- The paper introduces a scene graph-aware compression method that segments 3D point clouds into semantic patches, achieving up to 98% compression while maintaining structural details.
- It employs transformer-based autoencoders with FiLM conditioning to encode geometric and semantic information, outperforming classical codecs in fidelity.
- Experimental results demonstrate robust generalization across datasets and effective support for downstream robotic tasks with considerably reduced bandwidth.
Scene Graph-Aware Deep Point Cloud Compression: Technical Summary and Implications
Introduction and Motivation
The paper introduces a deep learning-based framework for extreme compression of 3D point clouds, leveraging semantic scene graphs to structure the encoding and decoding process. The motivation stems from the increasing reliance on 3D LiDAR data in multi-agent robotic systems, where bandwidth and storage constraints pose significant challenges for real-time transmission and collaborative processing. Traditional compression methods, such as octrees and clustering, fail to preserve fine-grained geometry and semantic information at high compression ratios. The proposed approach addresses these limitations by integrating semantic and relational context into the compression pipeline.
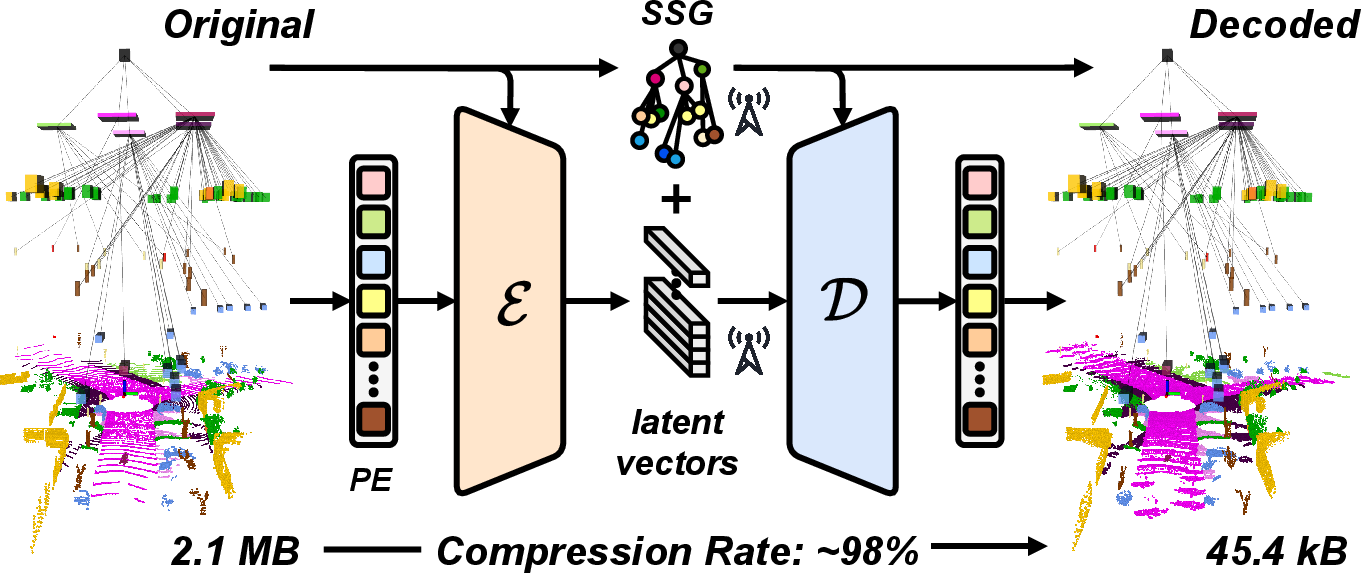
Figure 1: The framework converts a raw point cloud into a semantic scene graph, extracts layer-specific patches, encodes them into latent vectors, and reconstructs the full point cloud from these compact representations, achieving up to 98% compression.
