Attention Illuminates LLM Reasoning: The Preplan-and-Anchor Rhythm Enables Fine-Grained Policy Optimization
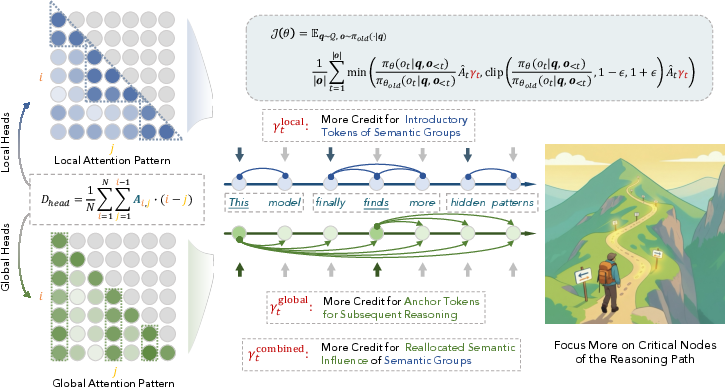
Abstract: The reasoning pattern of LLMs remains opaque, and Reinforcement learning (RL) typically applies uniform credit across an entire generation, blurring the distinction between pivotal and routine steps. This work positions attention as a privileged substrate that renders the internal logic of LLMs legible, not merely as a byproduct of computation, but as a mechanistic blueprint of reasoning itself. We first distinguish attention heads between locally and globally focused information processing and reveal that locally focused heads produce a sawtooth pattern near the diagonal indicating phrasal chunks, while globally focused heads expose tokens that exert broad downstream influence over future tokens. We formalize these with two metrics: 1) Windowed Average Attention Distance, which measures the extent of backward attention within a clipped window; 2) Future Attention Influence, which quantifies a token's global importance as the average attention it receives from subsequent tokens. Taken together, these signals reveal a recurring preplan-and-anchor mechanism, where the model first performs a long-range contextual reference to generate an introductory token, which is immediately followed by or coincides with a semantic anchor token that organizes subsequent reasoning. Leveraging these insights, we introduce three novel RL strategies that dynamically perform targeted credit assignment to critical nodes (preplan tokens, anchor tokens, and their temporal coupling) and show consistent performance gains across various reasoning tasks. By aligning optimization with the model's intrinsic reasoning rhythm, we aim to transform opaque optimization into an actionable structure-aware process, hoping to offer a potential step toward more transparent and effective optimization of LLM reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper tries to peek inside how LLMs “think” when they solve problems. The authors look at the model’s attention—the way the model chooses which earlier words to look back at when writing the next word—and discover a repeating rhythm in its reasoning. They call it preplan-and-anchor:
- Preplan: the model briefly looks farther back to plan the next step.
- Anchor: it then writes a key word that many later words keep referring to, guiding the rest of the reasoning.
Using this insight, they design a smarter training method so the model learns most from those key moments, not from every word equally. This makes the model learn faster and reason better.
What questions the paper asks
The paper focuses on three simple, kid-friendly questions:
- Can attention show us where the model is planning versus just filling in obvious words?
- Are there special “anchor” words that the rest of the answer keeps coming back to?
- If we train the model to focus more on these planning and anchor moments, does it get better at reasoning?
How they studied it (in plain language)
To understand the model’s inner steps, the authors analyzed attention—think of attention as the model’s eyes scanning back over its own writing to decide what to write next.
- Local attention (nearby): Like glancing back a few words to finish a phrase (“by the … way”). This creates short “chunks” of text.
- Global attention (farther back): Like jumping back to a main idea or important number that keeps mattering later.
