- The paper introduces a tractable Bayesian repulsive mixture model leveraging projection DPP priors to obtain closed-form posterior characterizations and efficient inference.
- The methodology reduces redundant clusters by enforcing global repulsiveness, which enhances interpretability and parsimony in applications like ERP waveform clustering.
- Empirical results and theoretical guarantees demonstrate improved mixing properties, posterior consistency, and convergence over traditional Dirichlet process mixtures.
Repulsive Mixture Models via Projection Determinantal Point Processes
Introduction
This work introduces a tractable Bayesian repulsive mixture model leveraging the Projection Determinantal Point Process (DPP) prior for mixture component locations. Standard Bayesian mixture models, such as Dirichlet Process Mixtures (DPM), frequently result in redundant or non-interpretable clusters due to a lack of repulsion among component atoms. Repulsive mixtures, particularly those employing DPP-based priors, aim to mitigate these interpretability concerns but have historically been accompanied by computational and inferential challenges. This paper addresses these issues by capitalizing on the unique analytical and computational advantages of projection DPPs, enabling direct closed-form posterior characterizations and efficient inference.
Projection DPP-Based Mixture Models
Projection DPPs
Projection DPPs are a subset of DPPs whose kernels admit only eigenvalues in {0,1}. For component locations Φ={ϕ1,…,ϕm} on a compact set, the joint intensity is given by
ρ(ϕ1,…,ϕk)=det{K(ϕi,ϕj)}i,j=1k
for all 1≤k≤m and pairwise distinct points. Crucially, projection DPPs generate a fixed number of atoms (∣Φ∣=m), and, among DPPs of given cardinality, maximize global repulsiveness relative to alternatives such as L-ensemble and Gaussian DPPs. Additionally, recent algorithmic advances allow exact, rejection-based sampling from projection DPPs without recourse to spectral analysis, facilitating practical MCMC implementation.
The mixture model considered consists of weighted kernel densities, with the mixing measure P(⋅)=G(⋅)/G(X), where G=∑h=1mshδϕh, {ϕ1,…,ϕm}∼pDPP(K) (with a stationary, homogeneous kernel such as a Fourier-based translation-invariant one), and sh∼π, with π usually taken as gamma (or other ID distribution).
Given data Y1,…,Yn∼∫f(⋅∣θ)P(dθ), with P as above, the central modeling innovation is the imposition of a projection DPP prior on the component locations ϕ1,…,ϕm. The resulting model is a finite mixture with built-in global repulsiveness among component atoms.
Posterior Characterization and Efficient Inference
