- The paper systematically reviews 224 studies to identify and categorize harm instances of generative AI in computing education.
- It employs PRISMA guidelines to map harms, such as cognitive, metacognitive, academic integrity, equity, social, and logistical concerns, to various educational contexts.
- The findings highlight that while benefits are well-documented, empirical support for harms remains modest, necessitating methodological advancements and policy adaptations.
Systematic Review of Harms and Consequences of Generative AI in Computing Education
Introduction
The rapid integration of generative AI (GenAI), particularly LLMs, into computing education has prompted a surge of research on both its pedagogical benefits and its potential risks. While prior work has cataloged the positive impacts of GenAI—such as improved code explanations, personalized feedback, and enhanced engagement—this systematic review addresses a critical gap: the breadth, prevalence, and empirical support for harms and unintended consequences of GenAI in higher education computing contexts. The review synthesizes findings from 224 peer-reviewed studies published between 2022 and July 2025, providing a taxonomy of harms, an analysis of evidence levels, and a mapping of harms to educational contexts, tool types, and populations.
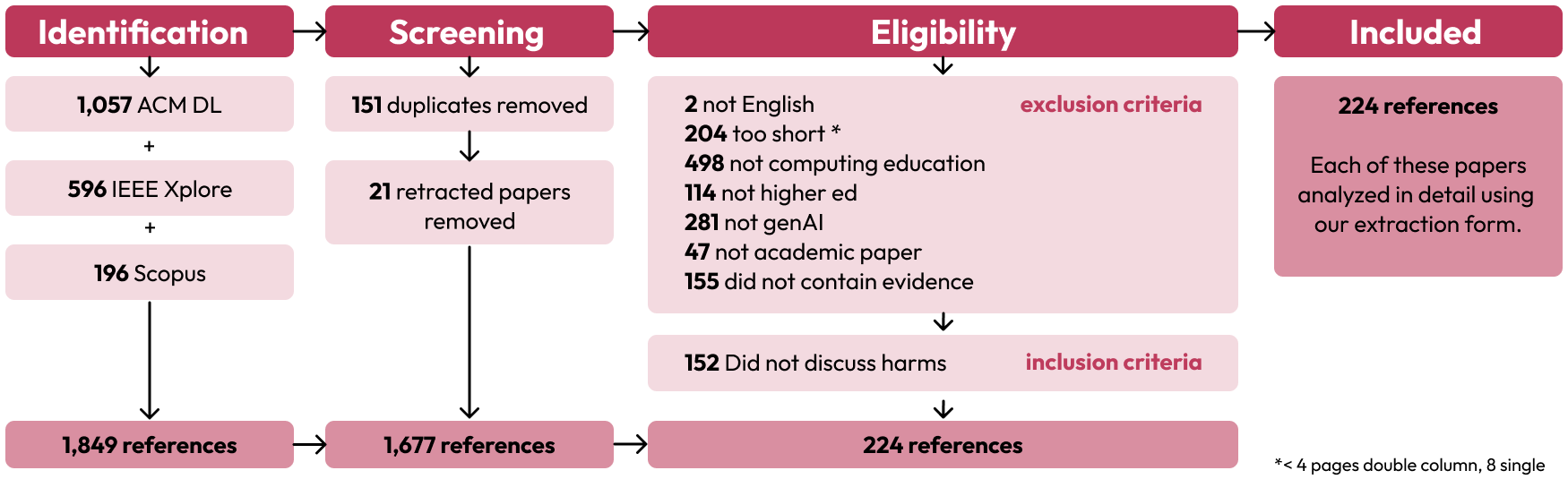
Figure 1: PRISMA diagram detailing the identification, screening, and assessment of paper eligibility for inclusion.
Methodology
The review follows PRISMA guidelines, employing a multi-stage process: identification of relevant literature from ACM DL, IEEE Xplore, and Scopus; screening based on language, focus, and educational level; and eligibility assessment via independent coding by four reviewers. The final corpus was coded for research method, GenAI tool type, learner population, educational task, and, critically, for concrete harm categories (e.g., academic integrity, cognitive/metacognitive effects, equity, social harms, logistical challenges). The review emphasizes empirical rigor by classifying the level of evidence for each harm instance.
