Self-Improving LLM Agents at Test-Time
Abstract: One paradigm of LLM (LM) fine-tuning relies on creating large training datasets, under the assumption that high quantity and diversity will enable models to generalize to novel tasks after post-training. In practice, gathering large sets of data is inefficient, and training on them is prohibitively expensive; worse, there is no guarantee that the resulting model will handle complex scenarios or generalize better. Moreover, existing techniques rarely assess whether a training sample provides novel information or is redundant with the knowledge already acquired by the model, resulting in unnecessary costs. In this work, we explore a new test-time self-improvement method to create more effective and generalizable agentic LMs on-the-fly. The proposed algorithm can be summarized in three steps: (i) first it identifies the samples that model struggles with (self-awareness), (ii) then generates similar examples from detected uncertain samples (self-data augmentation), and (iii) uses these newly generated samples at test-time fine-tuning (self-improvement). We study two variants of this approach: Test-Time Self-Improvement (TT-SI), where the same model generates additional training examples from its own uncertain cases and then learns from them, and contrast this approach with Test-Time Distillation (TT-D), where a stronger model generates similar examples for uncertain cases, enabling student to adapt using distilled supervision. Empirical evaluations across different agent benchmarks demonstrate that TT-SI improves the performance with +5.48% absolute accuracy gain on average across all benchmarks and surpasses other standard learning methods, yet using 68x less training samples. Our findings highlight the promise of TT-SI, demonstrating the potential of self-improvement algorithms at test-time as a new paradigm for building more capable agents toward self-evolution.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Self-Improving LLM Agents at Test-Time — A Teen-Friendly Explanation
Overview: What is this paper about?
This paper looks at a smarter way for AI “agents” (LLMs that can use tools and make decisions) to improve themselves while they are doing a task, not just during long training sessions. Instead of training on huge datasets (which is expensive and sometimes wasteful), the AI learns on-the-fly by spotting the questions it’s struggling with, making similar practice questions, and quickly updating itself to do better right away.
Think of it like a student taking a practice test: when they see a question they’re unsure about, they write a few similar questions and practice them. Then they go back and solve the original question with more confidence.
Objectives: What did the researchers want to find out?
The paper explores three simple ideas to make AI agents learn more like humans:
- Can an AI notice when it’s uncertain and likely to make a mistake?
- Can it generate useful practice examples based on the tricky question it’s facing?
- Can it do a quick, lightweight “mini-training” on those examples to improve its answer right now?
They test two versions:
- TT-SI (Test-Time Self-Improvement): the AI generates its own practice examples and learns from them.
- TT-D (Test-Time Distillation): a stronger “teacher” AI generates practice examples, and the student AI learns from those.
Methods: How does the approach work?
The method has three steps, like a mini study routine:
- Self-awareness (spot the hard cases): The AI measures how uncertain it is about what to do next. It looks at its top two choices and checks how similar their confidence levels are. If the top choice barely beats the second choice, that means the AI is unsure. This flags a “challenging” question.
- Everyday analogy: If you’re choosing between two answers and you feel only slightly more confident about one, you probably need to study that topic.
- Self-data augmentation (make practice problems): For each challenging question, the AI makes a small number of new, similar examples with correct answers (like variations of the original question). This gives it focused practice tailored to the specific thing it’s struggling with.
- Everyday analogy: If you’re shaky on a type of math problem, you create a few similar problems to practice.
- Self-improvement (quick learning): The AI does a tiny, temporary update using just these new examples. It uses a lightweight technique called LoRA (Low-Rank Adaptation), which is like adding small adjustable knobs to the model rather than retraining its whole “brain.” After it answers the question, it resets back to its original settings so it doesn’t forget other skills.
- Everyday analogy: You quickly review a few flashcards before answering a tricky question, then go back to your usual study plan.
There’s also a training-free variation: instead of updating its settings, the AI just places the new examples into its prompt (in-context learning), which can still help when you can’t run any training.
Results: What did they find, and why does it matter?
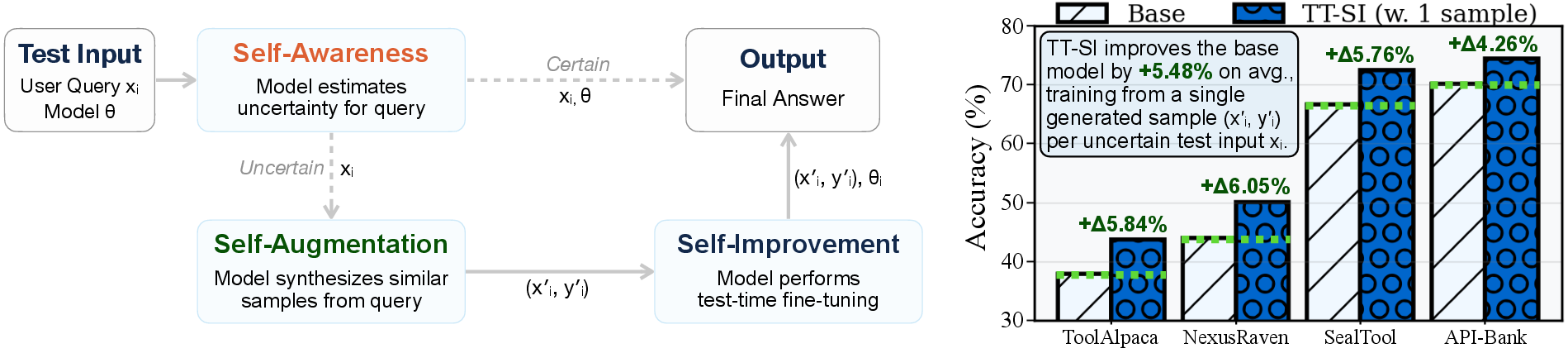
Across four tool-using tasks (ToolAlpaca, NexusRaven, SealTool, API-Bank), the approach consistently boosted accuracy.
