Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability
Abstract: LLM post-training has enhanced instruction-following and performance on many downstream tasks, but also comes with an often-overlooked cost on tasks with many possible valid answers. We characterize three desiderata for conditional distributional modeling: in-context steerability, valid output space coverage, and distributional alignment, and document across three model families how current post-training can reduce these properties. In particular, we disambiguate between two kinds of in-context learning: ICL for eliciting existing underlying knowledge or capabilities, and in-context steerability, where a model must use in-context information to override its priors and steer to a novel data generating distribution. To better evaluate and improve these desiderata, we introduce Spectrum Suite, a large-scale resource compiled from >40 data sources and spanning >90 tasks requiring models to steer to and match diverse distributions ranging from varied human preferences to numerical distributions and more. We find that while current post-training techniques help elicit underlying capabilities and knowledge, they hurt models' ability to flexibly steer in-context. To mitigate these issues, we propose Spectrum Tuning, a post-training method using Spectrum Suite to improve steerability and distributional coverage. We find that Spectrum Tuning often improves over pretrained models and their instruction-tuned counterparts, enhancing steerability, spanning more of the output space, and improving distributional alignment on held-out datasets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a problem with today’s chatty AI models: they’re great at following instructions and giving one “good” answer, but they often struggle when there are many different correct answers or when you need them to change their behavior based on new examples you give them. The authors introduce a new way to train models, called Spectrum Tuning, to help AIs better cover the full range of valid answers and to steer their behavior based on context you provide.
What questions did the researchers ask?
The researchers focused on three simple, people-friendly abilities an AI should have:
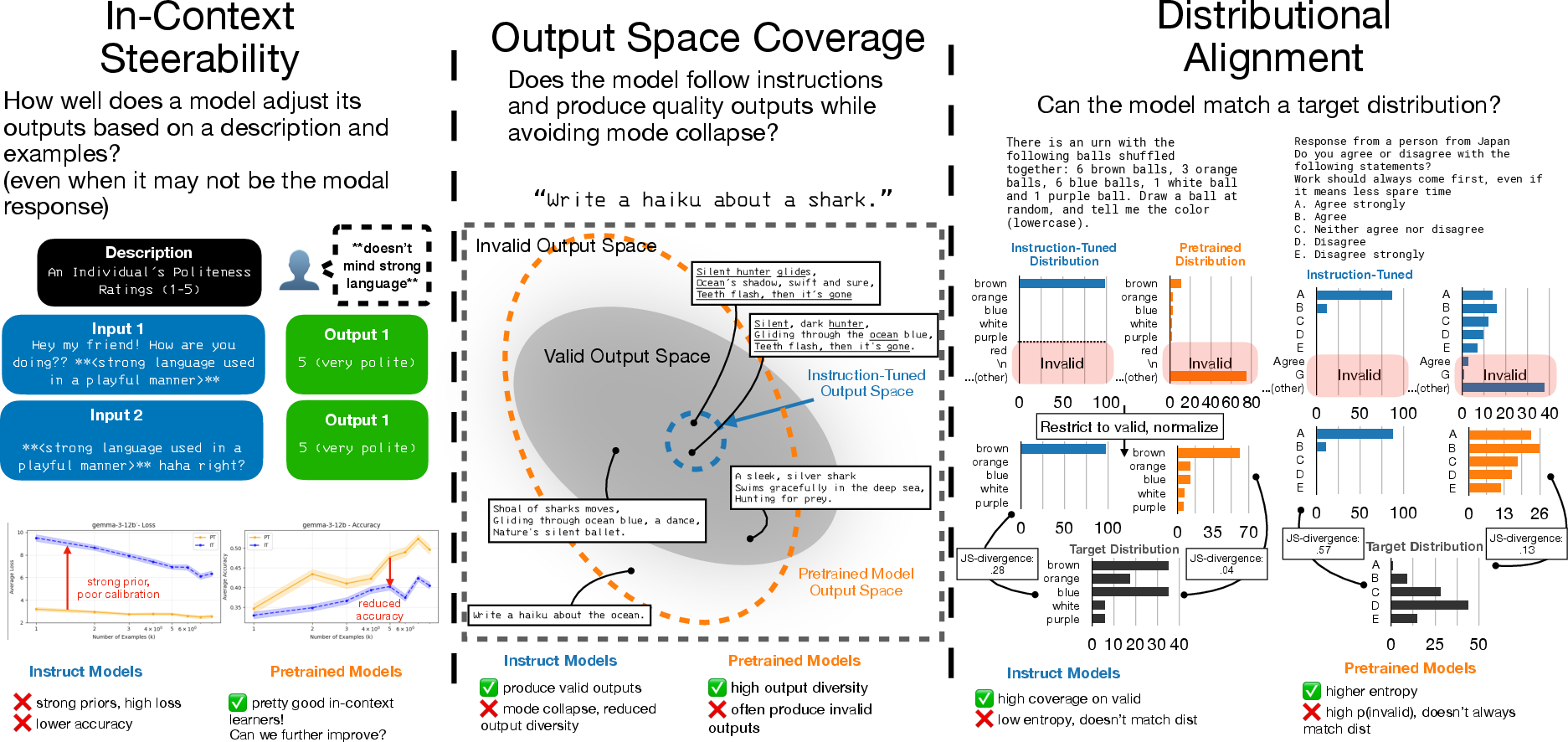
- In-context steerability: If you show the AI some examples or describe a new style or rule, can it shift how it answers right away?