Trends in GenAI Harms Research
The number of papers discussing GenAI harms in computing education has increased substantially since 2022, with a disproportionate rise relative to the overall growth in GenAI-related publications.
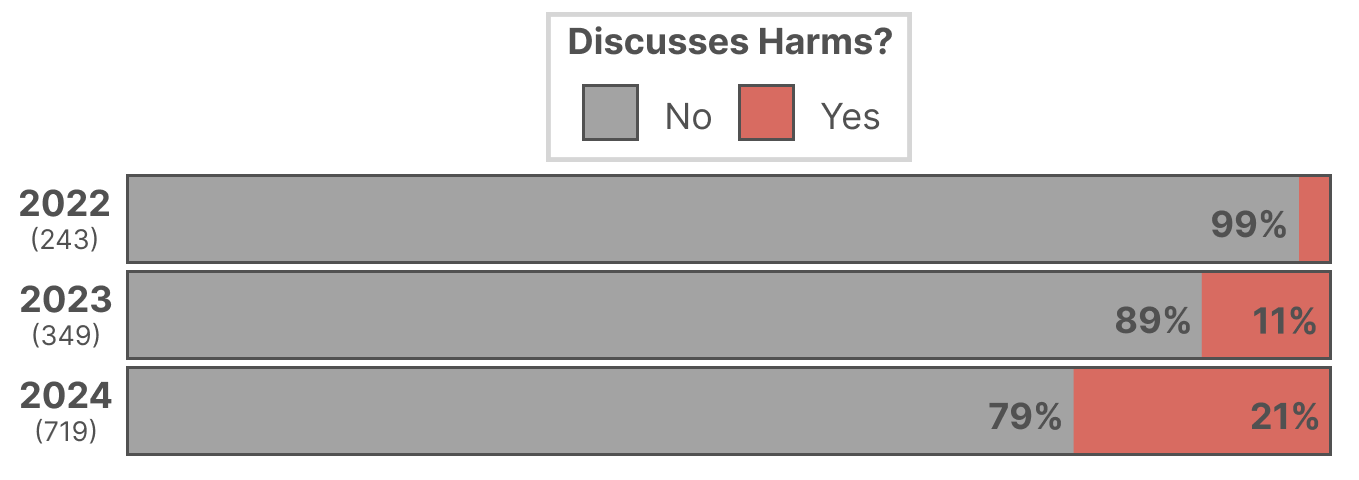
Figure 2: Percentage of papers discussing harms of GenAI in computing education by year.
Despite this growth, the majority of harm claims remain speculative or based on informal observations, with only a modest increase in rigorous empirical evidence over time.
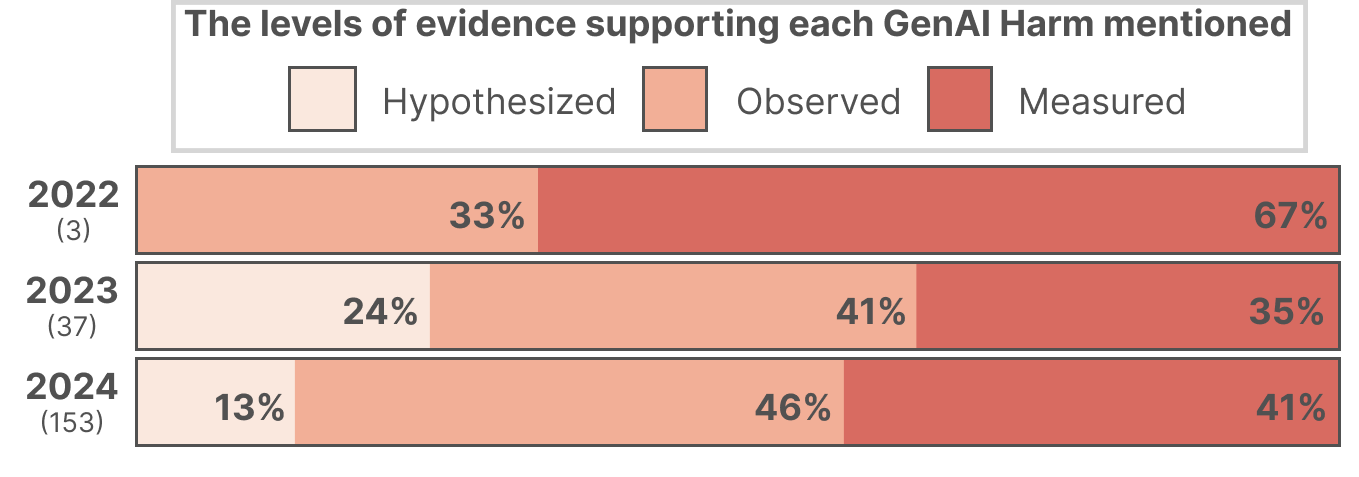
Figure 3: Proportion of papers by highest level of evidence for harms, omitting 2025 data.