They measure two things to detect the rhythm:
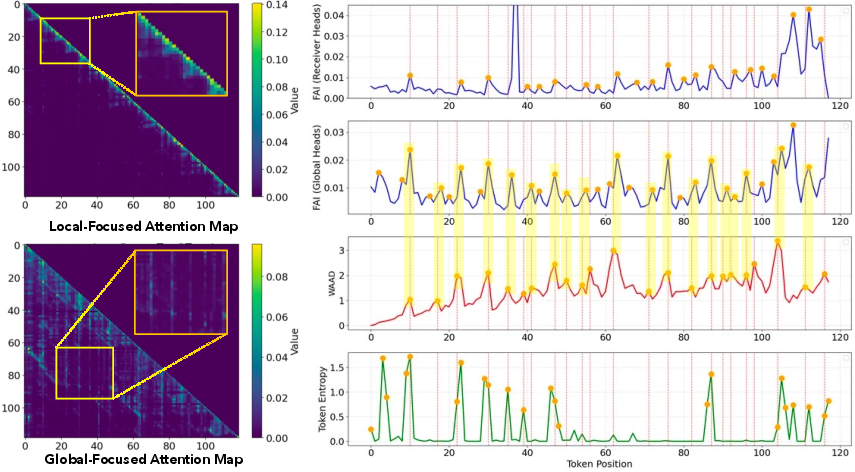
- WAAD (Windowed Average Attention Distance): How far back the model looks right before it starts a new chunk. A “spike” means it’s reaching farther back—like a quick pre-plan before starting a new step.
- FAI (Future Attention Influence): How much later words look back at a specific word. A “high FAI” word is an anchor—like a key idea (“total”, “target”, or a defined variable) that guides what comes next.
An everyday analogy:
- WAAD = how far you flip back in your notes before starting a new paragraph.
- FAI = how often future sentences refer to a keyword you just wrote.
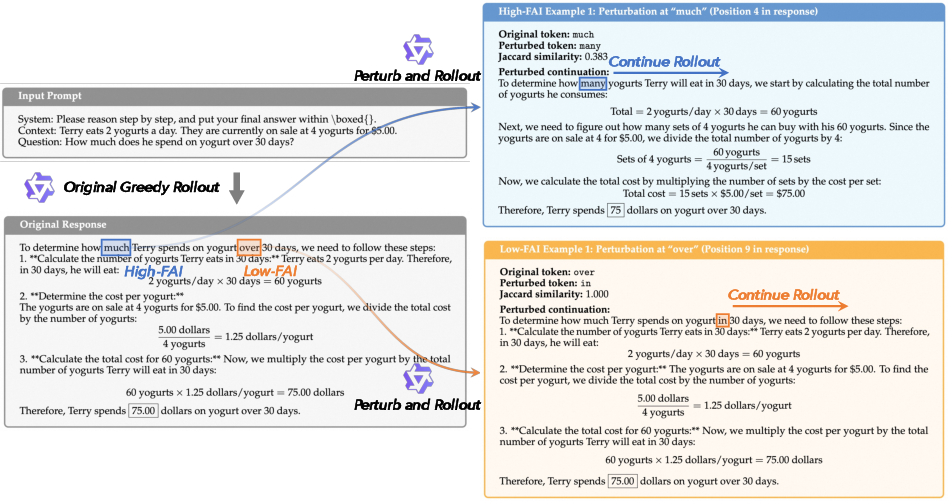
They also ran a simple test: change a high-FAI word (an anchor) and keep generating the answer—does the rest of the solution change? Yes, usually a lot. Change a low-FAI word (just a filler)? The solution often stays the same. That shows anchor words truly direct the reasoning.
Finally, they connect this to training. In normal reinforcement learning (RL), a model gets a reward for a correct final answer, and that reward is spread over all the words it wrote. That’s like giving every play in a game the same credit, even though a few key plays (planning and anchors) mattered most. The authors change this: they give extra training “credit” to just the preplan and anchor moments.
How they applied this in practice:
- They used a fast inference model to generate answers.
- Then they ran one extra quick pass to read out the attention maps (to compute WAAD and FAI).
- They boosted the learning signal on the detected preplan and anchor tokens.
What they found and why it matters
Main findings, explained simply:
- Attention shows a clear pattern: local heads form sawtooth “chunks” (short phrases), while global heads highlight a few anchor tokens that many later tokens keep referencing.
