- The paper introduces TTGS, a framework that leverages graph search and subgoal execution to overcome long-horizon decision challenges in offline goal-conditioned reinforcement learning.
- It constructs a directed graph from pre-computed datasets using learned value functions or domain-specific signals to enable efficient trajectory stitching without extra training.
- Experiments demonstrate that TTGS significantly improves performance on various locomotion tasks, outperforming more complex planning methods while requiring no additional online interaction.
Test-Time Graph Search for Goal-Conditioned Reinforcement Learning
Abstract
The paper introduces Test-Time Graph Search (TTGS), a planning framework for enhancing goal-conditioned reinforcement learning (GCRL) agents in offline settings. TTGS addresses the challenges of long-horizon decision-making by leveraging pre-computed datasets and learned value functions to guide trajectory stitching. This approach provides an inference-time solution that significantly improves success rates across various locomotion tasks without requiring additional training, supervision, or online interaction.
Introduction
Goal-conditioned reinforcement learning (GCRL) has emerged as a prominent method for training agents to achieve user-specified objectives. By decoupling behavioral policies from specific reward structures, GCRL facilitates broad data utilization without delicate reward engineering, making it applicable to domains like robotics and autonomous driving. However, offline GCRL faces significant challenges in long-horizon scenarios due to compounded errors in temporal credit assignment and decision-making.
TTGS addresses these challenges by employing a graph-based technique that constructs a weighted graph over the state space using either value functions or domain-specific distance signals. This graph is leveraged during inference to compute efficient subgoal sequences through Dijkstra's algorithm, enabling agents to converge to distant objectives reliably.
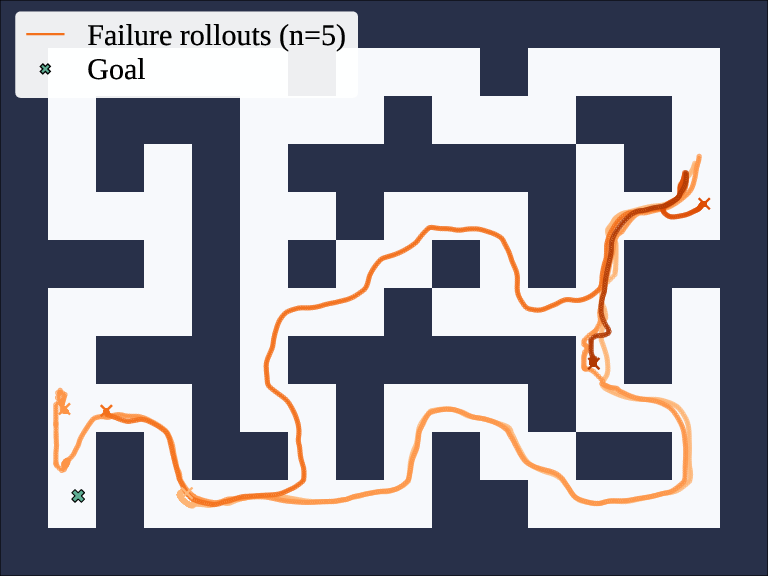
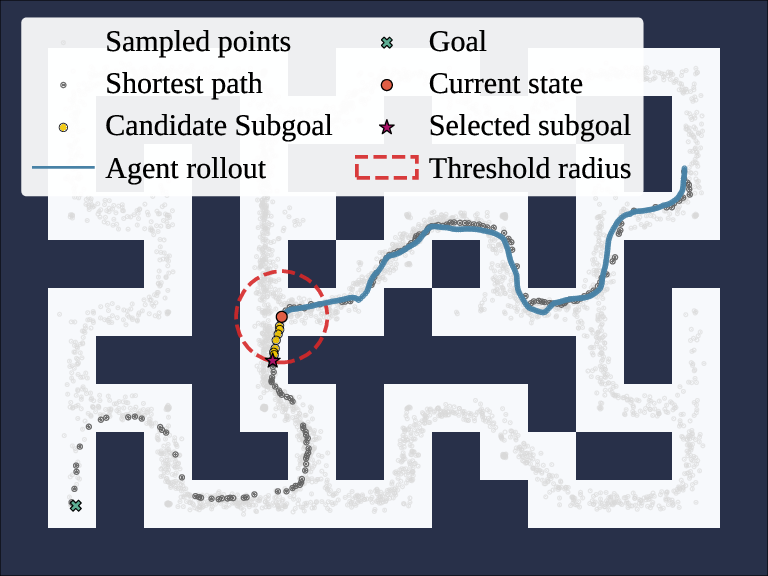
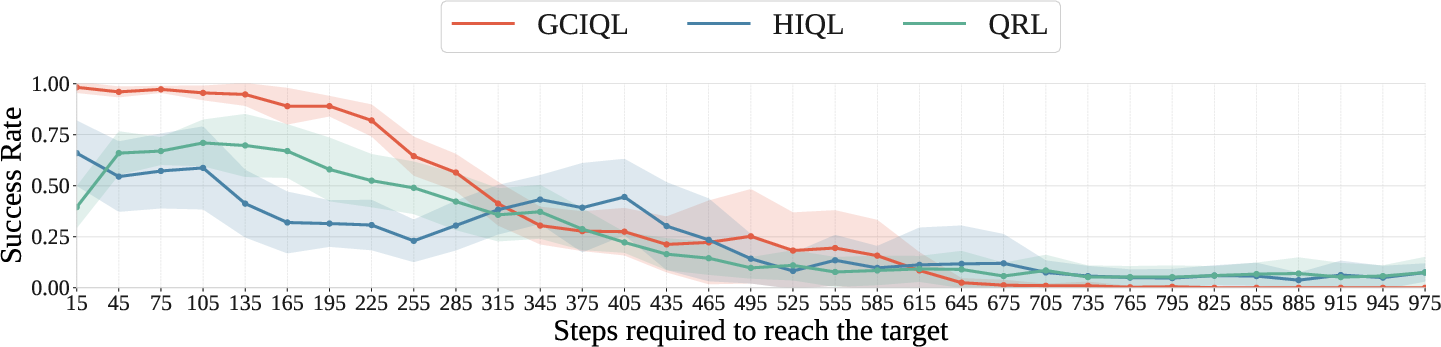
Figure 1: Rollouts from HIQL fail to reach a distant goal.
Methodology
