- The paper introduces GyroSwin as a scalable surrogate that directly simulates full 5D nonlinear gyrokinetic dynamics, capturing key phenomena like zonal flows.
- It leverages a Swin-based UNet with novel components such as 5D window attention and latent integrator modules to maintain stability over long autoregressive rollouts.
- Evaluation reveals superior heat flux prediction (lower RMSE) and accurate flux spectrum reproduction, while efficiently scaling to nearly 1B parameters.
GyroSwin: Scalable 5D Neural Surrogates for Nonlinear Gyrokinetic Plasma Turbulence
Motivation and Context
The accurate modeling of plasma turbulence is a central challenge in the design and operation of nuclear fusion reactors. Turbulent transport, governed by the nonlinear gyrokinetic equation, is a high-dimensional (5D) phenomenon that critically impacts energy confinement. Traditional approaches rely on reduced-order models (ROMs), such as quasilinear (QL) methods, which approximate turbulent transport by neglecting nonlinear interactions and employing empirical saturation rules. While computationally tractable, these models fail to capture essential nonlinear physics, notably zonal flows, leading to significant discrepancies in turbulent flux predictions.
GyroSwin addresses these limitations by introducing a scalable neural surrogate capable of directly modeling the full 5D nonlinear gyrokinetic dynamics. The model leverages hierarchical Vision Transformers, cross-attention, and integration modules to predict the evolution of the 5D distribution function, 3D electrostatic potential fields, and scalar heat fluxes, thereby providing a physically consistent and efficient alternative to ROMs.
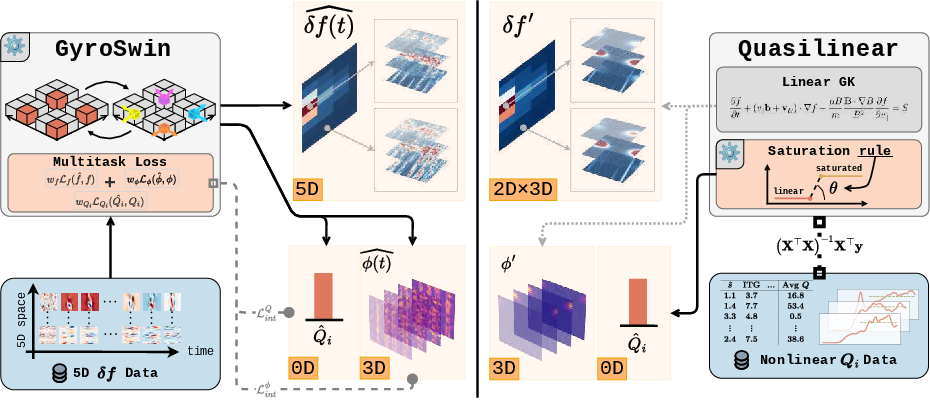
Figure 1: GyroSwin models the 5D distribution function of nonlinear gyrokinetics and incorporates integration blocks to predict 3D electrostatic potential fields and scalar heat flux. ROMs solve a cartesian product of 2D modes in spectral space and 3D fields, relying on saturation rules to approximate the nonlinear flux spectrum.
GyroSwin Architecture
GyroSwin is constructed as a Swin-based UNet with multitask heads for the 5D distribution function, 3D potential fields, and scalar fluxes. The architecture is designed to scale efficiently with input dimensionality and resolution, overcoming the quadratic complexity of standard Vision Transformers via local window attention. The core components include:
- 5D Shifted Window Attention (5DWA): Attention is performed within local 5D windows, enabling near-linear scaling with input size and preserving locality.
- Patch Embedding/Merging/Expansion: Inputs are partitioned into non-overlapping patches via local convolution, downsampled, and hierarchically merged to compress the representation, with skip connections for hierarchical feature fusion.
- Latent Integrator Modules: These modules aggregate the velocity space in the latent domain, enabling the reduction of 5D latents to 3D for potential prediction and facilitating cross-attention between 3D and 5D representations.
- Channelwise Mode Separation: Inspired by nonlinear physics, the architecture separates the zonal flow mode from other spectral modes, introducing real and imaginary components as additional channels to bias the model towards capturing essential nonlinear phenomena.
