- The paper introduces an information-theoretic framework for membership inference that refines sequence-level analysis by evaluating token-level leakage.
- It employs a Bayes factor-like statistic to compute information gain per token, demonstrating superior performance with high TPR@FPR and robust AUC across benchmarks.
- Token-level InfoRMIA facilitates targeted privacy audits and unlearning interventions, offering actionable insights to mitigate memorization risks in LLMs.
Introduction and Motivation
This work addresses two critical limitations in membership inference attacks (MIAs) for LLMs: the reliance on sequence-level statistics and the dependence of state-of-the-art attacks (e.g., RMIA) on large population datasets. The authors introduce InfoRMIA, a theoretically principled information-theoretic variant of RMIA, and extend it to token-level analysis, enabling more granular assessment of privacy risks and memorization behavior in LLMs. This approach offers statistically stronger inference power, improved efficiency, and actionable insights for privacy-preserving interventions.
The Robust Membership Inference Attack (RMIA) computes the proportion of population data a target query dominates, which yields a discrete score whose expressivity is bottlenecked by the number of reference points and introduces dependence on the population set size. InfoRMIA reframes the membership inference game as a composite hypothesis testing problem and employs a Bayes factor-like statistic that evaluates the information gain in bits—logp(x)p(x∣θ)—and accounts for distributional shift via DKL(p(z)∥p(z∣θ)). This continuous statistic enhances granularity, is less sensitive to the choice of the population set Z, and eliminates the need for threshold tuning.
The empirical evaluation in the paper demonstrates clear superiority: InfoRMIA consistently outperforms RMIA in AUC and TPR@FPR across diverse domains (tabular, vision, text) and maintains its efficacy even with drastically smaller population sets. This establishes InfoRMIA as a more scalable and cost-effective reference-based MIA.
Token-Level Membership Inference for LLMs
A critical insight of the paper is that sequence-level membership assessments in LLMs obscure the model's actual leakage patterns, as only a small subset of tokens in a sequence may represent sensitive content. The mapping from sequences to a single membership score acts as a severe (and lossy) compression, conflating common tokens with private ones and failing to illuminate the location or type of memorization.
The correlation between average sequence-level and private-token-level membership scores is weak, indicating deficiencies in sequence-level analysis.
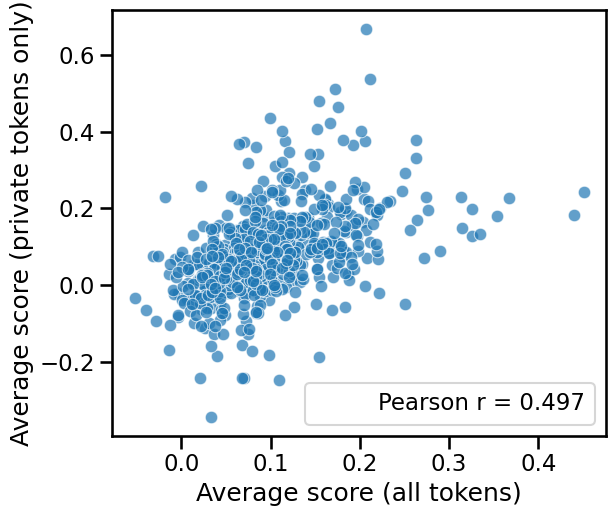

Figure 1: The average membership scores of sequences and their private tokens are not strongly correlated.
The token-level InfoRMIA framework evaluates membership per token prediction step—aligned with the LLM training objective—and provides position-aware scores. It leverages the fact that each next-token prediction is a learning instance, and enables token-based assessment of privacy risk, which is directly actionable for tasks such as targeted unlearning and forensic audits of memorized PII.
The distributional characteristics of token-level InfoRMIA scores on AG News demonstrate that sensitive entities (such as PERSON and WORK_OF_ART tokens) are more prone to memorization.
