- The paper demonstrates that condensing evaluation datasets via high model output disagreement can reduce evaluation costs by over 99% with only a 1.07 percentage point accuracy loss.
- The DISCO method leverages Predictive Diversity Score and Jensen-Shannon Divergence to simplify sample selection compared to traditional, clustering-based approaches.
- The approach enables frequent and sustainable model evaluations across language and vision benchmarks, promoting faster innovation cycles in AI development.
DISCO: Diversifying Sample Condensation for Efficient Model Evaluation
The paper "DISCO: Diversifying Sample Condensation for Efficient Model Evaluation" presents a novel approach to efficiently evaluate machine learning models by condensing evaluation datasets through sample selection that maximizes model disagreement. The proposed method, DISCO, addresses the escalating cost of model evaluation by significantly reducing the number of samples used while maintaining accurate performance predictions.
Problem and Motivation
The increasing size and complexity of machine learning models have led to prohibitive evaluation costs, often involving thousands of GPU hours per model. Traditional evaluation approaches, which rely on selecting an anchor subset of data and mapping accuracy on this subset to the final test result, are complex and sensitive to design choices. The paper argues that promoting diversity among samples is redundant; instead, the focus should be on selecting samples that maximize diversity in model responses.
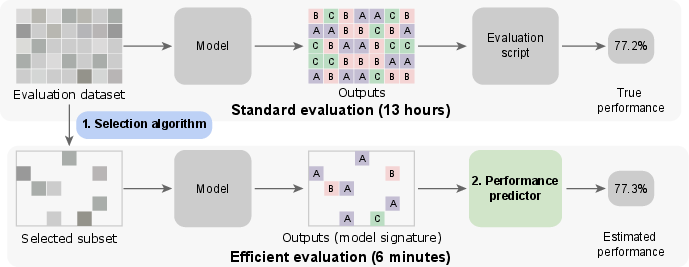
Figure 1: Problem overview: Selecting a smaller evaluation dataset while maintaining close estimated performances.
DISCO: Method Overview
DISCO comprises two main components: dataset selection and performance prediction. The dataset selection process identifies a reduced subset of the evaluation data that is most informative for performance prediction. This is accomplished by selecting samples that yield the greatest disagreement among different models' predictions, a concept supported by information-theoretical insights.
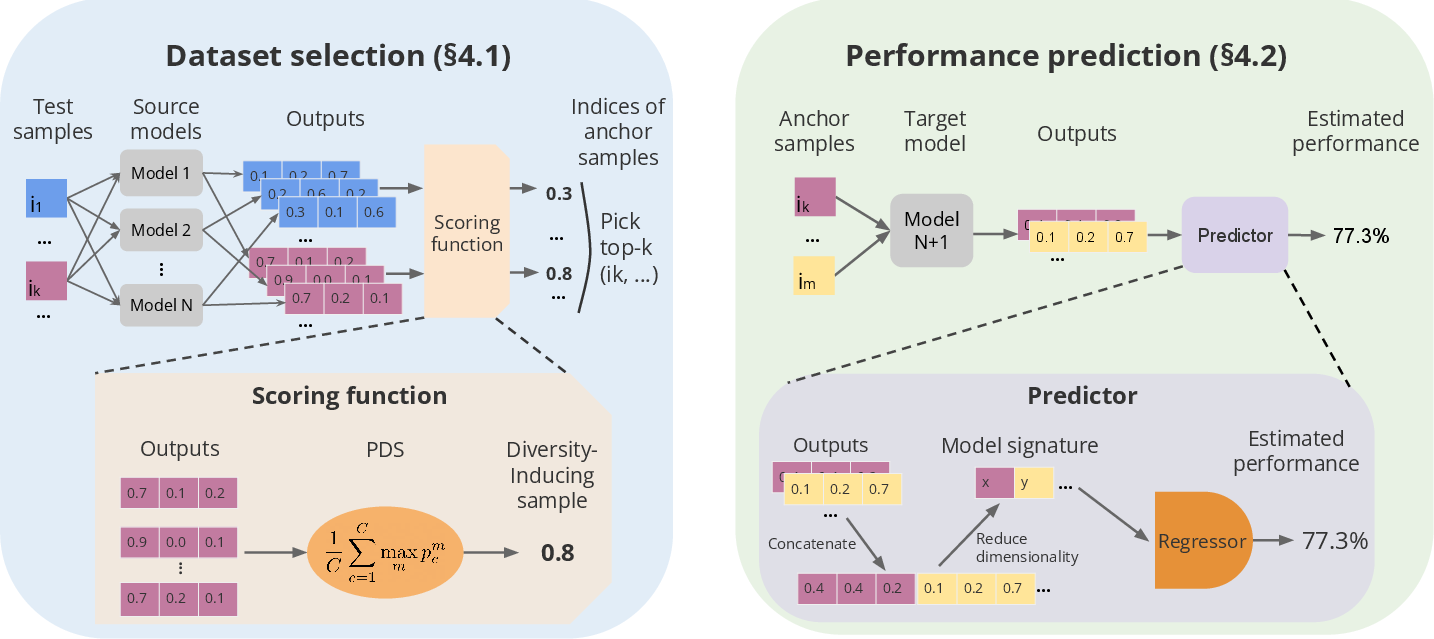
Figure 2: DISCO overview: First, select informative samples, then predict unseen models' performance.
