- The paper presents S-MADRL, which uses virtual pheromones for stigmergic communication to achieve decentralized coordination in high-density scenarios.
- It integrates curriculum learning to decompose complex tasks into simpler stages, enhancing training stability and scalability up to eight agents.
- Experimental results on a pellet excavation task show superior convergence and higher rewards compared to traditional MADRL methods.
Deep Reinforcement Learning for Multi-Agent Coordination
The paper "Deep Reinforcement Learning for Multi-Agent Coordination" (2510.03592) addresses the significant challenge of coordinating multiple robots within confined environments where congestion and interference are prevalent problems. This research introduces a Stigmergic Multi-Agent Deep Reinforcement Learning (S-MADRL) framework leveraging virtual pheromones and curriculum learning to enhance scalability and mitigate convergence issues prevalent in traditional multi-agent deep reinforcement learning (MADRL) systems.
Stigmergic Communication
The S-MADRL framework fundamentally relies on the concept of stigmergy, a mechanism inspired by social insects like ants that utilize environmental traces for communication. By adopting a virtual pheromone system, the proposed framework enables decentralized coordination without explicit message passing. Agents deposit virtual pheromones as they move, which decay over time, thereby encoding recent activity and occupancy data.
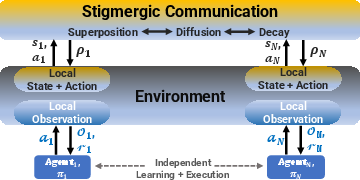
Figure 1: Proposed scalable decentralized MADRL framework with stigmergic communication. Each agent receives local observations and acts independently, allowing for scalability in large teams.
This indirect communication mechanism accomplishes a dual purpose: it mitigates the non-stationarity problem inherent in multi-agent environments and serves as a decentralized coordination tool, thereby reducing the complexity associated with explicit inter-agent communication. The framework's pheromone-based approach allows for the encoding of environmental memory, thereby facilitating efficient group performance even in high-density scenarios.
Curriculum Learning Integration
To further enhance the learning process, the research integrates curriculum learning, which systematically decomposes complex tasks into simpler sub-tasks. This approach significantly improves training stability and scalability, allowing the system to scale up to eight agents successfully. The curriculum learning strategy initiates training with simpler configurations, progressively introducing more complexity, thus optimizing both convergence speed and asymptotic performance.
Experimental Results
The framework's effectiveness was validated through extensive simulations on a pellet excavation task modeled on the OpenAI Gym platform. The study compared several MADRL strategies—including Independent Q-Learning (IQL), IQL with Global Reward, and IQL with Global Reward and Stigmergy—highlighting the superior performance of the proposed S-MADRL approach.
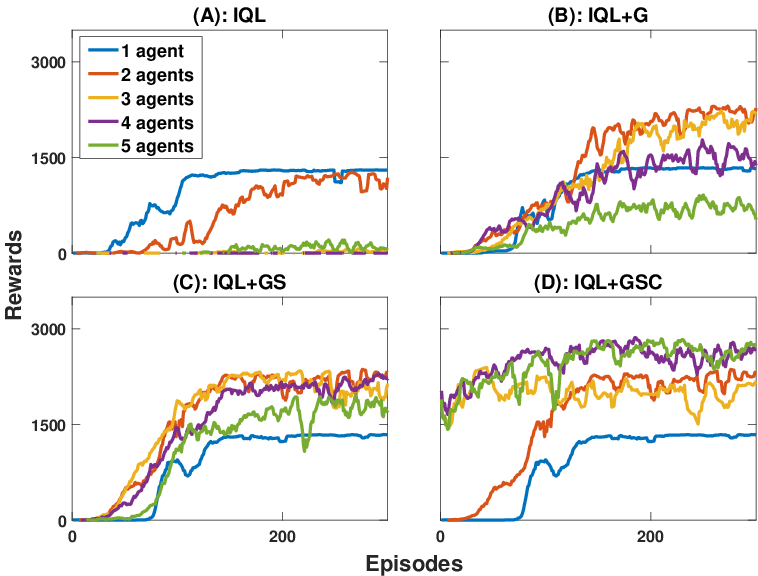
Figure 2: Learning curve comparison showing enhanced convergence and higher rewards achieved by the S-MADRL framework in environments crowded with five agents.
As Figure 2 illustrates, baseline techniques struggle to maintain convergence beyond three agents due to state-action space complexity. In contrast, the S-MADRL framework not only enhances convergence but also achieves high reward levels even in scenarios involving up to eight agents, thereby corroborating its scalability and robustness.
Discussion
The research addresses critical challenges in multi-agent coordination by leveraging bio-inspired stigmergy and curriculum learning. By providing a scalable decentralized approach, the S-MADRL framework circumvents the dimensionality issues and communication overhead common in MADRL algorithms. Moreover, the simulation studies reveal the emergence of biologically inspired strategies such as asymmetric workload distributions, reminiscent of natural systems where selective agent idleness and unequal participation mitigate congestion and enhance efficiency.
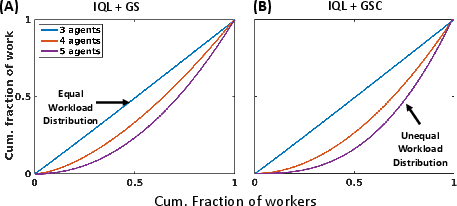
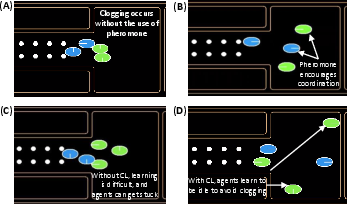
Figure 3: Lorenz curve illustrating unequal workload distribution as an emergent strategy from stigmergy and curriculum learning, enhancing excavation efficiency.
Conclusion
This work significantly advances the capabilities of multi-agent systems by presenting a scalable and decentralized approach that combines stigmergic communication and curriculum learning. The S-MADRL framework achieves robust coordination even in crowded environments, demonstrating superior scalability compared to traditional techniques. Future research directions could explore the extension of the S-MADRL framework to heterogeneous agents and refine curriculum learning strategies to accommodate even larger teams or more dynamic environmental conditions, further expanding the practical applicability of this approach in real-world robotic swarm and collective behavior domains.