MimicKit: A Reinforcement Learning Framework for Motion Imitation and Control
Abstract: MimicKit is an open-source framework for training motion controllers using motion imitation and reinforcement learning. The codebase provides implementations of commonly-used motion-imitation techniques and RL algorithms. This framework is intended to support research and applications in computer graphics and robotics by providing a unified training framework, along with standardized environment, agent, and data structures. The codebase is designed to be modular and easily configurable, enabling convenient modification and extension to new characters and tasks. The open-source codebase is available at: https://github.com/xbpeng/MimicKit.











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MimicKit, a free (open-source) toolkit that helps computers learn realistic body movements—like walking, backflips, or dance—by copying motion data from real people and practicing in a physics simulator. It’s built to make research and development in animation (for games and films) and robotics easier, faster, and more reliable.
What are the main goals?
The paper focuses on simple, clear goals:
- Build a single, easy-to-use system where different learning methods can train characters to move in a lifelike way.
- Make it simple to switch between different characters (humanoids, robots, quadrupeds), tasks, and simulators.
- Provide ready-made tools and examples so others can reproduce results and try new ideas.
- Compare several popular learning methods to understand their strengths and weaknesses.
How does MimicKit work? (In everyday terms)
Think of MimicKit like a training gym for digital characters and robots:
- A “coach” tells the character what to try, watches the result, gives points when it does well, and adjusts the training plan. In AI terms, this is reinforcement learning (RL), which is basically trial-and-error learning with rewards.
- The character practices inside a “virtual world” (a physics simulator) that follows the rules of motion (gravity, joint limits, friction).
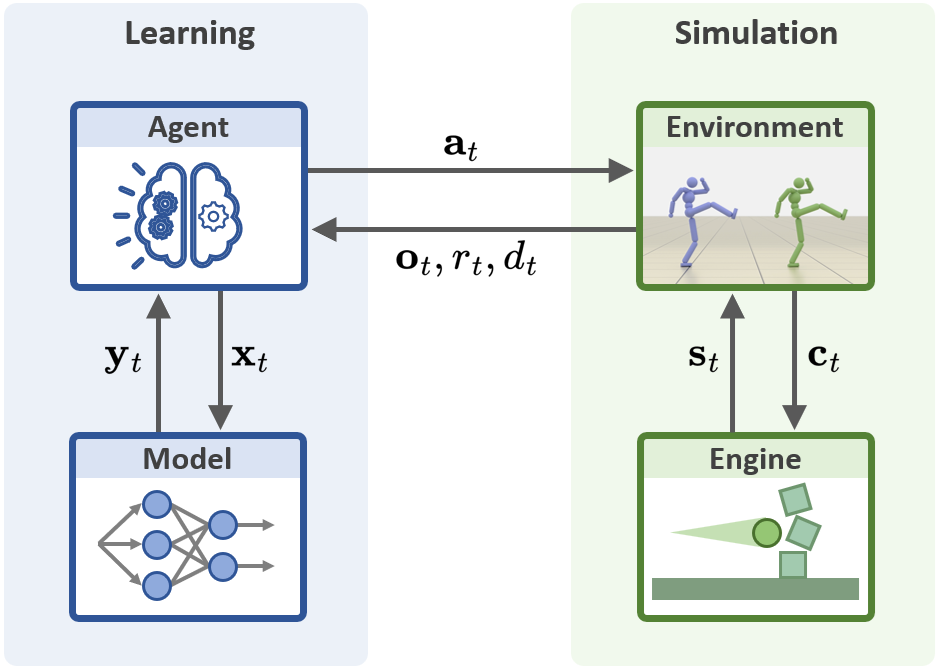
MimicKit organizes training into four plug-and-play parts:
- Agent: The “coach” that runs the learning algorithm and keeps track of practice sessions.
- Model: The “brain” (neural networks) that decides actions, estimates how good they are, or judges style.
- Environment: The “practice arena” that gives the character observations (like joint positions) and accepts actions (like move an arm).
- Engine: The “physics” underneath that actually moves the body parts and simulates the world (MimicKit currently uses Isaac Gym for fast GPU simulation).
What the character learns to do:
- It watches short clips of real motions (motion capture)—like running or cartwheels—and tries to imitate them.
- It gets reward points when its pose matches the reference, moves smoothly, or follows the desired style.
Different ways to train:
- DeepMimic: Like following a choreography sheet very closely. Great for precise copying but less flexible if you need to adapt.
- AMP (Adversarial Motion Priors): Learns the overall “style” from a set of clips (like learning to dance in the style of hip-hop without copying a specific routine). More flexible but less exact.
- ASE (Adversarial Skill Embeddings): Learns a “menu” of reusable skills in a hidden skill space, so a high-level controller can choose which skill to use later.
- ADD (Adversarial Differential Discriminator): Automatically learns what to copy, reducing the need to hand-craft reward formulas for each motion.
Under the hood:
- Most training uses PPO (Proximal Policy Optimization), a popular RL method for control tasks.
- MimicKit runs many practice worlds in parallel on the GPU to collect lots of experience quickly.
- It supports different command styles to the robot’s “joints,” like telling them a target position (pos), speed (vel), or force (torque).
What did they find?