- Valid output coverage: When many answers could be correct (like ideas for stories, possible hypotheses, or valid numbers), does the AI explore lots of those possibilities instead of repeating the same few?
- Distributional alignment: If you want the AI to match a whole pattern of answers (like the mix of opinions in a population or draws from a random process), can it produce responses with the right overall balance?
They asked: Do today’s instruction-tuned models damage these abilities? And can a new training method fix that without breaking other skills?
How did they study it?
To test and improve these abilities, they built two things: a big dataset and a new training recipe.
The three big ideas, in plain terms
- In-context steerability is like steering a car using new road signs you just saw. If you show the AI your writing samples, can it instantly switch to your style?
- Valid output coverage means exploring the space of correct answers. Think of brainstorming: more varied, still-correct ideas are better than repeating the same one.
- Distributional alignment means matching the overall “shape” of outcomes. If a survey shows 40% “Yes,” 60% “No,” the AI shouldn’t always say “Yes”—it should match the 40/60 balance when asked to simulate the population.
The new dataset: Spectrum Suite
They collected Spectrum Suite, a large set of over 90 tasks from more than 40 sources. These tasks include:
- Human preferences and opinions (people disagree a lot, and that’s the point)
- Creative text sets (like poems of a certain kind)
- Random draws (like numbers from a certain distribution)
- Uncertain reasoning tasks
Each task is standardized as:
- description: what the task is
- input: the prompt or context for a specific example (if any)
- output: the answer the AI should produce
This variety encourages models to learn how to steer, explore many valid answers, and match target patterns.
The new training method: Spectrum Tuning
Simplified, the recipe looks like this:
- Show the model a task description and several examples of inputs and correct outputs.
- Train it by “grading” only the outputs (not the instructions or the inputs).
- Shuffle examples and include multiple outputs from the same task so the model learns the overall pattern, not just a single “right” answer.
- The idea: by seeing many samples from a task’s “true” variety, the model learns to both steer and cover that variety.
Analogy: Imagine a coach who only scores your final answers but shows you many examples of what “good variety” looks like. Over time, you don’t just memorize one answer—you learn the whole space of acceptable answers and when to switch styles.
They tested this on three model families (Gemma, Qwen, Llama) and compared:
- PT models: the original pretrained models
- IT models: instruction-tuned models (the usual chat models)
- ST models: their Spectrum-Tuned versions
What did they find, and why is it important?
Here are the main results, explained simply:
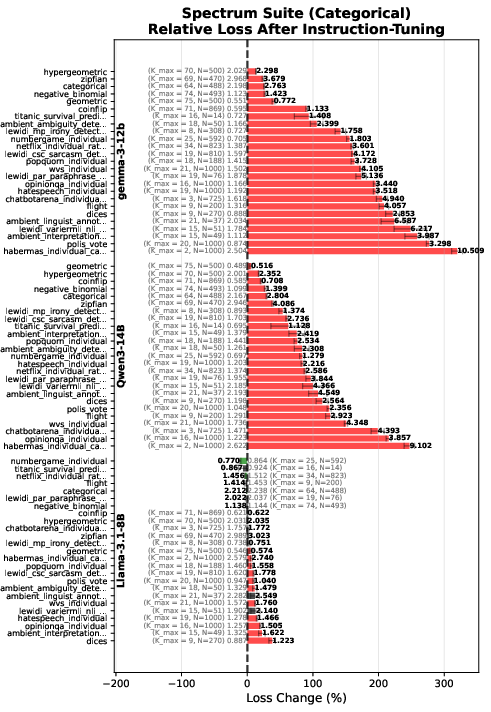
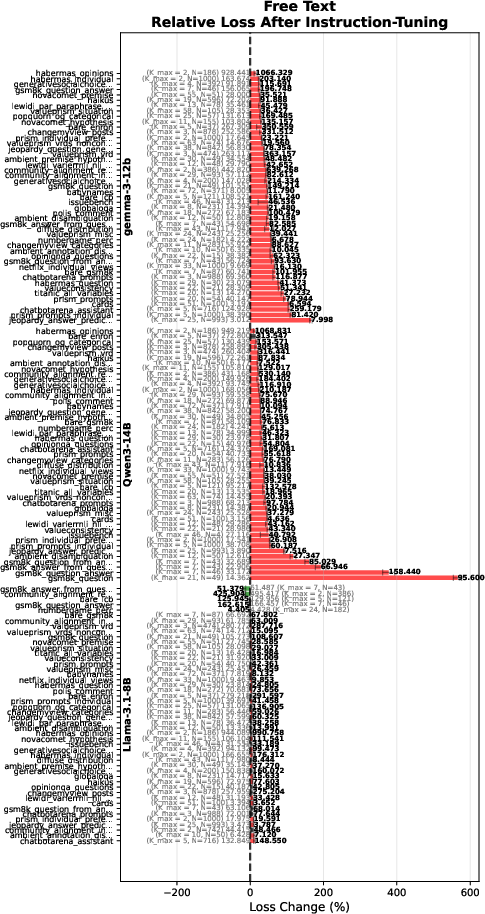
- Instruction-tuning helps on clear, single-answer tasks but hurts steerability. When a model must change behavior based on new examples in the prompt, many instruction-tuned models got worse. They held on too tightly to their habits instead of adapting.