Here are the big takeaways:
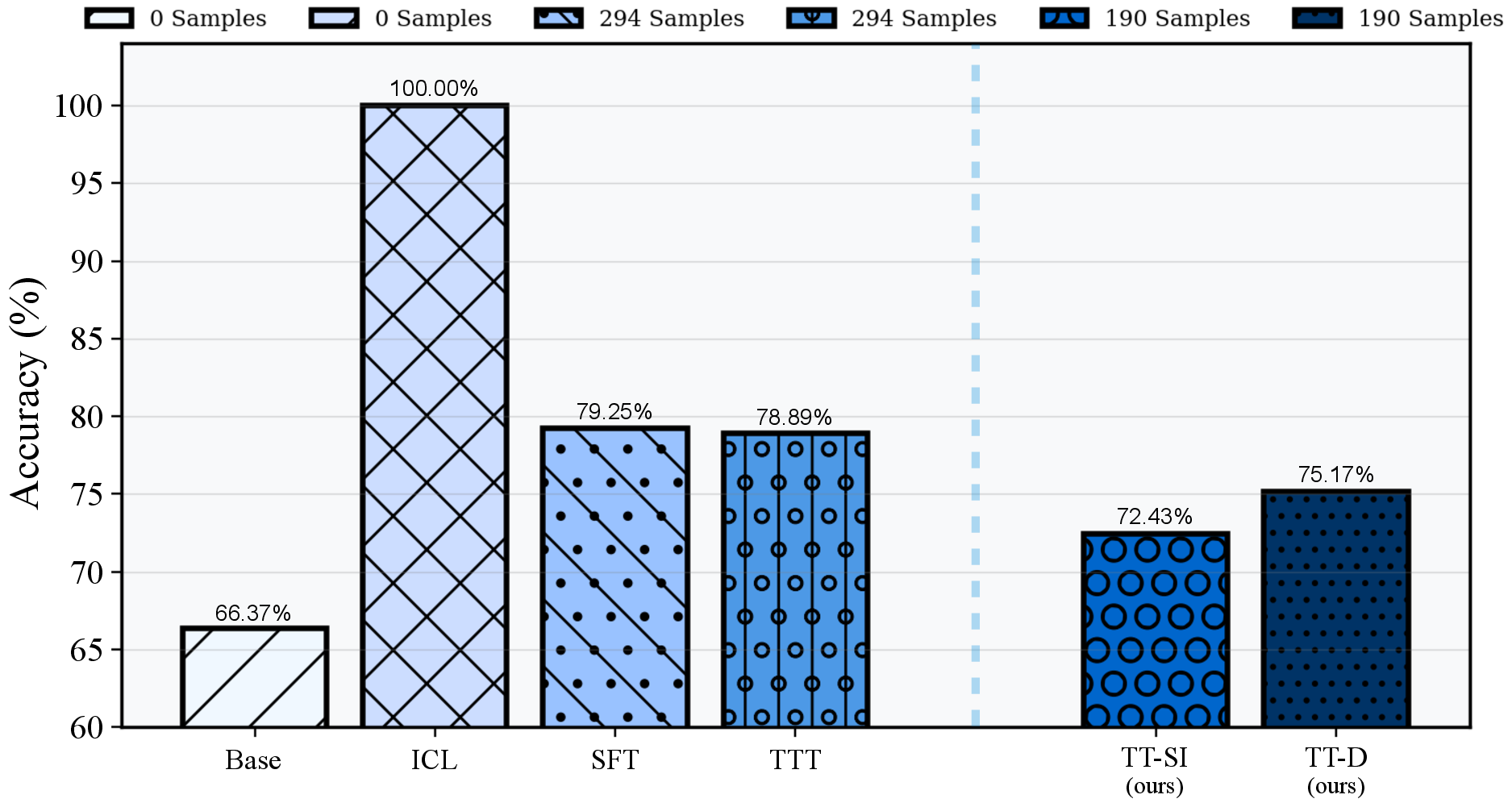
- With TT-SI, the AI improved by about +5.48% on average compared to just answering without self-improvement. This happened even when the AI trained on only one generated example per difficult case.