Taxonomy and Prevalence of Harms
The review identifies six umbrella categories of harm: cognitive, metacognitive, assessment/academic integrity, equity, social, and instructional/logistical. Each category encompasses multiple sub-harms, with cognitive and metacognitive harms being the most frequently reported and empirically supported.
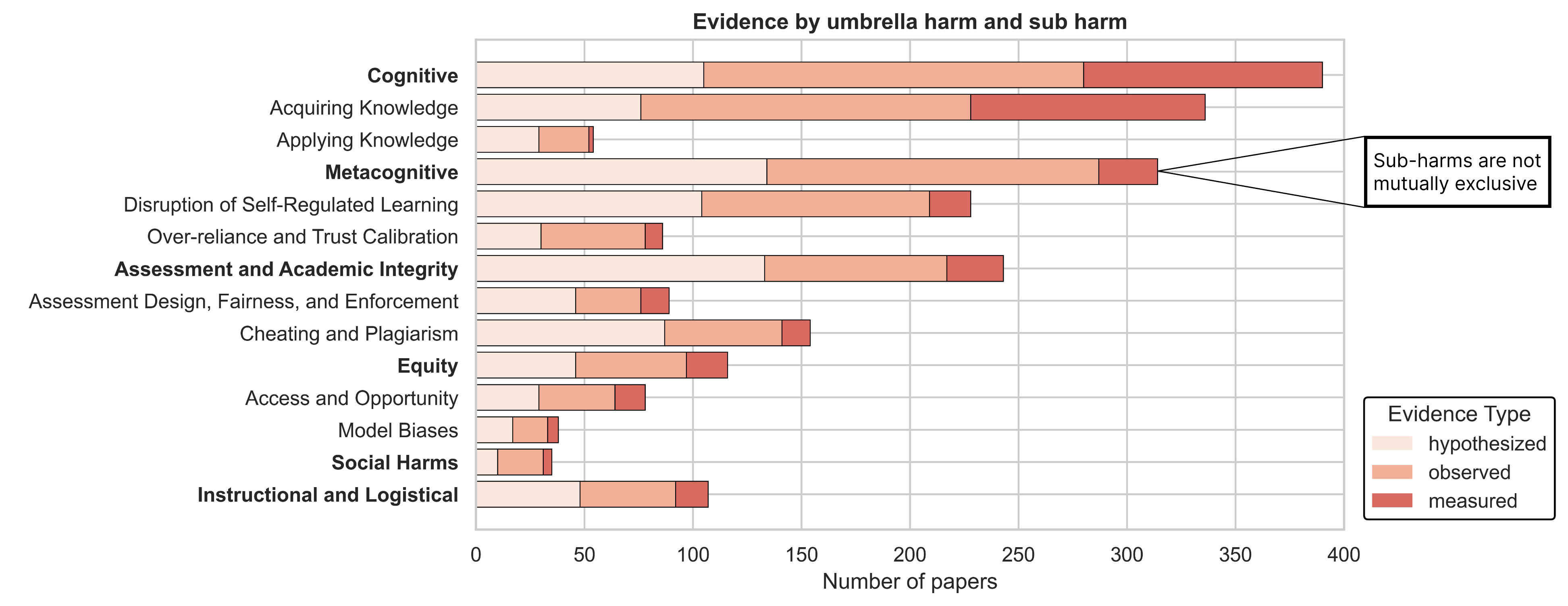
Figure 4: Umbrella harms (e.g., Metacognitive) and their empirical support across sub-harms.
