- The paper demonstrates that combining dynamic sparse training with advanced architectural techniques effectively mitigates optimization issues in DRL.
- The study introduces a Module-Specific Training (MST) framework that assigns dense, dynamic, and static training to encoders, critics, and actors respectively.
- Empirical results show that strong network design, including normalization and residual connections, is essential to overcoming plasticity loss and capacity collapse in DRL.
Rethinking the Role of Dynamic Sparse Training for Scalable Deep Reinforcement Learning
Introduction
The paper "Rethinking the Role of Dynamic Sparse Training for Scalable Deep Reinforcement Learning" introduces an in-depth analysis of how dynamic sparse training (DST) influences the scalability and performance of deep reinforcement learning (DRL) systems. Despite the widespread success of scaling in supervised learning, similar attempts in DRL have met with numerous challenges, including optimization pathologies like plasticity loss and capacity collapse. This study aims to elucidate the interactions between architectural improvements and dynamic training regimes and proposes a novel framework, Module-Specific Training (MST), to enhance the scalability and efficiency of DRL models without algorithmic modifications.
Dynamic Sparse Training in DRL
Dynamic sparse training involves dynamically adapting the network topology during training while maintaining a degree of sparsity. This approach contrasts with conventional dense training and has been shown to mitigate some of the optimization pathologies characteristic of DRL, such as plasticity loss and unstable learning dynamics. The study presents DST as a complementary strategy to architectural advancements, such as layer normalization and residual connections, which have independently demonstrated scalability benefits.
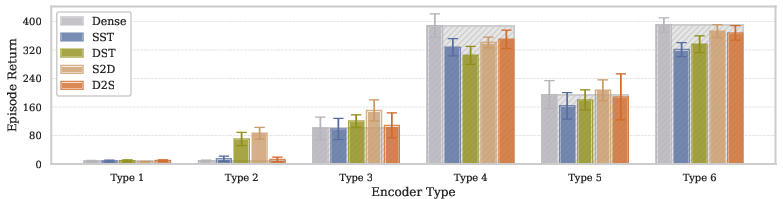
Figure 1: Impact of encoder architecture types and training regimes on agent performance at default size. The results demonstrate that architectural improvements (progression from Type 1 to Type 6) yield substantially greater performance gains than differences between training regimes.
Role of Network Architecture
The paper emphasizes the predominant role of architectural design in determining the optimization landscape and scalability potential of DRL models. Improvements such as normalization techniques, advanced activation functions, and strategic residual connections provide the foundational benefits that enable robust scaling (Figure 1). This architectural grounding is crucial, as evidenced by failures observed when dynamic sparse training methods alone are applied to inadequately designed networks.
Module-Specific Insights and Framework
Each DRL component—encoder, critic, and actor—has unique learning paradigms that affect how they respond to different training strategies. The authors systematically evaluate these responses:
- Encoder: Self-supervised learning encoders derive the most benefit from well-crafted architectural designs, with dynamic sparse training offering little additional advantage (Figure 2).
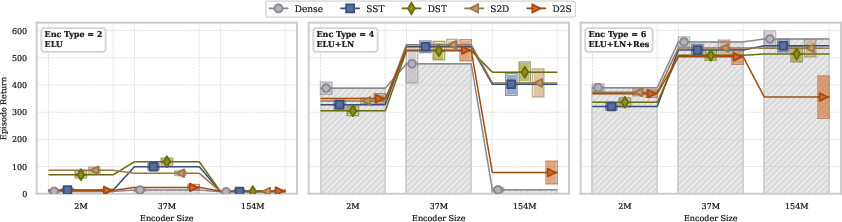
Figure 2: Scaling behavior of agent performance as encoder parameter count increases across three orders of magnitude. While introducing network sparsity and dynamicity can sometimes outperform dense training, architectural design remains the fundamental determinant of scalability potential.
- Critic: Critics benefit significantly from dynamic sparse training as it helps mitigate the plasticity loss intrinsic to temporal difference learning. The synergy between appropriate architectures and DST yields marked improvements in scalability.