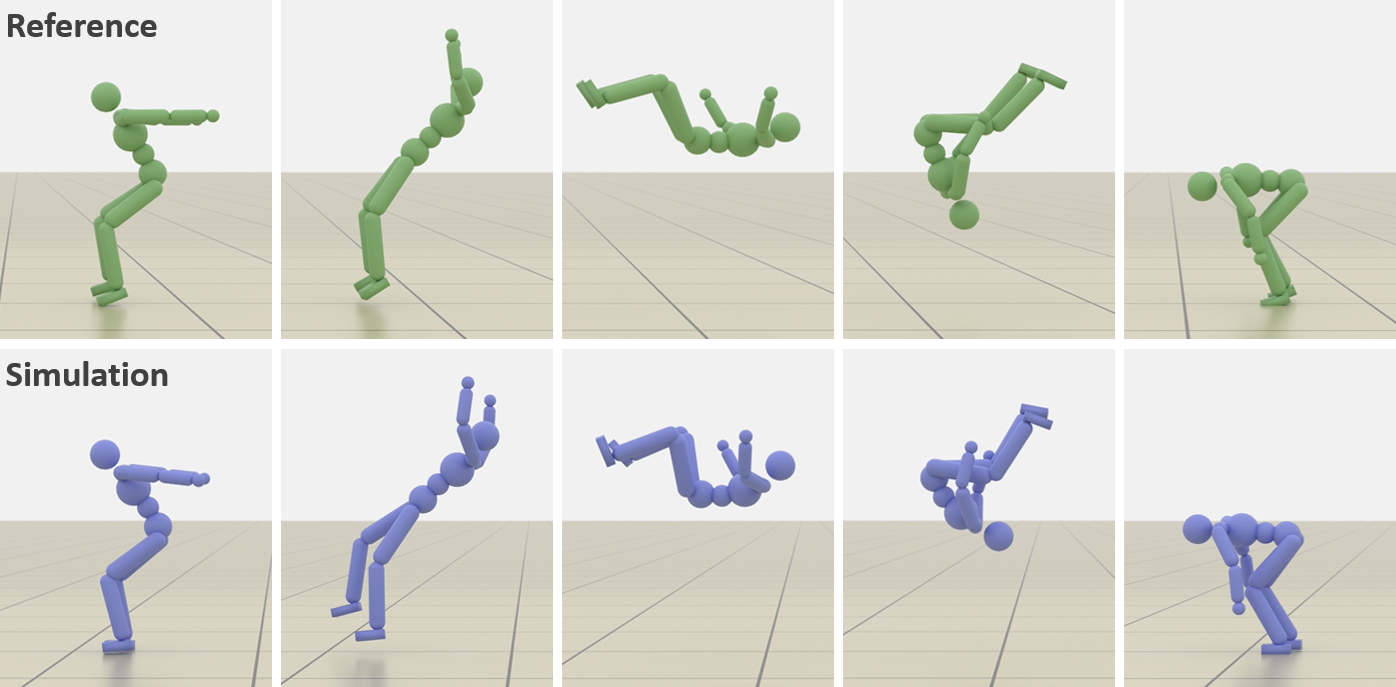
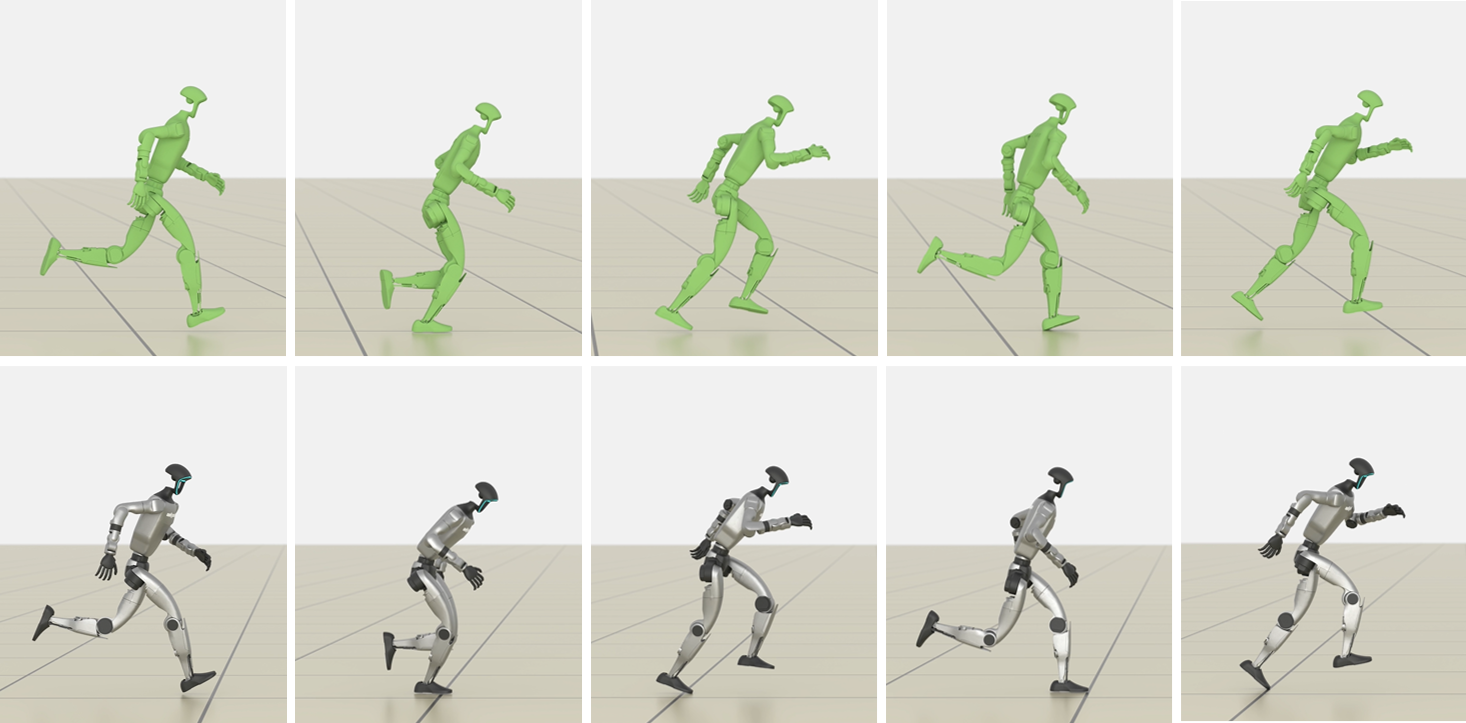
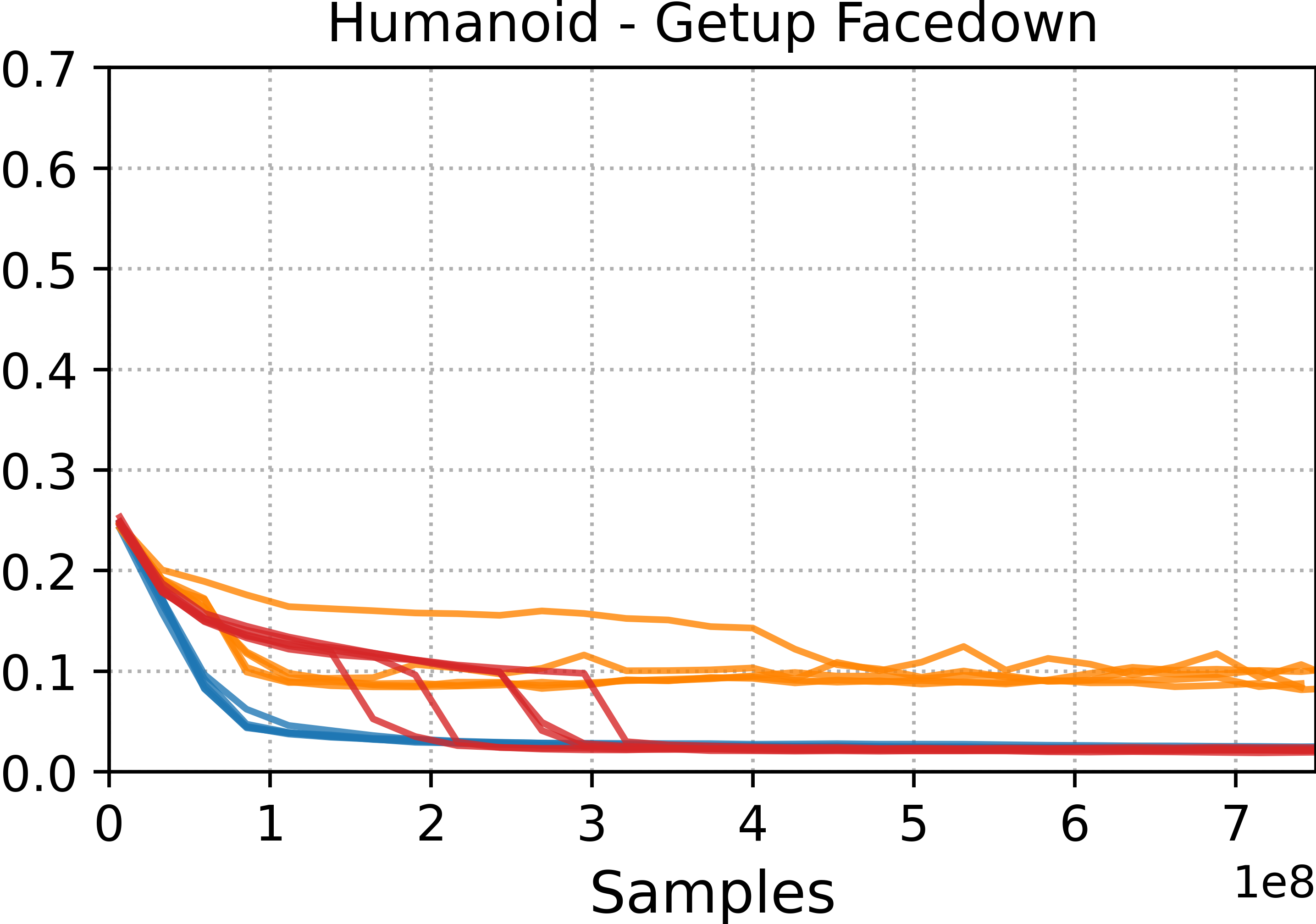
