High-resolution Photo Enhancement in Real-time: A Laplacian Pyramid Network
Abstract: Photo enhancement plays a crucial role in augmenting the visual aesthetics of a photograph. In recent years, photo enhancement methods have either focused on enhancement performance, producing powerful models that cannot be deployed on edge devices, or prioritized computational efficiency, resulting in inadequate performance for real-world applications. To this end, this paper introduces a pyramid network called LLF-LUT++, which integrates global and local operators through closed-form Laplacian pyramid decomposition and reconstruction. This approach enables fast processing of high-resolution images while also achieving excellent performance. Specifically, we utilize an image-adaptive 3D LUT that capitalizes on the global tonal characteristics of downsampled images, while incorporating two distinct weight fusion strategies to achieve coarse global image enhancement. To implement this strategy, we designed a spatial-frequency transformer weight predictor that effectively extracts the desired distinct weights by leveraging frequency features. Additionally, we apply local Laplacian filters to adaptively refine edge details in high-frequency components. After meticulously redesigning the network structure and transformer model, LLF-LUT++ not only achieves a 2.64 dB improvement in PSNR on the HDR+ dataset, but also further reduces runtime, with 4K resolution images processed in just 13 ms on a single GPU. Extensive experimental results on two benchmark datasets further show that the proposed approach performs favorably compared to state-of-the-art methods. The source code will be made publicly available at https://github.com/fengzhang427/LLF-LUT.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making photos look better, fast—even at very high resolutions like 4K. The authors created a new method called LLF-LUT++ that combines two kinds of image adjustments:
- Global changes that affect the whole picture (like overall brightness and color)
- Local changes that improve small details (like edges and textures)
By mixing smart math and efficient AI, the method can enhance big, high-quality images in real time, while keeping fine details sharp.
What were the researchers trying to do?
The paper sets out to solve a common problem: many image enhancement tools are either very powerful but too slow for big images, or fast but not great at improving details. The researchers wanted to:
- Make photo enhancement work in real time on high-resolution images (like 4K)
- Keep both overall appearance (color, brightness) and local details (edges, textures) looking good
- Use a method that doesn’t need huge amounts of memory or computing power
- Improve quality compared to earlier techniques that relied mostly on global changes
How did they do it?
To explain the approach, think of a photo as a layered cake:
Breaking the image into layers (Laplacian pyramid)
The image is split into layers:
- A smooth “base” layer that captures overall color and brightness (low-frequency)
- Several “fine detail” layers that capture edges and textures (high-frequency)
This split is reversible, so the image can be put back together perfectly after adjustments.
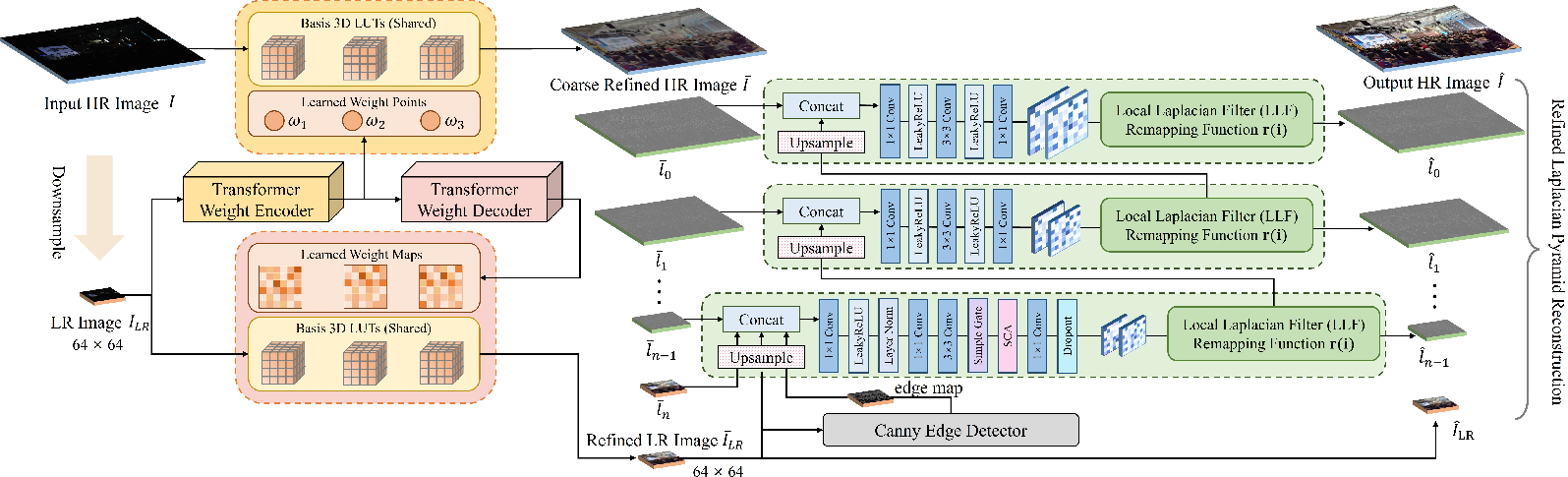
Global color adjustment with a 3D LUT (like a color recipe book)
A 3D Look-Up Table (3D LUT) is like a recipe book that tells you how to change each color into a better one. LLF-LUT++:
- Makes quick global changes to the full-resolution image using simple “weight points” (a few numbers)
- Makes more precise global changes to a small, downsampled version using detailed “weight maps” (a per-pixel guide)
Using both keeps things fast and consistent.
