Adam or Gauss-Newton? A Comparative Study In Terms of Basis Alignment and SGD Noise
Abstract: Diagonal preconditioners are computationally feasible approximate to second-order optimizers, which have shown significant promise in accelerating training of deep learning models. Two predominant approaches are based on Adam and Gauss-Newton (GN) methods: the former leverages statistics of current gradients and is the de-factor optimizers for neural networks, and the latter uses the diagonal elements of the Gauss-Newton matrix and underpins some of the recent diagonal optimizers such as Sophia. In this work, we compare these two diagonal preconditioning methods through the lens of two key factors: the choice of basis in the preconditioner, and the impact of gradient noise from mini-batching. To gain insights, we analyze these optimizers on quadratic objectives and logistic regression under all four quadrants. We show that regardless of the basis, there exist instances where Adam outperforms both GN${-1}$ and GN${-1/2}$ in full-batch settings. Conversely, in the stochastic regime, Adam behaves similarly to GN${-1/2}$ for linear regression under a Gaussian data assumption. These theoretical results are supported by empirical studies on both convex and non-convex objectives.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of “Adam or Gauss-Newton? A Comparative Study In Terms of Basis Alignment and SGD Noise”
1) What is this paper about?
This paper compares two popular ways to speed up training neural networks: Adam and Gauss-Newton (GN)-style methods. Both try to make smarter updates by scaling the step taken in each direction of the parameter space. The authors ask: when is Adam better, when is Gauss-Newton better, and what really matters for their performance?
They focus on two key factors:
- The basis (the “coordinate system”) you work in
- The amount of noise in the gradients (caused by using small vs. large batches)
2) What questions are the authors trying to answer?
In everyday terms, the authors want to know:
- Does choosing the right “coordinate system” (basis) make a big difference?
- How does randomness from small batches affect which optimizer works best?
- Is Adam doing something special, or is it just a practical shortcut to a curvature-aware method like Gauss-Newton?
- Should GN scale steps by 1/curvature or by 1/sqrt(curvature)? Which is better?
3) How did they study it? (Methods in simple terms)
Think of training as hiking down a bumpy landscape to reach the lowest point (the minimum).
- “Curvature” tells you how steep and twisty the land is in different directions.
- A “preconditioner” is like smart hiking boots that adjust your stride length differently in each direction so you don’t overshoot or get stuck.
Key ideas explained:
- Basis (coordinate system): Sometimes it’s easier to move if you rotate your map so that the axes line up with the hills and valleys. The “eigenbasis” is that ideal rotated map; the “identity basis” is the default, unrotated map.
- Adam: Scales steps using past gradient sizes. It’s like automatically taking smaller steps where the ground tends to be steep. It uses gradient statistics rather than exact curvature.
- Gauss-Newton (GN): Scales steps using estimated curvature. This is more like using a topographical map. They try two strengths of scaling: 1/curvature (GN-1) and 1/sqrt(curvature) (GN-1/2).
- Gradient noise: If you use tiny batches (like 1 sample), your gradient is noisy (a shaky compass). With full batches, it’s stable.
Approach:
- They analyze two simple, math-friendly problems:
- Linear regression (a smooth, “quadratic” landscape)
- Logistic regression (a bit more complex and can be non-convex with their setup)
- They test four scenarios: right vs. wrong basis, and large (full) vs. small (stochastic) batch.
- They back up the theory with experiments on small toy problems and real models (MLPs, CIFAR10, Transformers).
4) What did they find, and why does it matter?
The big picture: performance depends heavily on both basis choice and gradient noise.
