One Life to Learn: Inferring Symbolic World Models for Stochastic Environments from Unguided Exploration
Abstract: Symbolic world modeling requires inferring and representing an environment's transitional dynamics as an executable program. Prior work has focused on largely deterministic environments with abundant interaction data, simple mechanics, and human guidance. We address a more realistic and challenging setting, learning in a complex, stochastic environment where the agent has only "one life" to explore a hostile environment without human guidance. We introduce OneLife, a framework that models world dynamics through conditionally-activated programmatic laws within a probabilistic programming framework. Each law operates through a precondition-effect structure, activating in relevant world states. This creates a dynamic computation graph that routes inference and optimization only through relevant laws, avoiding scaling challenges when all laws contribute to predictions about a complex, hierarchical state, and enabling the learning of stochastic dynamics even with sparse rule activation. To evaluate our approach under these demanding constraints, we introduce a new evaluation protocol that measures (a) state ranking, the ability to distinguish plausible future states from implausible ones, and (b) state fidelity, the ability to generate future states that closely resemble reality. We develop and evaluate our framework on Crafter-OO, our reimplementation of the Crafter environment that exposes a structured, object-oriented symbolic state and a pure transition function that operates on that state alone. OneLife can successfully learn key environment dynamics from minimal, unguided interaction, outperforming a strong baseline on 16 out of 23 scenarios tested. We also test OneLife's planning ability, with simulated rollouts successfully identifying superior strategies. Our work establishes a foundation for autonomously constructing programmatic world models of unknown, complex environments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
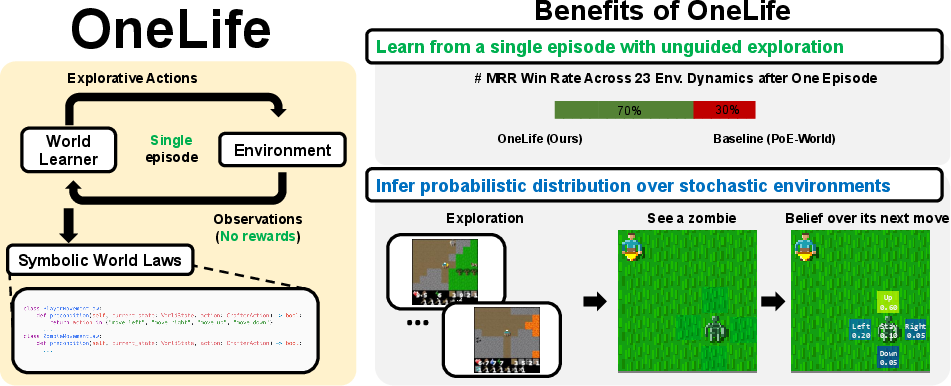
This paper introduces OneLife, a way for a computer agent to learn the rules of a complex, unpredictable world by exploring it just once—like having only one life in a tough video game. Instead of learning from lots of practice or being told what to do, the agent watches what happens and writes simple, human-readable “rule programs” that explain how the world changes when actions are taken. The goal is to build a world model the agent can use to predict the future and plan better actions.
What questions does it ask?
The paper focuses on a central question: How can an agent figure out the rules of a complicated, risky, and partly random world when it:
- Gets only a very small amount of time to explore (one episode),
- Receives no special hints, goals, or rewards from humans,
- And needs to predict what happens next in the world from its observations alone?
How did the researchers approach the problem?