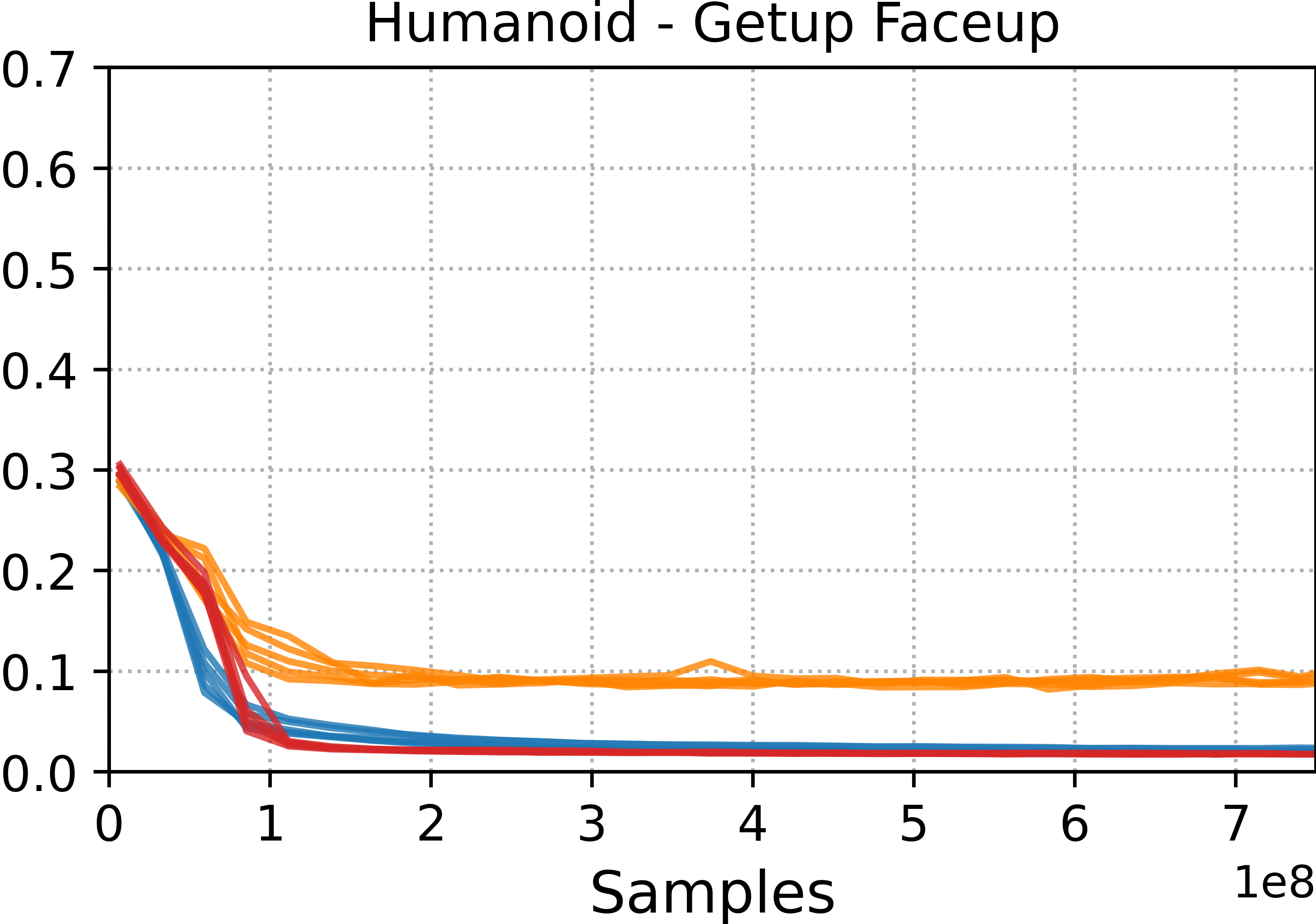
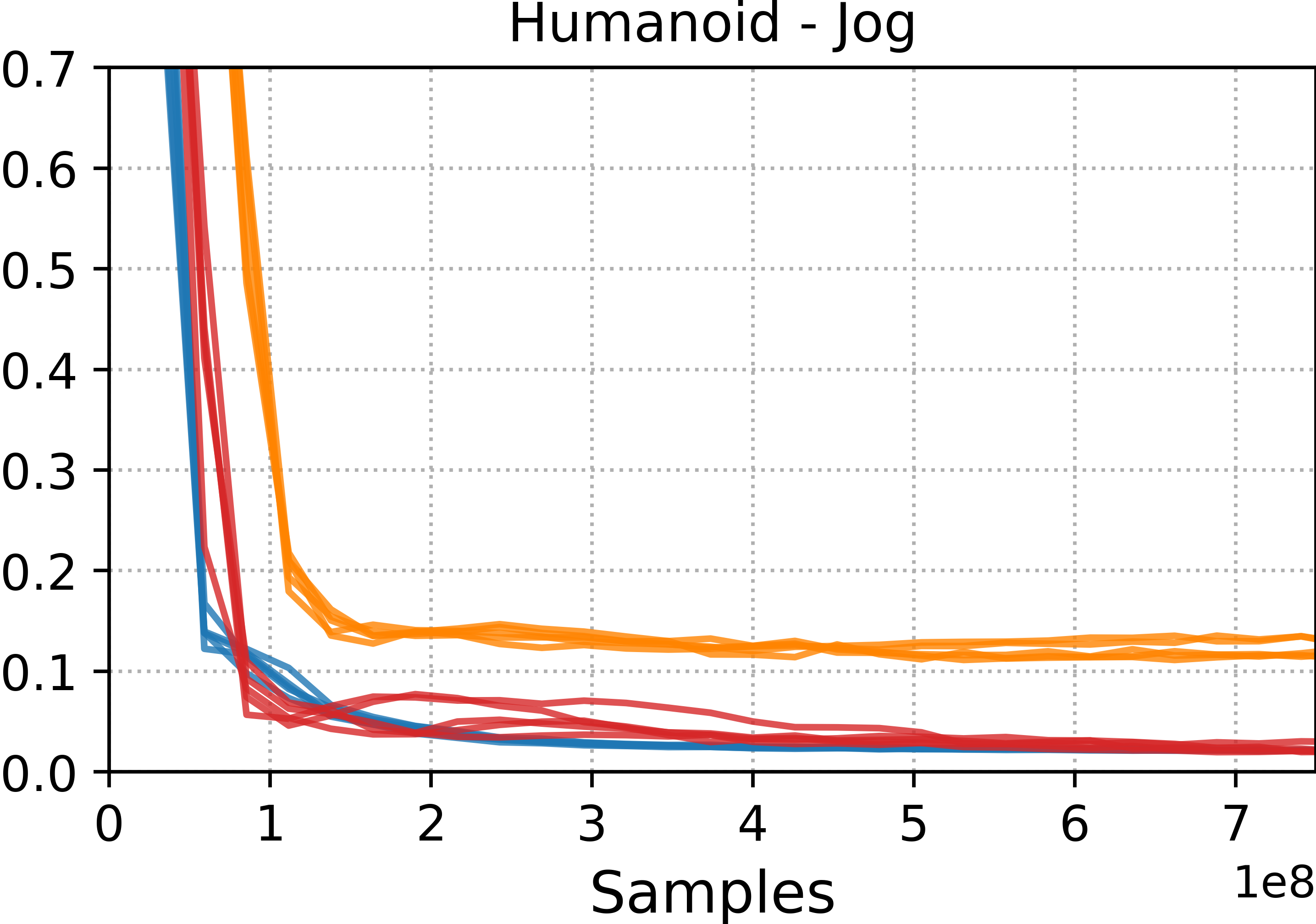
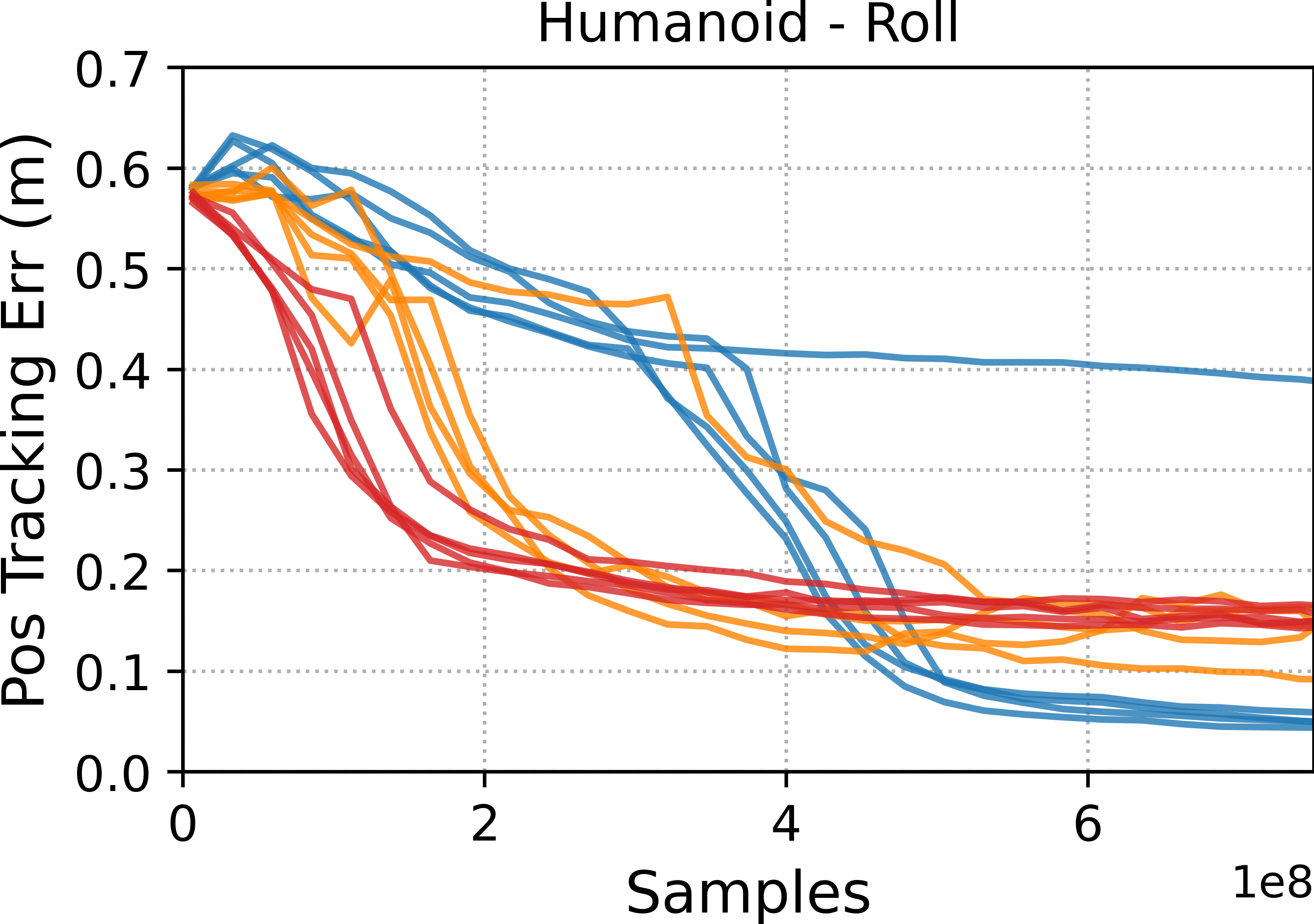
The team trained various