- The paper demonstrates that changes in sampling parameters significantly impact the detectability of machine-generated texts, revealing critical vulnerabilities in both supervised and unsupervised detectors.
- It utilizes a large-scale benchmark with 37 decoding configurations on Llama-3.2-3B and employs lexical diversity metrics like MTLD and Hapax Legomena Ratio to quantify text characteristics.
- The findings indicate that minor tweaks in decoding strategies can drastically reduce detection performance, underscoring the need for more robust and adaptive artificial text detection systems.
Sampling-based Decoding and the Detectability of Machine-generated Texts
Introduction
This paper presents a systematic investigation into the impact of sampling-based decoding strategies on the detectability of machine-generated texts. The authors address a critical gap in the evaluation of Artificial Text Detection (ATD) systems: the sensitivity of detectors to variations in generation parameters such as temperature, top-p, top-k, repetition penalty, typical sampling, and n-sampling. By constructing a large-scale benchmark with 37 decoding configurations using Llama-3.2-3B, the study exposes significant vulnerabilities in both supervised and unsupervised detection methods, challenging the robustness claims of current state-of-the-art systems.
Decoding Strategies and Lexical Diversity
The paper formalizes six major sampling adapters, each transforming the base output distribution of a LLM:
- Temperature Sampling: Modulates the sharpness of the distribution; T=1 yields ancestral sampling, T→0 approaches greedy decoding.
- Repetition Penalty: Reduces the probability of previously generated tokens, promoting diversity.
- Top-p (Nucleus) Sampling: Restricts token selection to the smallest set whose cumulative probability exceeds p.