The researchers designed OneLife to learn a “symbolic” world model, which means the model is written as small pieces of code (rules) rather than as a giant, unreadable neural network. Here’s how it works in everyday terms:
The world model as rules
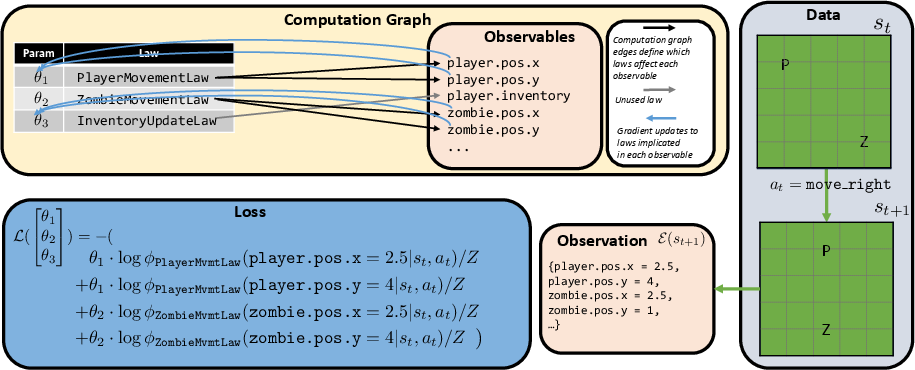
Think of the world as being governed by many little rules, each with:
- A precondition: When does this rule apply? (e.g., “If the player presses 'move right'...”)
- An effect: What does the rule change? (e.g., “...then the player’s x-position increases by 1.”)
Each rule only talks about the part of the world it cares about. For example, a “ZombieMovementRule” predicts where the zombie might move next, but it doesn’t say anything about the player’s inventory.
Because the world is partly random, the rules don’t say one exact outcome—they give probabilities (like “60% chance the zombie moves toward the player, 40% chance it wanders”). The model combines the opinions of all relevant rules to predict the next state.
Learning with “one life”
- The agent explores the world once without being told what goals to chase.
- A “law synthesizer” proposes many simple rule ideas based on what it saw during that episode. Complex events get split into small rule candidates (e.g., one rule for the player’s health change, another for the zombie’s movement).
- An “inference algorithm” then tests and scores these rules: rules that correctly predict observed changes get more weight; incorrect rules get less. Importantly, only rules that were actually relevant to a change get updated—so learning stays focused and efficient.
You can think of this like being a detective:
- You propose lots of small hypotheses (rules) about what causes what.
- You give more trust to the hypotheses that best explain the evidence you saw.
- You ignore hypotheses that weren’t involved in the observed change.
The test world (Crafter-OO)
To put OneLife to the test, the authors built Crafter-OO, a structured version of the popular Crafter game. It exposes a clean, text-based world state (like a detailed JSON or object list) and uses a pure “transition function” so there are no hidden tricks: the next state depends only on the current state and action, plus any randomness that’s part of the game.
Crafter-OO includes:
- Stochastic (random) behavior, like enemies that don’t move in a perfectly predictable way.
- Many mechanics: crafting, mining, fighting, and interacting with objects.
- Non-player characters (e.g., zombies) with their own behaviors.
How they judged success
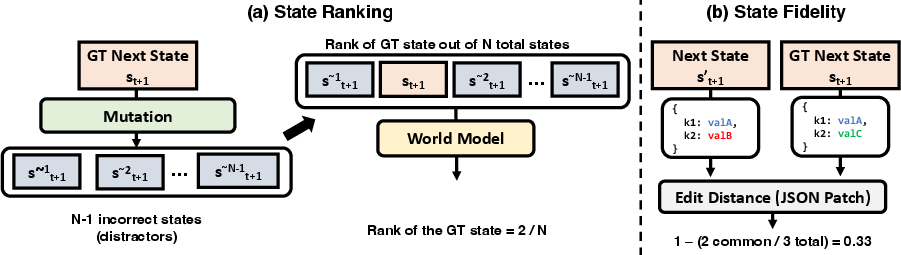
The team created two kinds of tests to see whether the world model is useful:
- State ranking: Can the model tell which future states are valid and which are illegal (made-up distractors)? For example, if you try to craft an item without the right materials, the model should rank that “next state” as unlikely.
- State fidelity: When the model simulates the next state, how close is it to the real next state? This is measured by how many small edits (changes) would be needed to fix the model’s prediction to match reality.
They used many scripted scenarios that trigger specific game mechanics (like crafting a sword) and a set of “mutators” that create illegal next states to test how well the model can spot mistakes.
What did they find?
- OneLife learned important rules of the game from just one unguided exploration episode and no human-provided rewards or goals.
