- The paper presents a hybrid framework that unifies relational graph queries and vector search to effectively process multimodal data.
- It employs modality-aware indexing and adaptive index management to optimize memory usage and real-time query performance.
- Empirical results demonstrate superior query latency, recall, and scalability compared to leading open-source systems.
The Hybrid Multimodal Graph Index (HMGI): A Comprehensive Framework for Integrated Relational and Vector Search
The "Hybrid Multimodal Graph Index (HMGI)" paper presents a cutting-edge architectural framework designed to integrate relational and vector search capabilities within a single cohesive system. This paper addresses the limitations of existing independent vector and graph databases by introducing an innovative hybrid approach capable of efficiently handling multimodal data through unified querying.
Introduction to HMGI
HMGI combines the strengths of graph databases, like Neo4j, which excel at complex relational queries, with the semantic power of vector databases optimized for Approximate Nearest Neighbor Search (ANNS). This integration is crucial for processing multimodal datasets, where both the semantic content and relational context of the data need to be analyzed concurrently. The framework is particularly relevant for applications in recommendation engines, drug discovery, and Retrieval-Augmented Generation (RAG) systems.
Core Innovations
The HMGI framework offers several key innovations:
- Hybrid Query Processing: By integrating graph-based pathfinding with ANNS, HMGI enables queries that utilize relational structures and semantic similarities simultaneously. This allows for more expressive queries on multimodal data.
- Modality-Aware Indexing: The framework partitions multimodal embeddings based on their source modality (e.g., text vs. image), optimizing the storage and query processes by focusing on relevant subsets of the data.
- Adaptive Index Management: Drawing inspiration from systems like TigerVector, HMGI includes adaptive mechanisms for managing dynamic data ingestion, ensuring that updates to the data are handled with minimal overhead and maintaining high performance in real-time applications.
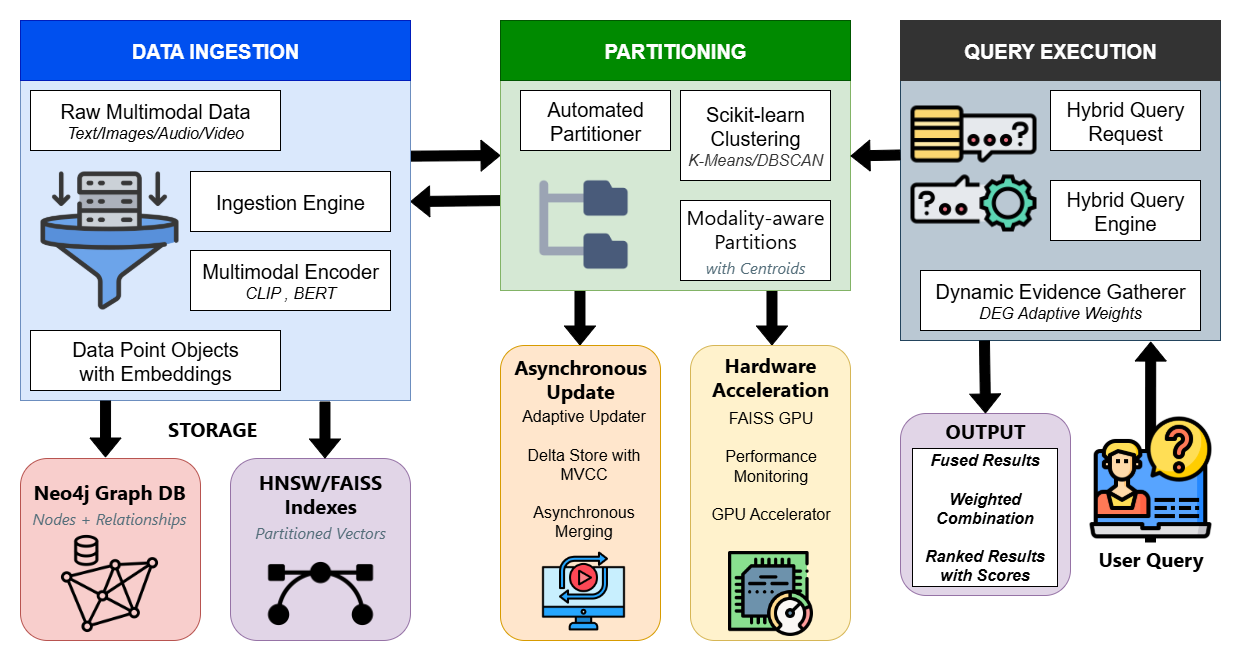
Figure 1: HMGI Framework Architecture
Methodology
The HMGI architecture is modular, allowing seamless integration of various components. It utilizes microservices for ingestion, indexing, storage, and querying, with gRPC endpoints and Kafka for communication. This design enables HMGI to handle high-dimensional, billion-scale datasets efficiently.