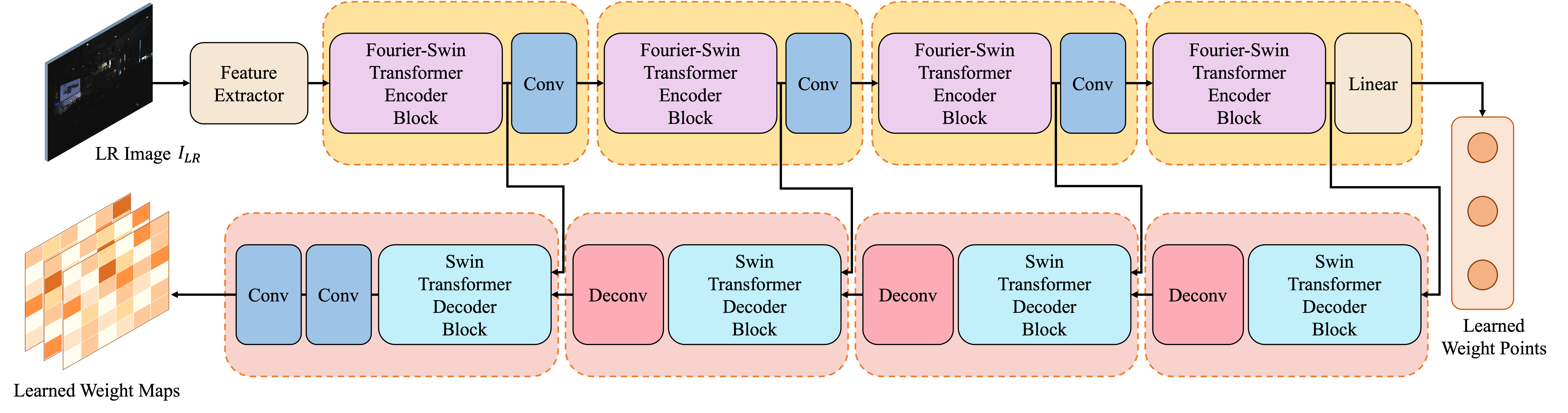
Predicting those weights with a lightweight transformer
A special “spatial-frequency transformer” predicts the weight points and weight maps by:
- Looking at spatial patterns (what appears where in the image)
- Looking at frequency patterns (how often colors and textures repeat), using a tool called FFT
This helps the model understand both the overall tone and the fine structure of the image without being slow.
Sharpening local details with a local Laplacian filter
Global color changes alone can miss small details. So the method uses a local Laplacian filter, which is an edge-aware tool that:
- Enhances details without causing unwanted halos or artifacts
- Learns the best parameters for the filter automatically from the image (so no manual tuning)
- Applies these filters progressively from low-resolution layers up to high-resolution layers
Putting it all together
The process in simple steps:
- Downsample the image and predict weights with the transformer
- Apply global color changes using the 3D LUT to both the full image and the small version
- Split the globally enhanced image into layers (pyramid)
- Use learned local filters to polish edges and details layer by layer
- Reconstruct the final enhanced image
What did they find?