Analytical tractability is achieved through the reduced Palm calculus for DPPs. Given a realization of unique latent component allocations θ∗={θ1∗,…,θk∗}, the conditional process for the remaining m−k atoms is again a projection DPP on the complement of existing atoms, but with an inhomogeneous kernel (the reduced Palm kernel Kθ∗!).
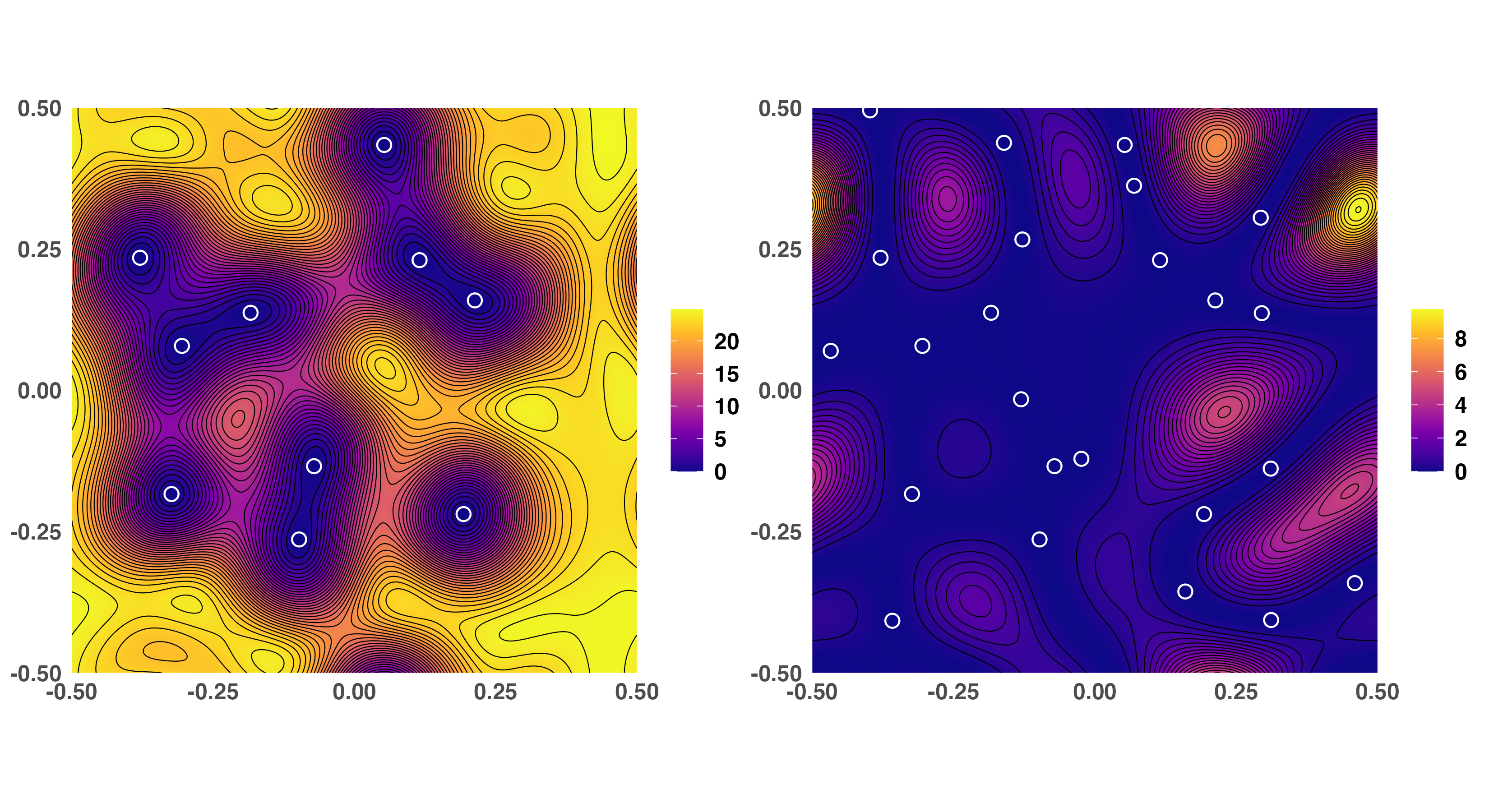
Figure 1: Intensity Kθ∗!(x,x) for varying numbers of conditioned atoms, demonstrating how potential component locations avoid regions near previously assigned ones, illustrating the repulsive property of the Palm-reduced projection DPP prior.
Explicit closed-form expressions are derived for:
- Conditional posterior of the unnormalized mixing measure G given observed latent allocations.
- Predictive distribution for the next potential component assignment.
- Conditional update rules for MCMC samplers (conditional and marginal/collapsed).
Two primary inference algorithms are proposed:
- Conditional Algorithm: Updates allocation and all atom-specific parameters, leveraging exact sampling of non-active atoms via the reduced Palm projection DPP.
- Marginal Algorithm (“Neal type 8”): Collapses mixing measure parameters, updating cluster assignments and unique values via full conditionals derived from the predictive characterization, avoiding costly normalizing constant calculations through auxiliary variables.
Both algorithms efficiently exploit the tractable structure of projection DPPs, yielding substantial improvements in mixing properties (i.e., effective sample size per iteration and convergence speed) over split-merge and birth-death schemes previously required for DPP-based mixtures.
Theoretical Guarantees
Strong large-sample theoretical properties are established. The model exhibits:
- Posterior consistency: The posterior contracts at the optimal rate (O(n−1/2log1/2n) in L1 norm) toward the true density if the data-generating process is a finite Gaussian mixture.
- Elimination of redundant components: Extra (unused) mixture components are emptied out in the posterior as the sample size increases, provided the prior on weights is sufficiently diffuse.
- Convergence in the mixing measure: Under standard identifiability constraints and regularity assumptions, the posterior contracts in the 1-Wasserstein distance to the true mixing measure.
This suite of results rigorously quantifies the absence of any penalty (in rate or contraction) for assuming a repulsive structure, relative to conventional non-repulsive Bayesian mixtures.
Simulation Studies
Synthetic Data: One-Dimensional and Multivariate Mixtures
Numerical experiments compare projection DPP mixtures against DPM, Gaussian DPP mixture, and L-ensemble DPP mixture competitors. All models fit the density well, but the projection DPP model yields substantially fewer clusters, reflecting stronger atom-level repulsion and more interpretable (parsimonious) clustering.