- Basis matters a lot
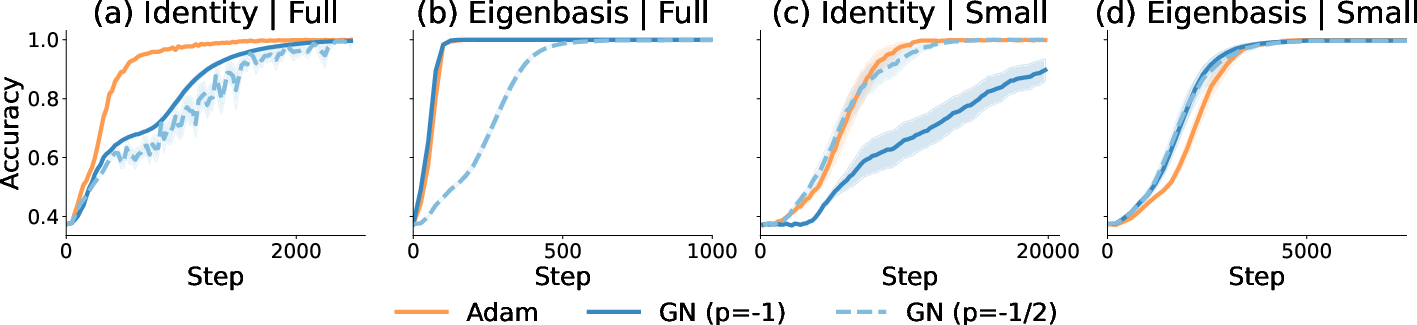
- In the right basis (eigenbasis), GN-1 is great for simple quadratic problems (linear regression). It can even be optimal in theory.
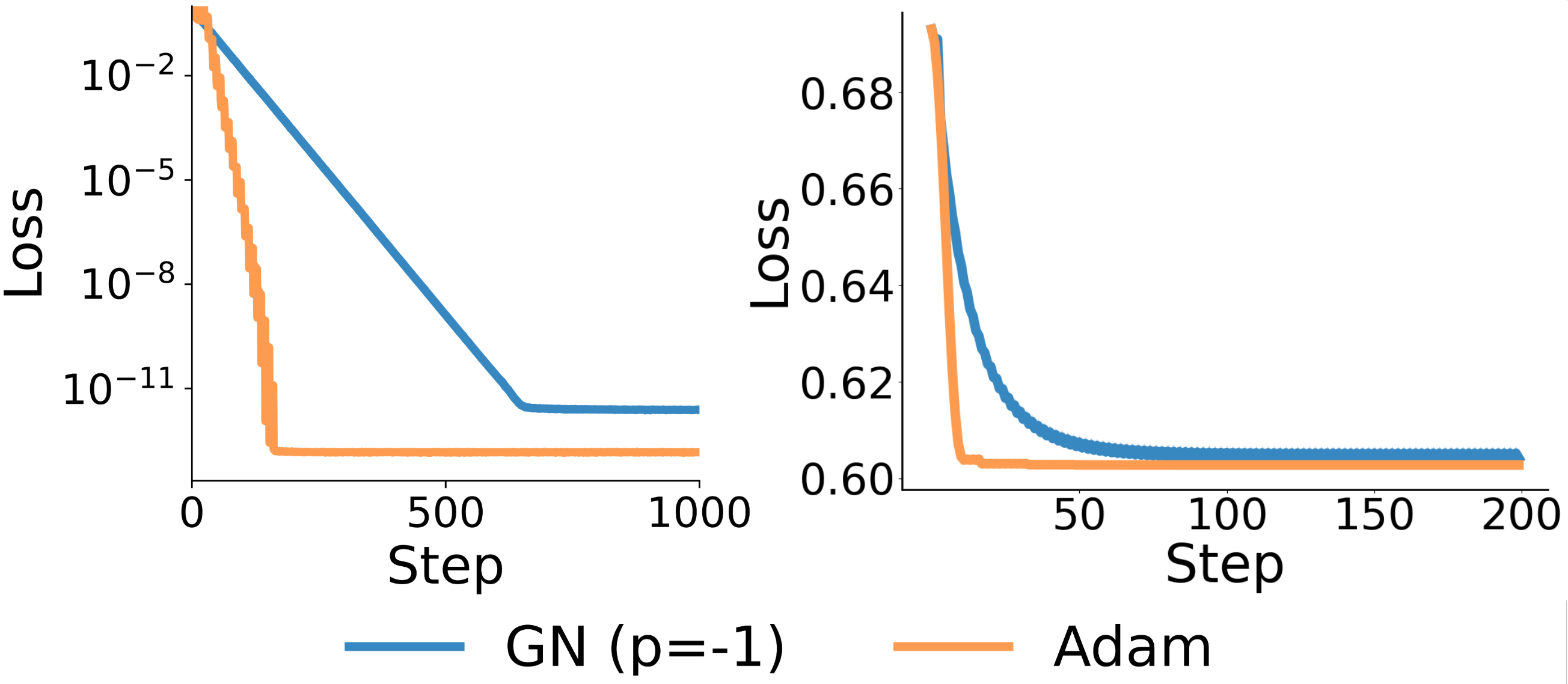
- In the wrong basis (identity), GN can lose its advantage. In fact, Adam (and often GN-1/2) can beat GN-1 in full-batch settings because Adam “auto-tunes” its step sizes to match the local steepness.
