- The paper demonstrates that a Whisper-based ML system can match or exceed human experts in detecting Parkinson’s Disease, especially using spontaneous speech tasks.
- It employs a robust experimental setup with the QPN dataset, incorporating five speech tasks, human expert evaluations, and advanced data augmentation techniques.
- The study highlights that machine detection is particularly effective for younger, mild, and female cases, suggesting significant implications for early, low-cost clinical screening.
Comparative Analysis of Human Expert and Whisper-Based Machine Detection of Parkinson’s Disease from Speech
Introduction
This study presents a systematic comparison between human experts and a Whisper-based ML system for detecting Parkinson’s Disease (PD) from speech. The investigation is grounded in the hypothesis that speech contains salient biosignals indicative of PD, and that both human and machine listeners may leverage different acoustic and linguistic cues for diagnosis. The work is motivated by the need for scalable, low-cost, and accessible diagnostic tools, given the limitations of current clinical practice, where general neurologists achieve only moderate diagnostic accuracy and specialist access is limited.
Experimental Design and Methodology
Dataset and Speech Tasks
The experiments utilize the Quebec Parkinson Network (QPN) dataset, comprising 208 PD patients and 52 healthy controls, all recorded in controlled acoustic conditions. Each participant performed five distinct speech tasks: sustained vowel phonation (SVP), sentence repetition, reading, memory recall, and picture description. These tasks span a spectrum from highly constrained phonatory tasks to spontaneous language production, enabling analysis of task-specific diagnostic utility.
Human Expert Evaluation
Seven experienced clinicians (four speech-language pathologists, three neurologists) participated in blinded listening tests. Each was presented with 64 balanced audio samples (≤30s), stratified by diagnosis, sex, language, and task. For each sample, experts provided a binary PD/HC judgment, a four-level confidence rating, and a categorical reason for their decision (voice quality, prosody, language use, typical speech, or other). This protocol enables both accuracy assessment and qualitative analysis of expert reasoning.
Machine Learning System
The ML system is based on a frozen Whisper Small encoder, with a lightweight classification head: linear layer, attention pooling, linear layer, and binary output. Dropout (0.2) and leaky ReLU activations are used for regularization. The model is trained on QPN data excluding all samples reviewed by human experts, ensuring strict separation of training and test sets. Data augmentation strategies include additive noise, random frequency notching, and temporal chunk dropout, applied dynamically to mitigate overfitting. Performance is averaged over six independent trials.
Results
The Whisper-based system matches or exceeds human expert performance across most categories when restricted to audio-only input. Notably, Whisper outperforms experts on spontaneous speech tasks (recall and picture description), which are less constrained and more reflective of naturalistic communication.
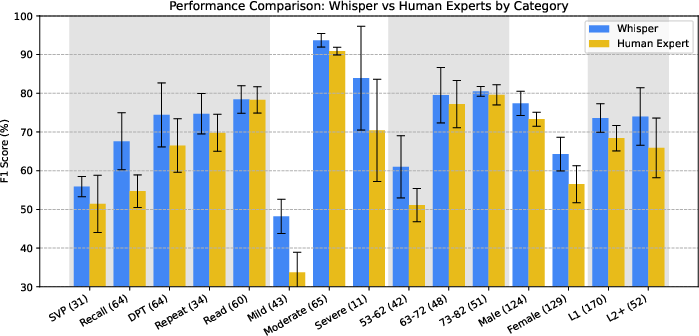
Figure 1: Performance comparison of human experts and the Whisper-based system across task, severity, age, sex, and language familiarity.
Demographic and Severity Subgroup Analysis
Whisper demonstrates a marked advantage in detecting PD among younger patients (53–62 years), mild cases, and female patients—subgroups where human expert performance is weakest. This suggests that the model is sensitive to subtle acoustic markers that may be less salient or less reliably interpreted by clinicians, particularly in early or atypical presentations.
Language and Sex Effects
Both human experts and Whisper perform better on male than female speech samples, even after controlling for age and severity. For non-native language samples, human experts report greater diagnostic uncertainty, likely due to confounding effects of L2 prosody and lexical retrieval. Whisper, however, closes this performance gap, indicating robustness to language background.
Expert Reasoning and Model Cues
Analysis of expert-provided reasons reveals that voice quality dominates judgments in constrained tasks (SVP, repetition), while prosody and language use are more frequently cited in spontaneous tasks. Whisper’s superior performance on samples where prosody is a key factor suggests that it may more reliably exploit prosodic cues for PD detection.
The study employed a custom speech sample rating tool for expert annotation, structured in three sequential views: binary diagnosis, confidence rating, and reason selection.