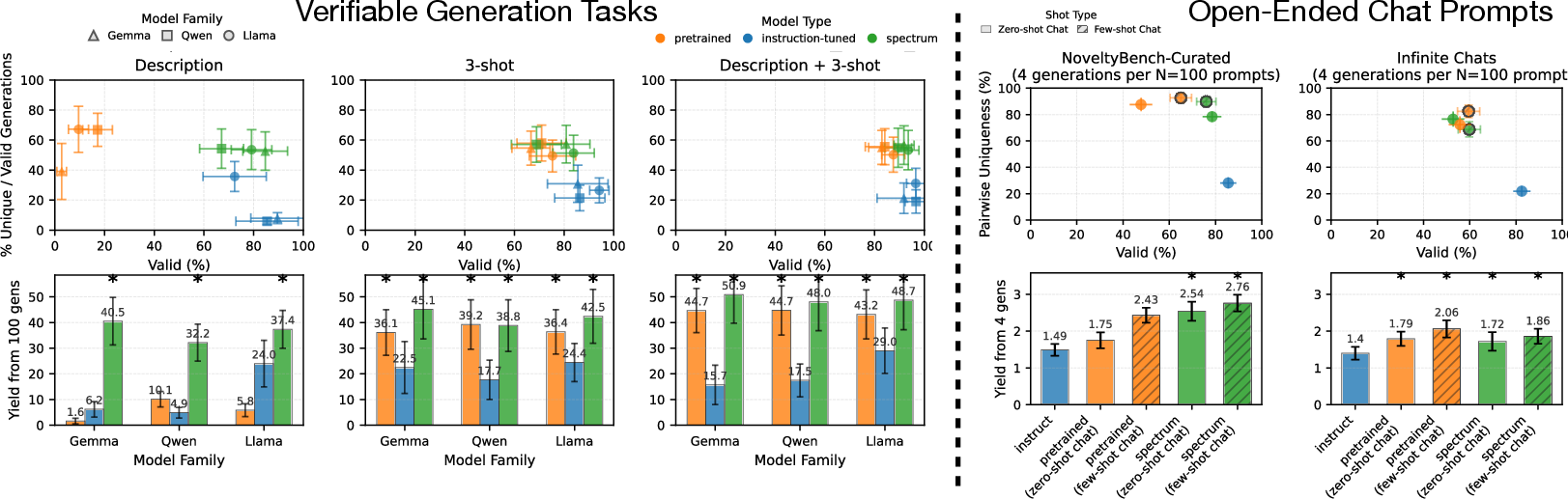
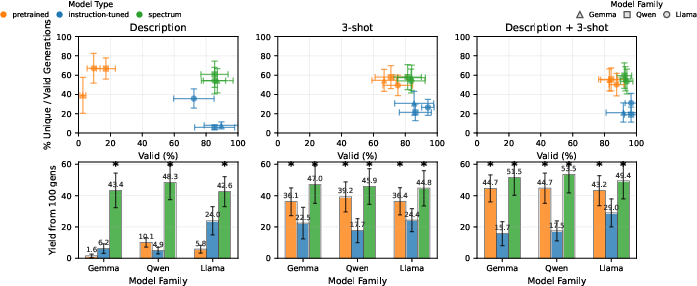
- Instruction-tuned models often become less diverse. They produce valid answers but repeat themselves, exploring only a small slice of what’s possible. That’s a problem for creativity, brainstorming, synthetic data, and scientific hypothesis generation.
- Spectrum Tuning usually restores or improves steerability. Compared to pretrained models, Spectrum-Tuned models match or beat them on tasks that require adapting from in-context examples, and they outperform instruction-tuned models on these tasks.
- Spectrum Tuning increases usable variety (“yield”). On tasks where many correct answers exist (like “name a prime number” or “generate a car make and model”), Spectrum-Tuned models produced more unique, valid answers—especially in zero-shot settings where only a description is given.