The new method is both fast and high-quality:
- On the HDR+ dataset, it improved image quality by 2.64 dB in PSNR compared to their earlier version (higher PSNR means the result is closer to the ideal target image)
- It processes 4K images in about 13 milliseconds on a single GPU (that’s real-time)
- It performs well on two popular benchmarks (HDR+ and MIT-Adobe FiveK), often matching or beating other state-of-the-art methods
- It uses a relatively small model with efficient computation, making it more practical for devices like phones and cameras
Why does this matter?
This research could make a real difference in everyday technology:
- Better-looking photos and videos on phones, drones, and cameras, instantly
- More reliable results with sharp details and good color, even in tricky lighting
- Faster processing that saves energy and works on smaller devices
- A strong example of how mixing classic image tools (like pyramids and filters) with modern AI (like transformers and LUTs) can solve tough problems
The authors plan to release the code, which means others can build on their work to improve photo and video editing apps, camera pipelines, and real-time imaging systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following aspects underexplored or unresolved, offering concrete directions for future research:
- Generalization beyond HDR+ and MIT-Adobe FiveK: no cross-dataset, cross-camera, or cross-ISP evaluation to assess robustness to different sensors, pipelines, or shooting conditions.
- Domain robustness: no analysis on highly challenging scenes (e.g., night, low-light noise, underwater, strong color casts, multi-illuminant scenes, backlit/high-contrast scenarios).
- Video extension: temporal consistency and flicker suppression for sequential data are not addressed.
- Edge-device deployment: real-time claims are reported only “on a single GPU”; no measurements on mobile SoCs/CPUs/NPUs, energy consumption, thermal throttling, or memory usage in edge environments.
- Scalability to ultra-high resolutions: runtime is reported for 4K only; behavior at 8K/48MP and memory/runtime scaling is not characterized.
- Data requirements: method is trained in fully supervised, paired settings; unsupervised/weakly supervised or few-shot adaptation to new styles/devices is not explored.
- User control and stylistic variability: no mechanism to control enhancement strength/style, or to emulate different editors (e.g., different FiveK experts) at inference time.
- Semantic awareness: the pipeline is not conditioned on semantic regions (faces/skin, sky, foliage, text), which often require region-specific adjustments; benefits of semantic priors remain unexplored.
- Consistency between HR and LR fusion: the strategy mixes HR weight-point fusion and LR weight-map fusion; potential inconsistencies or artifacts from this mismatch are not quantified or analyzed.
- Basis LUT design: the number of basis LUTs T, LUT bin resolution N_b, and their impact on accuracy/latency/memory are not reported nor ablated; optimal LUT set design remains open.
- LUT interpretability and reuse: learned LUT content is not analyzed (e.g., clustering, diversity, specialization), nor is transfer/reuse across datasets/devices studied.
- Pixel-level weight-map resolution: weight maps are predicted at LR (~64×64), potentially limiting fine-grained spatial modulation; benefits of multi-scale or HR weight maps are not investigated.
- Fixed LLF threshold σ_r: σ_r is fixed (0.1) and not learned or adapted; its sensitivity and optimality across scenes are not evaluated.
- Canny edge reliance: edge maps use a fixed-parameter, non-learned Canny detector; sensitivity to noise, textures, and parameter choices, and potential gains from a learned, differentiable edge/structure extractor are not studied.
- Fast LLF approximation trade-offs: the quality gap versus the original local Laplacian filter, and the artifact profile (e.g., halos, gradient reversals) under the fast approximation are not quantified.
- Artifact analysis: no targeted evaluation of halos, banding, ringing, or color shifts; failure-case taxonomy and stress tests (over/under-exposure extremes, heavy compression) are missing.
- Color management: handling of color spaces, gamut mapping, white balance consistency, and multi-illuminant conditions is not discussed; potential colorimetric drift is unquantified.
- RAW-to-sRGB integration: the method assumes preprocessed inputs (e.g., DNG→TIF); end-to-end integration with RAW demosaicing/ISP or joint training with camera pipelines is not explored.
- Loss design vs. aesthetics: reliance on PSNR/SSIM/LPIPS without human preference studies; alignment with subjective aesthetic quality and photographer intent is unverified.