- WAAD spikes (planning moments) usually have higher uncertainty (the model is less sure what’s next), which makes sense—starting a new idea is harder than finishing a phrase.
- Anchor tokens (high FAI) often appear right after a WAAD spike—first plan, then drop the anchor.
- Changing an anchor token changes the whole solution much more than changing a normal token. That confirms anchors truly guide the reasoning.
Training with this insight helps:
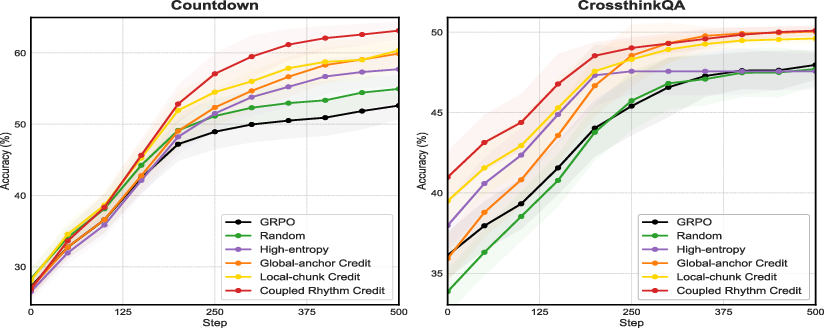
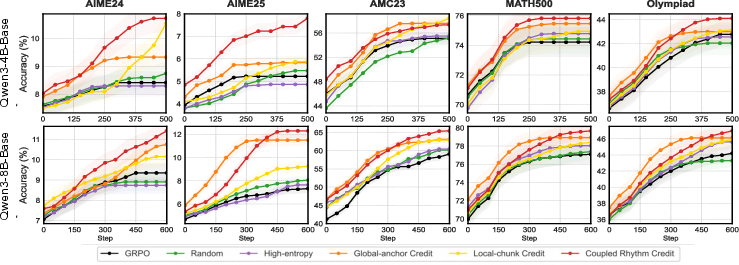
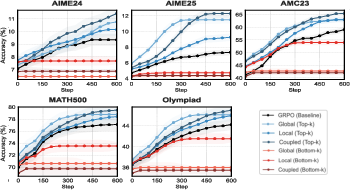
- On a number game (Countdown), their method improved accuracy from 52.6% to 63.1%.
- On a mixed-question set (CrossThink-QA), accuracy went from 48.0% to 50.1%.
- They also report consistent gains on several math reasoning benchmarks.
- Models learned faster and reached higher scores when the training gave extra credit to preplan and anchor tokens.
Why this matters:
- We get a clearer, more mechanical picture of how LLMs structure their reasoning.
- We can train models more efficiently by rewarding the few critical steps that shape the whole answer.
What this could change (implications)
- Smarter training: Instead of treating every word equally, future training can focus on the moments that matter—planning and anchoring—making models learn faster with less data.
- Better reasoning: By strengthening the internal “scaffold” of reasoning (the rhythm of preplan → anchor → develop), models may become more reliable on hard problems like math, coding, and decision-making.
- More transparency: Attention-based signals (WAAD and FAI) make the model’s inner logic more understandable, which could help debugging, safety, and trust.
- General recipe: The idea—detect the model’s own internal landmarks and train around them—could extend beyond math to long texts, planning tasks, and agents.
In short
The model’s attention reveals a two-beat rhythm—preplan then anchor—that organizes its reasoning. If we train with that rhythm in mind, models reason better and learn faster.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is phrased to be concrete and actionable for follow-up research.
- Causal validity of attention as mechanism: Beyond correlational patterns and small-scale token perturbations, rigorously test whether WAAD/FAI capture causal control by (i) head-level ablations (zeroing/pruning “global/local” heads), (ii) activation patching/causal mediation analysis across layers, and (iii) comparing to non-attention causal importance (e.g., gradients, integrated gradients, causal tracing).
- Robustness of the preplan-and-anchor rhythm: Quantify how often WAAD peaks precede FAI peaks across tasks, models, and languages; report the distribution of temporal lags and failure cases where the rhythm does not hold.