- Spectrum Tuning improves distributional alignment. When asked to match a whole pattern (like opinion distributions), Spectrum-Tuned models often beat pretrained models and clearly beat instruction-tuned models, which tended to be too “spiky” (overconfident in a narrow set of answers).
- Better calibration. Spectrum-Tuned models’ confidence better matched reality (when they were 70% confident, they were right about 70% of the time), which is useful for trust and risk-aware decisions.
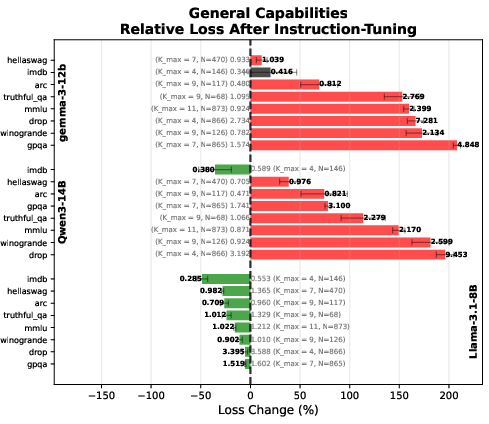
- General knowledge isn’t harmed. On standard benchmarks with single correct answers, Spectrum-Tuned models performed about as well as the original pretrained models (though instruction-tuned models still shine most on chatty, instruction-heavy tests).
Why this matters: If you want an AI that can personalize to you, explore more ideas, and fairly represent a range of human views or random processes, the usual instruction-tuning alone may not be enough—and can even make things worse. Spectrum Tuning helps fix that.
What could this change in the future?
- Better personalization and adaptation: AIs that instantly shift to your writing style, your company’s format, or a new task you describe with a few examples.
- Richer creativity and ideation: More diverse, valid outputs mean better brainstorming, content creation, and synthetic data generation.
- Fairer and more realistic simulations: Matching population opinion distributions or scientific randomness helps with research, forecasting, and policy testing.
- Safer decision-making: Improved calibration helps users know when to trust the model and when to be cautious.
- Rethinking post-training: Teams building AI may combine instruction-tuning with Spectrum Tuning to keep helpfulness while preserving diversity, steerability, and distribution matching.
In short, this work shows that “being good at following instructions” isn’t the whole story. For many real-world uses, you also need an AI that can adapt on the fly, explore many valid answers, and match the overall patterns you care about. Spectrum Tuning is a simple, practical step toward that goal.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that future work could address.
- Causal mechanisms of steerability degradation after instruction-tuning: isolate which components (SFT, RLHF/DPO, safety data, prompt templates, decoding settings) drive the observed loss in in-context steerability via controlled ablations on training objectives and datasets.
- Formal definition and measurement of “in-context steerability”: propose task-agnostic metrics that quantify the degree to which models override priors using context (e.g., information gain, KL between prior/posterior induced by demonstrations, sensitivity to contradictory examples).
- Prompt sensitivity and robustness: systematically test steerability under varied prompt formats, context lengths (8k–128k), demonstration ordering, distractors/adversarial examples, and noisy/mislabeled support sets.
- Data coverage and bias in Spectrum Suite: audit the >40 sources/>90 tasks for domain balance (creative vs. numeric vs. preferences), demographic representation, linguistic diversity (non-English), and potential measurement error; quantify how these affect the generality of results.
- Scaling and generalization: assess Spectrum Tuning on larger models (≥70B, MoE) and across more families; derive scaling laws for steerability, coverage, and distributional alignment as a function of parameters, data volume, and context size.
- Optimization sensitivity: systematically vary epochs (beyond ≤1), batch size, learning rate, description dropout probability, number of in-context examples, and loss-masking strategy; map trade-offs between distributional alignment, yield, and general capabilities.
- Reliance on IT special token initializations: remove or replace dependence on instruction-tuned (un/)embedding weights; compare plain-delimiter templates vs. chat-style format tokens; quantify the confounding effect of template/embedding choices on results.
- Decoding and sampler effects on diversity and yield: evaluate top-k, nucleus, temperature schedules, stochastic beam search, and entropy-preserving samplers; study yield/validity sensitivity to sampler choice and propose decoding strategies that maximize unique valid outputs.
- Calibration evaluation breadth: go beyond ECE with Brier score, negative log-likelihood on held-out sets, reliability diagrams, temperature scaling, and calibration under distributional shift; measure calibration of sequence-level probabilities, not just token-level.
- Distributional alignment beyond discrete labels: extend evaluation to continuous targets (e.g., numeric distributions), structured outputs (graphs, sets), and free-text distributions using proper scoring rules (e.g., CRPS, log score) and sampling-based goodness-of-fit tests.