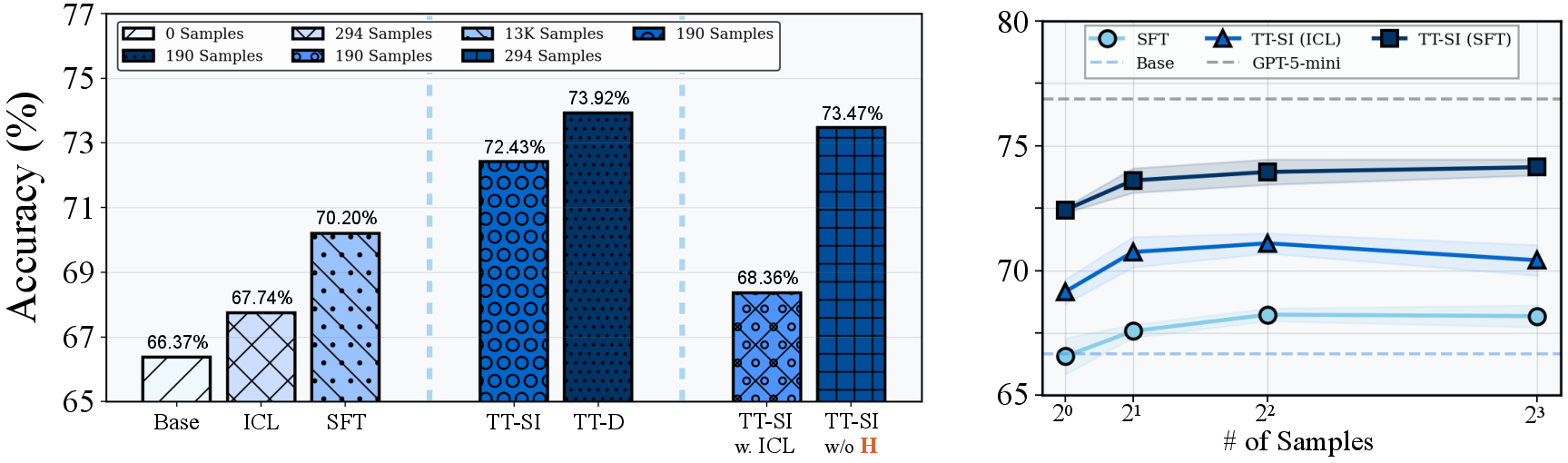
- TT-D (using a stronger teacher model to create examples) improved things even further, especially for complex, multi-turn conversations.
- The method was super efficient: on the SealTool benchmark, it beat standard supervised fine-tuning while using about 68× fewer training samples.
- When full training isn’t possible, the in-context version (no training, just adding examples into the prompt) still improved performance and even beat standard one-shot prompting.
- Picking only the uncertain questions to adapt on saves time and compute. Adapting to every single question gives only a tiny extra boost but costs a lot more.
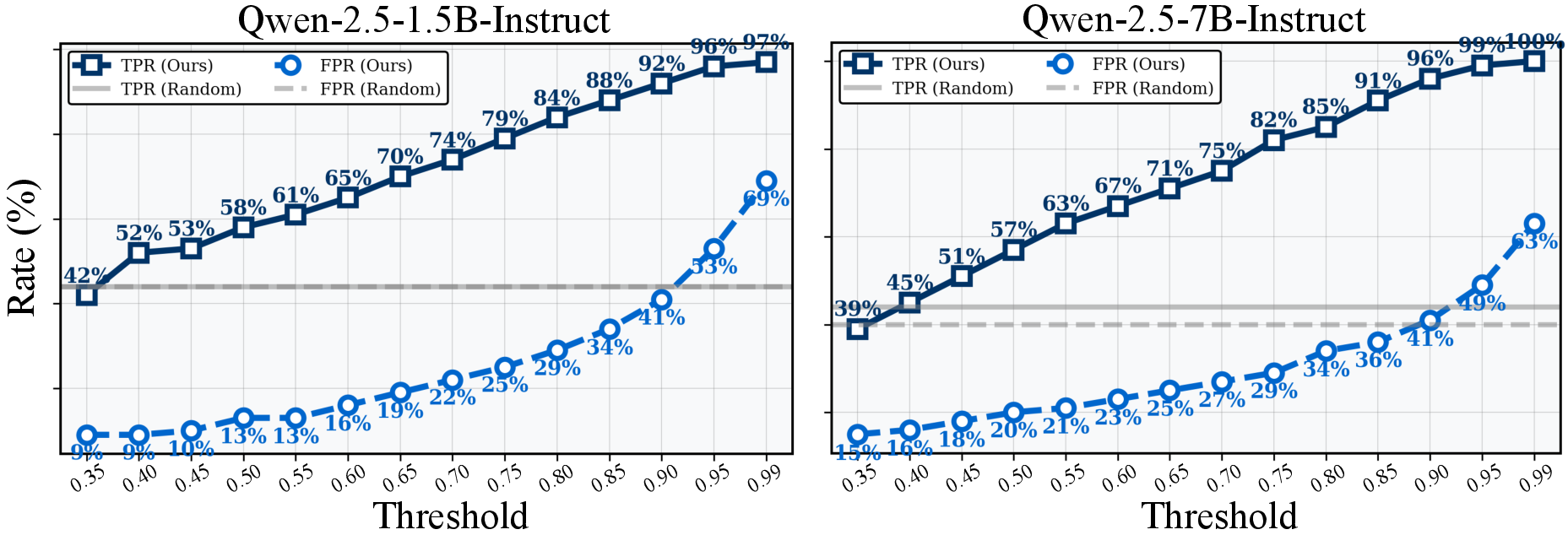
- Smaller models benefited even more (in % terms) than larger ones, which is great news for running useful AIs on limited hardware.