Framework Architecture
Semantic Scene Graph Generation
The framework begins by segmenting the input point cloud into semantic classes using a pre-trained segmentation model. These labeled points are organized into a hierarchical scene graph, with nodes representing terrain, infrastructure, objects, and agents. Each node is associated with geometric attributes (center, extent, orientation) and semantic labels. Edges encode spatial and hierarchical relationships, facilitating downstream tasks such as filtering and map merging.
Patch-Based Autoencoding
Each node (or subdivided terrain patch) is independently processed by a layer-specific autoencoder. The encoder employs a transformer backbone, with point-wise and positional embeddings modulated by Feature-wise Linear Modulation (FiLM) conditioned on semantic class embeddings.
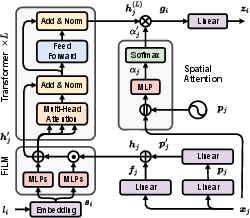
Figure 2: The semantic-aware encoder processes each patch with its semantic class, applies positional encoding, and uses FiLM to adapt features based on semantic context, followed by transformer blocks and spatial attention pooling.
The decoder reconstructs patches from latent vectors, conditioned on node geometry. It first generates coarse points within the bounding box, applies learned offsets, and then upsamples via a folding operation using a fixed 2D grid. A confidence mask is predicted to prune invalid points, accommodating the variable density of LiDAR data.
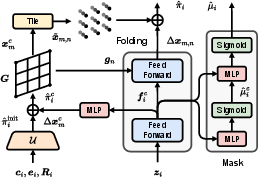
Figure 3: The decoder uses the latent vector and node attributes to generate coarse points, applies learned offsets, and upscales via folding, producing dense reconstructions with a confidence mask.
Loss Functions
Training is supervised by a multi-component loss: Chamfer Distance for geometric fidelity, voxel-based density regularization for spatial uniformity, and binary cross-entropy for confidence mask prediction. Auxiliary losses on coarse reconstructions and masks are decayed during training to focus optimization on fine-level fidelity.
Experimental Results
On SemanticKITTI, the framework achieves up to 98% compression (reducing bits-per-point from 60–70 to ~1.8) while outperforming classical codecs (Draco, MPEG) and recent learned methods (RecNet, OctAttention) in geometric and semantic fidelity at low bitrates. The method is competitive with RENO, which achieves the best overall performance but does not encode semantic labels.
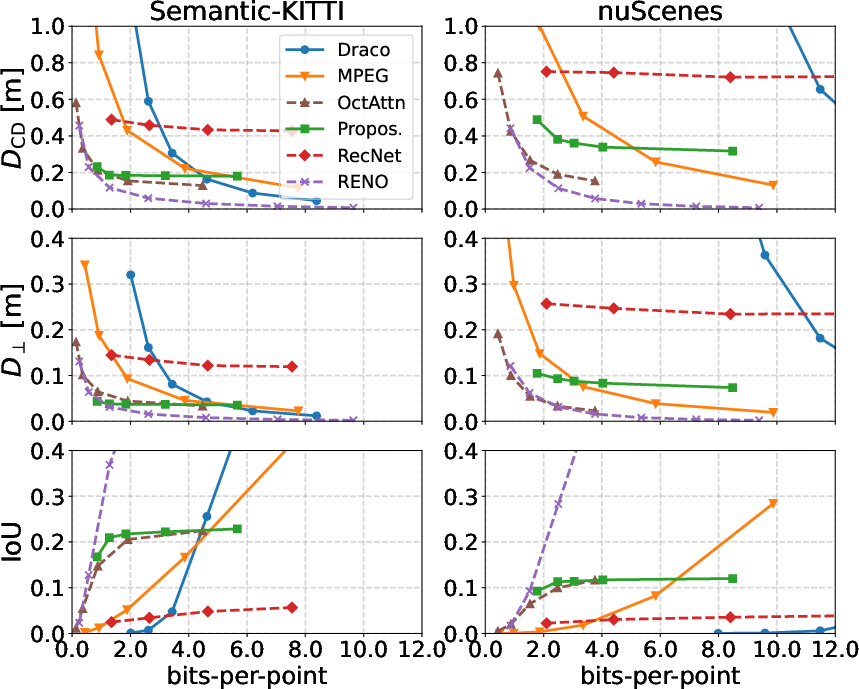
Figure 4: Compression results show superior geometric and semantic fidelity at low bitrates compared to baselines, with robust cross-dataset generalization to nuScenes.