- Integration with instruction-following and safety alignment: develop data-mixing or multi-objective schedules that preserve fine-grained constraint adherence (“five words”, format compliance) while maintaining diversity and steerability; evaluate toxicity, robustness, and hallucination rates post-tuning.
- Theoretical grounding of Spectrum Tuning: provide conditions under which cross-entropy on Monte Carlo samples recovers ; formalize the “underfit regime” requirement; connect meta-learning dynamics to Bayesian posterior estimation over task-generating distributions.
- Example selection policies: compare random vs. diverse/representative vs. active selection of in-context examples; test whether optimizing support sets (e.g., via Bayesian optimal design) improves steerability and distributional alignment.
- Benchmark completeness: build a unified suite measuring capability, steerability, coverage, and alignment together; include longer outputs, strict-format prompts, and multilingual tasks to prevent overfitting to narrow evaluation regimes.
- Human evaluation scale and rigor: expand beyond gemma-3-12b to other families; increase annotator counts and prompts; report inter-rater reliability with stronger adjudication; measure usefulness, novelty, safety, and adherence—not just validity.
- Failure modes in strict constraints: investigate why Spectrum-Tuned models miss precise requirements (length, format); test constraint-aware training (loss on control tokens), constrained decoding, or control vectors to recover instruction precision without sacrificing diversity.
- Interaction with retrieval and test-time adaptation: explore whether steerability gains can be achieved at inference (e.g., contextual calibration, retrieval-augmented in-context learning) without parameter updates; compare against Spectrum Tuning.
- Comparative baselines: run head-to-head with MetaICL, PRISM/pluralistic alignment methods, distribution-aware instruction tuning, entropy regularization, KL-to-prior penalties, and energy/MMD-based objectives on the same tasks.
- Domain generalization: evaluate steerability in code style adaptation, medical/legal domains, multimodal tasks, and non-English settings to test whether gains transfer beyond preference/numeric distributions.
- Long-context robustness: move beyond 1024-token windows; measure degradation and gains in steerability as contexts scale, with streaming examples and interleaved irrelevant content.
- Data contamination checks: verify that train/test splits are unseen with respect to pretraining corpora; quantify leakage risk and its impact on reported gains.
- Reproducibility and reporting: publish full training scripts, seeds, compute budgets, per-task prompts, and preprocessing details; standardize templates to reduce prompt-induced variance across PT/IT/ST comparisons.
- Societal and fairness impacts: assess whether improved distributional pluralism actually increases coverage of minority perspectives; measure group-wise distributional alignment, fairness metrics, and potential bias amplification due to increased diversity.
- Cost–benefit analysis: characterize compute/training time and memory overheads of Spectrum Tuning relative to gains in steerability and yield; provide guidance on practical deployment trade-offs in real systems.
Practical Applications
Immediate Applications
The following applications can be deployed today by fine-tuning an open-source LLM with Spectrum Tuning (SpecT) or by integrating its prompting format (description/input/output) and evaluation harnesses. Each item notes sectors, potential tools/workflows, and key assumptions or dependencies.
- Diverse, constraint-valid synthetic data generation
- Sectors: software/ML, healthcare (de-identified text), finance (scenario texts), robotics (simulation logs), education (item banks)
- What: Generate many unique outputs that satisfy verifiable constraints (e.g., regex/dictionary checks, membership lists), maximizing “yield” (unique valid items per budget).
- Tools/workflows: SpecT-tuned model; validity checkers; deduplication (e.g., NoveltyBench-style clustering); coverage/yield dashboard; temperature and sampling controls; batch generation API.
- Assumptions/dependencies: Domain verifiers exist and are reliable; compliance/privacy reviews for synthetic data use; sufficient compute to fine-tune and sample; prompt templates adapted to description/input/output.
- Preference-steerable assistants for personal style and tone
- Sectors: productivity, customer support, marketing, software (developer tools)
- What: In-context steer to a user’s writing or coding style using a short description plus a few examples; maintain diversity without sacrificing validity.
- Tools/workflows: “Preference Steer” prompt block; small local memory of user examples; calibrated sampling; yield-aware multi-sample generation; per-user persona cards.
- Assumptions/dependencies: User consent and privacy; small curated examples per user; alignment with org tone policies; performance trade-offs with heavy instruction-tuning (SpecT mitigates).
- Distribution-matching for surveys and social science
- Sectors: policy, academia (social sciences), civic tech
- What: Match population response distributions (pluralistic alignment) and report divergence (e.g., Jensen–Shannon) for opinion questions, ratings, or multiple choice.
- Tools/workflows: “Distributional alignment” mode; divergence and coverage metrics; pluralism dashboards; scenario probing; zero-shot description prompts.
- Assumptions/dependencies: Reliable ground-truth distributions; clear mapping from textual outputs to discrete classes; careful bias and ethics review.
- Coverage-aware ideation and variant generation
- Sectors: marketing, product design, entertainment
- What: Produce a broad slate of valid concepts (taglines, plot ideas, UX copy) with high uniqueness; surface coverage gaps; avoid mode collapse in creative tasks.