Figure 2: Screenshot of the first view in the speech sample rating tool.
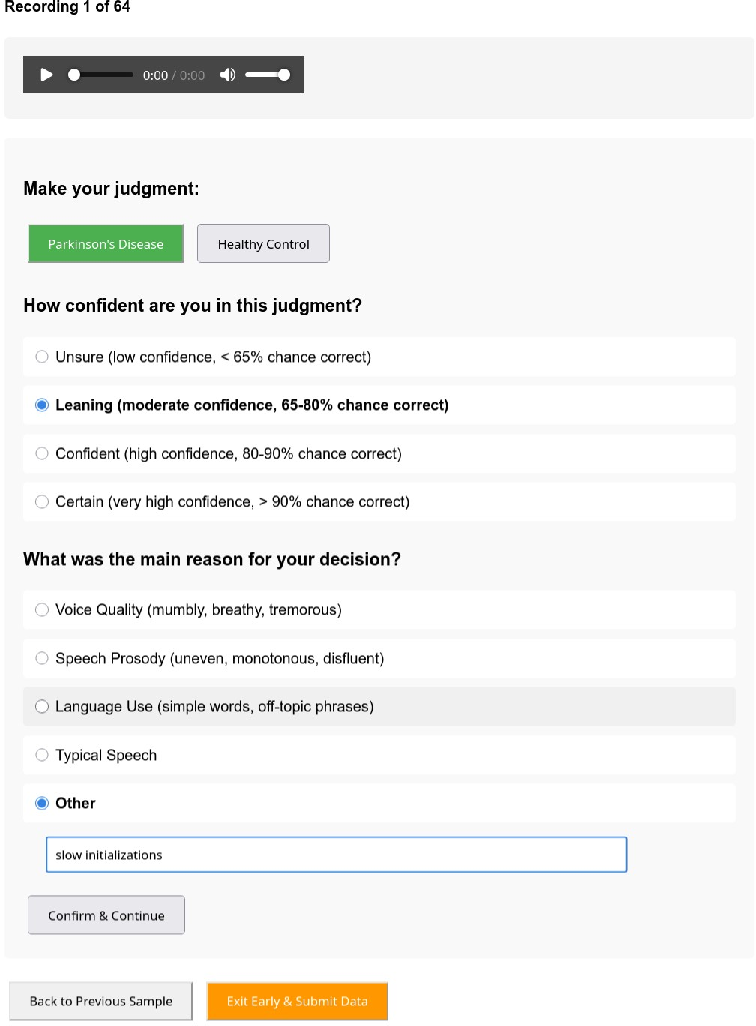
Figure 3: Screenshot of the second view in the speech sample rating tool.
Figure 4: Screenshot of the third view in the speech sample rating tool.
This interface facilitated systematic data collection and enabled fine-grained analysis of expert decision processes.
Discussion
The findings indicate that, when restricted to audio-only input, a Whisper-based ML system can match or surpass the diagnostic accuracy of experienced clinicians, particularly in challenging subgroups and spontaneous speech tasks. This supports the potential of speech-based ML models as accessible, scalable adjuncts to clinical assessment, especially for early or subtle cases where human performance is limited.
However, the study also highlights the complementary nature of human and machine expertise. Clinicians integrate multimodal and contextual information unavailable to the model, while the model excels at detecting subtle acoustic patterns. The black-box nature of the ML system remains a limitation for clinical adoption, as it does not provide explicit reasoning for its predictions. The collection of categorical expert reasons in this study represents a step toward aligning model explanations with clinical reasoning, but further work is needed to enhance interpretability and trust.
Implications and Future Directions
The demonstrated performance of Whisper-based models in audio-only PD detection suggests several practical and theoretical implications:
- Clinical Triage and Screening: ML systems could serve as front-line screening tools, flagging high-risk cases for further specialist evaluation, particularly in resource-limited settings.
- Early Detection: Enhanced sensitivity to mild and early-stage PD may enable earlier intervention and improved patient outcomes.
- Model Interpretability: Future research should focus on developing explainable AI techniques that bridge the gap between model predictions and clinical reasoning, potentially leveraging expert-annotated reasons as supervision signals.
- Task Optimization: The superior performance on spontaneous speech tasks suggests that diagnostic protocols should prioritize such tasks for both human and machine listeners.
Conclusion
This study provides a rigorous comparative analysis of human expert and Whisper-based machine detection of Parkinson’s Disease from speech. The results demonstrate that foundation model-based systems can achieve parity or superiority to clinicians in audio-only scenarios, particularly for spontaneous speech and diagnostically challenging subgroups. The work underscores the need for further research into model interpretability, integration with multimodal data, and deployment in real-world clinical workflows.