- Sensitivity and stability: hyperparameter sensitivity (loss weights λ_s/λ_m/λ_p, σ_r, pyramid depth/base resolution) and training stability across seeds/datasets are not reported.
- Pyramid configuration: the base resolution is fixed at ~64×64; optimal base resolution, alternative down/up-sampling kernels, and anti-aliasing strategies are not systematically evaluated.
- Fourier-Swin architecture specifics: the choice of FFT1d vs. 2D spectral modeling, and ablations isolating the spectral branch’s contribution to quality and speed, are not provided.
- Multi-scale weighting: only the lowest (LR) level appears to use weight maps; potential benefits of predicting multi-level weight maps/points across pyramid scales remain unexplored.
- Robustness to compression and noise: performance on JPEG-compressed or noisy inputs (typical for mobile photos) is not evaluated; denoising-aware training is absent.
- White-box guarantees: no theoretical analysis of monotonicity/stability for the combined LUT+LLF pipeline or of reconstruction fidelity under learned remapping.
- Deployment details: memory footprint (parameters + LUT tables), cache behavior, and quantization (INT8/FP16) effects on quality and speed are not studied.
- Fairness and reproducibility: the exact GPU model, inference settings, and preprocessing choices for all compared baselines are not fully standardized, complicating fair runtime/quality comparisons.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that directly leverage LLF-LUT++’s real-time, high-resolution photo enhancement, its fusion of global 3D-LUT tone manipulation with local Laplacian detail refinement, and its lightweight spatial-frequency transformer for image-adaptive weighting.
- Smartphone camera pipelines (Healthcare, Media, Consumer Electronics)
- Use case: Real-time HDR/low-light photo enhancement in the camera app—both in viewfinder previews and on capture—providing global tone mapping with edge-preserving local detail.
- Tools/products/workflows: “Enhance” mode in native camera; OEM firmware update integrating an LLF-LUT++ module; on-device gallery auto-enhancement.
- Assumptions/dependencies: Porting from GPU to mobile NPUs/ISPs requires quantization and color-space alignment; device-specific retraining using RAW-to-JPEG pairs; low-resolution weight prediction must be consistent with the device’s demosaicing and white balance stages.
- Drone and action camera imaging (Robotics, Media, Mapping)
- Use case: On-device enhancement of 4K aerial footage for cinematography and live teleoperation, improving contrast and detail without heavy compute.
- Tools/products/workflows: LLF-LUT++ add-on in DJI/GoPro pipelines for live preview and recording; SDK component for third-party drone apps; auto-grade profiles based on 3D-LUT bases.
- Assumptions/dependencies: Real-time budgets and power constraints on embedded SOCs; per-sensor calibration; careful use in workflows requiring radiometric fidelity (e.g., photogrammetry).
- Dashcams and security cameras (Security, Transportation)
- Use case: Clearer 4K frames under adverse lighting (glare, nighttime) with fast global tone adjustments and locally preserved edges that aid operator review and incident analysis.
- Tools/products/workflows: Firmware update for edge enhancement and tone mapping; on-prem NVR filter; cloud batch processing for archives.
- Assumptions/dependencies: Consistent performance across varied scenes; compatibility with vendor ISP pipelines; minimal latency increases for continuous recording.
- Photo and video editing plugins (Software, Media)
- Use case: Automated aesthetic enhancement that reduces manual color grading and local edge tweaking in tools like Photoshop, Lightroom, and DaVinci Resolve.
- Tools/products/workflows: “LLF-LUT++ Auto-Enhance” plugin; batch processing for large photo sets; preset-driven LUT bases combined with image-adaptive weights.
- Assumptions/dependencies: Color-space conversions (RAW, DCI-P3, Rec.709, sRGB); fine-tuning LUT bases to studio styles; licensing and integration with host APIs.
- Social media and content platforms (Media, Software)
- Use case: On-device or server-side pre-upload enhancement that improves aesthetics under platform constraints, enabling consistent visual quality with minimal compute.
- Tools/products/workflows: Mobile filter in TikTok/Instagram; server microservice for batch enhancement at scale; presets for creators.
- Assumptions/dependencies: Platform GPU availability; fairness and transparency policies for automated editing; user controls for style intensity.