- Tools/workflows: Batch generation with yield and pairwise uniqueness metrics; theme clustering; “Generate until coverage target” button; review queue with filters.
- Assumptions/dependencies: Human-in-the-loop curation; brand/legal constraints; dedup heuristics tuned to domain.
- Calibrated multi-sample generation for A/B testing
- Sectors: marketing, UX research, experimentation platforms
- What: Generate candidate variants with probability calibration (ECE) checks; select balanced sets to test; monitor posterior shifts as feedback arrives.
- Tools/workflows: Calibration monitor; balanced sampler; feedback-weighted re-sampling; logging of per-variant likelihoods.
- Assumptions/dependencies: Reliable calibration at decoding temperature; experiment platform integration; guardrails against biased selection.
- Persona-steered customer support
- Sectors: customer experience, BPO, SaaS
- What: Steer responses to customer segment or locale personas (polite/concise/empathetic) via descriptions and few-shot exemplars; preserve diversity for non-scripted issues.
- Tools/workflows: Persona libraries; description dropout to encourage robust generalization; yield-aware sampling for escalation paths.
- Assumptions/dependencies: Up-to-date persona definitions; supervisory review for sensitive cases; KPI alignment (CSAT, FCR).
- Steerability and coverage QA in MLOps
- Sectors: software/ML platforms
- What: Add Spectrum Suite tasks to CI pipelines to routinely track steerability, distributional alignment, calibration, and yield.
- Tools/workflows: Evaluation harness; standardized prompts; metric panels (loss/accuracy/ECE/JS-divergence/coverage/yield); alerts on regressions.
- Assumptions/dependencies: CI compute budget; agreement on pass/fail thresholds; version-controlled prompt templates.
- Classroom and tutoring personalization
- Sectors: education
- What: Adapt explanations, examples, and feedback to a student’s level or teacher’s rubric using in-context steerability; generate diverse practice items under constraints.
- Tools/workflows: Rubric descriptions plus exemplars; constraint-verifiable item generation; yield and uniqueness checks; difficulty calibration.
- Assumptions/dependencies: Curriculum-aligned exemplars; fairness and accessibility review; educator oversight.
- Labeling variance simulation for data teams
- Sectors: software/ML data operations
- What: Model label distributions (not just single labels) to capture disagreement and uncertainty; evaluate model robustness under label plurality.
- Tools/workflows: Distributional alignment metrics; coverage tracking over valid labels; dataset curation with label provenance.
- Assumptions/dependencies: Gold distributions (from multi-annotator datasets); ethical handling of disagreement; task taxonomies.
- Code style conformity and refactoring
- Sectors: software engineering
- What: Steer code generation to team-specific style guides and patterns (naming, formatting, idioms) using a few in-repo examples.
- Tools/workflows: Description of style plus exemplars; pre-commit hook integration for validation; diverse candidate patches for code review.
- Assumptions/dependencies: Clear style guide; repository samples; static analysis validators.
- Risk/uncertainty-aware advice
- Sectors: finance (scenario narratives), healthcare communications (general info), safety engineering
- What: Provide calibrated probability summaries or multiple plausible outcomes; avoid spiky distributions that obscure uncertainty.
- Tools/workflows: Probability thresholds; ECE checks; multi-scenario generation; rationale aggregation.
- Assumptions/dependencies: Not for diagnosis or regulated decisions; domain experts validate; disclaimers and compliance.
- “Generate until coverage target achieved” feature
- Sectors: content platforms, data generation tools
- What: Automatically continue generation until a predefined coverage or yield threshold is met, with validity checks.
- Tools/workflows: Coverage estimator; streaming dedup; budget controls; stopping criteria.
- Assumptions/dependencies: Well-defined validity constraints; compute budget; governance for content quality.
Long-Term Applications
These opportunities require further research, scaling, or productization (e.g., domain suites, safety reviews, or new training objectives). Each item notes sectors and key dependencies.
- Pluralistic alignment integrated into post-training and RLHF
- Sectors: foundation model training, safety
- What: Add distribution-coverage and alignment objectives alongside instruction following to avoid diversity collapse and spiky priors.
- Dependencies: New reward shaping; safety evaluations; benchmark adoption; compute.
- Population simulation and civic deliberation support
- Sectors: policy/government, academia
- What: Simulate population-level opinion distributions to stress-test policies, messaging, or deliberative processes.
- Dependencies: Representative datasets; governance/ethics; transparency; anti-misuse safeguards.
- Persistent probabilistic user models for agents
- Sectors: productivity, personal AI
- What: Maintain user-specific posterior beliefs over preferences/styles across sessions for better steerability and diversity.
- Dependencies: Privacy-preserving memory; consent; on-device or encrypted storage; drift detection.