characters—humanoid bodies, a Unitree G1 humanoid robot, and a Unitree Go2 quadruped—to perform many challenging skills: running, walking, rolls, cartwheels, backflips, get-ups, and spins.
Key results:
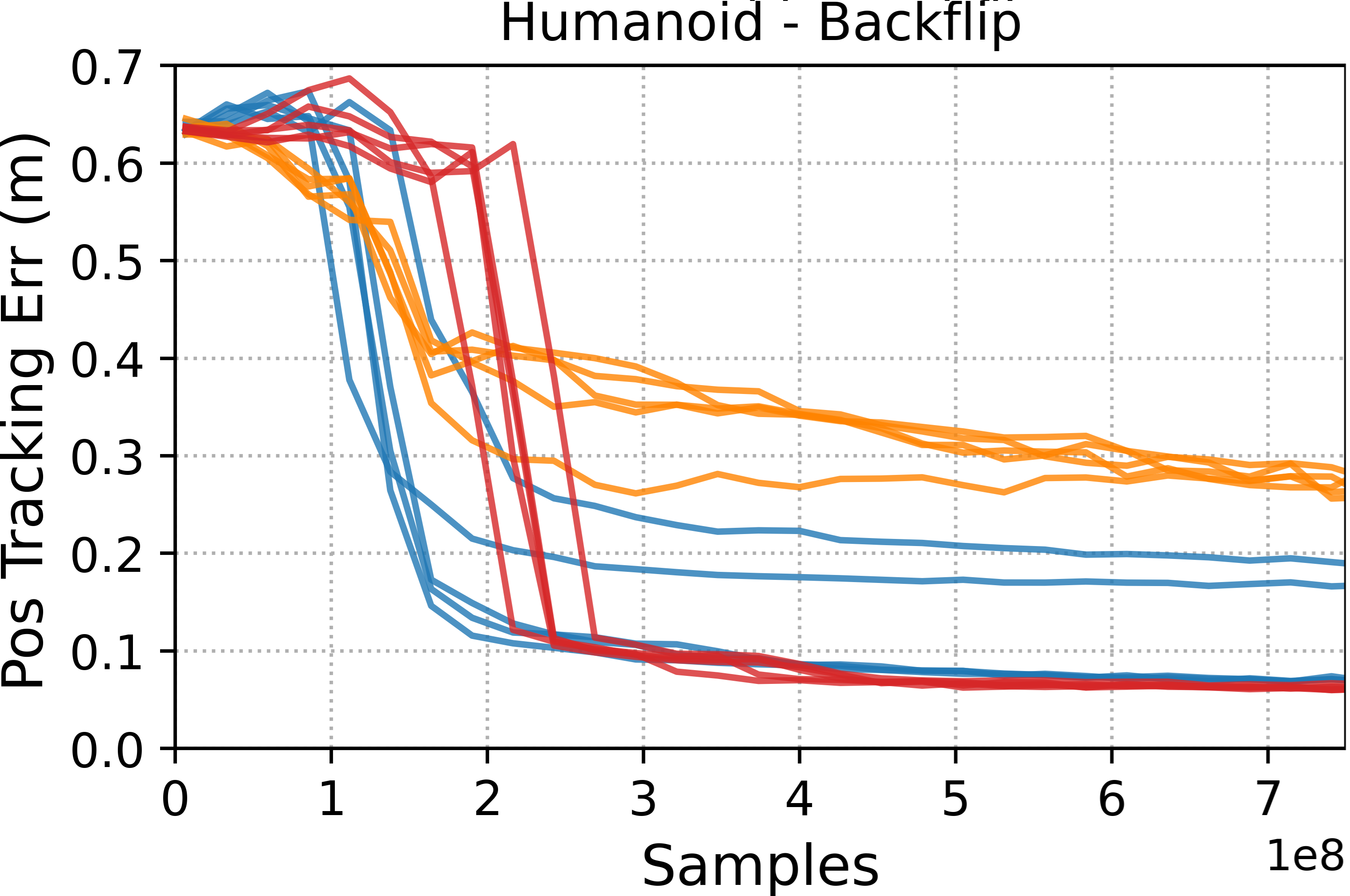
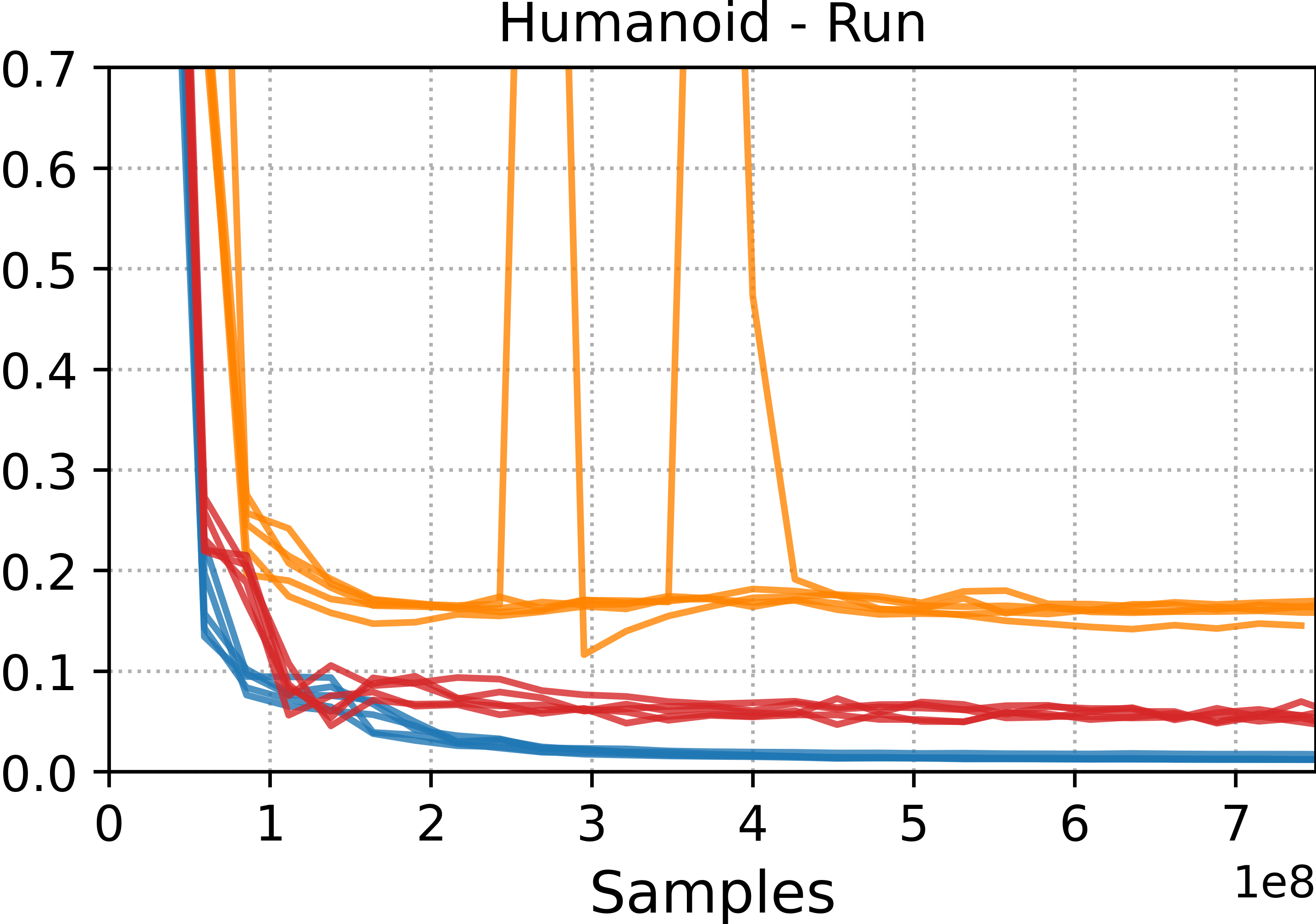