- Noise changes the game
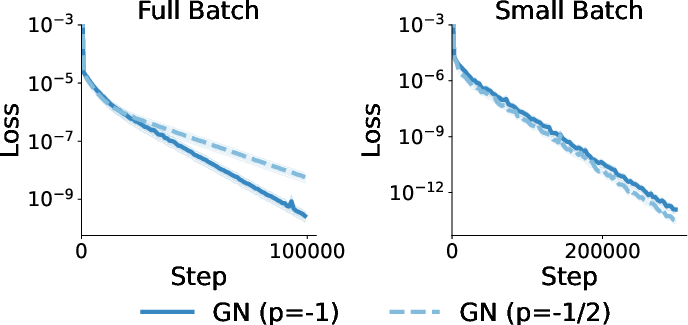
- With small, noisy batches, Adam behaves similarly to GN-1/2 for linear regression with Gaussian data, no matter which basis you use.
- Translation: in noisy training, Adam ≈ GN-1/2. That helps explain why Adam works so well in practice.
- Adam’s “auto-tuning” effect in full-batch
- When gradients are stable (large batches), Adam naturally adjusts how big each step should be in each direction. This can rescue performance when the basis is misaligned, letting Adam outperform GN-1 in some cases.
- Which GN power is better: -1 or -1/2?
- In the ideal basis, GN-1 is theoretically best for quadratics.
- In the wrong basis, GN-1/2 can sometimes converge faster than GN-1 because it leads to a better-conditioned (more balanced) update step.
- Logistic regression twist (even in the right basis)
- For a logistic-like setup, Adam can beat GN-1 even in the eigenbasis with full batches. Why? To stay stable globally (not blow up), GN-1 may need very small step sizes, which slows it down locally. Adam avoids that bottleneck.
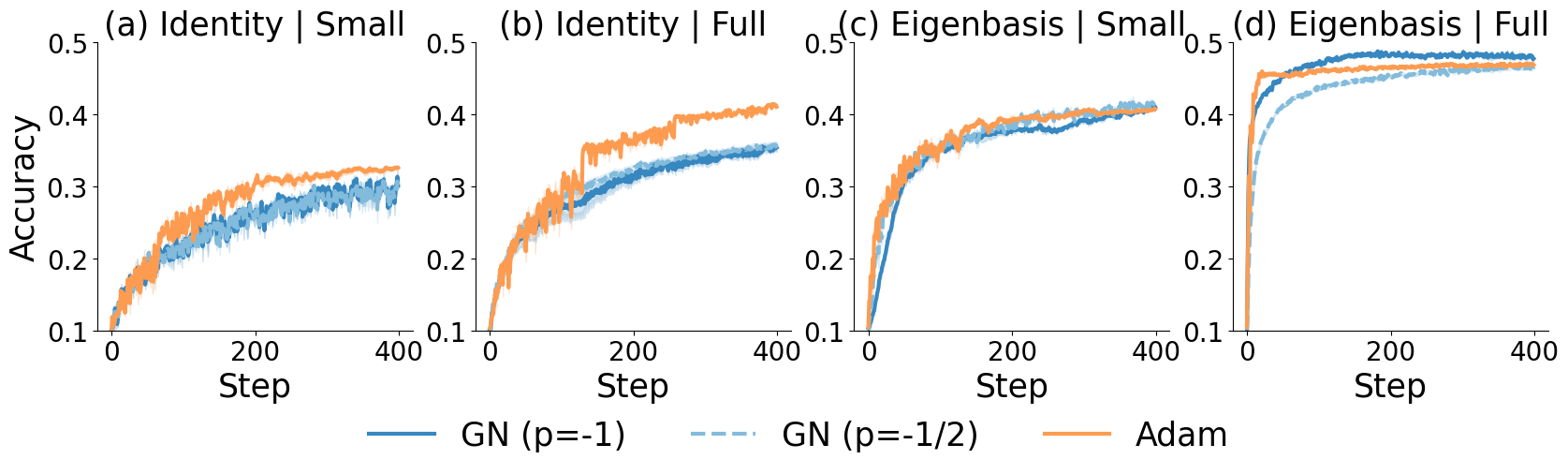
- Experiments agree
- Across linear/quadratic tests, non-convex MLPs, CIFAR10, and Transformers, the patterns match the theory:
- Full batch + wrong basis: Adam often faster than GN-1
- Small batch (stochastic): Adam ≈ GN-1/2
- Logistic-like tasks: Adam can outperform GN-1 even in the right basis
5) What does this mean going forward?