Why this matters: It shows a practical path to making AI agents more adaptable, efficient, and robust without massive retraining. The AI learns where it needs to, when it needs to.
Implications: What does this mean for the future?
This study suggests a new way to build AI agents:
- Cheaper and faster improvement: AIs can get better during use—no giant training runs needed every time.
- More generalizable behavior: By focusing on uncertain cases, the AI learns exactly where it’s weak, which helps it handle unusual or difficult situations.
- Modular design: You can swap in better uncertainty detectors, better data generators, or better quick-update methods as they are invented.
- Limitations: The method depends on choosing a good threshold for uncertainty, and it can only refine knowledge the model already somewhat has. For totally new facts, the AI might need external sources (like search or retrieval).
- Big picture: This points toward “self-evolving” agents—systems that not only answer questions but also improve themselves over time, much like students who identify gaps, practice smart, and grow their skills continuously.
In short: This paper shows how an AI can study smarter, not harder—learning exactly when and where it needs to, while it’s solving problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on them:
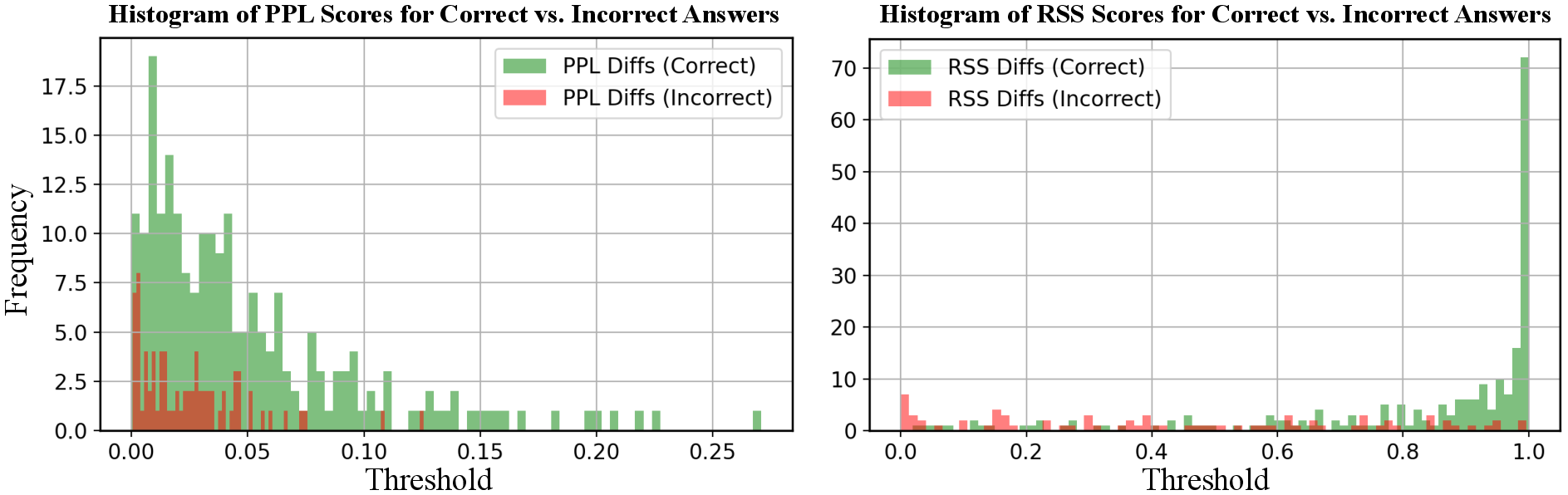
- Uncertainty estimator validity and calibration: Quantify how well the margin-based RSS score correlates with errors across tasks and models (ECE/Brier, AUROC for error detection), and compare against alternative estimators (entropy, temperature scaling, dropout/ensembles, Bayesian methods).
- Automatic threshold selection: Develop methods to learn or calibrate the uncertainty threshold τ per task/domain (e.g., Platt scaling, Bayesian gating, meta-learned thresholds), and evaluate robustness across distributions and session lengths.
- Applicability beyond discrete action spaces: Specify and test how SAorange generalizes to open-ended generation tasks (e.g., long-form reasoning, code synthesis) where candidate actions are not enumerated; define actionable confidence proxies in those settings.
- Label quality of self-generated data (SAforest): Measure label noise and correctness in synthetic pairs; introduce verification/consistency checks (self-critique, unit tests for tool parameters) and assess the impact of noisy labels on adaptation.