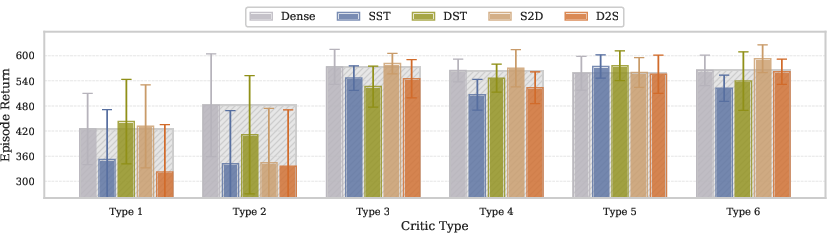
Figure 3: Comparison of critic architecture types and training regimes at default network size. With a strong encoder providing effective state and action representations, critic networks reliably achieve stable optimization.
- Actor: For actors, static sparsity combined with advanced architectures consistently outperformed dynamic sparse approaches, especially at larger scales, where training stability is paramount.
The proposed MST framework capitalizes on these findings by assigning dense training to encoders, DST to critics for managing learning pathologies, and static sparse training to actors to maintain policy stability.
Practical Implications and Future Work
The MST framework broadens the application potential of DRL algorithms through enhanced scalability while requiring no modifications to the underlying algorithms themselves. This approach is validated across varied DRL scenarios, showcasing its versatility and efficiency (Figures 4 and 5).
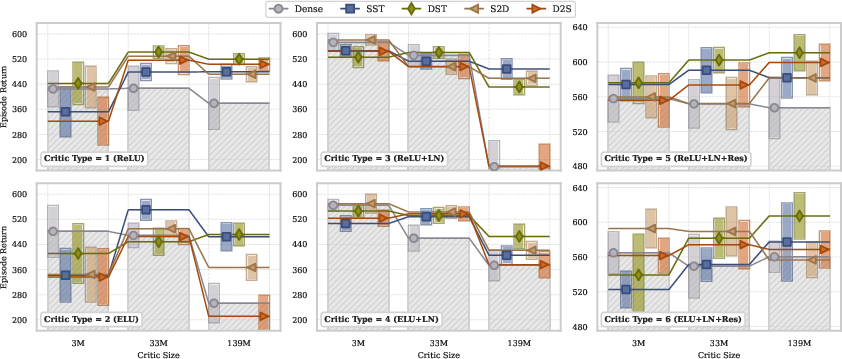
Figure 4: Dynamic training approaches, particularly DST, consistently outperform dense and static sparse baselines. Results demonstrate that unlocking the full potential of scaled critic networks requires the combination of advanced architectures with appropriate dynamic training regimes.
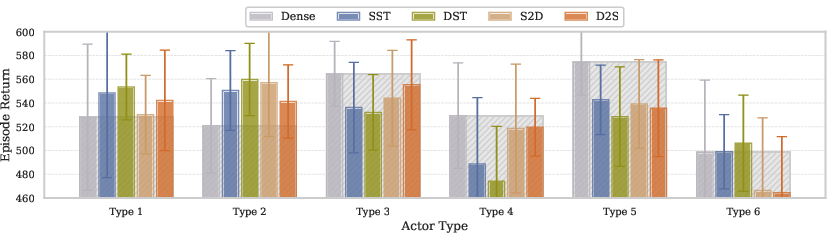
Figure 5: Scaling performance with massive model size (5× width and depth, 362M parameters). Baseline MR.Q fails completely at this scale, while adding residual connections effectively prevents catastrophic collapse.
Future research directions should explore the extension of these principles to real-world applications, where challenges such as larger action spaces, multi-task learning, and continual adaptation present ongoing obstacles. Adapting deep learning mechanisms specifically for these challenging landscapes will likely yield further breakthroughs in DRL scalability and efficiency.
Conclusion
The paper systematically demonstrates that while dynamic sparse training provides tangible benefits in addressing specific optimization pathologies in DRL, its full potential is unleashed when combined with architectural advancements. The introduction of the MST framework marks a significant step towards scalable, efficient DRL by strategically leveraging the strengths of both network design and training regime tailoring.