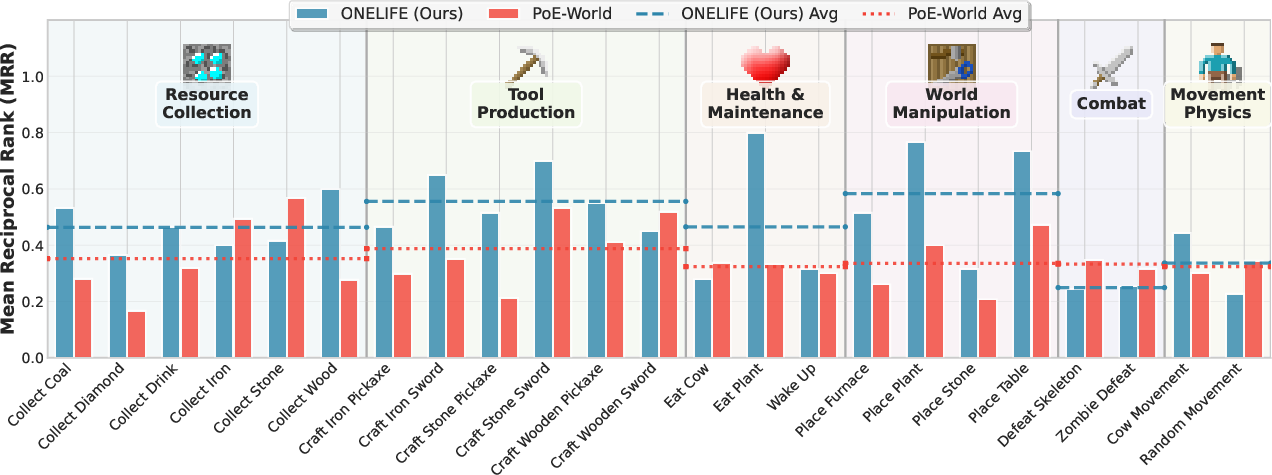
- Compared to a strong previous approach (PoE-World), OneLife did better at recognizing which future states were valid:
- It ranked the true next state as best more often (higher “Rank@1”).
- It achieved a higher Mean Reciprocal Rank (MRR), meaning it consistently put the true state near the top.
- OneLife outperformed the baseline on 16 out of 23 scenario tests, covering a wide range of mechanics (crafting, movement, combat, etc.).
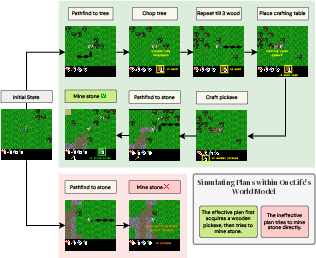
- Planning ability: The learned model could simulate long action sequences and correctly judge which plans would work better. For example:
- In a “Zombie Fighter” scenario, the model predicted that crafting a sword before fighting would lead to more damage per second than charging in immediately.
- In “Stone Miner,” it knew you must craft a pickaxe first to successfully mine stone.
- In “Sword Maker,” it recognized that reusing one crafting table is more efficient than making a new one every time.
These results suggest OneLife’s rule-based world model captures the causal logic of the environment well enough to guide decision-making.
Why does this matter?
Learning world rules from very little experience—without hand-crafted rewards or goals—is crucial for building agents that can:
- Safely explore unknown environments,
- Understand complex interactions,
- And plan smarter actions without constantly trial-and-erroring in the real world.
Because OneLife’s world model is written as small, readable rule programs, humans can inspect, edit, and trust it more easily than a black-box neural network. This opens the door to agents that can reverse-engineer the rules of complex systems, use those rules to plan, and adapt with limited data—all while staying understandable to people.
In short: OneLife shows that an agent can learn a practical, probabilistic, code-based model of a complex, random world from minimal, unguided exploration, and then use that model to make better decisions.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Reliance on privileged, object-centric state: the method assumes access to a full, symbolic, object-oriented state and a pure transition function; it is unclear how to extend OneLife to raw perceptual inputs (e.g., pixels), partial observability, sensor noise, or latent/hard-to-observe variables common in real systems.