Cognitive harms (32.4% of papers) primarily concern the acquisition and application of knowledge. Empirical studies document that GenAI can produce hallucinated or shallow outputs, leading to incorrect learning and reduced independent problem-solving. For example, in a data structures course, TA-moderated GenAI use improved average scores, but unchecked use led to propagation of errors in complex tasks. Over-reliance on GenAI is prevalent: in some studies, a third of students submitted assignments with minimal independent work, and students with lower proficiency were more likely to use GenAI for generation and debugging, but did not outperform manual coders.
Metacognitive harms (second most frequent) include disruptions to planning, monitoring, and adaptation during problem-solving. Log analyses and eye-tracking studies reveal a shift toward "prompt-and-accept" workflows, with students increasingly seeking direct solutions as deadlines approach and disabling guardrails to access full answers. Lower-performing students exhibit more metacognitive difficulties, are more likely to accept AI suggestions uncritically, and experience an "illusion of competence"—a misalignment between perceived and actual understanding.
Assessment and Academic Integrity
Harms related to academic integrity are the third most common. While GenAI can now solve the majority of programming assignments and exams at the CS1/CS2 level, most papers on cheating and plagiarism lack measured evidence. Detection approaches (e.g., style anomaly detection, code anomaly detectors) show promise but raise fairness concerns, especially in collaborative contexts. Preventative strategies include prompt problems and assignment design modifications, but there is no consensus on effective enforcement. Notably, some instructors have shifted to pragmatic acceptance of GenAI use, acknowledging the futility of outright bans.
Equity and Access
Equity-related harms (29% of papers) focus on model biases (e.g., language, gender, race) and unequal access to GenAI tools. Empirical work demonstrates that GenAI performs better in English and high-resource languages, and that subscription costs and hardware requirements create barriers for students and institutions. There is also evidence that students with prior GenAI experience or higher proficiency benefit more, potentially exacerbating existing divides.
Social Harms
Social harms are underrepresented (8.5% of papers), but recent qualitative studies highlight the erosion of peer learning and help-seeking communities. Students increasingly redirect questions to GenAI rather than peers or instructors, leading to isolation and reduced collaboration. Compatibility issues between LLM-generated code from different team members can hinder teamwork.
Instructional and Logistical Harms
Logistical challenges include privacy concerns (e.g., data protection under FERPA/GDPR), the need for new competencies (e.g., prompt engineering), and the requirement for explicit scaffolding to prevent misuse. Instructors report that GenAI can undermine student motivation and necessitate substantial changes to assessment and feedback practices.
Contextual Analysis: Populations, Tools, and Methods
Introductory undergraduates are the most studied population, with cognitive and metacognitive harms most prevalent in this group.