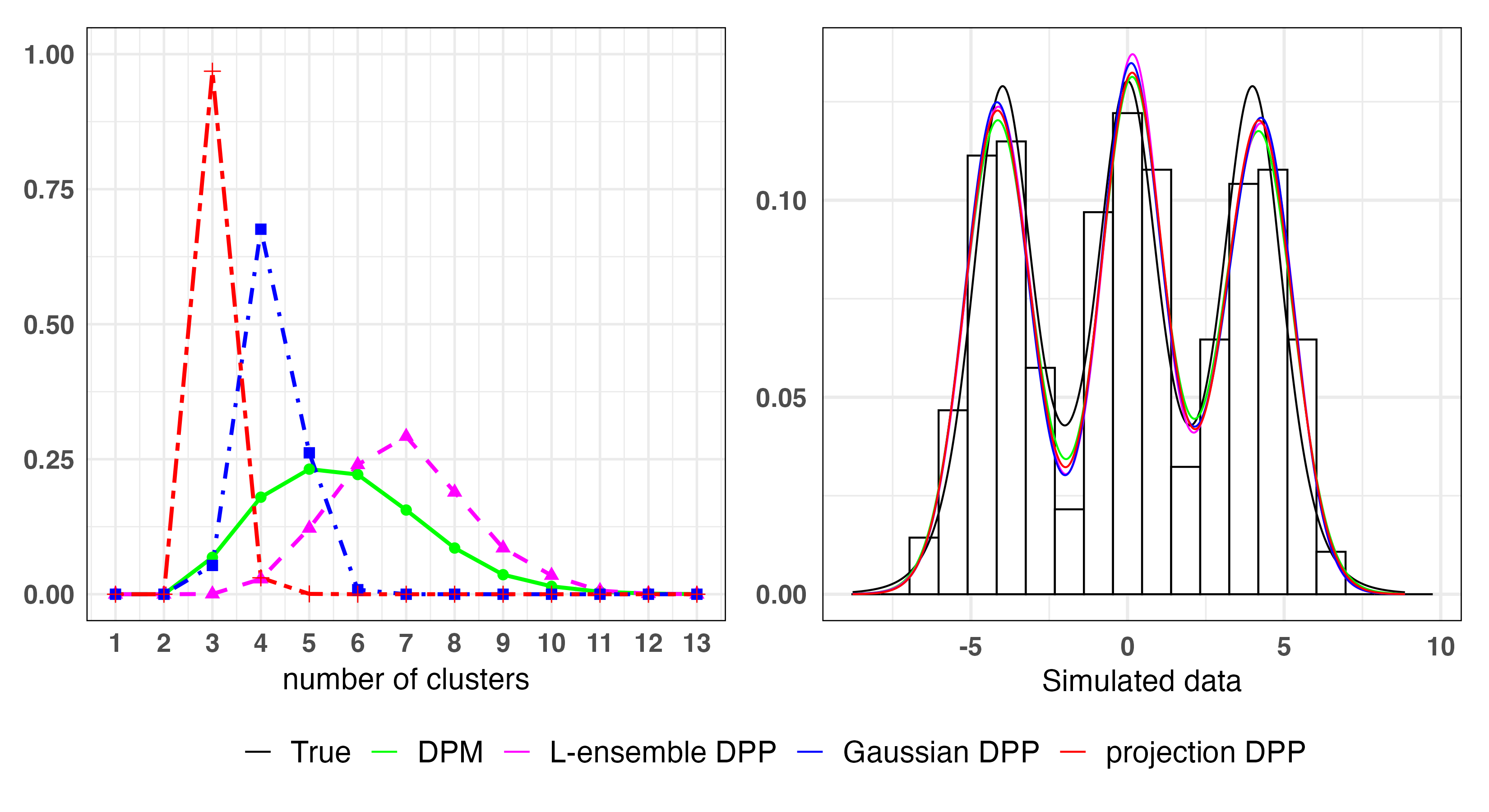
Figure 2: Posterior number of clusters and density estimates for various models, showcasing the superiority of projection DPP in parsimony without sacrificing density fit.