- Separate two design choices: which basis to use, and how to scale in that basis. A good basis (like a curvature-aware eigenbasis) helps, but the diagonal scaling rule still matters.
- In noisy training (common in practice), Adam’s behavior is close to GN-1/2. This suggests Adam isn’t just a hack—it’s aligned with a curvature-aware idea, especially when data is noisy.
- When batches are large, Adam’s auto-tuning can be a strong advantage, especially if you don’t have the perfect basis.
- Practical tip: Optimizers that combine a smart basis (curvature-aware) with Adam-like scaling may be very effective. This connects to recent methods that run Adam in a transformed (curvature-informed) basis.
- Future direction: Build new optimizers that keep Adam’s auto-tuning benefits even at small batch sizes, while retaining curvature awareness.
In short: picking the right coordinate system and understanding gradient noise are just as important as picking the optimizer itself. Adam shines when the basis isn’t ideal or when batches are large; in noisy settings, it naturally acts like a milder, robust version of Gauss-Newton.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide follow-up research.
- Theory limited to special cases
- Adam ≈ GN is proved only for linear regression with Gaussian inputs and batch size 1; it is unknown whether similar equivalences hold for:
- non-Gaussian, heavy-tailed, or structured inputs;
- generalized linear models beyond quadratics/logistic regression;
- deep nonlinear networks (beyond the special reparameterized logistic example).
- The logistic-regression separation relies on a particular parameterization (squared weights with weight tying), one-hot inputs, and imbalance; it is unclear how broadly these conclusions transfer to standard architectures and data distributions.
- Batch-size dependence is not fully characterized
- Results focus on the two extremes (full-batch vs batch size 1); a precise theory for intermediate batch sizes (transition regimes where mean vs variance terms dominate Adam’s denominator) is missing, including:
- explicit dependence of convergence rates and equivalence constants on ;
- sharp thresholds delineating “auto-tuning” from “variance-dominated” behavior.
- Basis alignment is only partially understood
- Theoretical guarantees are given for perfectly aligned (GN eigenbasis) and misaligned (identity) bases, but there is no quantitative characterization as a function of partial alignment (e.g., principal angles between the working basis and GN eigenvectors).
- The effect of approximate bases (e.g., Kronecker-factored or low-rank approximations) lacks a formal analysis quantifying degradation in convergence relative to exact eigenbases.
- Choice of GN power remains heuristic
- The paper shows existence of cases where GN outperforms GN under misalignment, but there is no decision rule or adaptive mechanism to choose the exponent based on observable signals (e.g., estimated condition number or alignment metrics).
- No analysis for a continuous family GN (beyond ), or for how the optimal depends on curvature heterogeneity and basis mismatch.
- Step-size and damping policies for GN are under-specified
- The lower bound for GN in logistic regression assumes non-increasing step sizes and a fixed regularization; it remains open whether:
- line search, trust-region, or adaptive damping can recover fast local convergence without compromising global stability;
- one can design globally convergent schedules that avoid the identified slowdown while being practical in deep learning.
- There is no principled guidance for selecting the preconditioner regularization (damping) beyond grid search.
- Adam modeling abstractions omit important practical features
- The analyses largely ignore Adam’s momentum (), bias correction, and decoupled weight decay; the impact of these features on the Adam ≈ GN relation and on the “auto-tuning” effect is unaddressed.
- The “auto-tuning” effect is argued heuristically; formal conditions and finite-time guarantees quantifying burn-in, stability, and curvature tracking are missing.