- Single-episode data constraints: the “one life” setting is not quantified (episode length, coverage); sensitivity to early death or short episodes is unexplored, as is the minimum data budget required to learn competent models.
- Dependence on LLM-driven exploration: the exploration policy likely embeds general world knowledge (e.g., Minecraft-like priors), but the paper does not analyze how policy quality, LLM choice, prompting, or prior leakage affects coverage and model accuracy; no ablations on purely random or weaker exploration are provided.
- Law synthesis quality and control: the LLM synthesizer can generate many atomic laws, but there is no formal assessment of law precision/recall, duplication, contradictions, or missed mechanics; procedures for pruning, clustering, or prioritizing laws and for controlling combinatorial growth are unspecified.
- Lack of program repair/editing: after initial synthesis, the framework only reweights laws and does not modify faulty preconditions or effects; there is no iterative program repair loop to fix incorrect logic or refine code when weights alone are insufficient.
- Static, global law weights: θi are global across contexts; the method does not learn context-dependent parameters, per-observable weights, or internal stochastic parameters within laws, limiting expressivity when a single law’s reliability varies by state or entity configuration.
- Independence assumption across observables: the model assumes conditional independence of observables given (s, a); correlated attributes and joint constraints (e.g., conservation laws, coupled updates across entities) may be violated by factorized predictions.
- Potentially inconsistent reconstructed states: sampling each observable independently can yield invalid state combinations (e.g., negative inventory, impossible positions); the paper does not quantify how often invalid states arise or enforce global invariants during reconstruction.
- Product-of-experts calibration and semantics: the weighted PoE can become overconfident; the paper does not analyze calibration, entropy, or sharpness of predicted distributions; the role of φi as probabilities vs. scores/log-probabilities is ambiguous, and equations contain notational inconsistencies.
- Limited stochastic parameter learning: while stochasticity is modeled, there is no direct estimation of ground-truth transition probabilities (e.g., matching the true zombie-move distribution); no metrics (e.g., KL divergence, Brier score, ECE) assess probabilistic calibration or distributional accuracy.
- Temporal and multi-step dependencies: learning targets single-step transitions; the approach does not explicitly model long-range dependencies, delayed effects, or temporally extended laws/options, which may be necessary for complex causal chains and resource dynamics.
- Hidden variables and non-pure dynamics: real environments often contain unobserved state and non-Markovian effects; it is unclear how OneLife would handle latent factors, exogenous shocks, or dynamics that are not pure functions of the visible state.
- Scalability and compute: no analysis of runtime/memory as the number of laws, entities, or observables grows; the cost of LLM-based synthesis and optimization (L-BFGS) with large law libraries is not reported; practical scaling strategies (e.g., indexing, caching, sparsity) are not evaluated.
- Law conflict resolution: beyond weight downweighting, there is no principled mechanism for resolving contradictory laws, de-duplicating near-identical laws, or merging/factoring overlapping ones; structural learning over the law set remains an open problem.
- Continuous variables and mixed data types: the implementation and evaluation are discrete; how to extend to continuous attributes and hybrid discrete–continuous states (with appropriate likelihoods) is not addressed.
- Robustness to noise and imperfect extraction: the observable extractor assumes clean, correct state; the pipeline’s robustness to extraction noise, missing values, or mis-specified supports is not evaluated.
- Generalization and transfer: evaluation is confined to Crafter-OO; transfer to other domains, seeds, maps, object taxonomies, or altered mechanics is untested; no results on out-of-distribution generalization or adaptation.
- Evaluation scope and baselines: distractor-based ranking depends on a hand-crafted mutator set—coverage and bias are unclear; comparisons exclude strong neural world models (e.g., Dreamer variants) and other symbolic/hybrid baselines; ablations on synthesizer design, number of laws, and exploration coverage are missing.
- Planning evaluation breadth: planning results cover three scenarios with hand-written policies and reward functions; no closed-loop planning (e.g., MCTS, policy search) or analysis of model bias accumulation in long rollouts and its effect on plan selection.