- Distributional APIs (“generate to target distribution”)
- Sectors: developer platforms, MLOps
- What: Expose APIs that accept target distributions or coverage constraints and return calibrated, diverse generations.
- Dependencies: Reliable distribution estimation; tooling standardization; cost controls.
- Domain-specific Spectrum Suites (healthcare, legal, finance)
- Sectors: regulated industries
- What: Curate task suites with verifiable constraints and pluralistic distributions tailored to domain norms and compliance.
- Dependencies: Domain experts; labeling standards; legal review; secure data handling.
- Multi-agent systems with diversity guarantees
- Sectors: simulation, creative industries, planning
- What: Coordinate agents to explore complementary regions of the solution space under coverage and validity constraints.
- Dependencies: Diversity-aware coordination protocols; evaluation harnesses; compute.
- Safety and fairness improvements via coverage monitoring
- Sectors: AI governance, safety engineering
- What: Monitor and enforce minimal coverage over minority perspectives to reduce homogenization and bias propagation.
- Dependencies: Perspective taxonomies; fairness audits; stakeholder participation.
- Optimization research for calibration and steerability
- Sectors: academia, foundation models
- What: Develop losses/regularizers and hyperparameter regimes (e.g., underfit/early stopping, special token strategies) to further improve distributional alignment while preserving capabilities.
- Dependencies: Benchmark consensus; reproducible experiments; open models.
- Finance and macro-risk simulation
- Sectors: finance, energy planning
- What: Generate calibrated scenario narratives matching historical or target distributions; support stress-testing and contingency planning.
- Dependencies: High-quality priors; expert validation; compliance; robust evaluation of tail risks.
- Clinical trial design with synthetic populations (textual artifacts)
- Sectors: healthcare research
- What: Use distribution-matched synthetic narratives (e.g., symptom descriptions) to pilot recruitment materials or assess protocol comprehension.
- Dependencies: IRB oversight; strict privacy; domain validation; not a substitute for clinical data.
- Standards and audits for steerability/coverage
- Sectors: policy, industry consortia
- What: Establish reporting norms (ECE, JS-divergence, coverage, yield) and audit procedures for LLM deployments.
- Dependencies: Multi-stakeholder process; interoperable tooling; certification pathways.
- Creativity engines with style distribution controls
- Sectors: media/entertainment
- What: Tune generation to match or diversify style distributions across genres; support editorial balance and novelty targets.
- Dependencies: Rights/attribution; style taxonomies; editorial workflows.
- Robust instruction-following without diversity loss
- Sectors: foundation model training, product UX
- What: Combine instruction capabilities with SpecT-like coverage objectives to avoid the validity-vs-diversity trade-off.
- Dependencies: Joint objectives; data mixture curation; scaled training.
- Enterprise analytics summarization with uncertainty
- Sectors: BI/analytics
- What: Summaries that reflect distributional variance rather than point estimates; better decision-making with uncertainty visualized.
- Dependencies: Data governance; KPI mapping; user education on uncertainty.
Cross-cutting assumptions and dependencies
- Data and privacy: Many applications need consented user data or representative population datasets; privacy-preserving storage and governance are essential.
- Evaluation and governance: Human-in-the-loop validation, fairness audits, and misuse prevention are required, especially for policy and healthcare settings.
- Model and tooling availability: Access to open models (e.g., Gemma, Llama, Qwen), the Spectrum Suite dataset, and SpecT training scripts; compute budgets for fine-tuning and multi-sample generation.
- Prompting and training details: Use description/input/output templates; initialize special tokens appropriately; consider early stopping/underfit regimes; restrict loss to output tokens for distributional alignment.
- Trade-offs: Heavy instruction-tuning can degrade steerability, coverage, and calibration; SpecT mitigates but productization may require hybrid strategies to retain chat-specific strengths.
Glossary
- Bayesian reasoning: Interpreting model updates to beliefs as Bayesian inference over distributions. "In-context steerability can also be seen as implicit Bayesian reasoning \citep{qiu2025bayesianteachingenablesprobabilistic} or as a subset of in-context learning/instruction-following tasks where the model must utilize novel information in-context."
- Capability elicitation: Using in-context examples or prompts to draw out latent skills or knowledge from a model. "Let us call this use of in-context learning capability elicitation, as its main purpose is to elicit some latent knowledge or capability of a LLM"
- Chain of thought: Prompting strategy that encourages models to generate step-by-step reasoning. "GPQA (5-shot with chain of thought, \citealt{rein2024gpqa})"
- Context window: The maximum number of tokens the model can consider in-context during inference. "fit into a 1024-token context-window."
- Cross-entropy loss: A standard objective for training probabilistic models to match a target distribution of outputs. "then perform supervised finetuning calculating cross-entropy loss only on the output tokens."
- Description dropout: Randomly removing the task description during training to encourage robustness. "Description dropout w/ prob. "
- Distributional alignment: Making a model’s output probabilities match a target output distribution. "To our knowledge, our method is the first to improve distributional alignment over pretrained models."