- Top-k Sampling: Limits generation to the k most probable tokens.
- Typical Sampling: Selects tokens closest to the local entropy.
- n-sampling: Chooses tokens above a context-dependent probability threshold.
Lexical diversity metrics (MTLD, Hapax Legomena Ratio, Simpson's Index, Zipfian Exponent, Heaps' Law) are used to quantify the statistical properties of generated texts. The study finds that certain parameter regimes (e.g., n=10−4, T=1.0, k=100, p=0.95, typical=0.95) yield outputs closely matching human diversity, while extreme values produce either repetitive or nonsensical text.
Impact of Sampling on Detection Accuracy
Supervised Detection
Supervised detectors, typically RoBERTa-based classifiers, exhibit high accuracy when trained and tested on data generated with similar sampling parameters. However, cross-parameter generalization is poor, especially for repetition penalty and high-temperature settings. Training on a mixture of parameter settings improves robustness, but even minor domain shifts in human data (e.g., switching news sources) cause accuracy to drop from 94% to 72%, indicating overfitting to the training distribution.
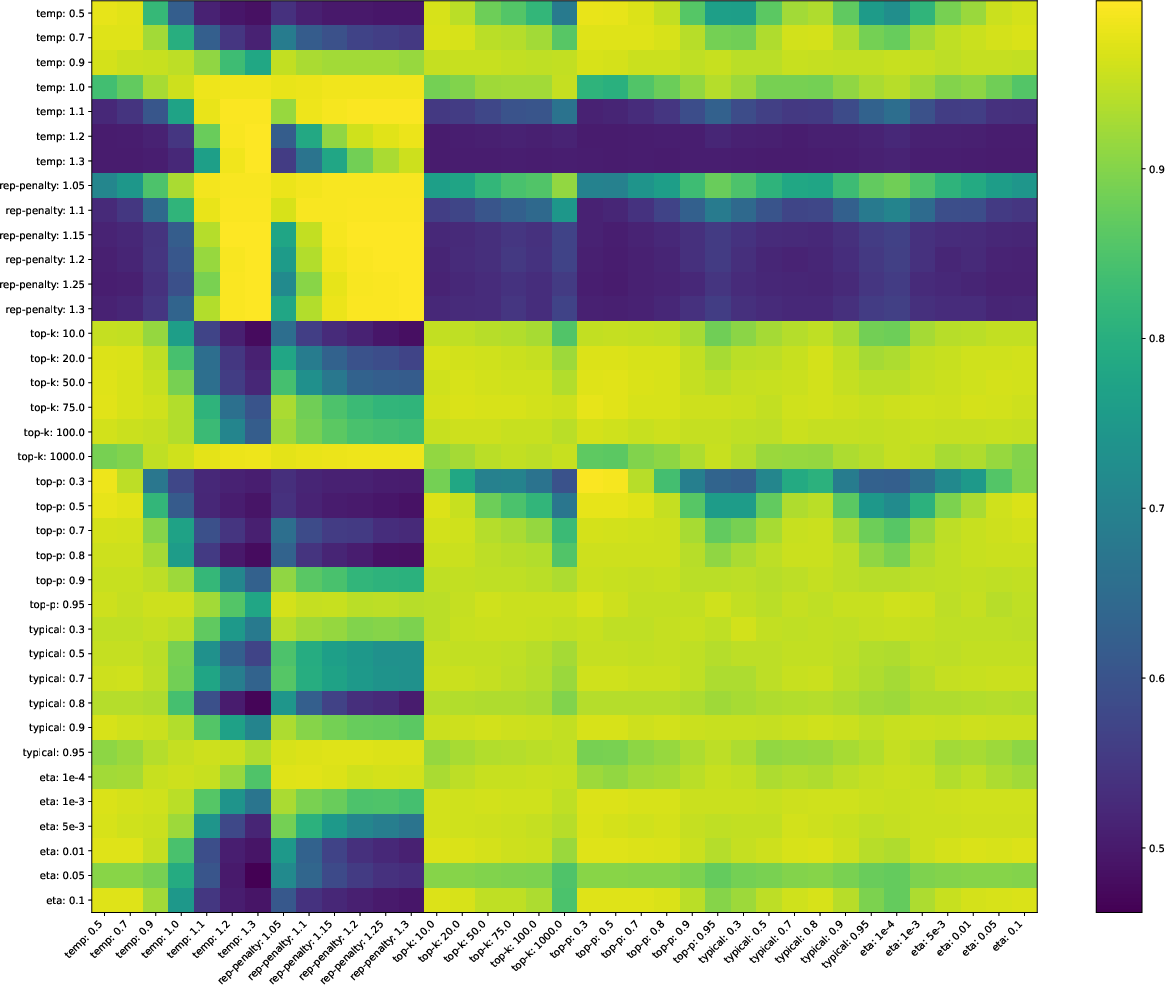
Figure 1: Heatmap of supervised detection accuracy across training and testing parameter configurations, revealing poor generalization for mismatched sampling strategies.
Unsupervised Detection
Unsupervised methods (Binoculars, FastDetectGPT) rely on surprisal and cross-entropy differences between detector models. These systems are highly sensitive to the alignment of the detector and generator distributions. For certain sampling adapters (notably repetition penalty and T>1), AUROC drops precipitously, sometimes to near 0.01, indicating complete failure to distinguish human from machine-generated text.