- Hyperparameter sensitivity of WAAD/FAI: Provide systematic sweeps for W (window size), Hlo/Hhi (influence horizons), head quantiles for local/global grouping, the number and location of layers sampled, and show stability bands/ablation plots.
- Head-grouping criterion validity: Compare the span-based head grouping to alternative criteria (e.g., column-wise kurtosis, induction/receiver-head detection, learned clustering) and report agreement/disagreement and effects on downstream RL gains.
- Layerwise localization: Map where WAAD/FAI signals are strongest (early/mid/late layers) and whether the identified rhythm shifts with depth; test whether using different layer subsets changes credit assignment impact.
- Tokenization dependence: Examine whether detected anchors are artifacts of tokenizer boundaries (BPE/SentencePiece), test different tokenizers and languages (morphologically rich scripts), and report robustness to re-tokenization.
- Online vs. post-hoc detection: Current method analyzes attention after full generation; investigate online detection during decoding to steer sampling and per-step credit assignment, and quantify latency/quality trade-offs.
- Auxiliary attention model fidelity: Validate that actor_attn attention maps match actor_train/actor_infer behavior (no/low kernel-induced drift); quantify discrepancies and their impact on credit scaling decisions.
- Scaling and systems overhead: Provide concrete throughput/latency measurements (tokens/sec, memory footprint) of the extra attention pass across sequence lengths (1k–32k), model sizes, and cluster scales; characterize bottlenecks.
- Generalization across model families: Evaluate on diverse architectures and sizes (LLaMA/Mistral/MoE, instruction-tuned vs. base, code models) to show whether the rhythm and RL gains persist beyond Qwen3-4B/8B.
- Task breadth and difficulty: Extend beyond math/QA/Countdown to multi-turn dialogue, tool use/agents, code synthesis/repair, long-context retrieval, and multilingual reasoning; report where rhythm-based credit helps or hurts.
- Stronger RL baselines: Compare against competitive token- or step-aware optimization methods (e.g., DAPO/VAPO, token-level reward shaping, PRM-based step rewards, ReST/RLAIF variants, trajectory weighting) under matched setups.
- Evaluation completeness and significance: Report full math benchmark tables (AIME/AMC/MATH500/OlympiadBench) with seeds, confidence intervals, significance testing, and learning curves without EMA-of-peak smoothing.
- End-task impact of perturbations: Replace Jaccard-over-content words with task-relevant causal metrics (answer correctness changes, proof/trace divergences, program execution diffs) and semantic similarity scores; quantify effect sizes.
- Negative-advantage handling: The method only scales nonnegative advantages; investigate how to scale negative advantages (penalize harmful anchors/preplans) and analyze effects on stability/performance.
- Interaction with PPO mechanics: Theoretically and empirically study how per-token γt scaling interacts with PPO clipping, variance, bias, and convergence; test with/without KL/entropy regularization and report behavioral drift.
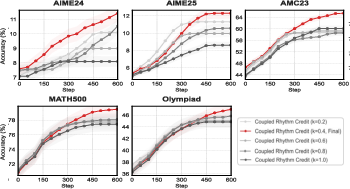
- Credit diffusion heuristics: The coupled rhythm scheme relies on thresholds (τwaad, τΔ), back-allocation window k, α, and γamp; provide sensitivity analyses, automated tuning (Bayesian search), or learnable schedulers/meta-controllers.
- Drift of internal signals during training: Monitor how WAAD/FAI distributions evolve as RL proceeds; assess whether optimization shifts or degrades the rhythm and whether the detection needs adaptive recalibration.
- Attention sinks and artifacts: Control for known artifacts (e.g., positional sinks, BOS/format tokens) to ensure anchors are semantic rather than formatting; add filters or normalization to mitigate sink-induced false positives.
- Human-grounded validation: Collect human annotations of “anchor” or “decision” tokens/phrases and measure precision/recall of FAI peaks; analyze disagreements and refine metrics accordingly.
- Safety and brittleness: Study whether amplifying anchors increases brittleness (over-reliance on specific tokens) or susceptibility to adversarial prompts; evaluate robustness under paraphrase, noise, and adversarial perturbations.