- Distributional pluralism: Representing a population by matching the distribution of their opinions or responses. "propose distributional pluralism for modeling or representing a population by matching their opinion distribution."
- Exchangeable: A property of data where the joint probability is invariant to the order of samples. "i.e. ``exchangeable" in Bayesian analysis \citep{bayesianstatisticalanalysis}, as the posterior is invariant to sample order."
- Expected Calibration Error (ECE): A metric quantifying the mismatch between predicted confidences and empirical accuracies. "Expected Calibration Error (ECE, )"
- Few-shot learning: Adapting to a new task using a small number of in-context examples. "zero-shot instruct models have even surpassed their few-shot pretrained counterparts"
- Greedy decoding: Generating text by iteratively selecting the most probable next token at each step. "whether the greedily-decoded model response results in the correct answer."
- In-context learning (ICL): Learning or adapting at inference time from examples included in the prompt rather than updating model weights. "We disambiguate between two kinds of in-context learning: ICL for eliciting existing underlying knowledge or capabilities, and in-context steerability, where a model must use in-context information to override its priors and steer to a novel data generating distribution."
- In-context steerability: The ability of a model to adjust its output distribution based on novel information provided in-context. "Let us term this ability in-context steerability."
- Independent and identically distributed (i.i.d.): A set of samples drawn independently from the same distribution. "are i.i.d. draws from a random distribution (e.g., draws from a normal distribution)"
- Instruction-tuning: Post-training that optimizes models to follow instructions, often impacting distributional properties. "Current instruction-tuning hurts in-context steerability."
- Jensen–Shannon divergence: A symmetric measure of difference between probability distributions. "calculate Jensen-Shannon divergence from the target distribution."
- Meta-learning: Learning to learn across tasks by leveraging task-level structure and adaptation. "This is the classic meta-learning formulation \citep{hospedales2020metalearningneuralnetworkssurvey}, except that the target is a distribution over instead of a single ."
- Mode collapse: Degeneration where a generative model produces low-diversity outputs concentrated in a few modes. "Pretrained models do not suffer from the same mode collapse, and consistently have higher diversity"
- Monte Carlo samples: Random samples from a distribution used to estimate properties of that distribution. "Because cross-entropy loss on Monte Carlo samples from a distribution encourages a well-calibrated estimate of the underlying distribution in the underfit regime (1$ epoch, \citealt{ji2021earlystoppedneuralnetworksconsistent})"</li> <li><strong>Negative log-likelihood (NLL)</strong>: A loss function that penalizes low probability assigned to observed data. "measuring the loss (negative log-likelihood) of each output conditioned on the prior examples under the model $m_\theta$"</li> <li><strong>Pareto improvement</strong>: An improvement along multiple objectives where no objective is worsened. "\method generally offers a Pareto improvement on diversity-validity over PT/IT models."</li> <li><strong>Posterior</strong>: The updated probability distribution after observing data or evidence. "Instead, the model must 1) maintain a prior over many possible generation functions and 2) maximally leverage in-context information in a well-calibrated way to form a posterior."</li> <li><strong>Prior</strong>: The initial belief or distribution before observing task-specific evidence. "ICL for eliciting existing underlying knowledge or capabilities, and in-context steerability, where a model must use in-context information to override its priors and steer to a novel data generating distribution."</li> <li><strong>Probability mass function (PMF)</strong>: A function that gives the probability of discrete outcomes. "Distinct from valid output coverage, distributional alignment includes a target probability mass function."</li> <li><strong>Support set</strong>: A set of in-context examples used to condition learning for a task. "Sample description $zS=\{(x_j,y_j)\}_{j=1}^{n}$."</li> <li><strong>Supervised fine-tuning</strong>: Updating model parameters using labeled input-output pairs and a supervised loss. "In many ways, \method is similar to supervised fine-tuning on instruction data"</li> <li><strong>Temperature (sampling)</strong>: A parameter that controls randomness in sampling from a model’s output distribution. "($\textrm{temperature}=1$ here and throughout)"</li> <li><strong>Terminal token</strong>: A special token used to mark the end of an output sequence. "terminal token $\langle\text{END}\rangle$"</li> <li><strong>Valid answer coverage</strong>: The total probability mass the model assigns to the set of valid outputs. "Valid answer coverage ($\uparrow$)."
- Valid output coverage: The extent to which a model can produce many different valid outputs for a prompt. "Valid Output Coverage. Many prompts entail multiple valid responses."
- Yield: The number of distinct valid generations produced within a fixed generation budget. "the number of distinct valid generations (or, yield)."
- Zero-shot: Performing a task without any in-context examples, relying only on instructions or descriptions. "We prompt models zero-shot with a description of the setting and a target question."
Collections
Sign up for free to add this paper to one or more collections.