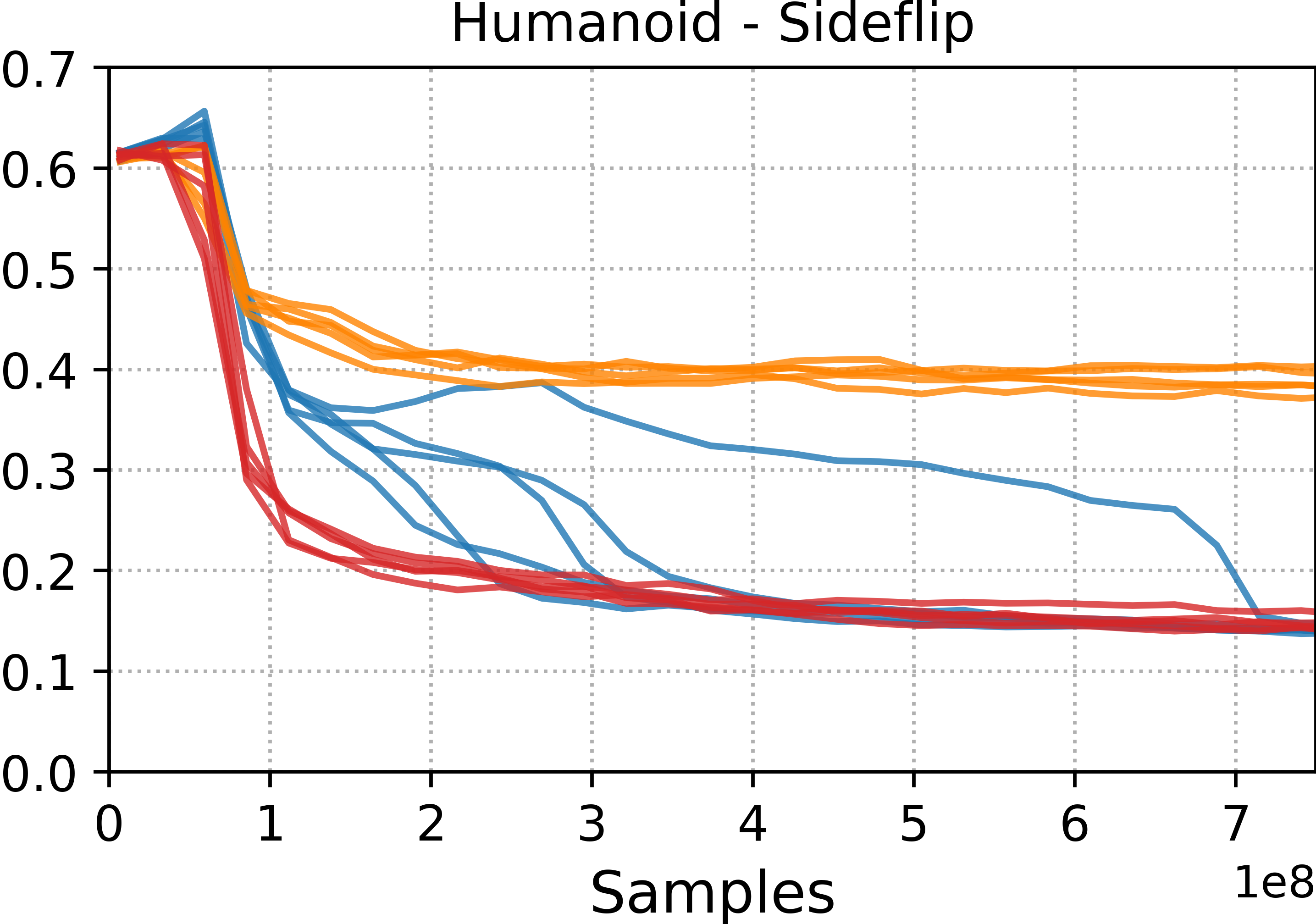
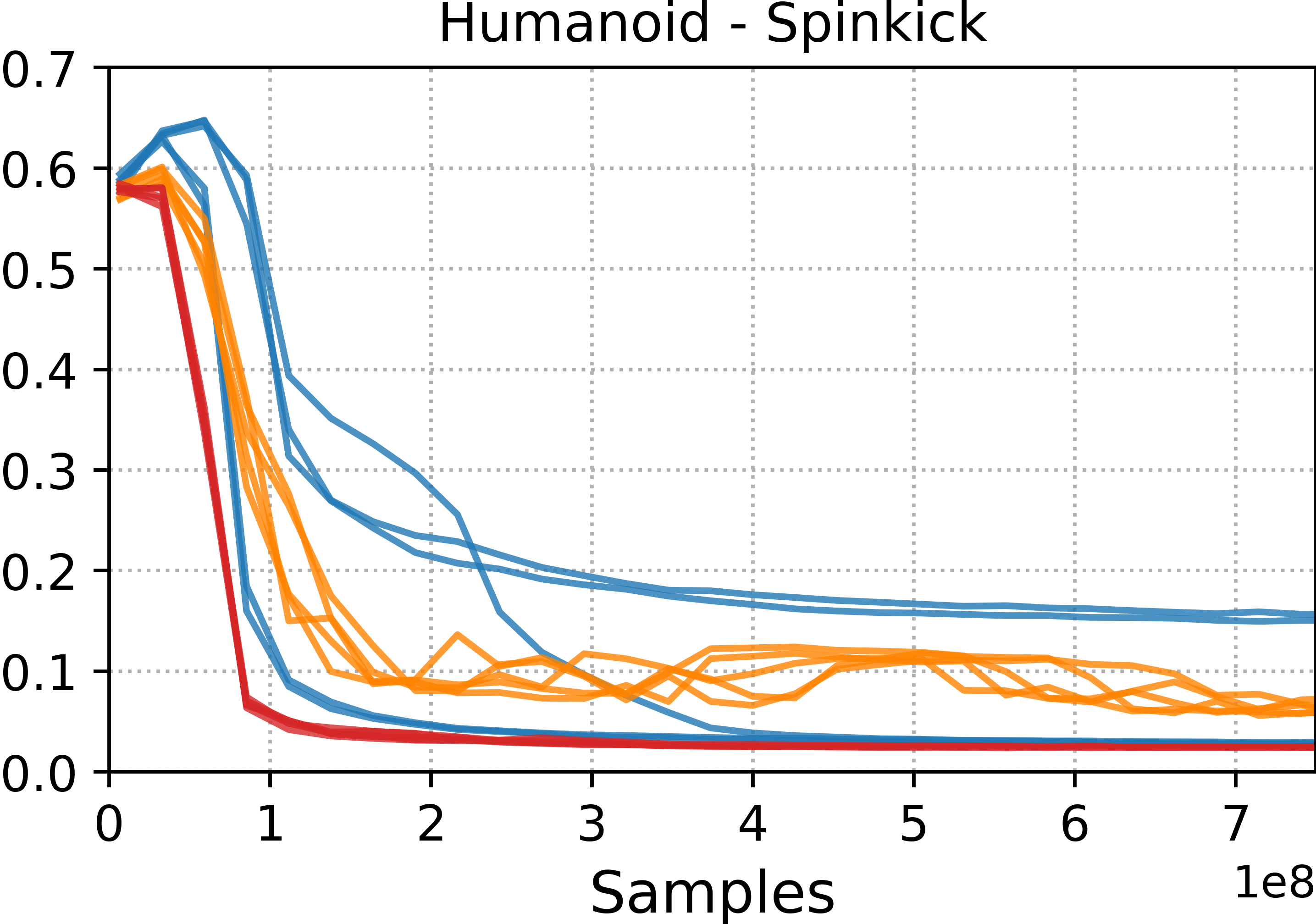
- Tracking methods (DeepMimic and ADD) were best at precisely reproducing specific motion clips. If you want a near-perfect copy of a move, these are strong choices.