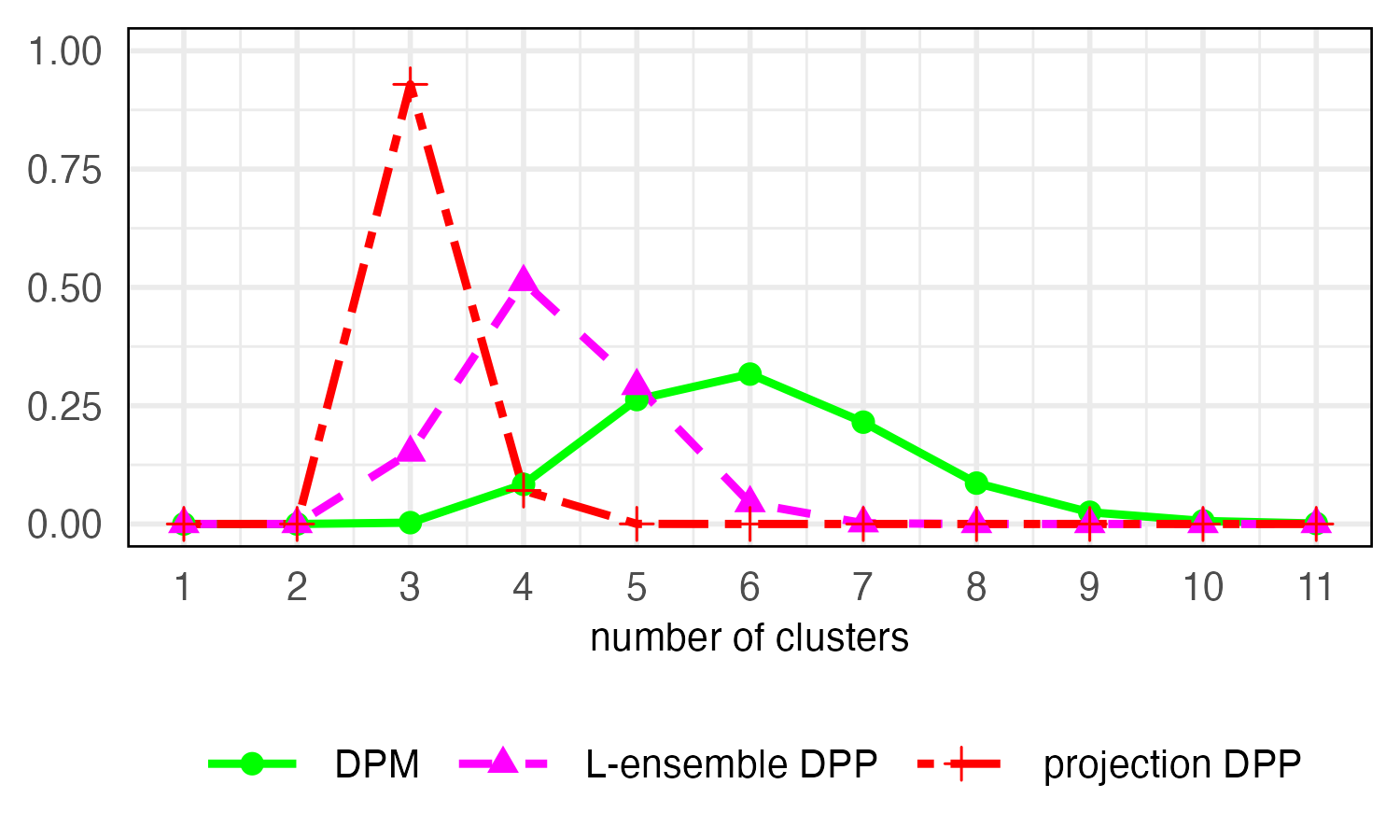
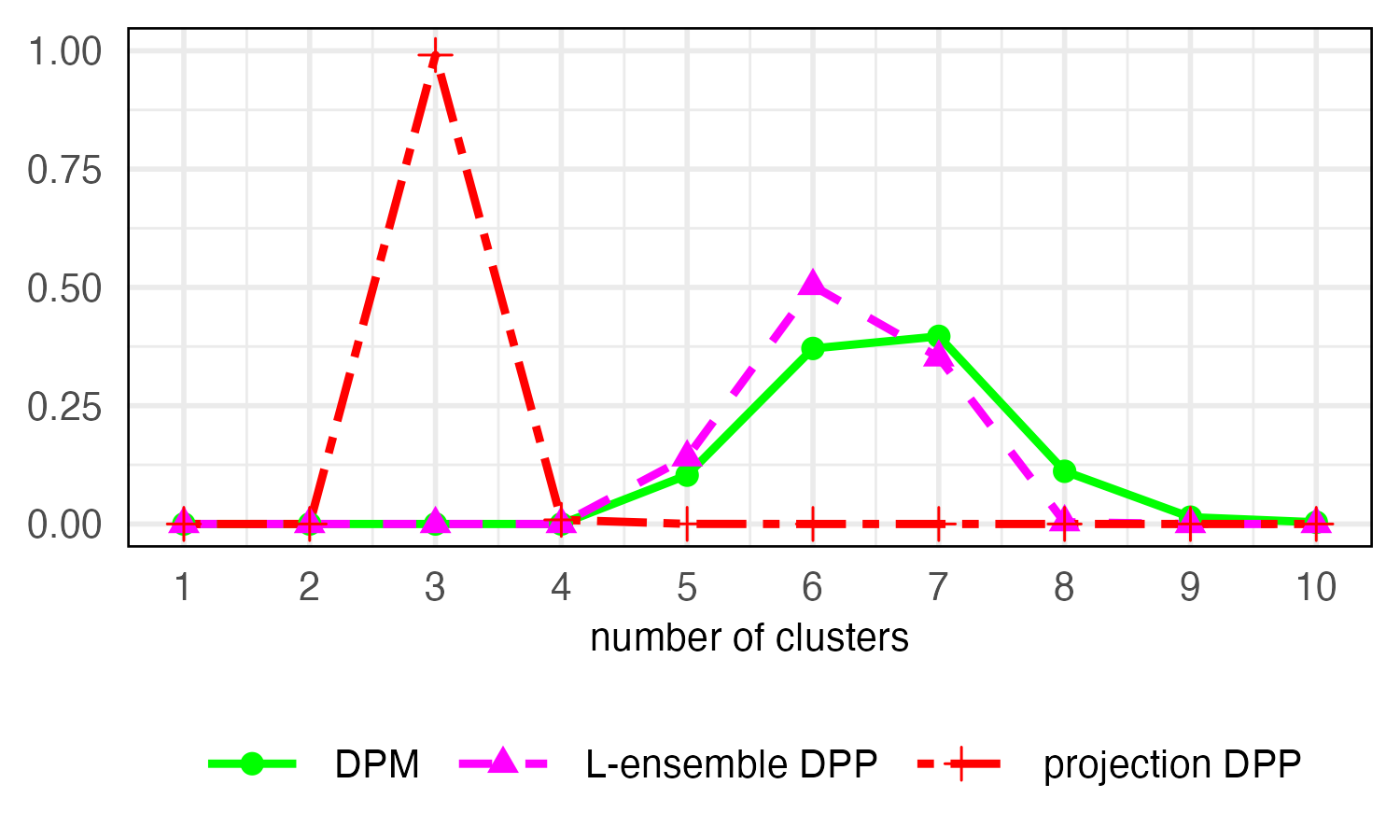
Figure 3: Multivariate simulation, d=2, showing posterior distribution for the number of clusters. The projection DPP model recovers the true number, unlike alternative methods.