- Stochastic-regime guarantees are coarse
- Convergence results (e.g., Lemma on preconditioned rates) are in big-O form and in expectation; high-probability bounds with explicit constants (and dimension dependence) are not provided.
- The assumption that gradient covariance is tied to the current iterate in a specific way (Gaussian linear setting) may fail in deep networks; robustness to iterate-dependent and state-dependent noise is unstudied.
- Empirical scope and scaling considerations
- Experiments validate trends on modest-scale MLPs/Transformers and CIFAR10; whether the observed Adam ≈ GN equivalence and basis effects persist at large foundation-model scales (with realistic pipelines, mixed precision, and distributed training) remains untested.
- No wall-clock, memory, or energy comparisons quantify the practical trade-offs of estimating GN eigenbases (or K-FAC approximations) versus running standard Adam; guidance for when the extra overhead is justified is lacking.
- Basis update frequency, batch reuse (separate batches for gradients vs basis), and staleness effects are not systematically studied or optimized.
- Fisher vs empirical Fisher beyond linear-Gaussian settings
- The paper proves equivalence up to scaling for linear-Gaussian regression; it is unclear:
- under what conditions (e.g., sub-Gaussian tails, bounded kurtosis, calibration conditions) empirical Fisher aligns with Fisher in general models;
- how model misspecification or label noise affects the empirical Fisher vs GN preconditioning gap.
- Generalization and implicit bias are not addressed
- The study focuses on optimization speed; whether the choice of basis and preconditioner (Adam vs GN) induces different implicit biases and generalization behaviors is unexplored.
- Non-convex theory is largely absent
- Beyond the tailored logistic example, there is no general non-convex analysis (e.g., for wide networks/NTK regime or PL conditions) characterizing when Adam or GN provides provable advantages.
- Interactions with modern architectures and tricks
- The impact of normalization layers (LayerNorm/BatchNorm), residual connections, attention sparsity, gradient clipping, and parameter sharing on basis alignment and preconditioner efficacy is not analyzed.
- Layerwise or block-diagonal preconditioning choices, and their interaction with basis alignment, are not theoretically characterized.
- Design of hybrid or new optimizers is left open
- The paper hints at combining Adam’s auto-tuning benefits in large-batch regimes with GN-like behavior in small-batch regimes but does not propose or evaluate concrete algorithms that adaptively transition across regimes or select bases/exponents online.
Glossary
- Adam: An adaptive first-order optimizer that scales updates using running averages of gradient moments, often interpreted as preconditioning by empirical second-order statistics. "runs Adam in Shampoo's eigenbasis."
- Adafactor: An optimizer that uses adaptive learning rates with sublinear memory by factorizing second moment estimates, enabling efficient large-scale training. "Adafactor~\citep{shazeer2018adafactor}"
- Auto-tuning: The phenomenon where an optimizer (e.g., Adam) implicitly adjusts effective learning rates across coordinates by normalizing with gradient magnitudes, adapting to curvature without explicit second-order information. "We refer to this as the auto-tuning of Adam"
- Condition number: A measure of the ill-conditioning of a matrix (e.g., Hessian or preconditioned Hessian) that governs convergence speed; higher values typically slow optimization. "depends on the condition number, similar to \Cref{lem:precond_loss_rate}."
- Diagonal preconditioner: A preconditioning matrix that is diagonal in a chosen basis, scaling each coordinate independently to improve optimization efficiency. "Diagonal preconditioners are computationally feasible approximate to second-order optimizers"
- Eigenbasis: A basis formed by the eigenvectors of a matrix (e.g., Gauss-Newton), in which diagonal preconditioning can align with curvature directions. "the eigenbasis of the GN matrix"
- Eigendecomposition: The factorization of a matrix into its eigenvalues and eigenvectors, enabling analysis and preconditioning in curvature-aligned coordinates. "admits a real-valued eigendecomposition."
- Empirical Fisher matrix: The expected outer product of per-example gradients computed with respect to true labels; used by adaptive methods like Adam as a proxy for curvature. "correspond respectively to empirical Fisher matrix and the Fisher matrix."
- Fisher matrix: The expected outer product of gradients with respect to the model’s output distribution; serves as a curvature measure linked to natural gradient and Gauss-Newton methods. "correspond respectively to empirical Fisher matrix and the Fisher matrix."