- E-commerce and product photography (Retail, Software)
- Use case: Batch enhancement of product images for clearer textures and true-to-life tones without manual retouching.
- Tools/products/workflows: Cloud pipeline using LLF-LUT++ for catalog updates; preset LUT bases tailored to product categories.
- Assumptions/dependencies: Lighting variability and color accuracy demands; integration with CMS/DAM systems; QA workflows to avoid over-enhancement.
- Live broadcast and streaming filters (Media)
- Use case: Real-time enhancement of camera feeds in OBS/VMix for better contrast and detail at low compute cost.
- Tools/products/workflows: LLF-LUT++ filter plugin; presets for different lighting conditions; operator control over enhancement strength.
- Assumptions/dependencies: Stable 4K throughput; CPU/GPU headroom in streaming rigs; simple UI for rapid tuning.
- Academic research baselines and pedagogy (Academia)
- Use case: Reference implementation for real-time high-res enhancement; teaching module demonstrating Laplacian pyramids with learned local filters and image-adaptive 3D LUTs.
- Tools/products/workflows: Open-source code (GitHub) in coursework; baseline for benchmarking new hybrid operators; ablation studies on LUT fusion and pyramid levels.
- Assumptions/dependencies: Availability of datasets (HDR+, MIT-Adobe FiveK); reproducible training environment; documentation quality.
Long-Term Applications
These use cases require additional research, scaling, or productization to address technical gaps such as temporal consistency, RAW-pipeline integration, device-specific constraints, and broader policy considerations.
- Video enhancement with temporal consistency (Media, Software)
- Use case: Shot-level, temporally coherent enhancement across frames to avoid flicker while preserving local detail.
- Tools/products/workflows: Temporal extension of LLF-LUT++ with motion-aware weight maps; temporal Laplacian filtering; shot boundary detection; streaming-friendly variants.
- Assumptions/dependencies: New training objectives for temporal stability; optical flow or transformer-based temporal attention; real-time constraints at 4K/60fps.
- Native RAW-to-JPEG ISP integration (Consumer Electronics, Imaging)
- Use case: Embedding LLF-LUT++ into the camera ISP pipeline for scene-adaptive tone mapping and edge-aware detail refinement directly from RAW.
- Tools/products/workflows: Per-sensor LUT bases; color-space-aware fusion; joint training with demosaicing/denoising modules; OEM SDK integration.
- Assumptions/dependencies: Access to proprietary ISP stages; calibration across sensors and lenses; energy and memory budgets; per-device datasets.
- Personalized aesthetic profiles and creative LUT ecosystems (Media, Software)
- Use case: User-specific enhancement styles via multiple 3D-LUT bases, regulated by image-adaptive weight maps for tailored looks (cinematic, vivid, natural).
- Tools/products/workflows: Style marketplace for LUT bases; creator tools to author LUT sets; mobile app personalization using lightweight predictors.
- Assumptions/dependencies: Robust style control without artifacts; intuitive UI/UX; cross-device consistency; rights management for LUT assets.
- AR/VR display optimization (XR, Gaming, Media)
- Use case: Dynamic tone mapping and edge-preserving enhancement for XR scenes to improve readability and comfort under varied display characteristics.
- Tools/products/workflows: LLF-LUT++ variants tuned to headset optics and HDR displays; scene-dependent enhancement; SDK for XR engines.
- Assumptions/dependencies: Latency targets in XR; color and gamma variations across devices; perceptual studies for comfort/safety.
- Remote sensing and multispectral adaptation (Energy, Geospatial)
- Use case: Edge-preserving tone/contrast enhancement of RGB aerial/satellite imagery for operator interpretation and reporting; exploratory extension to multispectral bands.
- Tools/products/workflows: Pipeline for RGB orthomosaics; customizable LUT bases for different terrains; potential adaptation to multispectral (requires new mappings).
- Assumptions/dependencies: Preservation of radiometric fidelity when needed; alignment with geospatial workflows; validation for non-RGB bands.
- Human-in-the-loop editorial workflows (Media, Policy)
- Use case: Semi-automatic enhancement with explainable controls and audit trails to meet authenticity standards in journalism and regulated contexts.
- Tools/products/workflows: UI exposing weight maps/points; metadata logs (C2PA) that record enhancement steps; review and approval pipeline.