The methodological core of TTGS revolves around three key processes: distance prediction, graph construction, and subgoal execution.
Distance Prediction
Distance prediction forms the backbone of TTGS, allowing the system to map state transitions in terms of expected rollout lengths. For value-based configurations, TTGS derives distances from the learned goal-conditioned value function, ensuring compatibility with existing GCRL frameworks. Domain-specific distances can also be employed, broadening TTGS's flexibility across various application landscapes.
Graph Construction
TTGS builds a directed graph over sampled states in the dataset. Distances between vertices are computed using either value-derived metrics or domain-specific signals, incorporating penalties for long jumps to enforce realistic traversal paths. This process ensures the graph reflects the feasible trajectories that align with the agent's learned capabilities, maintaining computational efficiency through sampling techniques and fast distance evaluations.
Subgoal Execution
Upon graph construction, TTGS uses a shortest-path algorithm to determine optimal subgoal sequences, which are subsequently fed to a frozen policy for execution. Subgoal selection occurs adaptively, dynamically selecting reachable subgoals that promote efficient task completion while mitigating common pitfalls inherent in direct, long-horizon execution attempts.

Figure 2: Goal-reaching success rates for QRL, GCIQL, and HIQL with and without TTGS. Distances are predicted from each base agent's learned value function. TTGS consistently improves or preserves performance on locomotion tasks that require trajectory stitching.
Experiments
TTGS was evaluated on the OGBench suite, targeting diverse locomotion challenges that demand hierarchical reasoning. The framework consistently enhanced performance across multiple GCRL algorithms (HIQL, GCIQL, QRL), often achieving superior results compared to existing complex planning solutions like GAS and CompDiffuser, which require additional training or model sophistication.
These results underscore TTGS's capacity to unlock latent capabilities within pre-trained policies, leveraging only test-time planning to overcome traditional model limitations.