- Gauss-Newton (GN) matrix: A positive-semidefinite approximation to the Hessian derived from first-order information, often used for second-order preconditioning. "the diagonal of the Gauss-Newton (GN) matrix"
- Hutchinson estimator: A randomized method to estimate traces or diagonals of large matrices (e.g., Hessian), used when exact second-order computation is infeasible. "the other commonly used Hutchinson estimator."
- Kronecker approximation: Approximating a large curvature matrix as a Kronecker product of smaller factors to reduce computation. "while adopting the Kronecker approximation in the experiments"
- Kronecker factorization: Factorizing curvature matrices into Kronecker products (e.g., K-FAC) to capture layerwise structure efficiently. "one can use the Kronecker factorization in place of the full basis"
- Kronecker-factored preconditioner: A preconditioner built from Kronecker-factored curvature estimates, providing a tractable approximation of the full eigenbasis. "we additionally consider the Kronecker-factored preconditioner~\citep{martens15KFAC,vyas2024soap} as a computationally efficient approximation of the eigenbasis"
- Local contraction factor: The spectral norm of the local iteration matrix that characterizes the ultimate linear convergence rate near an optimum. "We refer to $\spectralRad(\lr[\infty],\reg)$ as the local contraction factor"
- Natural gradient descent: A second-order optimization method that rescales gradients using the Fisher information metric to follow the geometry of the parameter space. "such as Newton's and natural gradient descent"
- Normalized gradient descent: A gradient method that scales updates by (a function of) the gradient norm, reducing sensitivity to curvature and step-size choice. "a property of normalized gradient descent"
- Positive-semidefinite (PSD): A matrix whose eigenvalues are non-negative; ensures well-defined curvature directions for preconditioning. "the GN term is positive-semidefinite (PSD)"
- Preconditioned Hessian: The effective curvature matrix after applying a preconditioner, whose condition number dictates the convergence rate of preconditioned gradient descent. "depends on the condition number of the preconditioned Hessian."
- Preconditioning: Transforming gradients by a matrix (often diagonal in a chosen basis) to improve conditioning and accelerate convergence. "brings the preconditioning closer to a second-order interpretation"
- Regularization coefficient: A small positive constant added to preconditioners (e.g., inverting GN) to stabilize computations and ensure convergence. "regularization coefficient "
- Shampoo: An optimizer that builds matrix preconditioners from second-moment estimates and can be viewed as applying diagonal scaling in a transformed basis. "Shampoo's eigenbasis"
- SOAP: An optimizer that executes Adam updates in the eigenbasis estimated by Shampoo, decoupling basis choice from diagonal scaling. "proposed an optimizer called SOAP that runs Adam in Shampoo's eigenbasis."
- Spectral radius: The largest absolute eigenvalue of a matrix; near-optimal local rates require the iteration matrix’s spectral radius to be small. "We are interested in lower bounding the spectral radius of the local iteration matrix:"
- Stochastic regime: The small-batch or single-sample setting where gradient noise dominates, affecting how preconditioners like Adam and GN behave. "in the stochastic regime"
Practical Applications
Immediate Applications
The following items summarize practical, deployable applications that can be implemented now, leveraging the paper’s findings on basis choice and gradient noise for diagonal preconditioners.
- Basis-aware optimizer selection in ML training pipelines
- What to do: Choose optimizers based on batch size and basis alignment.
- Large/full-batch phases (population gradient dominates): Prefer Adam for its auto-tuning behavior; avoid GN⁻¹ in identity basis.
- Small-batch phases (variance dominates): Adam behaves similarly to GN⁻¹ᐟ²; either is fine; avoid GN⁻¹ unless operating in a well-estimated eigenbasis.
- Sector: Software/AI; education (course labs).
- Tools/products: Drop-in PyTorch/TF utilities that automatically select Adam or GN⁻¹ᐟ² based on batch size.
- Dependencies/assumptions: Requires knowledge of batch size; full-batch setting for auto-tuning benefits; computing GN in the identity basis erodes advantages.
- Kronecker-factored eigenbasis preconditioning in practice
- What to do: Use KFAC-style eigenbasis approximations to apply diagonal preconditioning in a curvature-informed basis without full eigendecomposition cost.