- Assumptions/dependencies: Compliance with editorial guidelines; governance of automated editing; standardized metadata for transparency.
- Energy-efficient computing and green AI initiatives (Policy, Academia, Consumer Electronics)
- Use case: Demonstrate substantial energy savings by replacing heavy CNNs with hybrid LUT-plus-local-filter approaches on edge devices.
- Tools/products/workflows: Benchmarks of MACs/runtime vs. quality; policy briefs for sustainable imaging; OEM adoption in low-power modes.
- Assumptions/dependencies: Verified measurements in real devices; cooperation with manufacturers; standard test suites.
- Compression-aware enhancement for streaming (Media, Telecom)
- Use case: Pre-enhancement to improve perceptual quality at lower bitrates by optimizing contrast and detail before encoding.
- Tools/products/workflows: Encoder-integrated LLF-LUT++; joint optimization with rate-control; perceptual metrics-driven profiles.
- Assumptions/dependencies: Controlled studies proving bitrate savings without artifacts; encoder API integration; scene variability handling.
- Cross-domain transfer to specialized imaging (Healthcare, Industrial Inspection)
- Use case: Adaptation to non-aesthetic tasks where improved clarity helps human interpretation (e.g., dermatology photos, factory visual checks).
- Tools/products/workflows: Domain-specific LUT bases and training; clinician/operator-reviewed presets; QA protocols for safe use.
- Assumptions/dependencies: Strict validation to avoid misleading artifacts; preservation of diagnostically relevant information; regulatory approvals when applicable.
General Assumptions and Dependencies
- Data and training: Performance and aesthetics depend on representative training datasets (e.g., HDR+, MIT-Adobe FiveK), device-specific calibrations, and consistent color spaces.
- Hardware constraints: Reported 13 ms at 4K on a single GPU; achieving similar performance on mobile/embedded devices requires hardware-aware optimization (quantization, CUDA/OpenCL/Metal/Vulkan/NNAPI backends).
- Color pipeline compatibility: Proper handling of RAW/Bayer, white balance, gamma, and target output spaces (sRGB, Rec.709, HDR10) is essential for consistent results.
- Temporal stability (for video): The current pipeline is photo-centric; video use demands temporal consistency modules to prevent flicker.
- Transparency and ethics: Automated enhancement should include user controls and metadata for disclosure in contexts where authenticity matters (journalism, legal evidence).
Glossary
- 3D Look-Up Table (3D LUT): A 3D lattice mapping RGB values to new colors for tone/color transformation; often learned or fused adaptively for image enhancement. "we utilize an image-adaptive 3D LUT that capitalizes on the global tonal characteristics of downsampled images"
- AlexNet: A convolutional neural network whose intermediate features are used to compute perceptual losses like LPIPS. "where denotes the feature map of layer extracted from a pre-trained AlexNet~\cite{krizhevsky2017imagenet}."
- Bilateral grids: A data structure enabling fast edge-aware processing by organizing data in joint spatial–range space. "combined 3D LUTs and bilateral grids to deal with local differences within images."
- Canny edge detector: A classical multi-stage edge detection algorithm used to extract edges and avoid halo artifacts. "we initially employ a Canny edge detector with default parameters"
- CLUT (Compressed 3D Look-Up Table): A compact representation of a 3D LUT that preserves mapping capability with fewer parameters. "proposed an effective Compressed representation of 3-dimensional LookUp Table (CLUT) that maintains the 3D-LUT mapping capability and reduces the parameters."
- Fast Fourier Transform (FFT): An efficient algorithm to compute the discrete Fourier transform, used here to augment attention with spectral features. "we employ Windows Multi-Head Self-Attention (W-MSA) to extract spatial features and introduce the Fast Fourier Transform (FFT) and its inverse to W-MSA for spectral domain perception."
- Fast local Laplacian filter: A computationally efficient version of the local Laplacian filter for edge-aware detail manipulation. "a fast local Laplacian filter~\cite{aubry2014fast} is employed to replace the conventional local Laplacian filter~\cite{paris2011local} for computational efficiency."
- FLOPs (Floating Point Operations): A measure of computational cost counting arithmetic operations on floating-point numbers. "involving hundreds of billions of floating point operations (FLOPs)."