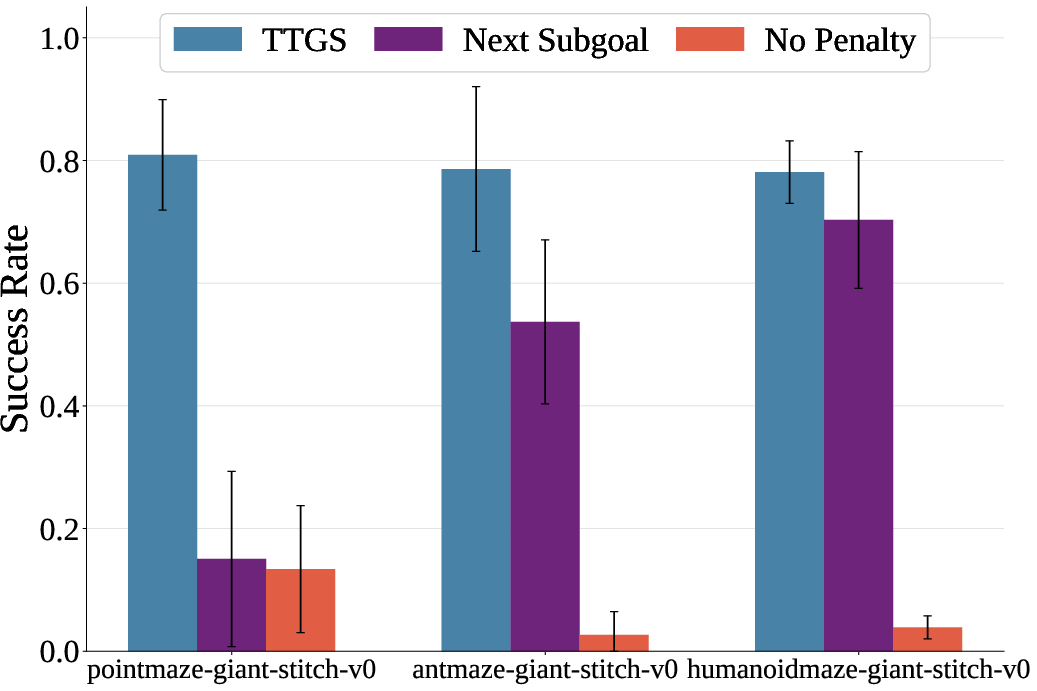
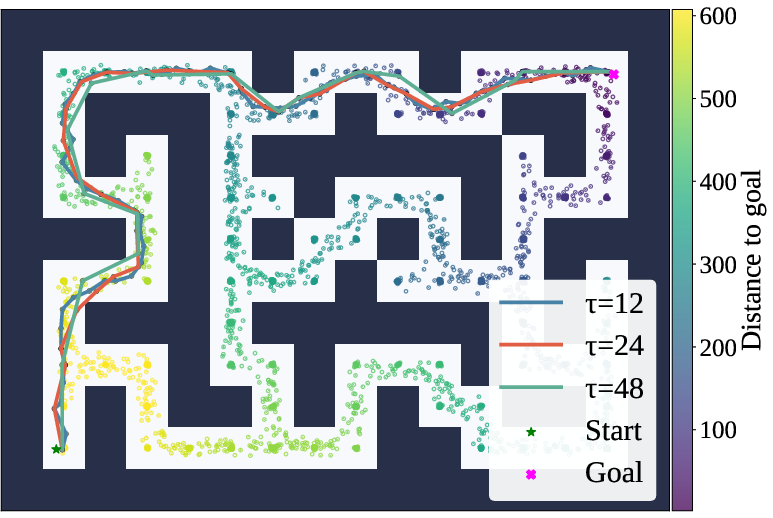
Figure 3: Ablations of HIQL+TTGS-value.
Limitations
Despite its successes, TTGS introduces mild computational overhead in graph construction and search operations. Furthermore, its reliance on the accuracy of the distance predictor and dataset coverage can occasionally limit performance, particularly in environments where the learned value functions are unreliable.
Conclusion
TTGS presents a robust framework for enhancing offline GCRL agents by transforming available datasets into actionable planning substrates without necessitating modifications to the existing training pipeline. It offers a practical solution to long-horizon planning, encouraging further exploration into modular planning strategies that combine the strengths of learned and algorithmic systems.
Overall, TTGS emerges as a potent resource for advancing goal-conditioned abilities within reinforcement learning paradigms, with promising applicability across diverse domains requiring nuanced planning capabilities.