- Safety and active experiment design: in a “one life” setting, strategies for safe, informative exploration (active learning/experimental design under risk) are not studied; how to choose actions to maximally reduce model uncertainty safely remains open.
- Theoretical guarantees: there are no identifiability results, convergence guarantees for weight optimization, or conditions under which atomic laws plus PoE recover the true transition dynamics; the expressivity and sample complexity of the law class are not analyzed.
- Reproducibility and cost: detailed LLM configurations, compute budgets, and cost of synthesis/exploration are not reported; sensitivity to random seeds and LLM nondeterminism is not presented.
- Faithfulness of Crafter-OO: while Crafter-OO is proposed as a pure, object-centric testbed, the degree of fidelity to original Crafter mechanics, and any discrepancies that could bias conclusions, is not quantitatively validated.
Practical Applications
Immediate Applications
Below are applications that can be deployed today, primarily in domains where system state is already structured and actions have discrete, auditable effects (e.g., software systems, games, workflows). Each item includes sector, use case, potential tools/products, and key assumptions/dependencies.
- Software/QA and DevOps SRE
- Use case: Spec-free “plausibility oracles” for integration tests and staging. Learn atomic precondition–effect rules from a single run of API/service workflows and use state ranking to flag implausible post-conditions in CI/CD.
- Tools/products: “RuleSynth QA” (log-to-rulebook compiler), “Plausibility Oracle” (MRR-based checker), mutator-driven negative test generator.
- Assumptions/dependencies: Access to structured traces (object-like states), stable API semantics, ability to define observables; limited manual effort to write mutators for key invariants.
- Process Mining and Compliance (Finance, Insurance, Enterprise IT)
- Use case: Reverse-engineer business process rules from event logs without hand-written specifications; rank and detect illegal transitions (e.g., bypassing mandatory approvals).
- Tools/products: Explainable process miner with a probabilistic “law bank,” compliance dashboard visualizing preconditions/effects and violation likelihoods.
- Assumptions/dependencies: Clean event schemas and state snapshots; stationarity of process; role-based access logs to constrain mutators.
- Cybersecurity and Identity/Access Management
- Use case: Anomaly detection via “impossible transitions” (e.g., privilege escalation without prerequisite states); rank next-state candidates to triage alerts.
- Tools/products: State-ranking anomaly detector, atomic lawbook for typical admin operations, tabletop-simulation generator for incident response.
- Assumptions/dependencies: Availability of structured change logs (IAM events, configs), curated mutators to encode common attack-path violations.
- Game AI, Simulation, and Tooling (Gaming, Education)
- Use case: Single-playthrough modeling of game mechanics to build NPC/world simulators for planning and tutoring; modding tools for rule inspection/editing.
- Tools/products: OneLife-like plugin for sandbox games, rule-inspection UI, plan validator for quest/puzzle design; Crafter-OO as a teaching and benchmarking suite.
- Assumptions/dependencies: Object-oriented state access (e.g., mod APIs), discrete action/state representations; limited stochasticity captured in discrete supports.
- Digital Twins for Discrete-Event Systems (Manufacturing/Operations)
- Use case: Quick-start, explainable digital twins from limited logs (one shift/episode) to validate process changes without live intervention.
- Tools/products: “World Model Compiler” from history to executable rulebook; plan ranking service to compare process variants.
- Assumptions/dependencies: Discrete-event logs with explicit state/transition fields; relatively stationary operations over the modeling period.
- RPA (Robotic Process Automation)
- Use case: Auto-induction of preconditions/effects for UI/API steps (e.g., form fields, state flags), enabling robust task scripts that validate plausibility of each step’s outcome.
- Tools/products: RPA guardrails using state ranking, rule-based failure explanations, stochastic outcome handlers (e.g., expected retries).
- Assumptions/dependencies: Stable UI element/state extraction; replayable actions; minimal hidden state.
- Academic Research and Education
- Use case: Benchmarking interpretable world models and agent planning with Crafter-OO; course modules on programmatic world modeling and stochastic rule induction.