- Exploration–exploitation balance: Examine whether focusing credit on anchors reduces diversity or causes premature convergence; track entropy, diversity, and solution variety over training.
- Long-context effects: Assess WAAD/FAI behavior and RL gains as context length grows (8k–32k), especially where attention becomes more diffuse; test adaptive horizons (Hhi) as a function of sequence length.
- Cross-lingual and domain transfer: Test whether rhythm-aligned policies learned in one domain (math) transfer to others (code, commonsense) and across languages; analyze transferability of anchor/preplan detectors.
- Per-head causal ablations: Remove/attenuate “global” or “local” heads and verify that predicted anchors/preplans lose influence and that RL gains vanish correspondingly, strengthening causal claims.
- Interaction with decoding strategies: Quantify how temperature, nucleus/top-k sampling, and beam search affect WAAD/FAI detection and downstream RL benefits; propose decoding-aware detection adjustments.
- Integration with non-attention signals: Evaluate hybrid detectors that fuse attention with logit entropy, surprise, gradient-based saliency, or value-estimates to improve anchor/preplan identification.
- Credit leakage across chunks: Analyze whether back-allocation spreads credit to unrelated neighboring tokens; add constraints to ensure diffusion remains within the intended chunk boundaries.
- Reproducibility and code: Release exact configs, seeds, and logs for all experiments, including the attention collection pipeline and synchronization schedule, to support replication and ablation by others.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be implemented with current LLM stacks, RLVR pipelines, and standard attention instrumentation.
- Attention-guided RLVR fine-tuning to boost reasoning accuracy (Software/AI infra; Education; Finance)
- Use WAAD/FAI-based token-level credit reweighting with PPO/GRPO to improve math, code, and decision-making performance without architectural changes.
- Tools/products/workflows: Anchor-aware GRPO/PPO plugin (“AnchorRL”), integration into ROLL; auxiliary actor_attn forward pass to compute attention maps; ready-to-use hyperparameters (e.g., WAAD window, FAI horizon).
- Assumptions/dependencies: Verifiable reward signals (RLVR) are available; access to attention weights via an auxiliary model; modest added compute for one attention-forward per sample; effectiveness strongest on tasks with explicit reasoning.
- Attention-driven debugging and interpretability dashboards (Industry; Academia; Regulated sectors like Healthcare/Finance/Legal)
- Visualize WAAD peaks (preplans) and FAI peaks (anchors) to explain why a model took a reasoning turn; identify brittle anchor tokens that cause failure cascades.
- Tools/products/workflows: “AttentionScope” dashboard for WAAD/FAI timelines; “Critical Token Explorer” for counterfactual perturbation and Jaccard-shift reports.
- Assumptions/dependencies: Access to full attention maps or an auxiliary attention pass; standard content-tokenization for similarity metrics.
- Decoding-time steering and compute allocation at critical tokens (Software; Robotics/Agents)
- Dynamically adjust temperature, sampling width, or verification effort at WAAD peaks/high-FAI anchors; budget extra tool calls or self-check steps at anchor points.
- Tools/products/workflows: “Anchor-Steered Decoding” plugin for vLLM; token-budget controller that spikes exploration at preplan peaks and tightens near low-entropy spans.
- Assumptions/dependencies: Access to attention metrics online or via an immediate post-hoc pass; careful latency management.
- Targeted data curation and augmentation (Academia; Industry)
- Enrich training data precisely at anchor/preplan spans (e.g., alternative phrasings of anchor tokens; counterfactuals focused on anchor swaps) to stress-test and strengthen global reasoning control.
- Tools/products/workflows: Data miners that mark anchor/preplan positions; augmentation scripts that create near-miss examples.
- Assumptions/dependencies: Attention metrics computed on candidate samples; alignment with task-specific correctness checks.
- Safety and robustness testing via anchor perturbations (Policy/AI Safety; Industry QA)
- Systematically perturb high-FAI tokens to probe worst-case reasoning shifts and discover prompt-model failure modes earlier.