Marginal samplers based on the proposed characterization routinely deliver several-fold improvements in effective sample size per iteration over conditional or reversible-jump approaches.
Application: Clustering ERP Functional Data
The model is applied to Event-Related Potential (ERP) waveforms from cognitive neuroscience. After functional PCA, the top principal component scores (covering 87% of variation) are clustered.
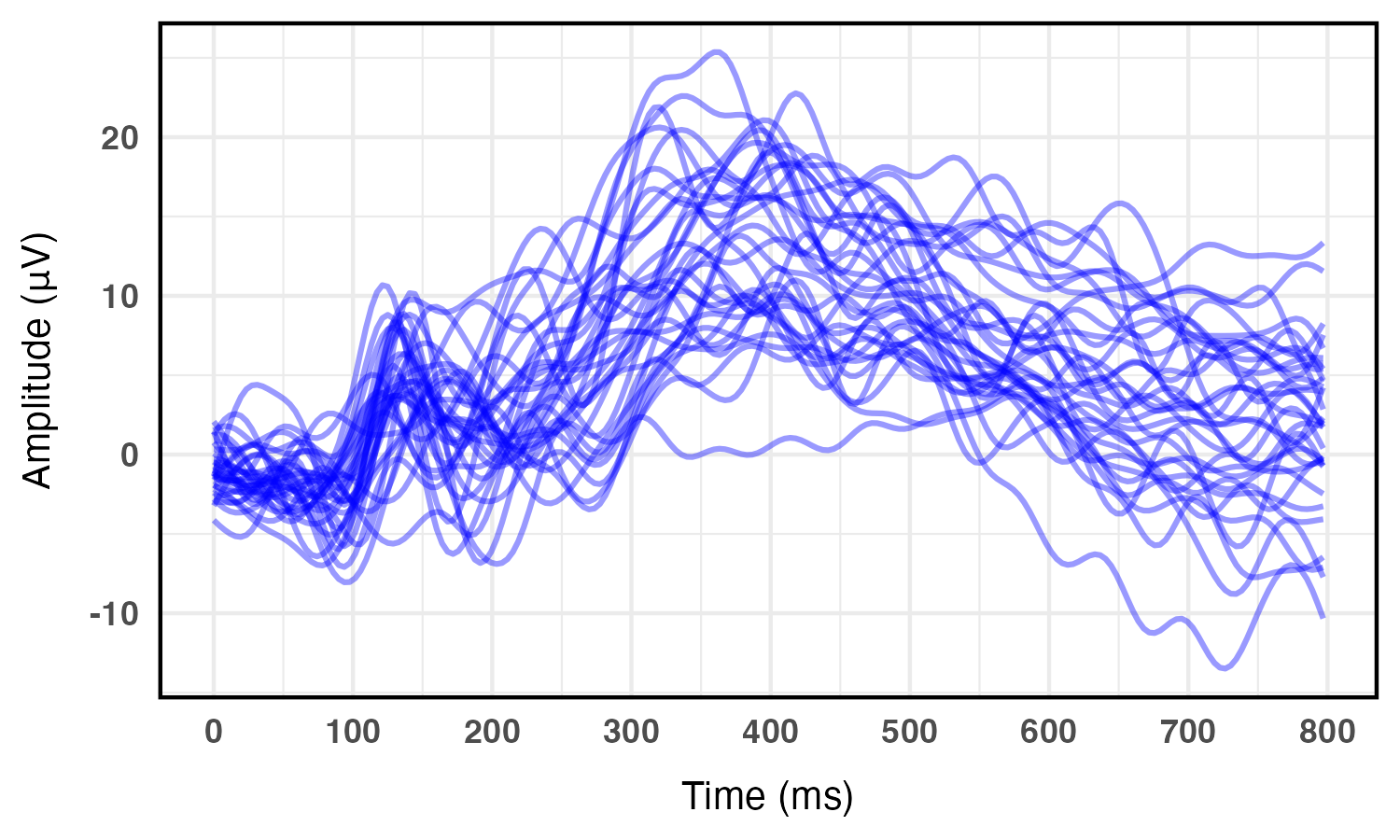
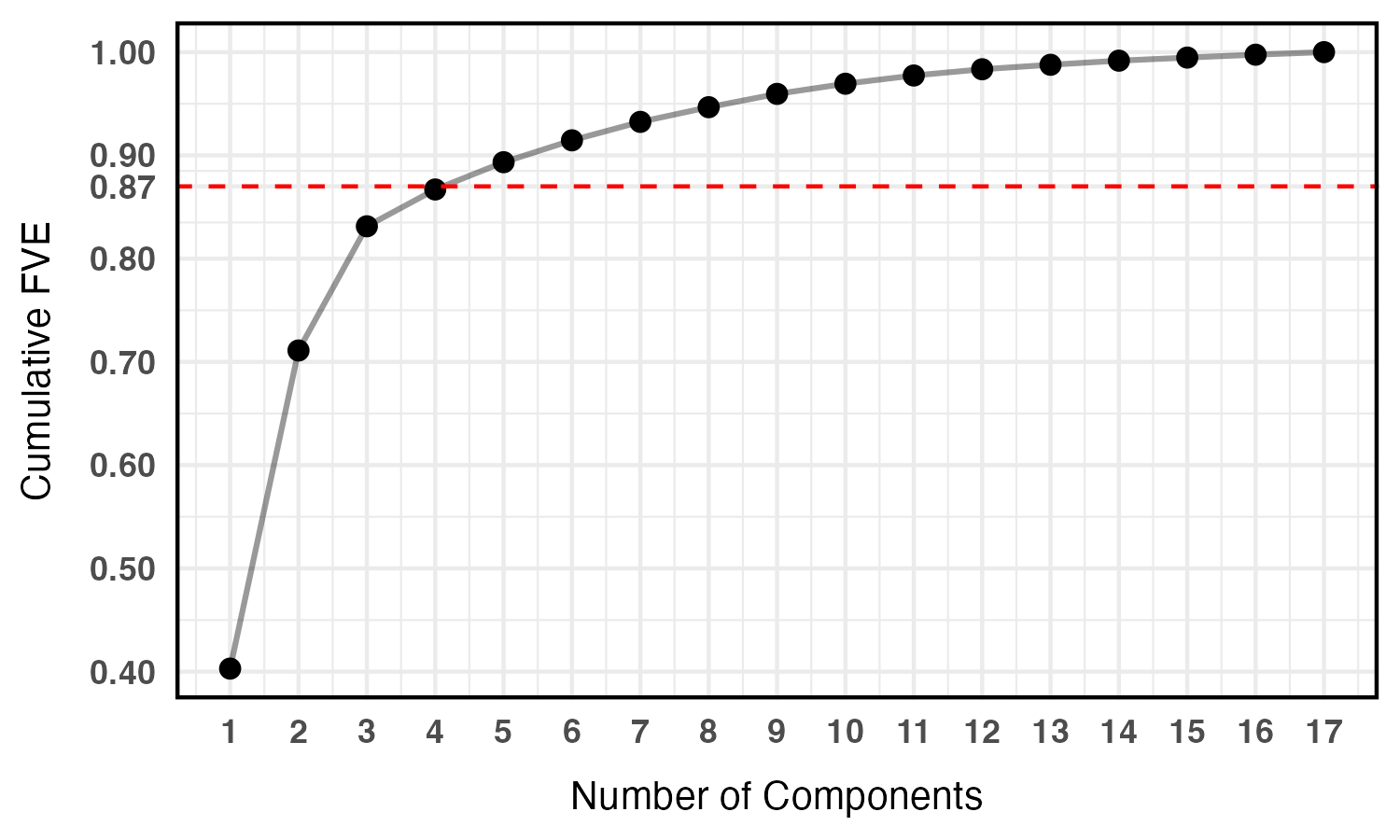
Figure 4: ERP waveforms from 34 subjects, showing heterogeneity in temporally resolved brain activity signals.