- Distributional alignment of synthesized data: Rigorously assess whether SAforest produces semantically similar yet sufficiently diverse examples (semantic similarity/diversity metrics), and study mode collapse or overfitting to superficial patterns.
- Confirmation bias and error reinforcement: Investigate whether training on self-generated labels entrenches wrong beliefs; test anti-bias strategies (teacher verification, counterfactual/adversarial augmentation, disagreement-based filtering).
- Test-time compute and latency: Provide wall-clock, memory, and energy profiles per uncertain case; quantify accuracy–latency trade-offs and define practical operating points for real-time systems with high QPS.
- Hyperparameter sensitivity in SAblue: Systematically ablate LoRA rank, learning rate, batch size, number of steps, optimizer choice, and initialization; characterize stability and failure modes of single-sample updates.
- Adapter lifecycle in multi-turn dialogues: Evaluate whether adapters should persist across turns or sessions (per-turn vs per-session adapters), and measure effects on coherence, state tracking, and cumulative performance.
- Short-term forgetting within sessions: Although parameters are reset per case, assess whether sequential ephemeral updates degrade performance on adjacent queries; study scheduling and interference across rapid successive adaptations.
- Cross-model generality: Test TT-SI/TT-D on diverse base models (e.g., Llama, Mistral/Mixtral, Phi, DeepSeek), languages, and domains to confirm architectural and multilingual generalization beyond Qwen.
- Task breadth: Extend evaluation beyond tool-calling to code generation, mathematical reasoning, structured prediction, factual QA, and safety-critical tasks; identify domains where TT-SI is less effective.
- Baseline coverage: Include head-to-head comparisons with strong TTT baselines (nearest-neighbor fine-tuning, SIFT, retrieval-augmented TTT, gradient-based ICL transforms) to isolate contributions over existing methods.
- Teacher selection in TT-D: Ablate different teachers (sizes, families), quantify teacher label quality, cost, and failure modes; characterize when distillation outperforms self-augmentation and why.
- Safety and adversarial robustness: Analyze whether malicious inputs can manipulate SAforest/SAblue to steer the model; design safeguards (adversarial detection, guardrails, robust training) and evaluate on attack suites.
- Real-world API execution: Move beyond offline/synthetic benchmarks to measure actual API success (parameter correctness, side-effect handling, rate limits), and define operational metrics (timeouts, retries, error recovery).
- Calibration effects of “sharpening”: Measure how TT-SI impacts calibration (ECE/Brier before/after), exploring trade-offs between accuracy gains and overconfidence, especially in safety-critical settings.
- Adaptive sample count (K): Replace fixed K with policies that decide K per case (e.g., uncertainty-driven, stopping criteria via self-verification), and study diminishing returns and optimal allocation.
- Formal guarantees: Develop theory for transductive single-sample updates (expected risk reduction bounds, overfitting control, convergence properties) and conditions under which “distribution sharpening” improves generalization.
- Combining ICL and fine-tuning: Evaluate hybrid strategies (using SAforest examples both in-context and for ephemeral adapters), and measure synergistic/antagonistic effects under constrained latency.
- Privacy and data governance: Assess privacy risks of training on live user inputs at test time; design privacy-preserving adapters, data minimization, and audit mechanisms for compliance.
- Adapter reuse and caching: Investigate clustering and caching of adapters for recurring uncertain patterns; measure memory costs, retrieval latency, and generalization from cached updates.
- Prompt sensitivity in SAforest: Quantify variance due to generation prompts, provide standardized recipes, and test automated prompt optimization to reduce engineering overhead.
- Evaluation metrics coverage: Report granular metrics (tool parameter correctness, output format adherence, multi-turn success rates) beyond accuracy/Pass@k to better capture agent competence.
- Alternative uncertainty selectors: Compare margin vs entropy vs mutual information; evaluate multi-criteria selectors that incorporate input hardness (e.g., syntactic complexity, OOD scores).
- OOD detection and long-tail handling: Test whether SAorange can separate truly OOD cases from in-domain uncertainty; integrate OOD detectors and study performance on long-tail distributions.
- Retrieval/external knowledge integration: Define gating policies for when latent knowledge is insufficient and retrieval/search should be invoked; measure gains and interactions with TT-SI.
- Bias and fairness impacts: Evaluate whether self-improvement amplifies demographic or domain biases; introduce fairness-aware selection or augmentation and track group-level performance changes.
- Scalability under high throughput: Explore batching/adapters-on-GPU scheduling, asynchronous adaptation, and prioritization under load; provide throughput and stability benchmarks for deployment.
Practical Applications
Immediate Applications
The following list outlines concrete, deployable use cases that leverage the paper’s test-time self-improvement (TT-SI) and test-time distillation (TT-D) methods, uncertainty gating (SAorange), self-augmentation (SAforest), and ephemeral LoRA updates (SAblue). Each bullet includes sector, application, potential tools/workflows, and feasibility notes.