- Fourier-Swin Transformer: A Swin Transformer variant that integrates Fourier-domain processing within attention blocks. "(a) is the Fourier-Swin Transformer encoder block;"
- Gaussian pyramid: A multi-scale image representation produced by repeated smoothing and downsampling, used as the reference in Laplacian filtering. "g is the coefficient of the Gaussian pyramid at each level, which acts as a reference value"
- Halo artifacts: Unwanted bright/dark bands near edges caused by improper edge-aware processing or filtering. "to mitigate potential halo artifacts."
- HDR imaging: High Dynamic Range techniques for capturing and reproducing scenes with wide luminance variations. "high dynamic range (HDR) imaging techniques"
- LDR (Low Dynamic Range): Images with standard, limited dynamic range used as references/targets in enhancement tasks. "16-bit input HDR and 8-bit reference LDR image"
- Laplacian pyramid: A multi-scale decomposition capturing band-pass (detail) information at each level; invertible with a Gaussian pyramid. "closed-form Laplacian pyramid decomposition and reconstruction."
- Learnable Local Laplacian Filter (LLF): A parameterized, data-driven local Laplacian filtering module whose parameters are predicted per image. "we propose an image-adaptive learnable local Laplacian filter (LLF) to refine the high-frequency components"
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric using deep features to assess image similarity. "we employ an LPIPS loss~\cite{zhang2018unreasonable} function"
- MACs (Multiply–Accumulate Operations): A hardware-relevant count of operations combining multiplication and addition, often used to estimate efficiency. "The MultiplyâAccumulate Operations (MACs) and runtime are both computed on resolution."
- Monotonicity term: A regularization encouraging monotonic behavior (e.g., in LUT mappings) to stabilize training. "including smoothness term and monotonicity term "
- NAF-Block: A neural network building block emphasizing simplified attention and gating for efficient image processing. "To enhance the performance of the network, we incorporated key design elements from the NAF-Block~\cite{chen2022simple} into our architecture"
- Octave Gaussian filter: A Gaussian filter applied across octave scales (factor of two) in pyramid construction. "by means of an octave Gaussian filter"
- PSNR (Peak Signal-to-Noise Ratio): A distortion metric indicating reconstruction fidelity in decibels. "LLF-LUT++ not only achieves a 2.64 dB improvement in PSNR on the HDR+ dataset"
- Reinforcement learning: A learning paradigm where an agent optimizes actions via reward signals, here used to learn enhancement policies. "used a reinforcement learning strategy for image enhancement"
- Spatial-frequency transformer weight predictor: A transformer module that exploits both spatial and spectral features to predict fusion weights. "we designed a spatial-frequency transformer weight predictor that effectively extracts the desired distinct weights"
- SSIM (Structural Similarity Index): A perceptual metric that assesses image similarity in terms of structure, luminance, and contrast. "SSIM"
- Swin Transformer: A hierarchical vision transformer using shifted-window self-attention for efficient local-global modeling. "Unlike the vanilla Swin-Transformer block~\cite{liu2021swin}, our design features two branches"
- Transposed convolution: A learnable upsampling layer that inverts the spatial downsampling of standard convolutions. "The first three decoder blocks each include a Swin-Transformer decoder block and a transposed convolution layer"
- Trilinear interpolation: Interpolation within a 3D grid (e.g., LUT) across three axes to compute continuous outputs. "then performs trilinear interpolation to transform images."
- Windowed Multi-Head Cross-Attention (W-MCA): Cross-attention computed within local windows, attending decoder queries to encoder keys/values. "W-MCA is Windowed Multi-Head Cross-Attention."
- Windowed Multi-Head Self-Attention (W-MSA): Self-attention computed within local windows to reduce complexity while modeling dependencies. "W-MSA is Windowed Multi-Head Self-Attention"
- ΔE (Delta E color difference): A perceptual metric quantifying color differences between images. "\textcolor{black}{\downarrow}$"
- Weight map fusion: Combining outputs (e.g., from multiple LUTs) using spatially varying weight maps for per-pixel adaptation. "It retains the high performance of weight map fusion"
- Weight point fusion: Combining base LUTs using a small set of global weight scalars for efficient, spatially uniform adjustments. "integrates the benefits of weight point fusion and weight map fusion."
Collections
Sign up for free to add this paper to one or more collections.