The projection DPP mixture discovers four distinct clusters with interpretable neurocognitive properties: clusters differentiate by amplitude and latency of P3 peaks, corresponding to canonical neurophysiological sub-processes.
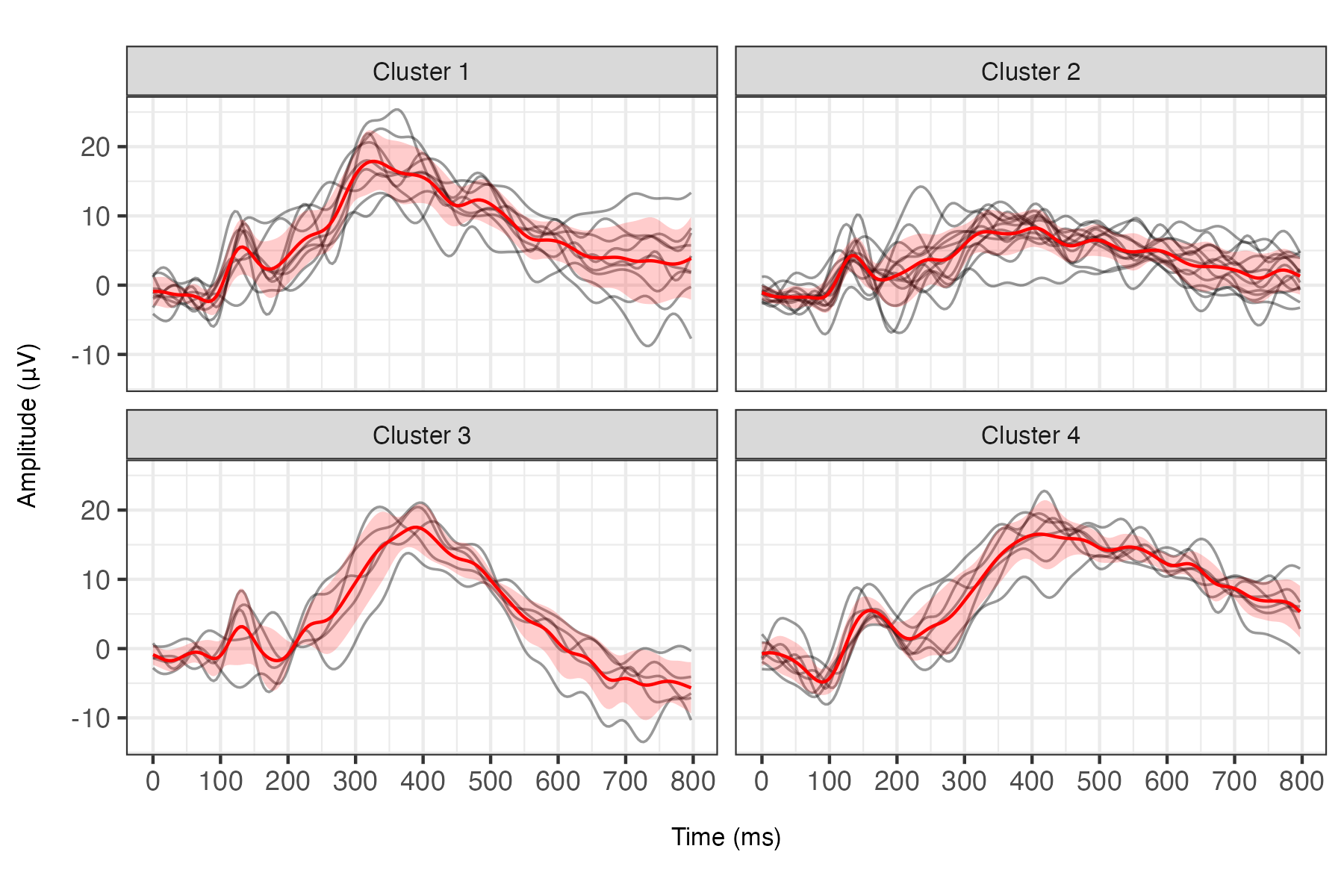
Figure 5: Clustering of 34 ERPs by projection DPP mixture, with cluster-average and within-cluster variability highlighting interpretable functional differences. Clusters are well-separated and no singletons are identified.
For comparison, a DPM fit partitions subjects into many singleton clusters and provides poor interpretability.