- Sector: Software/DevTools
- Application: Production function-calling agents that self-adapt to long-tail API requests
- Tools/Workflows: Integrate an “TT-SI inference middleware” into existing agent stacks (e.g., LangChain/LlamaIndex) to:
- Compute uncertainty over candidate tools/actions via the softmax-difference margin
- Generate one similar input-output exemplar per uncertain case (self-augmentation)
- Apply ephemeral LoRA adapters for per-request updates; reset weights after response
- Assumptions/Dependencies: Access to model logits/probabilities for candidate actions; PEFT/LoRA support at inference; guardrails to avoid updating on adversarial inputs; threshold τ tuned for cost/performance
- Sector: Customer Support/Contact Centers
- Application: Self-improving chatbots that handle noisy, multi-turn dialogues (API-Bank-like scenarios)
- Tools/Workflows: Use TT-SI with ICL in low-compute settings; switch to TT-D for complex conversations with a centrally hosted teacher (e.g., GPT-class) generating higher-quality exemplars
- Assumptions/Dependencies: Moderation and privacy controls for generated exemplars; session-level caching of adapted adapters; prompt hygiene to prevent prompt injection during generation
- Sector: Enterprise Integration/RPA
- Application: Resilient workflow automation that “self-heals” on failing tool dispatches
- Tools/Workflows: Uncertainty gate microservice (SAorange) detects fragile calls; TT-SI produces a single targeted training item per failure mode; ephemeral fine-tuning improves the next dispatch; rollback to base weights after completion
- Assumptions/Dependencies: Observability/telemetry to monitor uncertain cases; API sandboxing; policy to disable TT-SI for high-risk operations
- Sector: Data Platforms/ETL
- Application: Robust data agents that adapt to schema drift or atypical queries at run-time
- Tools/Workflows: TT-SI for local adaptation when parsing/transforming out-of-distribution inputs; TT-D when a teacher model can supply precise exemplars for complex formats
- Assumptions/Dependencies: Clear candidate action space (parsers, validators); cost-aware τ to limit adaptation frequency; synthetic exemplars checked for format compliance
- Sector: Developer Productivity/Code Assistants
- Application: On-the-fly adaptation to unfamiliar library calls or API signatures
- Tools/Workflows: When the assistant is uncertain about a call, generate similar code snippets and usage examples; apply short LoRA updates to improve function selection/argument construction
- Assumptions/Dependencies: Access to repo context; guardrails to avoid memorizing proprietary code in adapters; storage limits for ephemeral adapters
- Sector: Education (Academic + Consumer)
- Application: Tutoring agents that mirror the paper’s paradigm by generating targeted practice problems when uncertain about a topic
- Tools/Workflows: Use SAorange to detect weak areas; SAforest to synthesize similar exercises; insert exemplars via ICL for training-free personalization; optionally use short LoRA updates for persistent sessions
- Assumptions/Dependencies: Curriculum-aligned prompts; correctness validation for generated solutions; avoid overfitting to synthetic patterns
- Sector: MLOps/Platform Engineering
- Application: Cost-efficient inference services that adapt only on uncertain requests
- Tools/Workflows: Service mesh plugin exposing τ as a tunable knob; per-request LoRA adapters with timeouts; adapter caching for recurring patterns; dashboards reporting accuracy vs. adaptation rate
- Assumptions/Dependencies: Stable deployment of PEFT ops; autoscaling policies mindful of adaptation cost; canary evaluation to detect regressions
- Sector: Healthcare (Administrative)
- Application: Self-adapting agents for scheduling, eligibility checks, and document formatting (non-diagnostic)
- Tools/Workflows: TT-SI for adapting to varied forms/templates and noisy patient inputs; TT-D when a teacher model provides compliant exemplar outputs
- Assumptions/Dependencies: Strict data governance; prohibition of TT-SI for clinical decision-making; validation layers for format/compliance; risk review for synthetic exemplars
- Sector: Finance (Customer Service/Compliance)
- Application: Adaptive form-filling and policy Q&A agents
- Tools/Workflows: TT-SI on uncertain policy interpretations; TT-D to distill exemplars aligned to current regulations; ICL mode for training-free deployments in regulated environments
- Assumptions/Dependencies: Human-in-the-loop approval; audit trails of adaptation events; policy snapshots pinned to exemplar prompts
- Sector: Public Sector/Policy Delivery
- Application: Small-model deployments for citizen services in compute-constrained environments
- Tools/Workflows: Deploy Qwen2.5-1.5B-class agents augmented with TT-SI to get +3–6% accuracy boosts using ~68× fewer samples than standard SFT; use ICL variant where training is infeasible
- Assumptions/Dependencies: Accessibility requirements; transparency notices on adaptive behavior; local teacher distillation only where permitted
Long-Term Applications
These use cases are promising but require further research, scaling, or integration work (e.g., stronger uncertainty calibration, safety frameworks, multimodal support, dynamic generation policies).