- Tools/products: Open scenarios/mutators; evaluation harness for state ranking and fidelity; law-synthesis notebooks and visualization.
- Assumptions/dependencies: Willingness to adopt OO-state testbeds; access to LLMs for law synthesis (or scripted heuristics for low-cost settings).
- Decision Support and “What-if” Analysis (Product Ops, Customer Support)
- Use case: Plan ranking in imagination to compare alternative playbooks (e.g., escalation flows, refund/resolution paths) without deploying to production.
- Tools/products: PlanSim service leveraging learned rules; plan editor with precondition-effect explainability.
- Assumptions/dependencies: Logs that expose state variables (ticket states, flags); conservative mutators to induce realistic “illegal” states for stress tests.
- Reliability Engineering and Safety Checks (General)
- Use case: Pre-execution plausibility checks for candidate actions (e.g., “is the next state likely under learned laws?”) to catch silent failures early.
- Tools/products: Lightweight SDK that wraps critical operations with state-likelihood scoring and optional deny/alert.
- Assumptions/dependencies: Observable extractor exists or can be approximated; alignment of “invalid” with risk in the target domain.
Long-Term Applications
These applications require additional research and engineering—especially in perception-to-symbol mapping, scaling to richer stochasticity, and safety—but are plausible extensions of OneLife’s method and findings.
- Robotics and Embodied AI (Manufacturing, Warehousing, Service Robotics)
- Use case: Learn interpretable, stochastic task dynamics (tool use, part interactions) from a few unguided trials; plan via imagination to reduce risky exploration.
- Tools/products: Symbolic dynamics layer atop perception; task lawbooks editable by operators; safety monitors using state ranking.
- Assumptions/dependencies: Reliable symbol grounding (perception → OO state), safe exploration policies, handling of continuous variables and contact dynamics.
- Autonomous Vehicles and ADAS
- Use case: Infer traffic interaction rules and rare-event dynamics from limited on-road exposure; rank plans by safety likelihood before execution.
- Tools/products: Rulebook overlays for map/scene graphs; precondition-aware policy validators; simulation-driven safety cases.
- Assumptions/dependencies: High-fidelity scene abstraction (agents, intents); regulatory acceptance of symbolic safety arguments; robust handling of non-stationary behavior.
- Healthcare Operations and Clinical Pathways
- Use case: Reverse-engineer clinical workflow laws (preconditions, effects) from EHR event sequences; simulate care plans to optimize throughput/safety.
- Tools/products: Explainable pathway miners; plan ranking under uncertainty; compliance checkers (e.g., prerequisite labs before medications).
- Assumptions/dependencies: De-identified, structured EHR logs; clinical validation of induced laws; governance for use in decision support, not autonomy.
- Energy and Grid Operations
- Use case: Learn discrete control and contingency rules (e.g., switching, protection, DER behaviors) from limited events; plan reconfiguration under faults.
- Tools/products: Stochastic rulebooks for grid state transitions; anomaly ranking for SCADA; digital twins for “one-life” contingency planning.
- Assumptions/dependencies: Structured telemetry and event models; safety constraints on exploration; integration with continuous physics simulators.
- Supply Chain and Logistics
- Use case: Infer executable, stochastic process laws (transport, inventory, customs) from sparse events; plan routing/fulfillment under disruptions.
- Tools/products: Planning-in-imagination over rulebooks; likelihood-based detection of implausible ETA or status transitions.
- Assumptions/dependencies: Clean, granular event/state data; handling partial observability and exogenous shocks.
- Scientific Discovery and Automated Experimentation
- Use case: Robotic scientists that form atomic laws from few unguided trials, route credit to active hypotheses, and plan next experiments.
- Tools/products: Hypothesis lawbanks with weight inference; experiment planners that simulate outcomes to maximize information gain.
- Assumptions/dependencies: Reliable experiment-to-symbol mapping; robust stochastic modeling; lab safety and closed-loop validation.
