- The paper demonstrates that FLRC significantly reduces memory and compute demands using Fisher-based layer-wise rank allocation and progressive decoding.
- It achieves up to a 17.35% increase in ROUGE-L scores and reduces rank allocation search time by up to 49 times compared to traditional methods.
- FLRC paves the way for efficient LLM deployment on resource-constrained hardware, expanding practical applications for advanced language models.
FLRC: Fine-grained Low-Rank Compressor for Efficient LLM Inference
Introduction
The paper "FLRC: Fine-grained Low-Rank Compressor for Efficient LLM Inference" introduces an innovative method for the compression of LLMs to enhance their deployability on resource-constrained hardware. The proposed approach, Fine-grained Low-Rank Compressor (FLRC), addresses the limitations of traditional low-rank compression techniques by optimizing layer-wise rank allocation and implementing progressive low-rank decoding. This method significantly reduces memory and computational demands without compromising on the quality of text generation, thereby improving the efficiency of LLM inference.
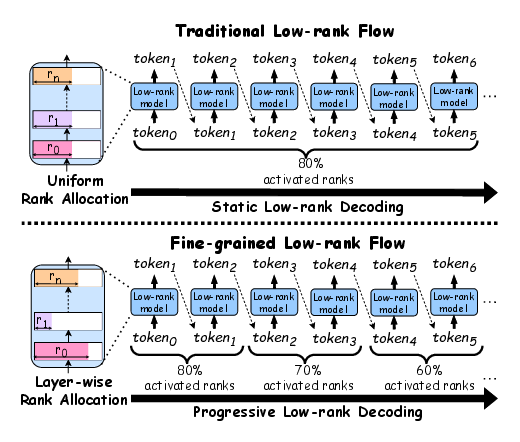
Figure 1: The differences between FLRC and traditional low-rank compression. As shown on the left side of the figure, we can determine the optimal number of ranks to preserve for each layer. On the right side, during the decoding stage, our approach gradually reduces the model's overall activated rank as more tokens are generated, unlike previous static methods, thereby decreasing the parameter usage and computational requirements while maintaining the quality of the generated output.
Methodology
The FLRC framework encompasses two core innovations:
- Fisher-based Layer-wise Rank Allocation: This algorithm calculates an optimal rank allocation for each layer's projections in LLMs. By leveraging gradients and weight magnitudes, it assigns importance scores to projections, thereby guiding the rank allocation to preserve critical information dynamically. This method efficiently distributes the compression budget across the model, ensuring superior performance compared to uniform compression ratios.
- Progressive Low-rank Decoding: This dynamic compression strategy reduces the model's active ranks progressively during the token generation process. By adjusting the compression rate dynamically, it maintains high text generation quality while significantly reducing computational and memory requirements. This approach capitalizes on the inherent structure of singular values in matrices, facilitating efficient implementation in real-time inference scenarios.
Experimental Evaluation
The proposed method was evaluated on several benchmarks and demonstrated substantial improvements over existing state-of-the-art low-rank compression techniques. For instance, FLRC achieved up to a 17.35% increase in ROUGE-L scores on summarization tasks compared to traditional methods, underscoring its enhanced capability for text generation tasks.
The experiments also showed that FLRC reduces the rank allocation search time by up to 49 times, showcasing its efficiency in deploying compressed models.
Implications and Future Directions
The FLRC framework presents significant implications for the deployment of LLMs in environments where computational resources are limited, such as mobile devices and edge servers. By reducing the computational overhead and memory footprint, this method paves the way for more widespread use of LLMs in various applications.
Future research could focus on further optimizing the dynamic scheduling of ranks to minimize overhead and enhance efficiency. Additionally, exploring the integration of this method with other compression techniques like quantization could offer synergistic benefits, leading to even more robust and effective LLM implementations.
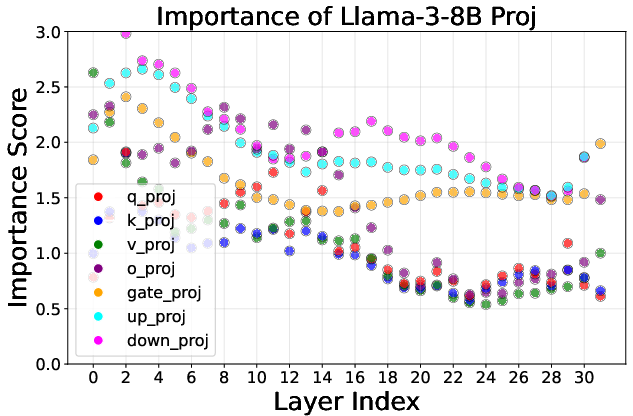
Figure 2: The importance score of various projections in Llama-3-8B across different layer indices. Each point represents a projection's score; higher scores (e.g., "down_proj") indicate that less compression should be applied, while lower scores allow for more aggressive compression.
Conclusion
FLRC is a significant advancement in the field of LLM compression, offering a nuanced approach to optimizing inference efficiency across diverse scenarios. By tailoring rank allocation and adjusting ranks dynamically, FLRC ensures that LLMs maintain high performance levels while operating under reduced resource constraints. This method sets a new benchmark for efficient LLM inference and opens avenues for further research into optimized model compression techniques.