Qualitative analysis demonstrates that the proposed method preserves fine structures (cars, poles, signage) and scene completeness even under extreme compression, whereas baselines suffer from sparsity and artifacts.
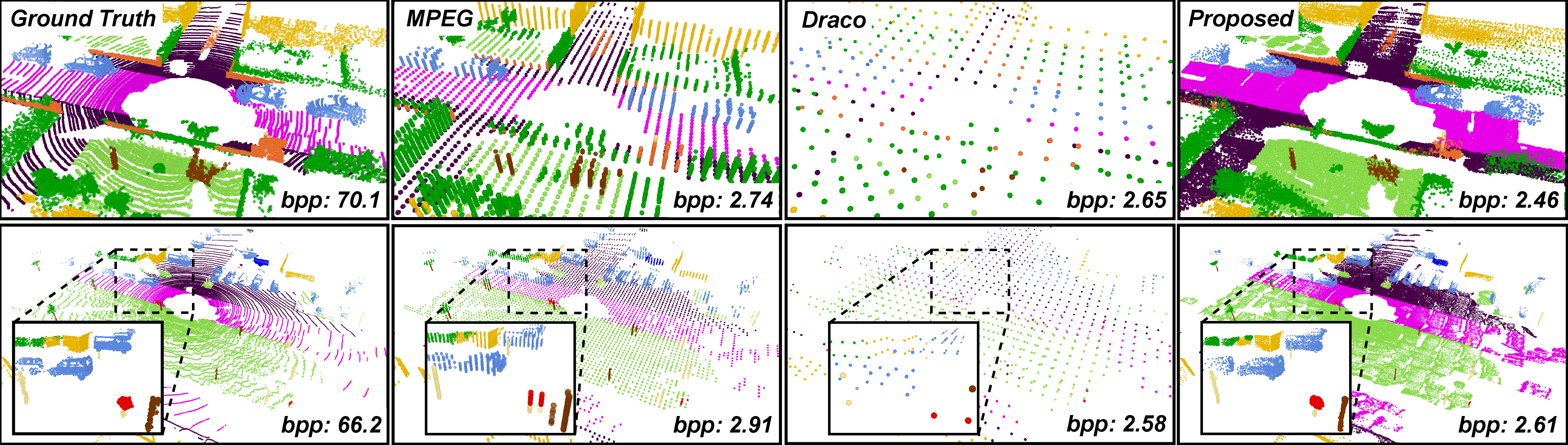
Figure 5: Qualitative comparisons highlight superior reconstruction of fine-grained structures at 98% compression, with baseline methods losing geometric detail.
Generalization
Models trained on SemanticKITTI generalize well to nuScenes without fine-tuning, maintaining strong performance despite differences in sensor configuration and scene layout. This robustness is attributed to local geometric encoding within semantic layers, rather than global scene memorization.
Ablation Studies
Ablation of FiLM and positional encoding modules reveals their complementary roles: FiLM enhances semantic-aware reconstruction, while positional encoding improves geometric precision. Disabling both leads to significant degradation in Chamfer Distance and IoU. Using predicted semantic labels (from RangeNet++, KP-FCNN, RandLA-Net) shows that segmentation error type, not just mIoU, affects reconstruction quality, with cluster-level misclassifications being more detrimental than point-wise errors.