- Sector: Self-Evolving Agents (Cross-Industry)
- Application: Continual, test-time learning systems that autonomously choose how many exemplars to synthesize and which update rule to apply
- Tools/Workflows: Adaptive K selection; policy learners for τ; meta-learning over SAorange/SAforest/SAblue choices
- Assumptions/Dependencies: Robust uncertainty calibration; safeguards against distributional drift and data poisoning; lifecycle governance
- Sector: Personalization/On-Device AI
- Application: Per-user ephemeral adapters for assistants that learn local preferences without central training
- Tools/Workflows: Private TT-SI loops on-device; adapter rotation/decay; personalized uncertainty thresholds; encrypted adapter storage
- Assumptions/Dependencies: Efficient PEFT on edge hardware; privacy-preserving exemplar generation; battery/latency constraints
- Sector: Robotics
- Application: Tool-using robot agents that adapt to unfamiliar environments or tasks at deployment
- Tools/Workflows: Multimodal SAorange (vision + language) to detect uncertainty; TT-D from a simulation teacher; local LoRA for skill routing (function calling to controllers)
- Assumptions/Dependencies: Safe exploration policies; real-time PEFT; validated exemplars that do not induce unsafe behavior
- Sector: Healthcare (Clinical Decision Support; High-Stakes)
- Application: Adaptive triage or guideline retrieval agents that improve robustness to atypical presentations
- Tools/Workflows: TT-D with certified clinical teacher models; retrieval augmentation combined with TT-SI; strict audit and human validation
- Assumptions/Dependencies: Regulatory approval; bias/safety audits; external knowledge integration to address missing domain knowledge (noted limitation in the paper)
- Sector: Enterprise Change Management
- Application: “Self-healing” integration layers that adapt to evolving APIs, schemas, and policies without full retraining
- Tools/Workflows: Distributed uncertainty gates per service; organization-wide teacher distillation service; adapter registries with policy governance
- Assumptions/Dependencies: ITSM alignment; change control processes; rollback and fail-safe modes
- Sector: Multilingual/Localization
- Application: Adaptive agents for low-resource languages and domain-specific jargon
- Tools/Workflows: TT-SI for local dialects; TT-D with bilingual teachers; dynamic exemplar synthesis to reduce translation errors
- Assumptions/Dependencies: Strong teacher availability; dataset scarcity alleviated by high-quality synthetic examples; cultural/linguistic review
- Sector: Safety/Trustworthiness
- Application: Calibrated uncertainty and adaptive guardrails to minimize harmful outputs during adaptation
- Tools/Workflows: Learn τ via calibration; adversarial input detection before TT-SI triggers; sandboxed adaptation with differential privacy constraints
- Assumptions/Dependencies: Reliable uncertainty estimators; red-teaming pipelines; measurable safety metrics
- Sector: Research/Benchmarks
- Application: Standardized test-time learning benchmarks for tool-use agents with plug-and-play SAorange/SAforest/SAblue modules
- Tools/Workflows: Open-source “TT-SI toolkit” with reproducible protocols; teacher distillation harnesses; evaluation of cost-performance trade-offs
- Assumptions/Dependencies: Community adoption; clear measurement for Pass@k, majority vote, and direct inference; reporting norms for adaptation rate
- Sector: Policy/Regulation
- Application: Governance frameworks for adaptive systems that update at inference time
- Tools/Workflows: Compliance profiles defining where TT-SI is permitted (e.g., non-high-stakes); audit logs for adaptation events; certification of uncertainty thresholds
- Assumptions/Dependencies: Regulator engagement; standard-setting around adaptive inference; transparency requirements
- Sector: Advanced RAG/Knowledge Work
- Application: Hybrid retrieval + TT-SI where agents both pull external knowledge and self-adapt on uncertain queries
- Tools/Workflows: Uncertainty-triggered retrieval; exemplar synthesis grounded by retrieved documents; per-query adapters for complex reasoning
- Assumptions/Dependencies: Document attribution and provenance; mitigation of hallucination via verification; scalable adapter management
Notes on Feasibility and Dependencies
- Compute and latency: Ephemeral LoRA updates add per-request overhead; practical deployments must balance τ to adapt only when it matters.
- Data quality: Synthetic exemplars must be validated (format, correctness, safety); TT-D benefits from a strong, trusted teacher.
- Knowledge boundaries: As noted, TT-SI cannot create knowledge absent from the base model; retrieval or external tools may be needed.
- Safety and compliance: High-stakes domains require human oversight, audit trails, and clear policies limiting where TT-SI applies.
- Modularity: The framework is replaceable at each component—better uncertainty estimators, stronger data generators, and alternative update rules can be plugged in to improve performance.
Glossary
- Agentic LMs: LLMs designed to act autonomously (e.g., tool use) to complete tasks. "create more effective and generalizable agentic LMs on-the-fly."
- API-Bank: A benchmark evaluating agents in realistic multi-turn tool-use dialogues. "API-Bank (+4.26%)."