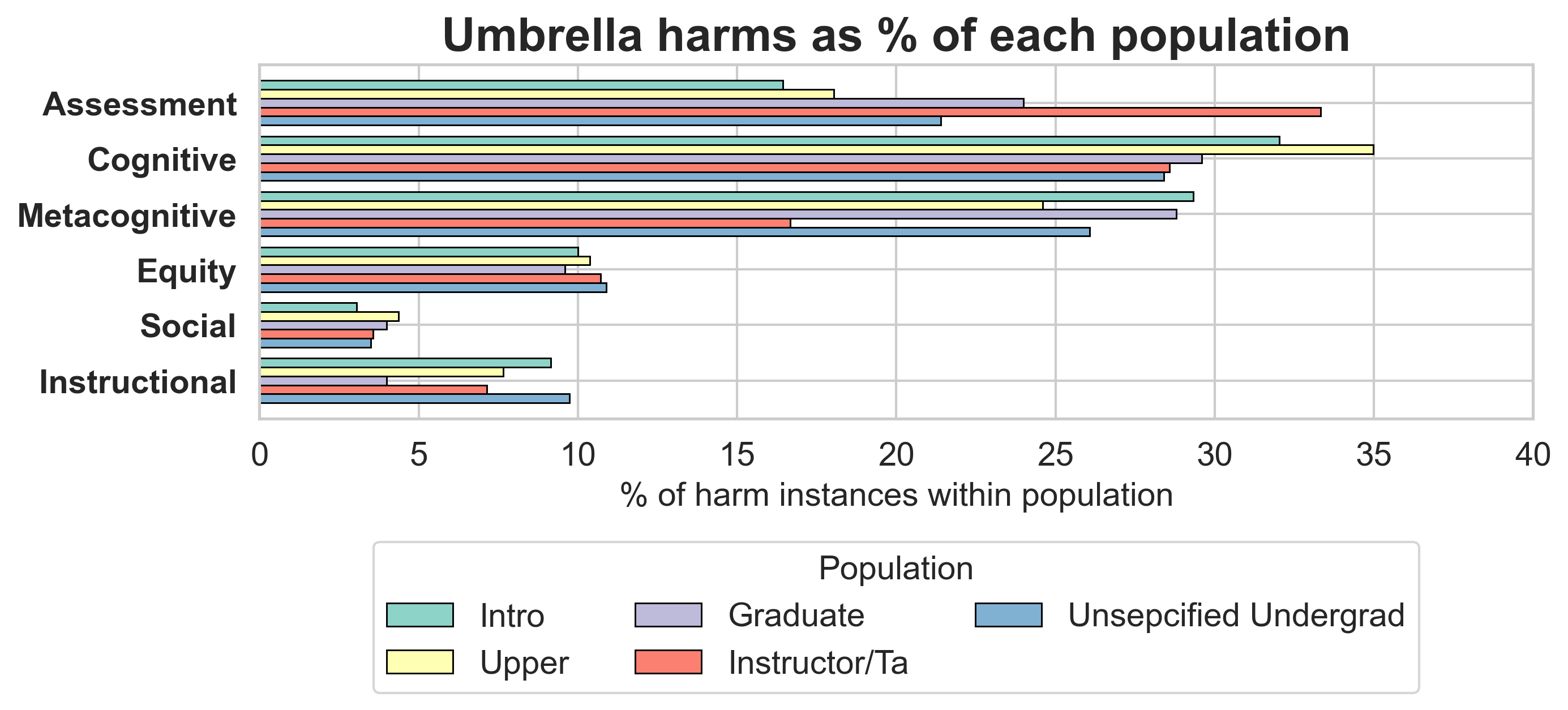
Figure 5: Harms as a percentage of each population; introductory students dominate harm instances.
Chat models (e.g., ChatGPT, Claude, Gemini) are the most frequently implicated tool type across all harm categories, followed by code assistants (e.g., Copilot). Custom tools and image models are less frequently discussed but are associated with specific harm types.