Data Ingestion and Processing
Multimodal data from various sources are ingested through a specialized pipeline. Embeddings are generated using different models suited for each data type, such as SentenceTransformer for text and CLIP for images. K-means clustering is employed to partition embeddings, reducing search spaces significantly during queries.
Storage and Indexing
HMGI employs Neo4j's vector indexing capabilities to store multimodal embeddings as node properties. This setup supports high-performance ANNS with parameters fine-tuned for specific modalities, leveraging techniques like flash quantization to optimize memory usage.
Query Processing
Queries within HMGI are processed through an extended Cypher syntax that incorporates vector operations. The system evaluates both semantic similarities and relational connections, allowing complex inquiries that filter results based on both criteria. Techniques such as DEG-inspired dynamic weighting enhance query flexibility and accuracy.
Empirical tests demonstrate that HMGI consistently outperforms leading open-source competitors, such as Milvus and Qdrant, in query latency and throughput, particularly in relational-heavy contexts. Its memory usage and update efficiency showcase its scalability and suitability for real-time applications.
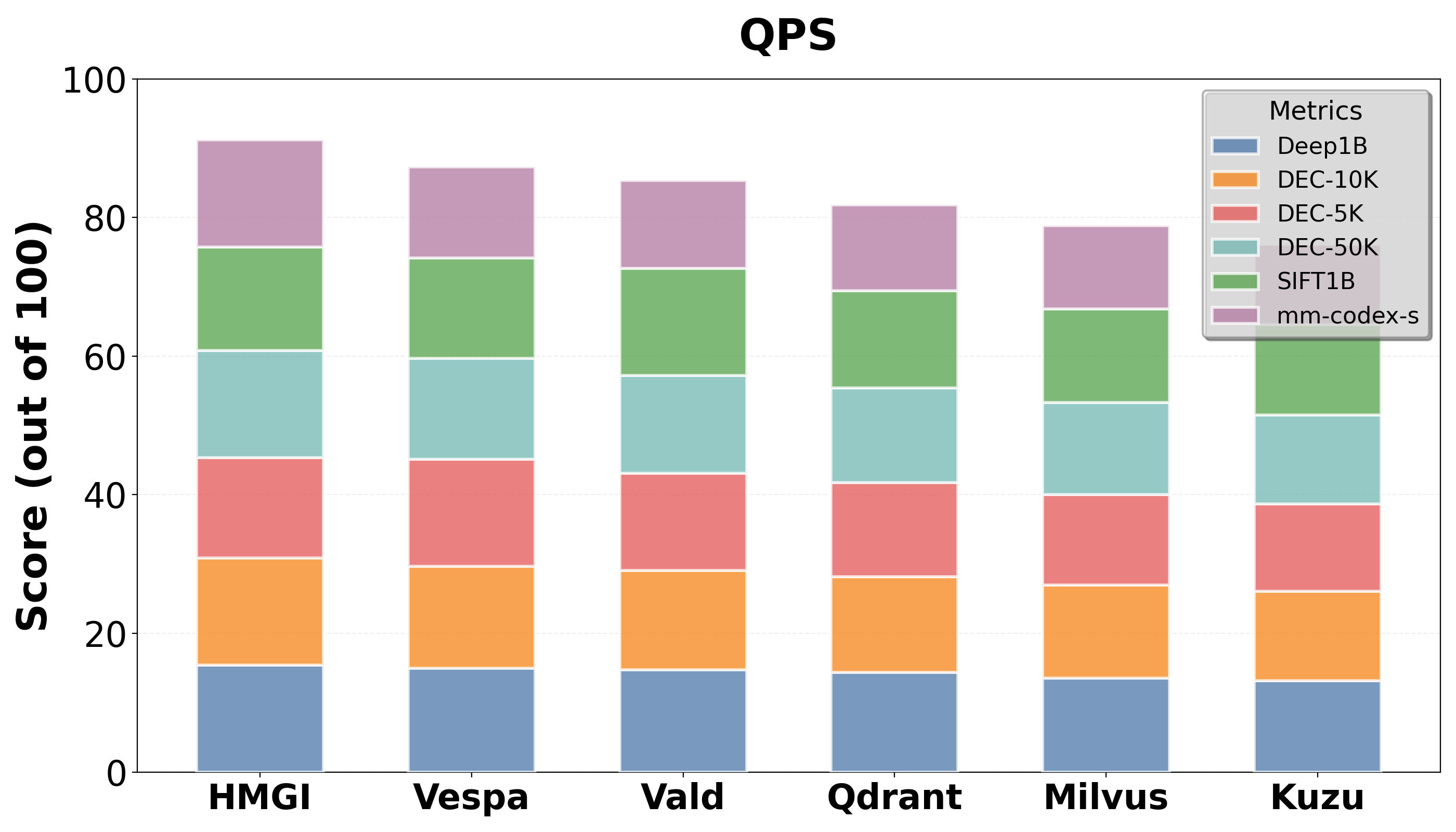
Figure 2: QPS of HMGI vs Leading Open Source Competitors
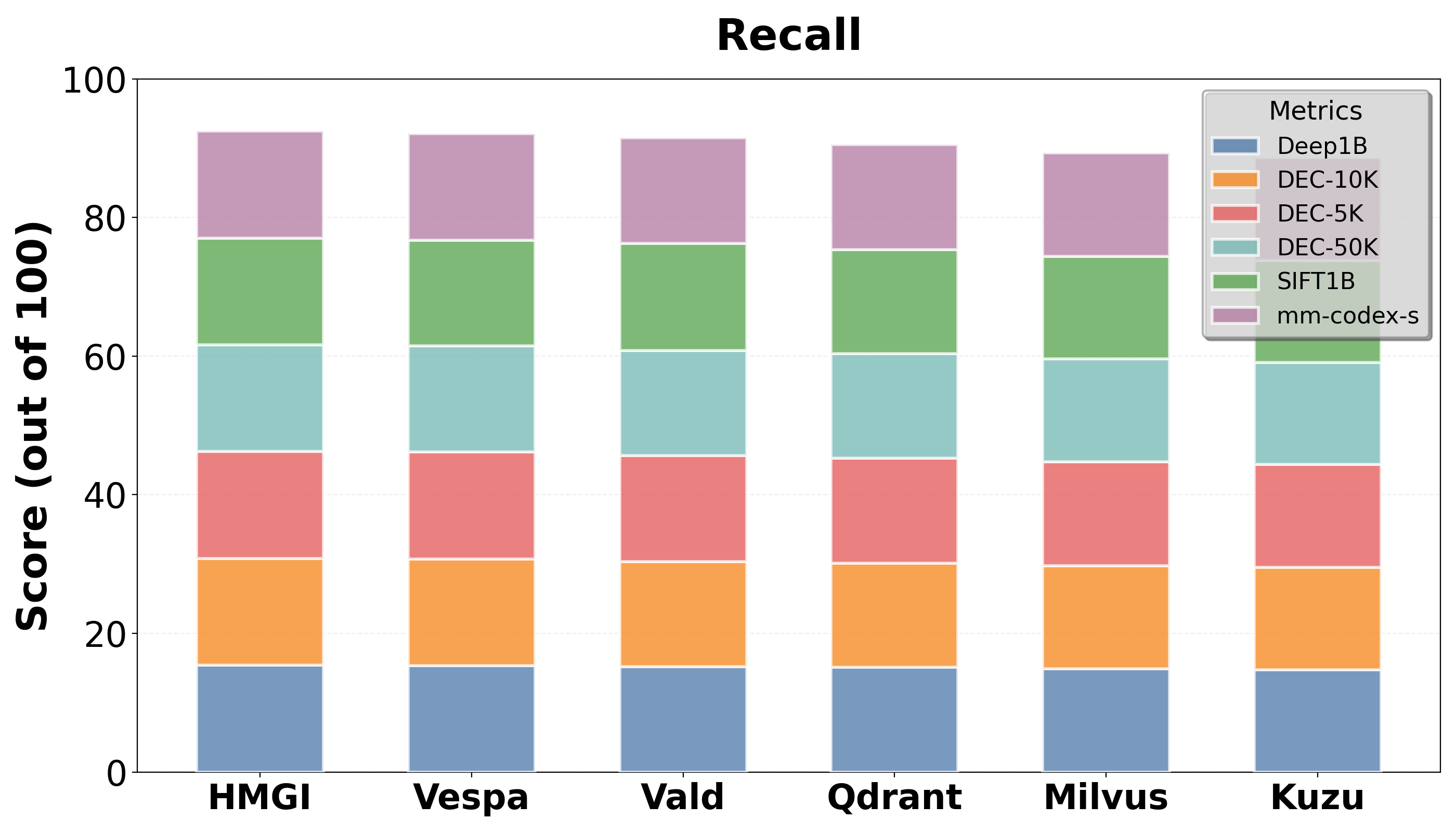
Figure 3: Recall@10 of HMGI vs Leading Open Source Competitors
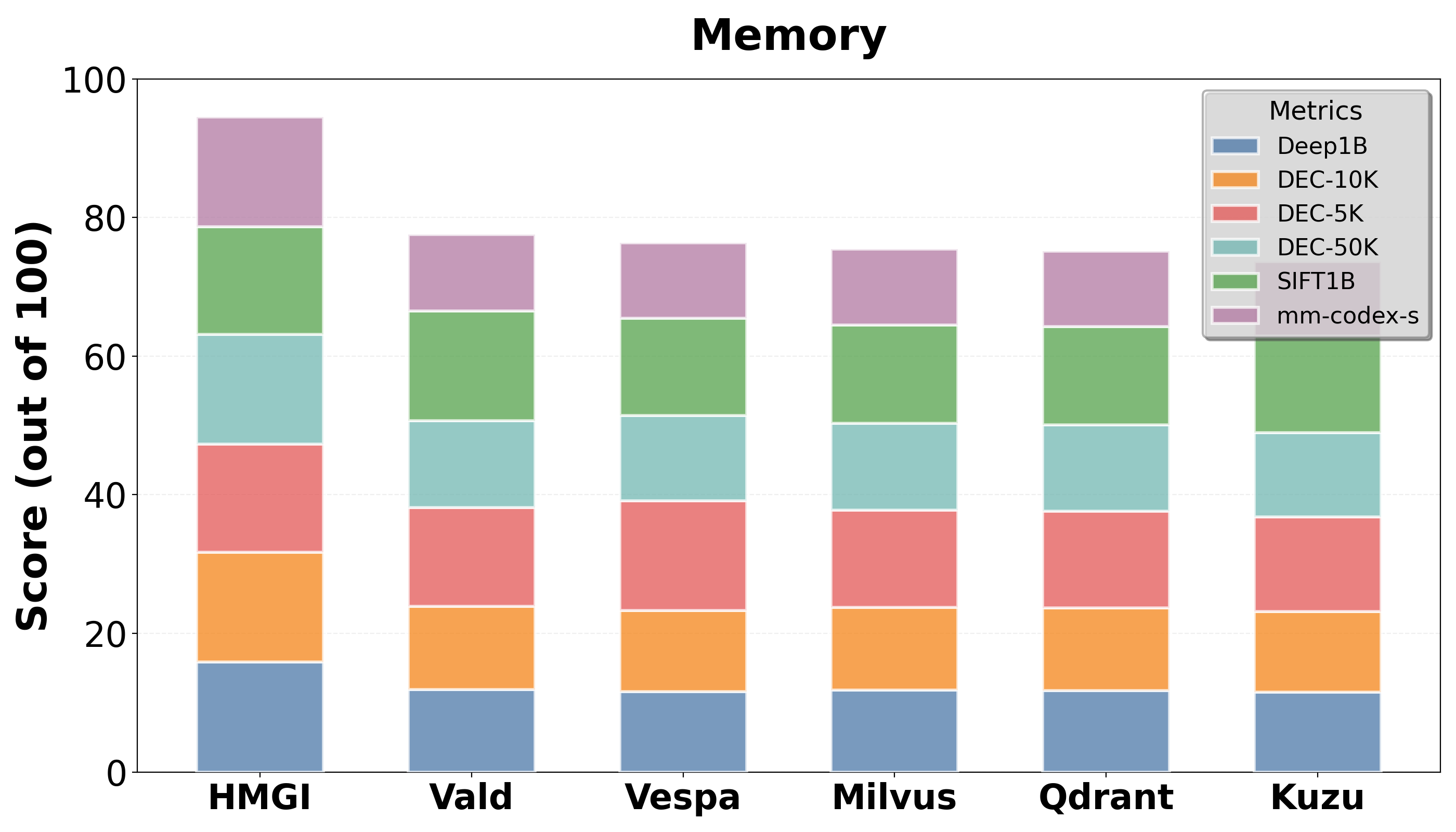
Figure 4: Memory Usage of HMGI vs Leading Open Source Competitors
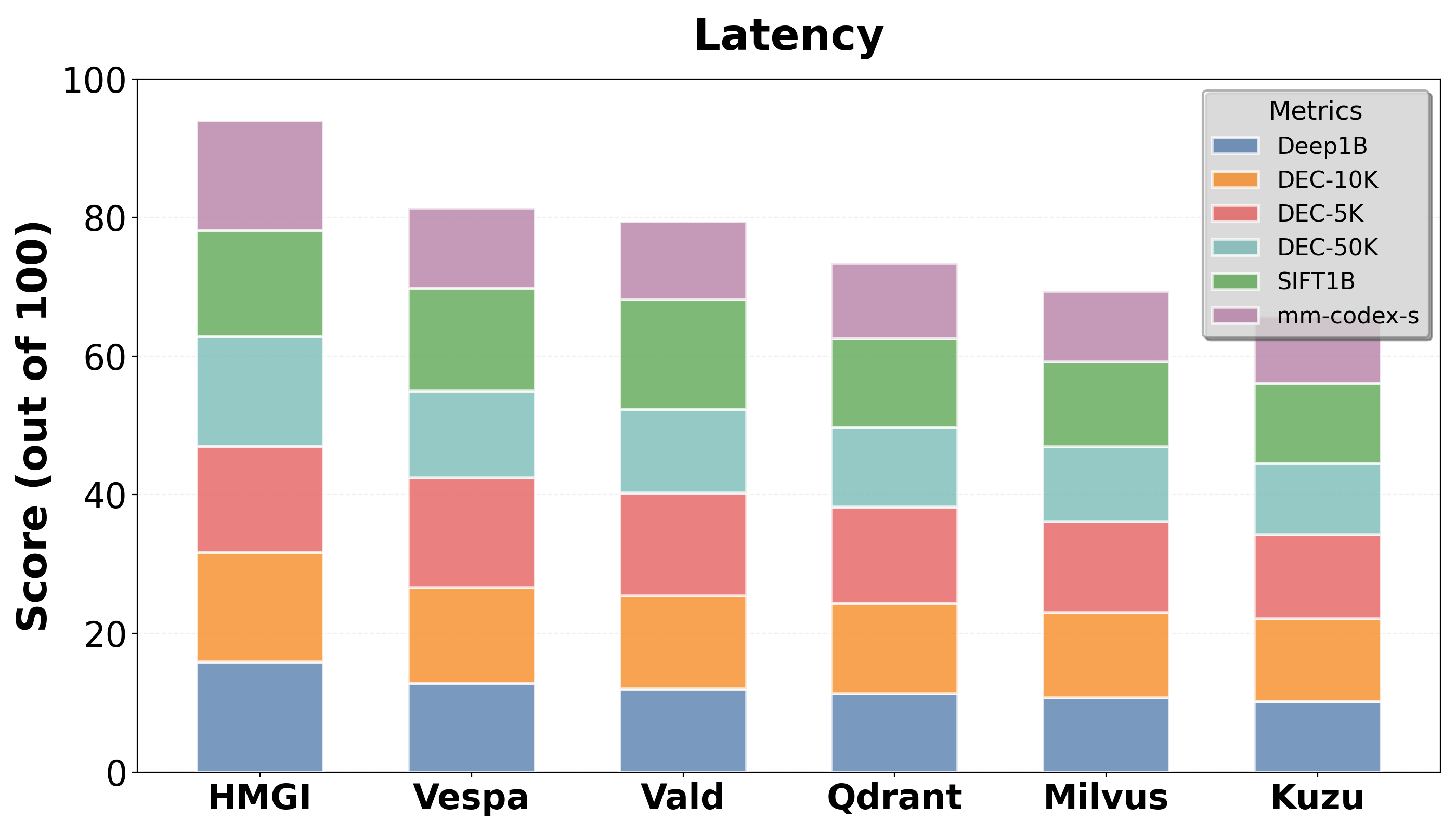
Figure 5: Average Query Latency of HMGI vs Leading Open Source Competitors
Discussion and Future Work
While HMGI represents a significant advancement in hybrid database systems, challenges remain in further reducing latency, embedding modality generalization, and real-time adaptability. Future work could explore automated partitioning, hardware acceleration, and learned index structures to further enhance performance and applicability.
Conclusion
The HMGI framework stands as an influential model for advancing multimodal data processing, providing a unified approach that marries the semantic precision of vector search with the relational depth of graph databases. As data continua to grow in complexity and volume, HMGI’s hybrid capabilities will be essential for innovative AI applications and complex analytics.