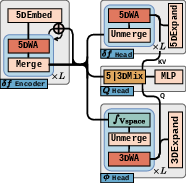
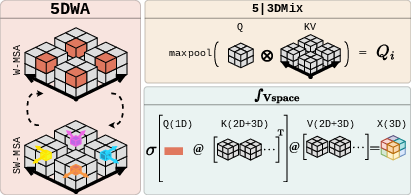
Figure 2: High-level GyroSwin architecture, illustrating multitask heads and integration modules for 5D↔3D latent interactions.
Experimental Setup and Data Generation
GyroSwin is trained on nonlinear gyrokinetic simulations generated with the GKW code, focusing on the adiabatic electron approximation to reduce computational cost. The dataset comprises 255 simulations, each with a resolution of (32×8×16×85×32), spanning a 4D parameter space (safety factor q, magnetic shear s^, ion temperature gradient R/Lt, and density gradient R/Ln). Latin hypercube sampling ensures uniform coverage of turbulent regimes. The model is evaluated on both in-distribution (ID) and out-of-distribution (OOD) test sets, with separate validation trajectories for model selection.
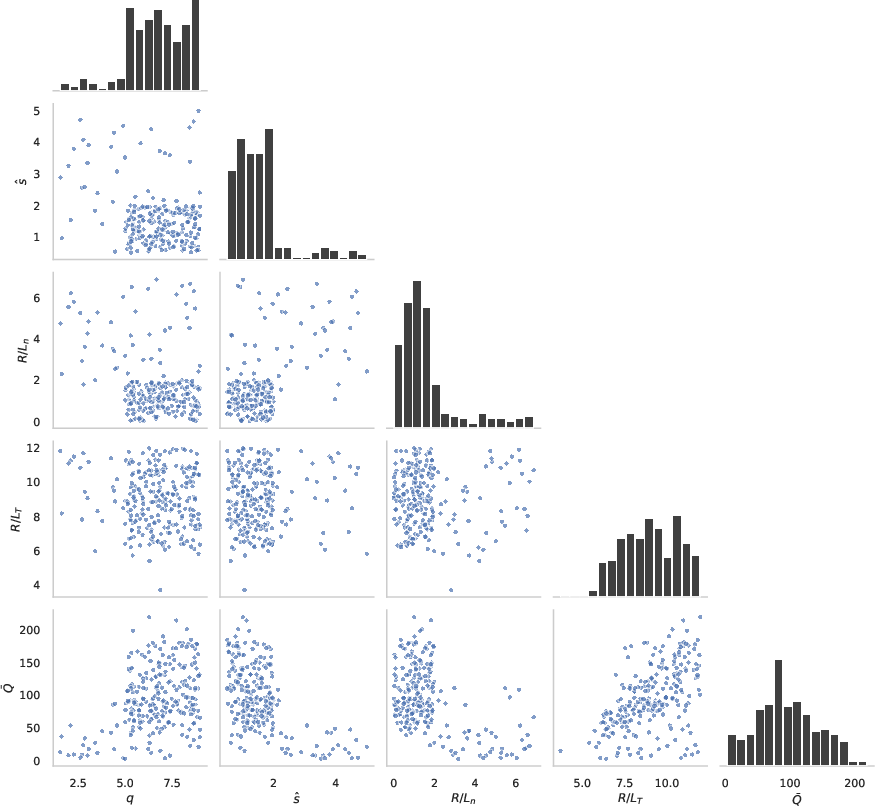
Figure 3: Distribution of input parameters s^, q, R/Ln, and R/Lt along with average heat flux Qˉ, demonstrating uniform sampling of the parameter space.
Results: Turbulence Modeling, Flux Prediction, and Scalability
5D Turbulence Modeling
GyroSwin demonstrates superior stability in autoregressive rollouts, maintaining high correlation with ground truth for over 100 timesteps, even in OOD scenarios. Competing neural surrogates (FNO, PointNet, Transolver, ViT) exhibit rapid error accumulation and instability, particularly in high-dimensional rollouts.

Figure 4: Side-by-side comparison of autoregressive rollout predictions with GyroSwin compared to ground truth (x and y in real space), in the saturated phase. GyroSwin preserves high-level structure and remains stable over long rollouts.