- Tools/products/workflows: “Anchor Perturbation Test” suite reporting Jaccard-shift and outcome flips; red teaming playbooks focusing on top-FAI positions.
- Assumptions/dependencies: Availability of safe testing sandboxes; clear acceptance criteria (e.g., reward pass/fail, safety constraints).
- Tutoring and explanation tools that highlight key steps (Education; Daily life)
- Mark anchor steps in solutions; surface preplan phrases that set up the next move; help learners see “why” a step matters.
- Tools/products/workflows: Classroom LLM tutors that annotate WAAD/FAI traces; “explain-my-solution” overlays in math/coding apps.
- Assumptions/dependencies: Content is text-based reasoning; attention maps obtainable; privacy-preserving instrumentation for student data.
- Code agent planning aids (Software engineering)
- Detect anchor tokens that reflect API selection, architectural choices, or invariants; add extra verification or human confirmation at those points.
- Tools/products/workflows: IDE plugins that flag anchor tokens in codegen diffs; auto-insert unit tests after anchor decisions (e.g., schema or protocol choice).
- Assumptions/dependencies: Integration with code agents and CI; mapping anchor tokens to code-level decisions.
- Prompt authoring and writing assistants that encourage clear anchors (Daily life; Education; Enterprise knowledge)
- Suggest insertion of concise “anchor sentences” and preplan cues to stabilize downstream generation and reduce meandering.
- Tools/products/workflows: Authoring assistants that detect missing anchors; templates that scaffold preplan→anchor→detail rhythms.
- Assumptions/dependencies: Minimal—can be done with lightweight attention analysis or learned templates.
Long-Term Applications
These opportunities are promising but require further research, scaling, or productization to reach production-grade maturity.
- Standardized interpretability and audit trails based on WAAD/FAI (Policy/Regulation; Compliance)
- Require “anchor traces” in model cards or audit packs, showing which tokens governed decisions and how credit was assigned.
- Tools/products/workflows: Compliance-grade WAAD/FAI reports; certifiable logs of critical-token behavior for regulated deployments (healthcare triage, credit decisions).
- Assumptions/dependencies: Policy consensus on acceptable interpretability standards; efficient, privacy-preserving attention logging at scale.
- Anchor-aware guardrails and human-in-the-loop control (Healthcare; Finance; Robotics/Autonomy)
- Gate high-stakes actions at anchor tokens; pause for human approval or external verification when FAI is high and entropy is non-trivial.
- Tools/products/workflows: “AnchorGuard” middleware that enforces checks at decision anchors; risk-tiered intervention policies.
- Assumptions/dependencies: Reliable mapping from anchor tokens to real decisions; calibrated uncertainty; latency budgets that permit intervention.
- Architecture-level designs that separate “preplan” and “anchor” modules (Core AI research; Software)
- Build layers/heads explicitly specialized for preplanning vs anchoring; train with rhythm-aware losses or auxiliary objectives for reasoning structure.
- Tools/products/workflows: New transformer variants with rhythm constraints; curriculum that alternates preplan formation and anchor consolidation.
- Assumptions/dependencies: Evidence of consistent gains across scales and domains; careful ablations to avoid overfitting to metrics.
- Cross-modal and tool-using extensions (Vision-LLMs; Code; Robotics)
- Generalize WAAD/FAI to multi-modal attention (e.g., “visual anchors”) and tool-use anchors (e.g., when to call a planner or database).
- Tools/products/workflows: Anchor-aware tool routers; VLM tutors that highlight visual/text anchors jointly.
- Assumptions/dependencies: Robust multimodal attention attribution; consistent semantics of anchors across modalities.
- Adaptive compute and scheduling around anchors (AI infra; Energy/Green AI)
- Concentrate training and inference compute on WAAD peaks and high-FAI spans; reduce energy costs by downweighting low-impact tokens.
- Tools/products/workflows: Curriculum schedulers that upsample anchor-rich spans; accelerator kernels optimized for selective attention retention.