- Policy, Governance, and Assurance for AI Systems
- Use case: Auditable, human-editable rulebooks behind agents; plan validators that encode preconditions/effects for regulated operations.
- Tools/products: “Explainable Dynamics Console” for auditors; conformance tests using mutators; MRR/Rank@1 as interpretability metrics.
- Assumptions/dependencies: Standards for symbolic model reporting; acceptance of probabilistic, not purely deterministic, assurances.
- Cyber-Physical Systems Security
- Use case: Model cyber-physical laws (actuator limits, control sequences) to detect impossible state progressions indicative of tampering.
- Tools/products: Likelihood-based intrusion detectors; simulated attack-path evaluators using mutators to craft illegal transitions.
- Assumptions/dependencies: Accurate mapping from sensor data to symbolic states; adversarial robustness.
- Generalized “World Model Compiler” Platforms
- Use case: From logs to an executable, probabilistic rulebook; from plans to ranked outcomes with explanations; from operator edits to re-weighted laws.
- Tools/products: SDKs for observable extraction, law synthesis, inference (L-BFGS for weights), forward simulation, and mutator libraries.
- Assumptions/dependencies: Domain-specific observable definitions; scalable law synthesis (LLM or programmatic); conditional independence approximations or structured relaxations.
Cross-cutting assumptions and dependencies
- Symbolic state availability: Immediate deployments work best where the environment exposes an object-oriented state; otherwise, a perception layer must map raw signals to symbols.
- Coverage in “one life”: The single-episode data must encounter relevant mechanics; exploration quality (LLM scaffolding, prompts) affects learned model completeness.
- Precondition–effect fit: The domain must be suitably factorable into conditional rules; high interdependence may require richer structured modeling (relaxing independence assumptions).
- Stochasticity handling: Discrete support must cover key outcomes; continuous domains may require discretization or hybrid laws.
- Safety and governance: Unguided exploration is risky in physical systems; use simulation, sandboxes, or strict safety monitors before real-world trials.
- Compute and LLM reliance: Law synthesis currently leverages LLMs; quality and cost depend on model choice and prompt engineering; offline synthesis pipelines mitigate runtime cost.
These applications leverage the paper’s core innovations: modular precondition–effect laws, probabilistic weighting with targeted gradient updates, state ranking vs fidelity metrics, and planning via forward simulation—all designed to learn useful, interpretable dynamics from minimal, unguided interaction.
Glossary
- Automata synthesis: Automatically constructing finite-state machines or automata to model behaviors or latent dynamics. "combined functional and automata synthesis to capture latent state dynamics"
- Causally relevant dynamics: Environment behaviors that directly affect outcomes under specific goals or plans. "capture causally relevant dynamics for goal-directed decision-making"
- Conditional independence: An assumption that variables are independent given some conditioning information. "The model assumes that all observables are conditionally independent given the current state and action."
- Conditional probability distribution: A probability distribution describing outcomes of a variable given conditions. "The effect of each law specifies a set of conditional probability distributions "
- Credit assignment: Determining which components of a model are responsible for observed outcomes to update them appropriately. "perform more precise credit assignment, isolating and down-weighting incorrect hypotheses"
- Dynamic computation graph: A computation structure that changes per input, routing updates only through relevant components. "This creates a dynamic computation graph that routes both inference and optimization only through relevant laws"
- Edit Distance, Normalized: The edit distance scaled by the size of the state representation to compare errors across states. "Normalized Edit Distance: The raw edit distance divided by the total number of elements in the state representation."
- Edit Distance, Raw: The number of atomic operations needed to transform one state into another. "Raw Edit Distance: The total number of atomic JSON Patch operations required to transform the predicted state, , into the ground truth state, ."
- Exploration policy: A strategy guiding an agent’s actions to discover environment mechanics without explicit rewards. "we employ an exploration policy driven by a LLM."
- Extrinsic rewards: External, task-specific signals provided by the environment to guide learning. "Agents that explore and learn in complex, open-world environments without extrinsic rewards"
- Forward simulation: Generating predicted future states from a model to evaluate action sequences. "Forward simulation is the process of using the learned world model generatively to predict a future state"
- Hierarchical policy: A plan composed of modular subroutines structured across levels of abstraction. "Each plan is represented as a hierarchical policy (in code) that composes subroutines for navigation, interaction, and crafting."