- Sector: Software/AI; robotics (resource-constrained training).
- Tools/products: Optimizer plugin that exposes a “basis” knob (Identity vs KFAC Eigenbasis) and a “diagonal scaling” knob (Adam vs GN with power −½ or −1).
- Dependencies/assumptions: KFAC approximations must be stable per-layer; additional memory/compute overhead; regularization for numerical stability.
- Optimizer power selection: Prefer GN⁻¹ᐟ² when basis may be misaligned
- What to do: Under identity or imperfect bases, choose GN⁻¹ᐟ² over GN⁻¹ to improve convergence (condition-number considerations).
- Sector: Software/AI; finance (streaming models), healthcare (smaller batch training).
- Tools/products: Configurable Sophia-like variants that support power = −½; scripts to compare GN powers per-task.
- Dependencies/assumptions: Condition-number benefits depend on data covariance; small-batch regimes make Adam ≈ GN⁻¹ᐟ².
- Regime-aware training workflows (staging optimizers across phases)
- What to do: Use Adam in early large-batch pretraining (auto-tuning), then continue with Adam or switch to GN⁻¹ᐟ² in small-batch fine-tuning.
- Sector: Software/AI; energy/compute efficiency for industry training runs.
- Tools/products: Training recipes in MLOps platforms (e.g., MLFlow) with stage-specific optimizer defaults; built-in schedules (step decay).
- Dependencies/assumptions: Requires monitoring of gradient mean vs variance; transition points driven by batch size or noise metrics.
- Attention-heavy models (Transformer modules): Prefer Adam in full-batch eigenbasis
- What to do: For logistic-like structures (e.g., self-attention), avoid GN⁻¹ even in eigenbasis during full-batch operations; use Adam with non-increasing step sizes to ensure fast and stable convergence.
- Sector: Software/AI (NLP, vision Transformers).
- Tools/products: Predefined optimizer presets for attention blocks; layer-wise optimizer assignment.
- Dependencies/assumptions: Non-increasing step-size schedules; local convergence properties rely on problem conditioning and initialization.
- Optimizer diagnostics: Gradient noise and basis-alignment monitoring
- What to do: Track per-basis gradient mean vs variance and approximate alignment; use these diagnostics to decide optimizer and power.
- Sector: Software/AI; academia (experimental methodology).
- Tools/products: “NoiseMeter” module that estimates E[g]² vs Var(g) per layer; alignment metrics for GN eigenbasis; dashboard integrations.
- Dependencies/assumptions: Access to per-example gradients or mini-batch statistics; added compute to estimate GN/KFAC.
- Reduced hyperparameter sweeps via auto-tuning
- What to do: Use Adam in large-batch settings to benefit from auto-tuning of effective step size, reducing LR sweep effort.
- Sector: Software/AI; AutoML.
- Tools/products: AutoML pipelines with optimizer-stage presets and narrower LR search ranges.
- Dependencies/assumptions: Full-batch or large-batch regimes where mean gradient dominates; standard Adam settings (e.g., β₂ tuned, β₁ possibly set to 0 for clarity).
- Energy-efficient training best practices
- What to do: Select optimizers to reduce wall-clock and energy usage (Adam for large batches; Adam or GN⁻¹ᐟ² for small batches), minimizing wasted epochs under misaligned bases.
- Sector: Energy; policy for “Green AI.”
- Tools/products: Internal guidance documents and checklists for enterprise training runs; standardized optimizer reporting.
- Dependencies/assumptions: Organization-wide adoption; consistent logging; simple rules-of-thumb applied to workloads.
Long-Term Applications
These items suggest applications that need further research, scaling, or development before widespread deployment.
- Variance- and basis-aware adaptive optimizers
- What to build: New optimizers that dynamically adjust (i) basis (Identity/KFAC/learned eigenbasis), (ii) diagonal scaling source (Adam/Empirical Fisher vs GN/Fisher), and (iii) power (continuously between −1 and −½) based on observed noise and curvature.
- Sector: Software/AI; robotics (continual learning), finance (streaming), healthcare (online adaptation).
- Tools/products: A “BasisSplit Optimizer” that auto-switches per-layer and per-phase; runtime controllers that tune power and basis; per-layer schedulers.