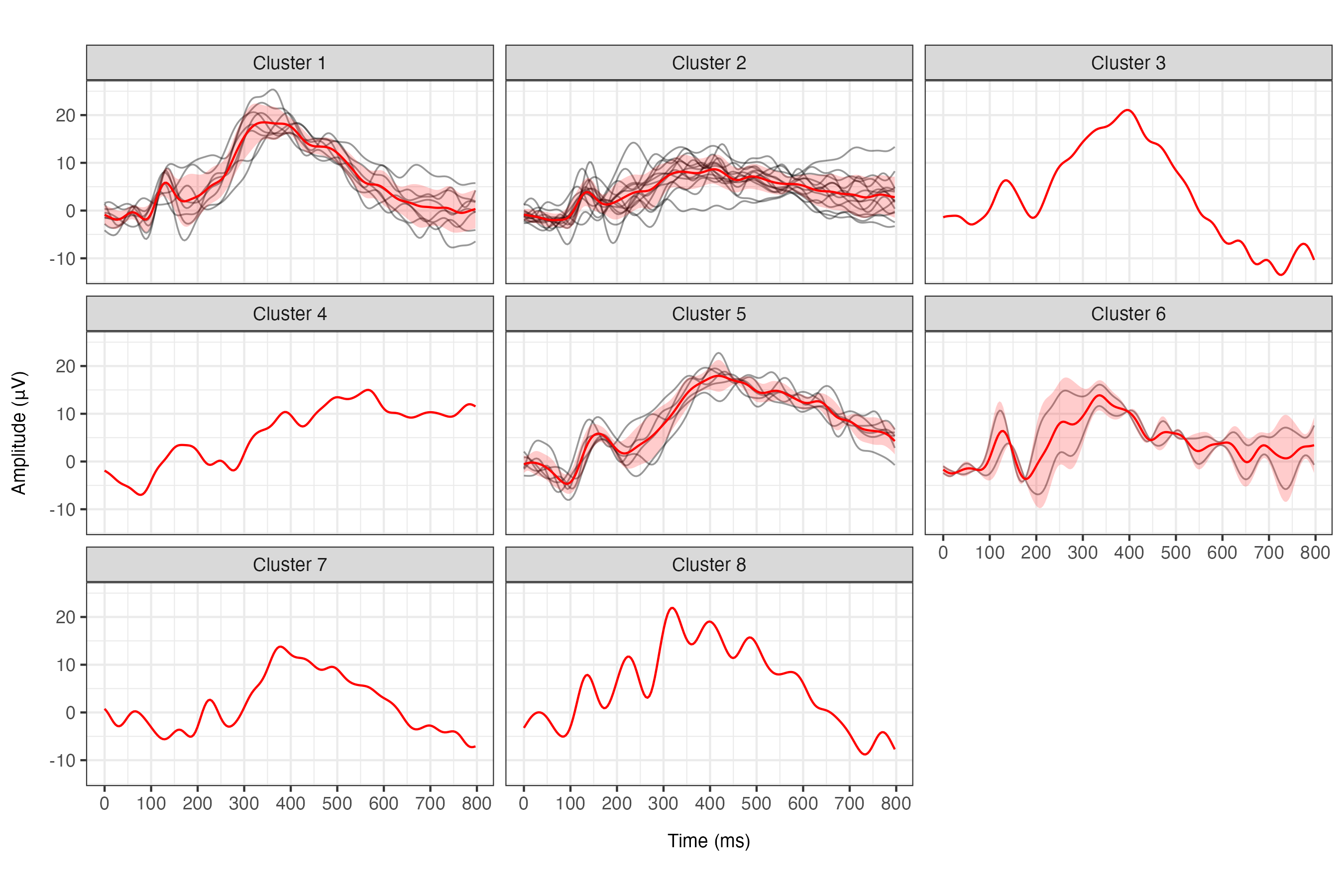
Figure 6: DPM-based clustering overfits, yielding many small clusters and singletons, a direct result of lack of repulsion among atoms.
Implications and Extensions
Projection DPP priors render repulsive mixture models both computationally feasible and theoretically robust. Practically, this yields clustering solutions with minimal redundancy, balancing flexibility and interpretability—a desideratum in functional and high-dimensional applications (e.g., neuroscience, genomics).
The main limitation is the need to fix the number m of atoms (upper bound on clusters). However, the theory and simulation show extra components are efficiently emptied out in the posterior. Extending this work to allow random (unbounded) numbers of atoms via mixtures of projection DPPs (i.e., random cardinality DPP models) is a promising direction. Furthermore, the framework can be naturally combined with models for covariate-dependent mixtures or functional point processes.
Conclusion
This paper provides a foundational advance for repulsive Bayesian clustering, integrating the strongest repulsive DPP prior with closed-form inference and efficient algorithms. The resulting models achieve the dual objectives of interpretability and statistical optimality and are of broad interest for both theoretical and applied researchers in Bayesian nonparametrics and computational statistics.
References
See the references in the original (2510.08838).