- Assumptions/dependencies: Proven end-to-end gains in cost/accuracy; hardware/runtime support for dynamic attention capture.
- Provenance, watermarking, and accountability at critical steps (Policy; Enterprise)
- Watermark anchor decisions, store provenance for post-hoc audits, and attribute responsibility in multi-agent systems.
- Tools/products/workflows: Anchor-level provenance chains; dispute-resolution tools showing where the reasoning turned.
- Assumptions/dependencies: Secure logging infrastructures; legal frameworks recognizing token-level provenance.
- Personalized learning systems that adapt to anchor missteps (Education)
- Diagnose which anchors a learner reliably misses and adapt exercises to those decision points.
- Tools/products/workflows: Student models that map mistakes to anchor types (definition anchors, strategy anchors).
- Assumptions/dependencies: Longitudinal data; privacy and fairness safeguards.
- Safer autonomous decision-making with hierarchical anchoring (Robotics; Logistics; Energy grid ops)
- Use anchors to segment policies into stable subplans; enforce constraints, safety checks, and rollback at anchor boundaries.
- Tools/products/workflows: Hierarchical controllers supervised by anchor-aware critics; simulation-to-real pipelines focusing on anchor reliability.
- Assumptions/dependencies: Robust mapping from textual anchors to control primitives; verification or formal methods integration.
Notes on feasibility and generalization
- The approach depends on obtaining attention maps. In high-throughput settings using FlashAttention, an auxiliary attention model or modified kernels are required.
- WAAD/FAI hyperparameters (window, horizon, thresholds) may need per-task tuning; robustness across languages and domains warrants validation.
- Gains are most evident in tasks with verifiable rewards and explicit reasoning. For open-ended creative tasks, benefits may be smaller or require different reward shaping.
- Care is needed to avoid gaming the metrics (e.g., over-emphasizing stylistic anchors); coupling with correctness/safety signals is essential.
Glossary
- Advantage (RL): The expected improvement signal assigned to actions or tokens, used to scale policy gradients in reinforcement learning updates. "where is the advantage at step , typically estimated via Generalized Advantage Estimation (GAE)"
- Anchor tokens: Tokens with strong downstream influence that the model repeatedly attends to, organizing subsequent reasoning. "globally focused heads highlight a small set of anchor tokens that exert broad downstream influence."
- Attention heads: Independent attention components within a multi-head attention layer, each learning distinct patterns of information flow. "We first distinguish attention heads between locally and globally focused information processing"
- Attention map: The matrix of attention weights showing how each token attends to previous tokens in the sequence. "we obtain attention maps via a single forward pass over the concatenated prompt-response sequence"
- Attention sinks: Tokens (often early) that systematically attract disproportionate attention, potentially due to architectural biases. "Additional phenomena include attention sinks on initial tokens"
- Attention span (average attention span): A measure of how far a head looks back on average, defined as the attention-weighted mean positional distance of its connections. "we classify attention heads as either locally or globally focused based on their average attention span, which we define as the attention-weighted mean positional distance of their attention connections."
- Autoregressive dependence: The constraint that each token can only attend to current and past tokens during generation. "Causal masking enforces autoregressive dependence with"
- Causal attention map: An attention matrix computed under causal masking, restricting attention to past positions. "Let denote the causal attention map for layer and head "
- Causal masking: A mask that prevents attention to future tokens, ensuring autoregressive generation. "Causal masking enforces autoregressive dependence with"
- Clipped surrogate objective: A stabilized PPO objective that clips policy ratios to constrain large updates and maintain training stability. "and optimizes a clipped surrogate objective to constrain divergence between the new and old policies"
- Decoder-only LLM: A LLM architecture that uses only decoder layers to generate tokens autoregressively. "a decoder-only LLM policy autoregressively generates an output sequence"
- Entropy regularization: A training penalty encouraging higher output entropy (exploration), often used to prevent premature convergence. "The loss excludes both KL and entropy regularization."