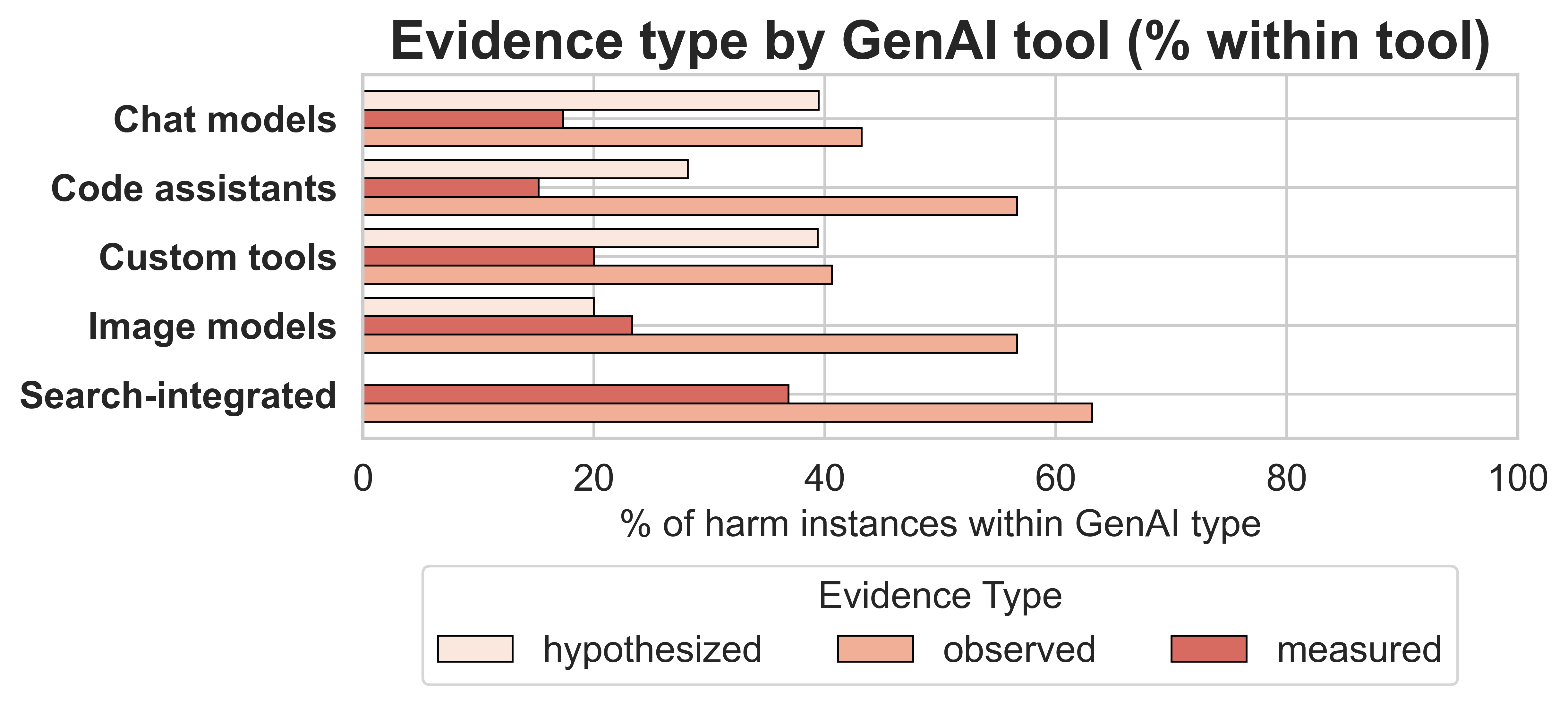
Figure 6: Percentage of harm instances by evidence type within each type of GenAI tool.
Methodologically, cognitive harms are most often surfaced in experiments and content analyses, while assessment harms are highlighted in benchmarking studies.
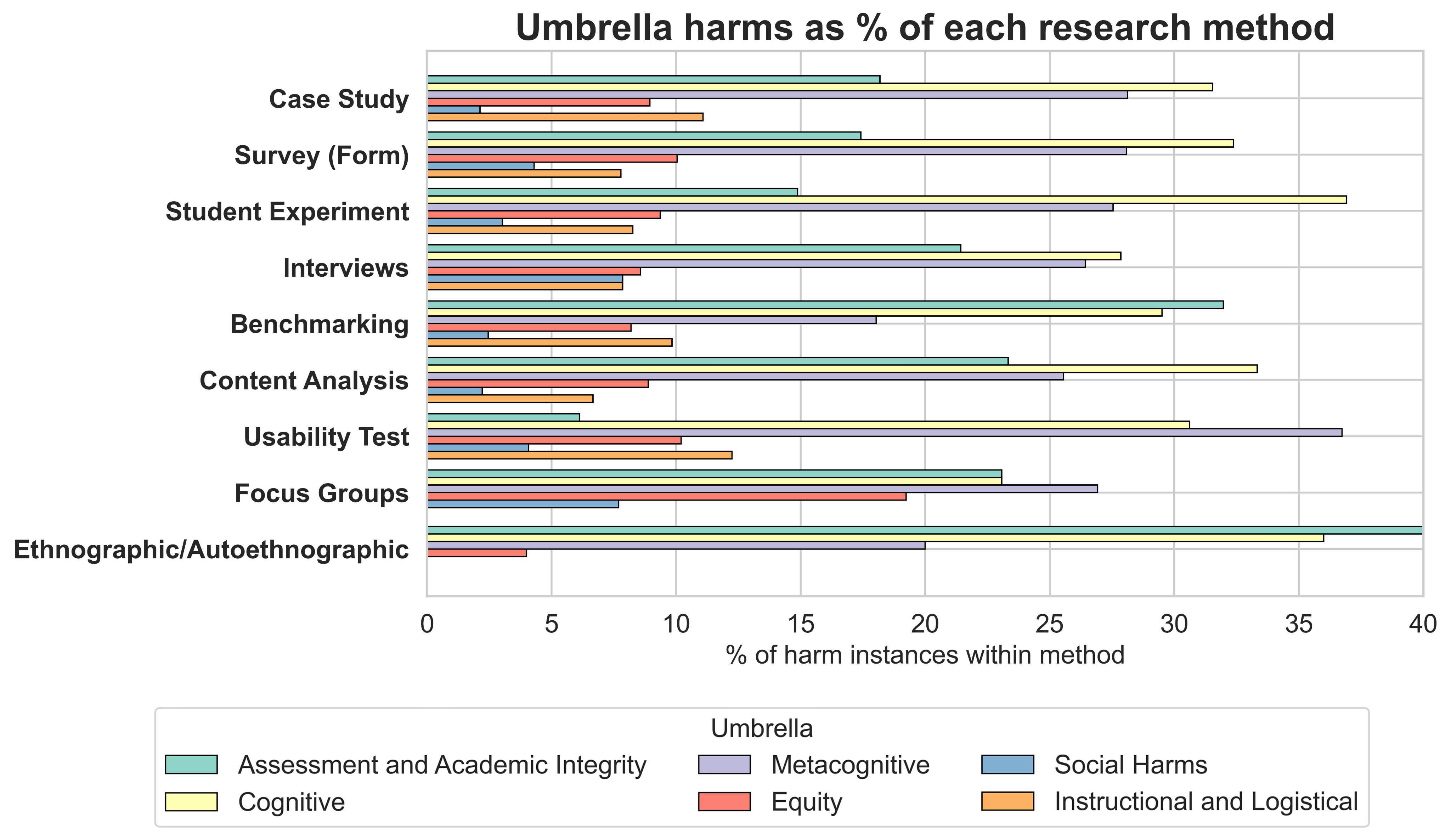
Figure 7: Umbrella harms across research methods.
Implications and Grand Challenges
The review surfaces several critical challenges for the field:
- Assessment Validity: As GenAI can solve most standard programming tasks, assessment must shift from product to process, but GenAI is increasingly capable of supporting process-level tasks as well.
- Cognitive and Metacognitive Development: Model improvements may reduce hallucinations, but foundational problem-solving and metacognitive skills risk atrophy if students over-rely on GenAI.
- Mitigating Over-reliance: The "illusion of competence" is a persistent risk; interventions such as autocompletion quizzes and guardrails show promise but require further study.
- Preserving Learning Communities: Social harms are underexplored; maintaining peer interaction and sense of belonging is essential for retention and learning outcomes.
- Logistical Adaptation: Instructors must address privacy, equity, and the need for new literacies, while adapting to changing student motivation and preparedness.
Limitations
The review is limited by the scope of published literature and may underrepresent harms that are less studied or more difficult to measure. The prevalence of certain harms may reflect research focus rather than real-world frequency or severity. The review does not quantify the magnitude of harms, which would require meta-analytic synthesis.
Conclusion
This systematic review provides a comprehensive taxonomy and contextual analysis of harms associated with GenAI in computing education. While the field is increasingly attentive to risks, empirical support remains limited for many harm categories, and certain populations and harms (notably social and equity-related) are underexplored. The findings underscore the necessity of balancing GenAI's benefits with proactive mitigation of its risks, and highlight the need for rigorous, context-sensitive research to inform policy and practice as GenAI becomes ubiquitous in computing education.