Downstream Robotic Tasks
The compressed representation supports multi-agent pose graph optimization and map merging with trajectory and alignment accuracy comparable to raw scans, but at 98% lower bandwidth. Classical codecs fail in these tasks due to poor geometric fidelity. Semantic pruning via the scene graph enables effective removal of dynamic objects, improving map clarity.
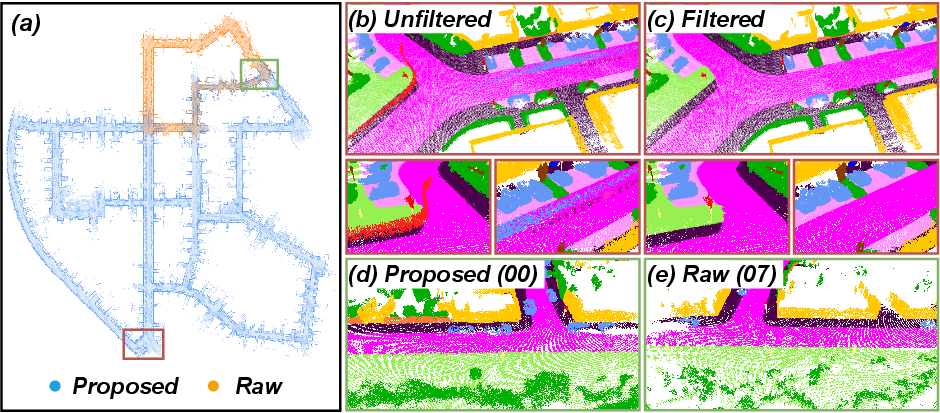
Figure 6: Merged maps and zoomed views demonstrate successful alignment and semantic filtering using compressed scans, with preserved structure in overlapping regions.
Implementation Considerations
- Computational Requirements: Encoding/decoding is efficient (0.17s/0.08s per scan on RTX 4090), but semantic scene graph generation is a bottleneck (~0.25s). Distributed training on A100 GPUs is used for model optimization.
- Resource Constraints: The method is suitable for edge/cloud deployment, but further acceleration (model pruning, quantization, hardware optimization) is needed for embedded platforms.
- Scalability: Compression rate is controlled by latent vector size; network capacity is fixed, limiting performance at very high bitrates.
- Limitations: Dependence on fixed semantic vocabulary and segmentation accuracy; real-time graph generation remains challenging.
Theoretical and Practical Implications
The integration of semantic scene graphs into point cloud compression represents a shift toward task-driven, structure-aware representations. By encoding relational and semantic context, the method supports not only efficient transmission but also downstream robotic tasks (localization, mapping, filtering) without requiring full-resolution data. This approach aligns with trends in multi-agent SLAM and collaborative perception, where compact, informative representations are critical for scalability and robustness under communication constraints.
The framework demonstrates that extreme compression is feasible without sacrificing geometric or semantic fidelity, provided that relational structure is preserved. The use of transformer-based encoding and FiLM conditioning enables generalization across datasets and environments, addressing a key limitation of prior learned codecs.
Future Directions
- Real-Time Graph Generation: Development of approximate or hardware-accelerated scene graph construction to enable deployment in latency-sensitive applications.
- Open-Vocabulary Segmentation: Integration of dynamic or open-set semantic models to increase flexibility and adaptability.
- Model Compression: Application of pruning, quantization, and distillation for resource-constrained platforms.
- Task-Specific Compression: Exploration of compression strategies tailored to specific downstream tasks (e.g., navigation, object detection).
- Federated and Decentralized Learning: Extension to collaborative training and inference across distributed robotic agents.
Conclusion
The proposed scene graph-aware deep point cloud compression framework achieves state-of-the-art performance under extreme bandwidth constraints, preserving both geometric and semantic structure. Its patch-wise, relational encoding supports efficient transmission and robust downstream robotic tasks, with demonstrated generalization across datasets. The approach sets a new standard for semantic-aware compression in multi-agent systems and opens avenues for further research in structure-driven representation learning and collaborative robotics.