- Flash attention: A memory-efficient attention algorithm that computes attention without materializing full attention matrices. "typically employ flash attention~\citep{dao2022flashattention} for computational efficiency"
- Future Attention Influence (FAI): A token-level metric measuring the average attention a token receives from future positions, indicating its global importance. "The Future Attention Influence (FAI, Def.~\ref{def:fai)} quantifies a token's global importance by measuring the average attention it receives from later tokens."
- Generalized Advantage Estimation (GAE): A variance-reduced estimator of advantages used to stabilize and improve policy gradient learning. "where is the advantage at step , typically estimated via Generalized Advantage Estimation (GAE)"
- Group Relative Policy Optimization (GRPO): An RL method that normalizes rewards among multiple responses for the same prompt, removing the value function. "Group Relative Policy Optimization (GRPO) eliminates the value function (critic) and instead estimates the advantage by normalizing rewards within a group of sampled responses for the same prompt."
- Importance sampling: A technique to correct for distribution shift between old and new policies when computing policy gradients. "PPO updates on data from a frozen old policy , applies importance sampling to correct distribution shift"
- Jaccard similarity: A set overlap metric (intersection over union) used here to measure similarity between token sets in rollouts. "Jaccard similarity of rollouts for top- and bottom- ranked by FAI."
- KL penalty term: A Kullback–Leibler divergence penalty added to discourage large deviations from a reference policy. "In addition to this modified advantage estimation, GRPO adds a KL penalty term to the clipped objective in Eq.~\ref{eq:ppo_loss}."
- Large Reasoning Models (LRMs): LLMs optimized to generate extended, structured chains of thought for complex tasks. "giving rise to Large Reasoning Models (LRMs) that excel on challenging problems in mathematics"
- Lower-triangular: A matrix property where entries above the main diagonal are zero; in causal attention, disallowing future attention. "Thus, each attention map is lower-triangular and row-stochastic"
- Megatron: A distributed training system enabling efficient large-scale model parallelism for LLMs. "actor_train: implemented in Megatron for efficient large-scale training with model parallelism."
- Multi-head self-attention: An attention mechanism using multiple heads to capture diverse dependencies among tokens. "multi-head self-attention computes head-specific attention maps"
- On-policy rollouts: Sampling trajectories from the current policy during training, as opposed to using off-policy data. "online policy-gradient methods with on-policy rollouts"
- Policy gradient methods: RL algorithms that directly optimize the policy by ascending gradients of expected returns. "Policy gradient methods~\citep{williams1992simple} are a standard approach for solving this optimization problem"
- Proximal Policy Optimization (PPO): A widely used on-policy RL algorithm that stabilizes updates via clipped objectives and trust-region-like constraints. "Proximal Policy Optimization (PPO)~\citep{schulman2017proximal} as the de facto standard"
- Receiver heads: Attention heads identified by selective inbound attention distributions, highlighting tokens heavily attended by future positions. "has identified receiver heads, i.e., attention heads whose inbound attention distribution is highly selective"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setup where rewards are derived from automated, verifiable correctness checks. "A prominent paradigm is Reinforcement Learning with Verifiable Rewards (RLVR)"
- Row-stochastic: A matrix whose rows sum to 1; attention rows represent probability distributions over past positions. "Thus, each attention map is lower-triangular and row-stochastic"
- Semantic anchors: Tokens that serve as stable reference points repeatedly attended to, guiding the global reasoning trajectory. "These tokens function as semantic anchors that are repeatedly revisited and steer unfolding reasoning to a stable frame."
- Token-level entropy: The predictive uncertainty of the next-token distribution at each position, often used to characterize exploration. "Token-level entropy reflects predictive uncertainty and drives reasoning exploration"
- vLLM: A high-throughput inference engine for serving LLMs efficiently with low latency. "actor_infer: deployed with vLLM for high-throughput, low-latency inference"
- Windowed Average Attention Distance (WAAD): A local attention metric measuring how far a token looks back within a clipped window, highlighting chunk boundaries. "The Windowed Average Attention Distance (WAAD, Def.~\ref{def:waad)} measures how far a token looks back within a clipped window"
Collections
Sign up for free to add this paper to one or more collections.