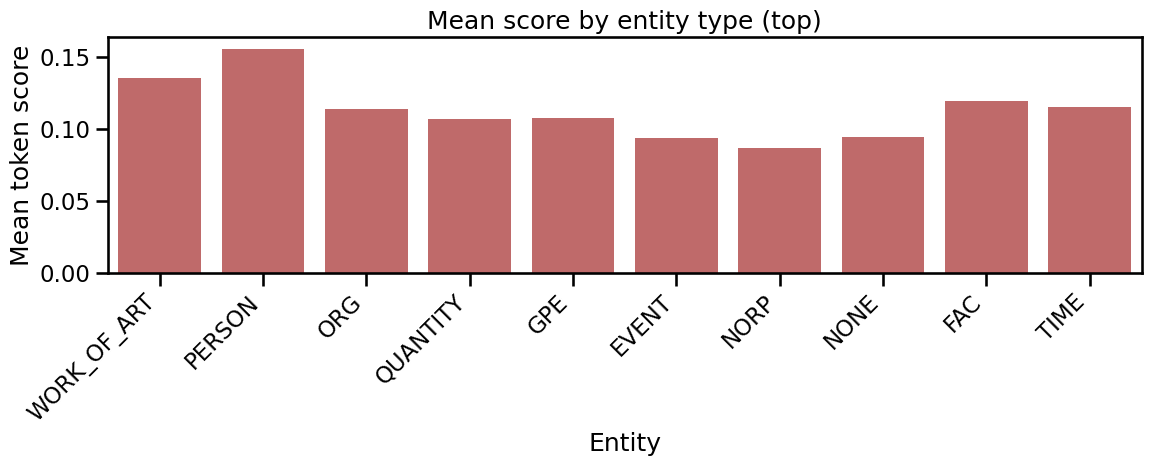
Figure 2: Histogram of average token scores across top entity groups on AG News; PERSON and WORK_OF_ART have notably higher memorization rates.
The agglomerated statistics confirm that memorization is concentrated in a minority of private entity tokens, and non-private/common tokens generally dilute leakage assessments when averaging over an entire sequence.
On the ai4privacy benchmark, the analysis reveals two phenomena: (1) non-private tokens can exhibit comparable or higher variance in "memorization" than true private ones, and (2) the top sequences by sequence-level score often do not contain high-scoring private tokens.
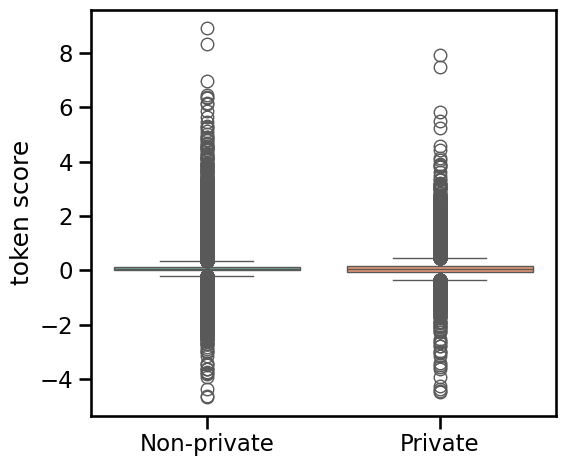
Figure 3: Non-private tokens show a slightly higher mean and larger variance in membership scores compared to private tokens.

Figure 4: Top-10 memorized sequences by sequence-based scores in ai4privacy; some lack private tokens altogether, others have low average private token scores.
In contrast, sequences with the highest average private token memorization do not rank highly by sequence-based metrics—attesting to the strong dilution of privacy signals in sequence-level evaluation.

Figure 5: Top-10 sequences with highest average private token scores have low overall sequence-level scores, illustrating dilution of memorization signals.
Token-level InfoRMIA, when aggregated (e.g., via averaging), achieves competitive or superior sequence-level MIA performance relative to both sequence-based InfoRMIA and reference-model approaches, according to all major benchmarks (AG News, ai4privacy, MIMIR). Critically, InfoRMIA delivers high TPR at very low FPR, which is the operational regime of greatest concern for privacy audits.
Moreover, token-level analysis exposes the limitations of AUC-based privacy quantification in LLMs: high aggregate AUCs may not reflect true leakage of private information, as memorization is not uniformly distributed and sequence-level scoring misidentifies privacy risk. The authors' HTML visualization interface and heatmapping tool offer actionable inspection for auditors—making it possible to localize leakage, assess the memorization of specific entities (especially PII), and devise more precise and surgical unlearning procedures.
The distribution of token-level InfoRMIA scores further supports focused audit strategies.