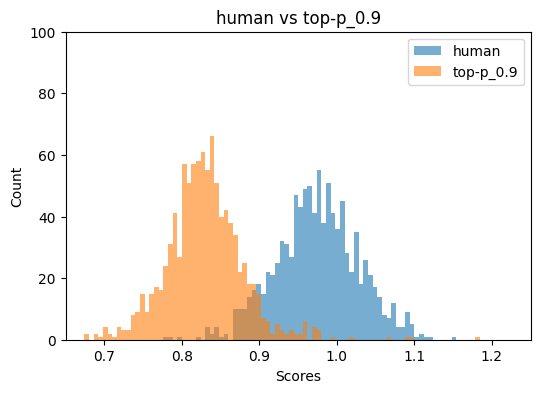
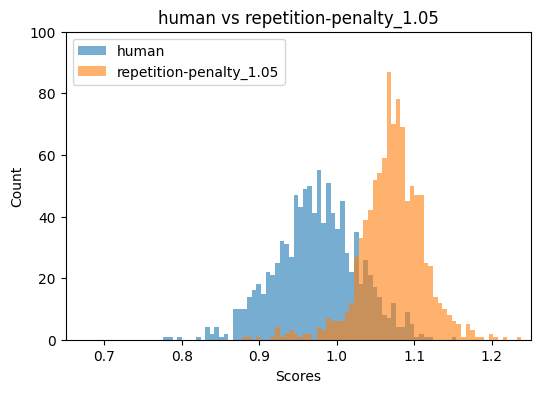
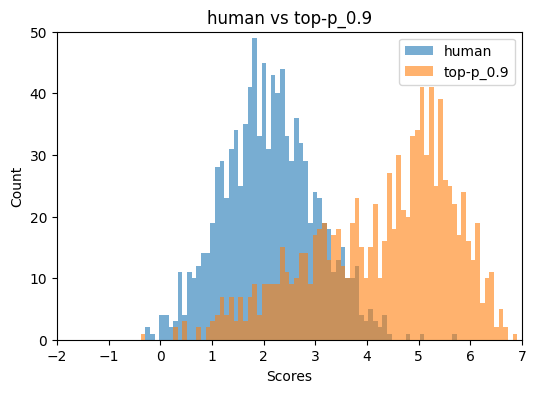
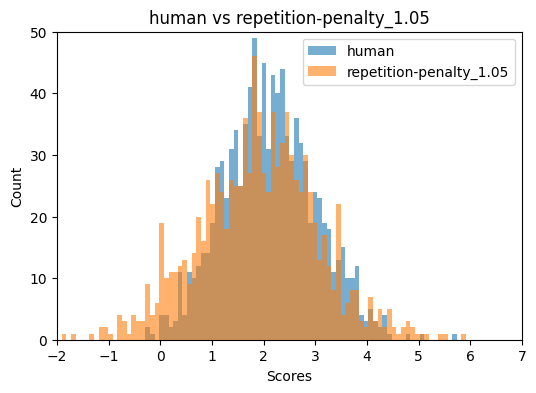
Figure 2: Binoculars and FastDetectGPT score distributions for top-p=0.9 and repetition penalty=1.05, illustrating detector breakdown under specific sampling regimes.
Mixture models, which average over multiple decoding-induced distributions, offer marginal improvements but do not resolve failures for problematic adapters.
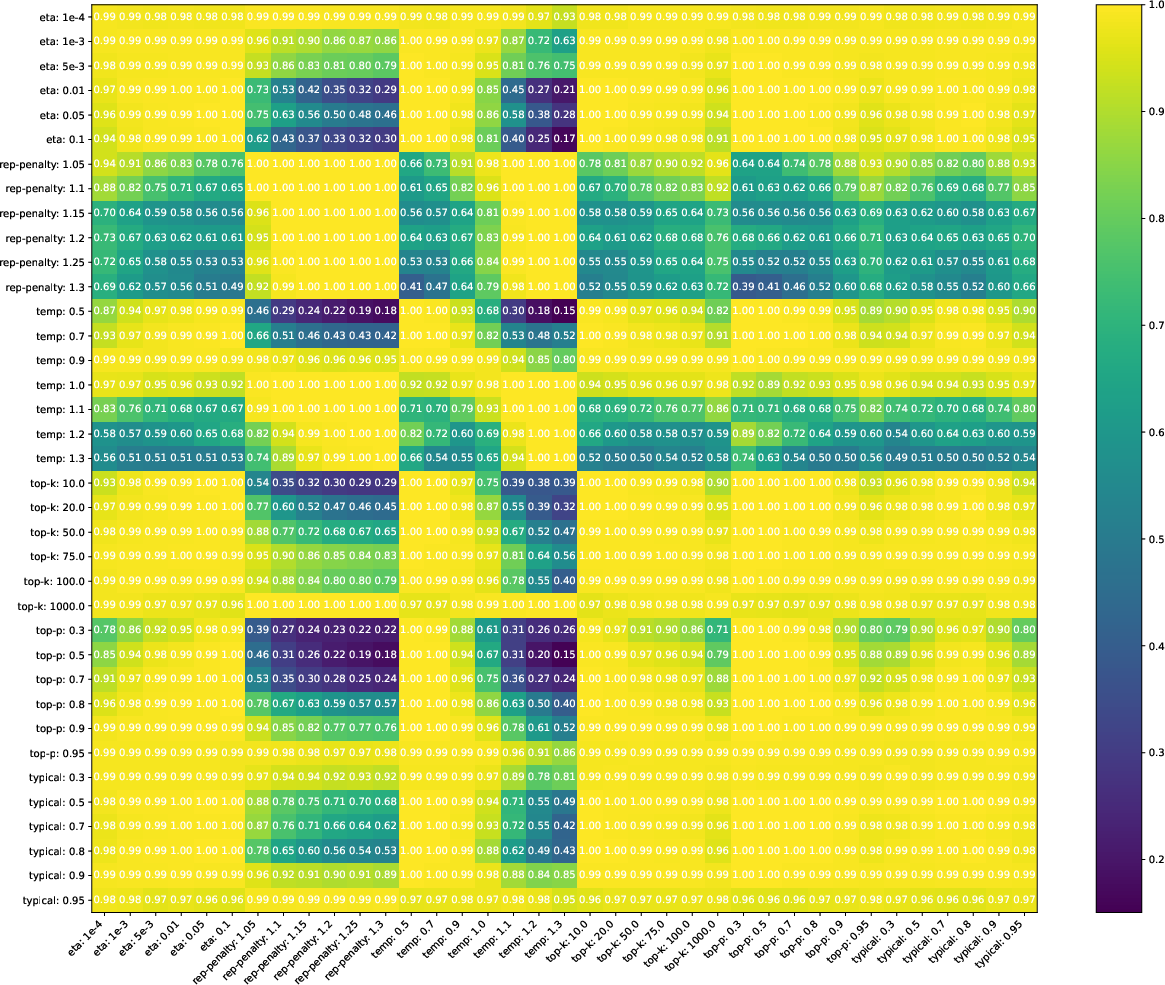
Figure 3: Heatmap of AUC detection rates for unsupervised methods across decoding parameters, highlighting severe performance degradation for certain settings.
Mechanisms of Detector Failure
The analysis correlates detection performance with distributional metrics. High entropy and large divergence between the main and auxiliary detector models are the strongest predictors of detection failure. Perplexity and direct distributional distance (TV, L2) are less informative. The detectors misclassify highly diverse machine-generated texts as human, due to the induced distributional similarity in the token frequency tails and entropy profiles.

Figure 4: Changes in the decoding strategy can lead to errors in detection, as illustrated by misclassification under top-p and repetition penalty settings.
Practical and Theoretical Implications
The findings have several implications:
- Benchmark Design: Existing ATD benchmarks insufficiently cover the space of decoding strategies. Robust evaluation requires systematic variation of generation parameters.