- Dependencies/assumptions: Reliable online estimation of GN/Fisher; stable basis updates; low overhead; robust regularization and damping.
- Scalable eigenbasis learning and integration into distributed training
- What to build: Efficient, distributed estimation of curvature bases (beyond KFAC), integrated with sharded training; selectively update basis for critical layers (attention, MLP heads).
- Sector: Software/AI; energy/compute efficiency.
- Tools/products: Curvature service in training frameworks (e.g., parameter-server-like module); APIs in PyTorch/TF/XLA for basis updates; caching and amortization strategies.
- Dependencies/assumptions: Communication overhead tolerable; numerically stable eigendecompositions/factorizations; hardware-friendly kernels.
- Hybrid optimizers for attention/logistic-like modules
- What to build: Attention-specific optimizer presets that detect logistic-like behavior and enforce Adam in full-batch; enable GN⁻¹ᐟ² in small-batch fine-tuning.
- Sector: Software/AI (LLMs, ViTs).
- Tools/products: Layer-type-aware optimizer management; compiler passes that annotate layers with recommended optimizer behavior.
- Dependencies/assumptions: Accurate detection/annotation of layer behavior; consistency across models; integration with training orchestration.
- Theory-to-practice expansion for non-convex deep networks
- What to research: Extend proofs connecting Adam and GN⁻¹ᐟ² in stochastic regimes to deep, non-convex settings; characterize when GN⁻¹ loses optimality even in eigenbasis beyond logistic cases; develop guarantees for mixed-basis and multi-power schedules.
- Sector: Academia; software/AI.
- Tools/products: Benchmarks and reproducible suites covering the 2×2 grid (basis × batch size) across architectures; standardized reporting templates.
- Dependencies/assumptions: New theoretical tools; reliable empirical replication; careful isolation of confounders.
- Optimizer reporting standards and policy guidance
- What to build: Community standards to report optimizer choice, basis, batch size, and estimated energy; promote transparent, comparable results and greener training practices.
- Sector: Policy; energy; academia.
- Tools/products: Checklists for papers and industry reports; model cards including optimizer-basis-batch disclosures; guidance from standards bodies (e.g., IEEE/ACM).
- Dependencies/assumptions: Broad community buy-in; alignment with reproducibility goals; tooling for easy reporting.
- Hardware-software co-design for preconditioned updates
- What to build: Accelerator kernels optimized for diagonal preconditioners in learned/KFAC bases; efficient per-example gradient statistics collection.
- Sector: Semiconductors; software/AI.
- Tools/products: Library support for efficient GN/Fisher estimation; mixed-precision routines that preserve stability for GN powers; memory-aware batching.
- Dependencies/assumptions: Hardware support for matrix factorizations; robust numerical methods; cost-benefit validated in production.
- Curriculum and workforce upskilling on basis- and noise-aware optimization
- What to build: Educational materials explaining the decomposition of basis vs diagonal scaling; practical guidelines for optimizer selection and scheduling.
- Sector: Education; industry training programs.
- Tools/products: Short courses, labs, and internal training sessions; interactive notebooks demonstrating the 2×2 grid behavior.
- Dependencies/assumptions: Access to compute for demos; alignment with current ML engineering practices.
Key Assumptions and Dependencies Across Applications
- Equivalence claims (Adam ≈ GN⁻¹ᐟ²) are strongest under Gaussian inputs and quadratic losses; empirical alignment holds widely but may vary with data/model specifics.
- Adam’s auto-tuning advantage is tied to large/full-batch regimes where mean gradient dominates variance; small batches diminish this effect.
- GN’s sensitivity to basis misalignment is significant; curvature-informed bases are beneficial but have computation and stability costs.
- Non-increasing step sizes are assumed for some logistic regression results; line search may alter conclusions.
- Practical eigenbasis estimation relies on KFAC or related approximations; full eigenbasis is typically infeasible at scale.
- Regularization/damping terms are required for numerical stability in GN-based updates.
- Per-example gradient statistics may be needed to estimate noise; incurs compute/memory overhead.
These applications aim to make optimizer choice and design more principled by decoupling basis selection from diagonal scaling, and by explicitly accounting for gradient noise regimes.
Collections
Sign up for free to add this paper to one or more collections.