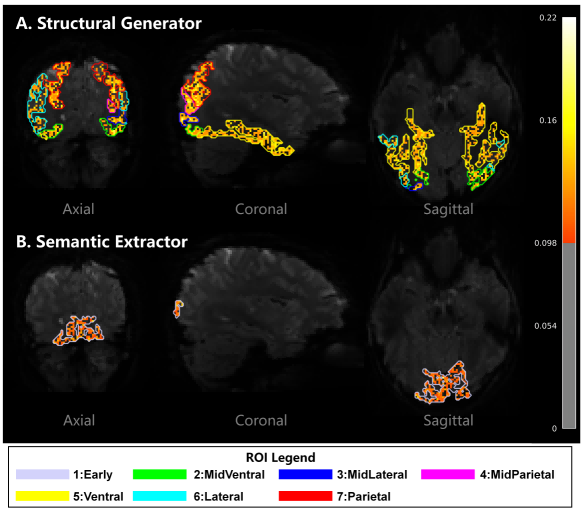
Figure 5: Spatial mapping of brain region contributions to Structural Generator (A) and Semantic Extractor (B) on Subj01.
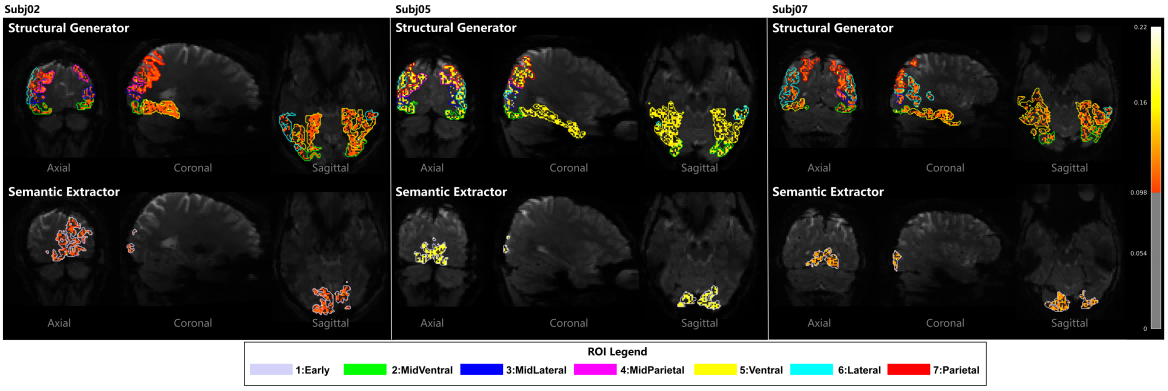
Figure 6: Voxel-wise contribution intensity maps for Subj02, Subj05 and Subj07, demonstrating cross-subject adaptability.
Implementation Details
HAVIR is trained from scratch for 200 epochs on Subj01 (40 hours fMRI, NVIDIA A800 80GB, batch size 30), then fine-tuned via transfer learning on Subj02, 05, and 07 (1 hour each, 3×RTX 4090 24GB, batch size 50). Individualized ROI masks are used for voxel selection, enhancing anatomical specificity and functional mapping precision.
Implications and Future Directions
HAVIR's hierarchical design, multimodal fusion, and individualized brain mapping set a new standard for fMRI-based visual reconstruction. The model's ability to disentangle and jointly optimize structural and semantic features opens avenues for more interpretable and generalizable brain decoding systems. Future work may extend HAVIR to other sensory modalities, integrate temporal dynamics, or explore zero-shot generalization across unseen subjects and stimuli. The approach also has potential applications in brain-computer interfaces, cognitive neuroscience, and clinical diagnostics.
Conclusion
HAVIR introduces a biologically inspired, hierarchical framework for fMRI-to-image reconstruction, achieving state-of-the-art performance in both structural and semantic fidelity. By decomposing brain signals into distinct processing streams and leveraging multimodal diffusion guidance, HAVIR overcomes the limitations of prior models in complex scene reconstruction. The model's adaptability to individual brain architectures and its robust quantitative and qualitative results underscore its significance for computational neuroscience and AI-driven brain decoding.