Dataset Selection
The selection process leverages Predictive Diversity Score (PDS) and Jensen-Shannon Divergence (JSD) to measure model disagreement. Samples inducing the highest model output diversity are preferred, simplifying the sampling procedure compared to clustering-based methods.
Performance prediction in DISCO bypasses traditional scalar summaries like accuracy on anchor sets. Instead, it employs model signatures—concatenated model outputs on selected samples—to predict performance using algorithms like kNN or Random Forest. This approach reduces complexity and provides robust performance estimates.
Experiments and Results
The experimental evaluation demonstrates the method's efficacy across language and vision domains. On the MMLU language benchmark, DISCO reduced evaluation costs by 99.3% with only a 1.07 percentage point error in accuracy, outperforming prior methods. Similar results were observed in the vision domain with ImageNet, achieving substantial cost reductions with minimal accuracy loss.
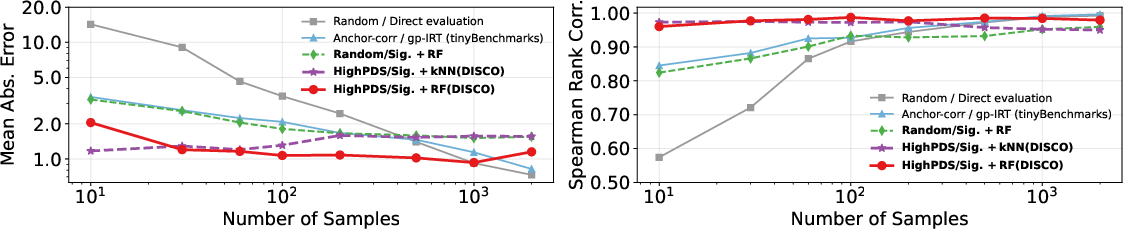
Figure 3: MMLU performance estimation vs. compression rates: Shows correlation between true model ranking and estimated model ranking with MAE differences.
Applications and Implications
The DISCO framework offers significant implications for efficient model evaluation and scalability. By drastically reducing evaluation costs without compromising accuracy, it enables more frequent and inclusive model evaluations, fostering faster innovation cycles and reducing environmental impacts. The method is particularly beneficial in low-resource settings, supporting end-user model checks and frequent training performance assessments.
Conclusion
DISCO presents a practical, scalable solution for model evaluation by optimizing sample selection based on model output diversity. Its application can lead to more sustainable and accessible AI development processes. Future work could focus on enhancing model adaptability to handle distribution shifts and integrating adaptive learning techniques for continuous model updates.
The paper contributes to the methodological advancement of model evaluation in machine learning, with the potential to significantly impact AI research and deployment strategies.