- Intrinsic motivation: Internal signals that drive exploration and learning in the absence of external rewards. "use them to drive exploration through intrinsic motivation"
- L-BFGS: A quasi-Newton optimization algorithm for efficiently fitting parameters. "We use L-BFGS for optimization"
- Latent world models: Implicit, often non-symbolic models that represent hidden state and dynamics. "typically learn non-symbolic, latent world models"
- Law synthesizer: A component that proposes candidate programmatic laws explaining observed transitions. "a law synthesizer (\cref{sec:law_synthesis}) that proposes new laws"
- Log-softmax: A function that converts scores to log-probabilities via normalization over all outcomes. "Normalized log-probability of observing the specific outcome is then given by the log-softmax function."
- Mean Reciprocal Rank (MRR): A ranking metric averaging the inverse of the rank of the correct item. "measured by MRR (Mean Reciprocal Rank) of the true next state"
- Mutators: Programmatic functions that create illegal distractor states to test model discrimination. "We create distractors for state ranking using mutators (\cref{sec:mutators}), which programatically modify the next state "
- Normalizing factor: A constant ensuring probabilities sum to one in a model. "Note we use here to denote the normalizing factor."
- Observable extractor: A function mapping complex states to a vector of primitive observables for comparison and learning. "we introduce an observable extractor, ."
- Object-centric state: A representation that organizes the world into explicit entities and their attributes. "Crafter-OO, our variant of the complex Crafter environment with object-centric state"
- Object-oriented symbolic state: A structured, code-readable representation of entities and relations in the environment. "structured, object-oriented symbolic state"
- PDDL: A standard language for expressing planning problems and domain dynamics symbolically. "construct formal planning representations like PDDL from environment interactions"
- Planning in imagination: Evaluating plans by simulating them within a learned model instead of the real environment. "supports planning in imagination; by simulating rollouts of different policies entirely within the model"
- Precondition-effect structure: A rule format with applicability conditions and resulting state changes. "Each law operates through a precondition-effect structure"
- Probabilistic program: A program that defines stochastic generative processes over variables. "Our world model can be viewed as a probabilistic program"
- Probabilistic programming: A modeling paradigm where programs express probability models and inference. "a probabilistic programming approach (\cref{sec:mixture_of_laws})"
- Product of programmatic experts: Combining multiple expert programs multiplicatively to model complex dynamics. "representing the world model as a product of programmatic experts"
- Reverse engineer: Infer underlying rules of a system from observations alone. "How can an agent reverse engineer the laws of a complex, dangerous stochastic world"
- Rollouts: Sequences of simulated states and actions generated by a model to evaluate plans. "rollouts simulated within the world model successfully identify superior strategies"
- State fidelity: The closeness of generated states to the true next states of the environment. "state fidelity, the ability to generate future states that closely resemble reality."
- State ranking: The ability to assign higher likelihood to plausible next states than to implausible ones. "state ranking, the ability to distinguish plausible future states from implausible ones"
- Stochastic environment: An environment with inherent randomness affecting outcomes. "a complex, stochastic environment"
- Support (of a distribution): The set of all possible values an observable can take under a distribution. "Let be the discrete support (set of all possible values) for observable "
- Symbolic world modeling: Inferring executable, interpretable programs that capture environment dynamics. "Symbolic world modeling is the task of inferring and representing the transitional dynamics of an environment as an executable program."
- Transition function: A function mapping a current state and action to the next state (possibly stochastically). "a pure transition function that operates on that state alone"
- Unguided exploration: Interaction without environment-specific goals or rewards to discover mechanics. "a single unguided (no environment-specific rewards / goals) episode"
- Weighted product of programs: Combining program outputs multiplicatively with learned weights to form predictions. "represent the transition function as a weighted product of programs"
Collections
Sign up for free to add this paper to one or more collections.