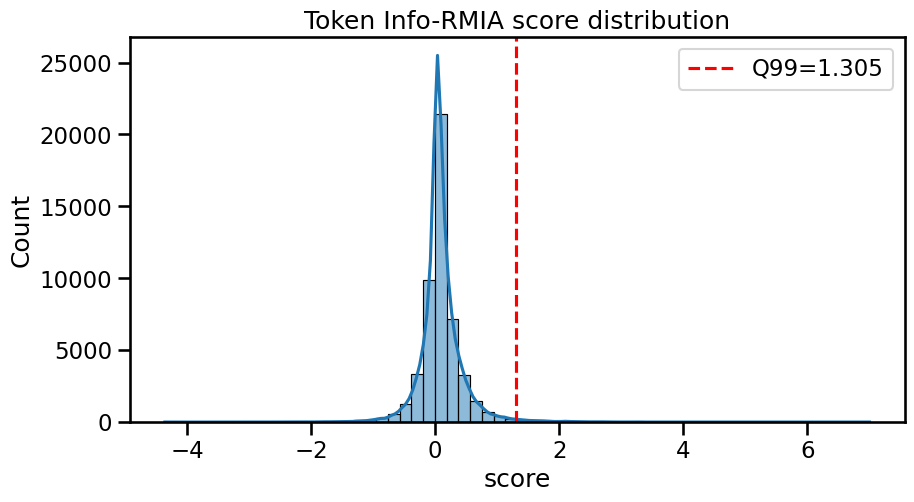
Figure 6: Distribution of token InfoRMIA scores on AG News shows near-normal distribution but strong right-tail for certain entities.
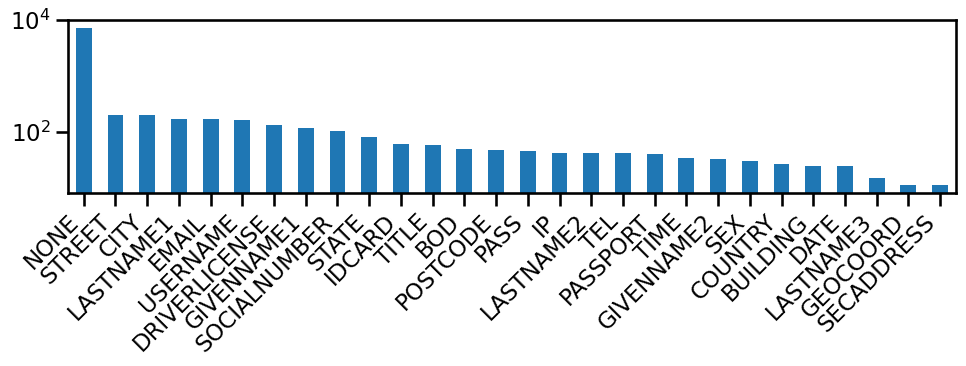
Figure 7: Distribution of high scoring tokens by type in ai4privacy (log-scale), emphasizing the statistical sparsity of memorized sensitive tokens.
Implications and Future Directions
This work redefines the granularity at which privacy risk should be assessed and mitigated in LLMs. The information-theoretic framework of InfoRMIA provides a statistically sound and computationally efficient attack paradigm, suitable for both academic evaluation and real-world audits. The token-level perspective greatly enhances interpretability and the scientific understanding of memorization phenomena in deep autoregressive transformers.
Practically, the approach enables targeted interventions—e.g., selective unlearning or content filtering—potentially retaining non-sensitive knowledge while guaranteeing erasure of specific memorized elements. Theoretical implications are substantial: privacy risk assessments should shift toward token-level or span-level statistics, especially for domains (legal, medical, financial) where sensitive entities are local and limited.
Future work can extend in several technical directions:
- Further optimization of aggregation strategies for membership signals to match downstream privacy definitions,
- Extension to subword or span analysis for contextual memorization,
- Integration with automated detection of infrequent/entity tokens,
- Exploration of adversarial or certified unlearning guided by token-level memorization maps.
Conclusion
(Token-Level) InfoRMIA advances the state of the art in membership inference attacks for LLMs, both in terms of statistical rigor and practical interpretability (2510.05582). By grounding its methodology in information theory and shifting analytical granularity to the token level, it achieves stronger, more efficient, and operationally relevant privacy leakage assessment. The token-level perspective reveals the limitations of previous sequence-level approaches and equips both researchers and practitioners with direct tools for precise privacy auditing and mitigation in the LLM era.