- Detector Robustness: Both supervised and unsupervised detectors are brittle to changes in sampling adapters. Overfitting to specific generator distributions or human domains is prevalent.
- Adversarial Evasion: Simple parameter tuning (e.g., increasing repetition penalty) can evade detection, raising concerns for misuse in plagiarism, fraud, and misinformation.
- Model Alignment: Unsupervised methods require close alignment between detector and generator models; mismatches induce false negatives and positives.
Future Directions
The study suggests several avenues for future research:
- Comprehensive Benchmarks: Expansion to more languages, models, and advanced decoding techniques (e.g., MBR, MCTS).
- Adaptive Detection: Development of detectors robust to distributional shifts induced by sampling adapters.
- Domain Generalization: Addressing overfitting in supervised detectors to improve cross-domain performance.
- Distributional Analysis: Leveraging deeper statistical properties of text for detection, beyond token-level surprisal.
Conclusion
This work demonstrates that the detectability of machine-generated texts is highly contingent on the choice of sampling-based decoding strategies. State-of-the-art detectors, both supervised and unsupervised, are vulnerable to modest changes in generation parameters, with performance dropping from near-perfect to null in some cases. The results underscore the necessity for more comprehensive evaluation protocols and robust detection methods, especially as generative models become increasingly fluent and accessible. The released benchmark and code provide a foundation for future research in reliable ATD.