- Catastrophic forgetting: The tendency of a model to lose previously learned skills when fine-tuned on new tasks. "Standard fine-tuning for LMs often suffer from catastrophic forgetting"
- Distributional shift: A mismatch between training and test data distributions that degrades generalization. "Distributional Shift: Test distributions $\mathcal{P}_{\text{test}$ often differ from the training distribution $\mathcal{P}_{\text{train}$"
- Distribution sharpening: Adjusting a model’s output distribution to emphasize confident, high-reward predictions. "This process can be framed as distribution sharpening."
- Distilled supervision: Guidance produced by a stronger teacher model to improve a student model. "enabling the student to adapt using distilled supervision."
- Empirical risk: The average loss over the training dataset used to fit model parameters. "minimize the empirical risk on the training data:"
- In-context learning (ICL): Performing tasks by conditioning on examples in the prompt without parameter updates. "in-context learning (ICL) offers a fast, training-free alternative"
- Inductive fine-tuning: Training a model to generalize from a fixed dataset to unseen examples in a separate test set. "Fundamental Issues in Inductive Fine-Tuning"
- Local learning: Adapting a hypothesis to specific observed inputs rather than learning a global rule. "Motivated by local and transductive learning"
- Low-Rank Adaptation (LoRA): A parameter-efficient method that injects trainable low-rank matrices into layers for fast fine-tuning. "We employ Low-Rank Adaptation (LoRA)~\citep{hu2022lora}"
- Margin-based confidence estimator: An uncertainty metric using the difference between top probabilities to identify hard cases. "we implement a margin-based confidence estimator"
- Negative Log-Likelihood (NLL): A loss quantifying how unlikely the model considers the correct output; lower is better. "Negative Log-Likelihood (NLL) for candidate action"
- NexusRaven: A function-calling benchmark testing single, nested, and parallel calls. "NexusRaven~\citep{srinivasan2023nexusraven} is a function-calling benchmark"
- Out-of-distribution (OOD): Inputs drawn from a distribution different from the training data, often challenging for models. "out-of-distribution (OOD) setting"
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that adapt a small subset of parameters instead of the full model. "parameter efficient fine-tuning techniques (PEFT)~\citep{hu2022lora}"
- Pass@5: Evaluation metric where success is counted if any of five sampled outputs is correct. "Pass@5 (correct if any of 5)."
- Relative Softmax Scoring (RSS): A normalized confidence distribution over actions computed from likelihoods for uncertainty estimation. "Apply Relative Softmax Scoring (RSS) normalization"
- SealTool: A self-instruct tool-learning benchmark measuring precision and formatting adherence. "SealTool~\citep{wu2024sealtools} is a self-instruct dataset for tool learning"
- Self-awareness: The model’s ability to assess its own uncertainty and decide whether to adapt. "Self-Awareness: SAorange\ (SAorange) identifies inputs at inference-time which the agent is uncertain on,"
- Self-consistency: An inference strategy that aggregates multiple generations (e.g., majority vote) to improve reliability. "Majority Vote (5-sample self-consistency)"
- Self-Data Augmentation: Generating synthetic, distributionally similar examples from uncertain inputs to improve learning. "(self-data augmentation)"
- Self-Instruct: A data synthesis approach where an LLM generates instruction-output pairs to teach itself tasks. "self-instruct dataset"
- Self-reward: An internally defined scoring used to prefer high-quality outputs during self-improvement. "internally defined self-reward"
- Softmax-difference: The gap between the top two normalized scores used as a margin-based uncertainty measure. "Compute uncertainty (softmax-difference):"
- Supervised Fine-Tuning (SFT): Updating model parameters using labeled data and a supervised loss. "Compared to standard supervised fine-tuning (SFT), TT-SI surpasses accuracy"
- Test-time fine-tuning: Temporarily updating model parameters during inference for the current input. "uses these newly generated samples at test-time fine-tuning (self-improvement)."
- Test-time training (TTT): Performing small, ephemeral parameter updates at inference to adapt to observed test inputs. "Test-time training (TTT) performs small, ephemeral parameter updates during inference"
- Test-Time Distillation (TT-D): Adapting a student model at inference using examples generated by a stronger teacher. "Test-Time Distillation (TT-D), where a stronger model generates similar examples"
- Test-Time Self-Improvement (TT-SI): A method that identifies uncertain cases, synthesizes similar examples, and adapts on-the-fly. "Overview of the Test-Time Self-Improvement (TT-SI) framework."
- ToolAlpaca: A synthetic tool-calling dataset across many categories for evaluating tool-use capabilities. "ToolAlpaca~\citep{tang2023toolalpaca} is designed for tool-learning"
- Transductive learning: Adapting directly to the test inputs without learning a general rule for all possible inputs. "Motivated by local and transductive learning"
- Uncertainty estimator: A mechanism to quantify how unsure the model is about its prediction for an input. "identify uncertain samples via a novel uncertainty estimator"
- Uncertainty threshold (τ): A cut-off value deciding whether an input is considered uncertain and triggers adaptation. "A sample is deemed uncertain if "
- xLAM dataset: A state-of-the-art function-calling dataset used for scaling and OOD evaluation. "xLAM function-calling dataset~\citep{zhang2025xlam}"
Collections
Sign up for free to add this paper to one or more collections.