Nonlinear Heat Flux Prediction
GyroSwin achieves significantly lower RMSE in time-averaged heat flux predictions compared to QL models and other neural surrogates. On the large training set (241 simulations), GyroSwin attains RMSE values as low as 18.35±1.56 (ID) and 26.43±9.49 (OOD), outperforming QL models by a substantial margin. Notably, error accumulation in competing surrogates leads to overestimation of Qˉ, highlighting the importance of physically informed architecture and multitask training.
Physical Diagnostics: Flux Spectrum and Zonal Flows
GyroSwin accurately reproduces the flux spectrum Q(ky) and turbulence intensity spectrum W(ky), with near-perfect correlation to ground truth in high-data regimes. The model captures the energy transport per mode and the structure of turbulence, including the nonlinear damping effects of zonal flows.
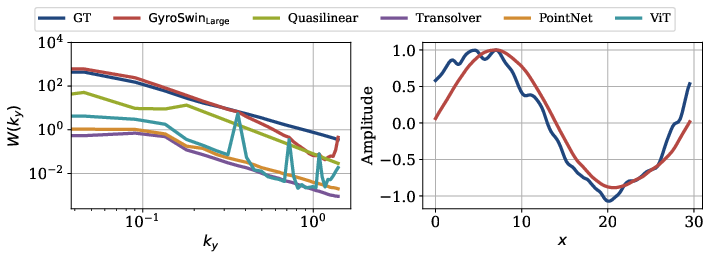
Figure 5: Left: W(ky) averaged over time and OOD simulations for different 5D neural surrogates. GyroSwin matches the spectrum well, with slight discrepancies at higher frequencies. Right: Time-averaged zonal flow profile for a slice along s across radial coordinates x for a selected OOD simulation. GyroSwin captures the zonal flow profile.
Scalability and Resource Efficiency
GyroSwin scales favorably in terms of inference speed, memory consumption, and parameter count. When scaled to ∼1B parameters and trained on 241 simulations (∼6TB of data), GyroSwin continues to improve training and validation loss, demonstrating strong scaling laws and suitability for high-fidelity plasma simulations.
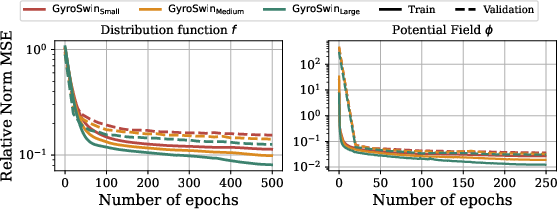
Figure 6: Scaling GyroSwin to ∼1B parameters trained on 241 simulations. Train/validation error for predicting the 5D distribution function (left) and the 3D electrostatic potential field (right) shows continued improvement with scale.
Implementation Considerations
- Computational Requirements: Training GyroSwin on large datasets requires distributed data parallelism and high-memory GPUs (e.g., H100 80GB). Lazy dataloading and mixed precision are essential for handling multi-terabyte datasets.
- Model Conditioning: Physical parameters and timesteps are encoded via FiLM-style conditioning, enhancing generalization across the parameter space.
- Data Preprocessing: Standardization and transformation from spectral to real space are critical for stable training and efficient patch operations.
- Autoregressive Rollouts: The model is trained for next-step prediction, with autoregressive inference enabling long-term evolution of the 5D field.
Limitations and Future Directions
GyroSwin does not currently model the chaotic, distributional nature of turbulence, leading to error accumulation in long rollouts. Incorporating generative modeling approaches (e.g., diffusion models) may mitigate this limitation by directly sampling from the saturated phase distribution. Extension to the linear phase and inclusion of kinetic electron effects are promising avenues for future work. Transfer learning from low-fidelity simulations could further enhance data efficiency and coverage of the parameter space.
Conclusion
GyroSwin establishes a new paradigm for surrogate modeling of nonlinear gyrokinetic plasma turbulence, directly evolving the 5D distribution function and capturing essential nonlinear phenomena, including zonal flows. The architecture's scalability, physical consistency, and superior predictive performance position it as a viable alternative to reduced-order models for integrated plasma simulations. The approach has broad implications for accelerating fusion reactor design, enabling real-time scenario optimization, and advancing the application of deep learning surrogates in high-dimensional scientific domains.