- Style-learning methods (AMP) captured the general feel of the motion but didn’t match every pose exactly. They’re better for flexible, adaptable behavior.
- ADD often produced more consistent results across different runs because it learns its own tracking objective, which reduces manual tuning.
- The same training framework worked across very different body shapes (“morphologies”), showing that MimicKit is modular and general.
Why it matters:
- Accurate tracking means characters look realistic and move smoothly—important for animation and games.
- Flexibility means robots can adapt learned motions to new tasks—important for real-world use.
- Consistency and speed (thanks to GPU simulation and parallel environments) help researchers and developers iterate faster.
What is the impact?
MimicKit makes it easier to:
- Build lifelike movement for digital characters in movies and games without writing lots of hand-tuned control code.
- Train robots to perform complex, dynamic skills by learning from human demonstrations.
- Reproduce research results and try new ideas quickly, accelerating progress in motion control.
- Extend to more simulators and eventually deploy on real robots in the future.
In short, MimicKit is a practical, powerful “training gym” that helps both scientists and creators teach virtual characters and robots how to move like living beings—precisely when needed, and flexibly when tasks demand it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper and framework, phrased to be actionable for follow-up research.
- Simulator dependence and portability: The Engine currently supports only IsaacGym; no evaluation across alternative physics engines (e.g., MuJoCo, Bullet, PhysX via Isaac Sim) or evidence of consistent behavior across simulators.
- Sim-to-real gap: No deployment on physical robots despite the Engine API being designed for real systems; missing protocols for domain randomization, sensor/actuator noise models, latency handling, and hardware constraints.
- Off-policy RL coverage: AWR is included but not empirically evaluated; no comparison versus modern off-policy baselines (e.g., SAC/TD3) in terms of sample efficiency, stability, and performance on motion imitation tasks.
- Sample efficiency: No analysis of environment steps required per method (PPO/AMP/ADD/ASE), nor strategies (e.g., replay, curriculum, data reuse) to reduce data needs.
- Stability of distribution-matching methods: AMP is acknowledged as prone to local optima, but no ablations on mitigations (curriculum design, better negatives, discriminator regularization, pretraining, hybrid objectives).
- Hybrid objectives: Open question on combining tracking and distribution-matching (e.g., DeepMimic+AMP/ADD hybrids) to retain precision while allowing stylistic flexibility; no experiments on such hybrids.
- Termination conditions and fairness: Comparisons disable pose-error termination for fairness but no standardized termination protocol across methods; the effect of different termination schemes on learning and evaluation remains unquantified.
- Generalization across motions: Policies are trained per-clip; there is no quantitative evaluation of generalization to unseen clips, multi-clip unified policies, or zero-shot interpolation between motions.
- Skill reuse and downstream tasks: ASE is included but not benchmarked on downstream tasks (goal reaching, navigation, manipulation) to demonstrate controllability, sample efficiency, and transfer benefits.
- Cross-morphology retargeting: The framework claims character-agnostic support, but lacks a detailed, reproducible retargeting pipeline (kinematic mapping, scale adaptation, timing alignment) and its quantitative impact on performance.
- Metrics breadth: Evaluation focuses on pose and DoF-velocity errors; missing metrics for contact fidelity (foot-slip/foot-strike errors), energy/torque costs, jerk/smoothness, robustness (push recovery), and human perceptual realism.
- Statistical rigor: Results across 5 seeds are provided but without statistical tests or effect sizes; no sensitivity analysis to hyperparameters or initialization.
- Runtime performance: No profiling of training throughput (steps/sec), GPU/CPU utilization, memory footprints, or multi-GPU scaling efficiency; unclear limits for very large numbers of environments.
- Real-time inference: No latency/throughput measurements of trained controllers for real-time deployment; missing analysis of control frequency trade-offs and their effect on stability.
- Control modes and actuation realism: Limited discussion of actuator models (e.g., motor torque dynamics, saturation, backlash) and PD gain tuning; no auto-tuning or adaptation of controller gains per character/task.
- Sensor models and observations: Focus on proprioception; no support or experiments with high-dimensional observations (RGB/Depth/LiDAR), nor study of partial observability and sensor noise.
- Terrain and environment diversity: Experiments are on flat terrain; no tests on varied terrains, stairs, slopes, friction changes, or perturbations to evaluate policy robustness and adaptability.
- Contact-rich tasks beyond locomotion/acrobatics: No coverage of manipulation, object interactions, or multi-contact dexterity; unclear how the framework extends to these domains.
- Data pipeline details: Motion data curation, preprocessing (denoising, foot contact labeling), temporal alignment, and scaling to large datasets are not documented or evaluated.
- Multi-task and hierarchical control: No benchmarks on multi-task training (single policy across many skills), hierarchical controllers, or high-level planners selecting among skills/latents (beyond stating ASE’s potential).
- Reward design automation scope: ADD automates tracking rewards but it is unclear how robustly it transfers across morphologies and motion categories; missing ablations on discriminator architectures, loss choices, and stability tricks.
- Domain randomization and robustness: No experiments applying physics/material randomization, observation/action noise, or dynamics perturbations to evaluate robustness and sim-to-real readiness.
- Reproducibility and access: Heavy reliance on IsaacGym (license/availability constraints) and external data links may hinder reproducibility; no Docker/environment snapshots or deterministic seed guidance across machines/GPUs.
- Large-DoF characters: No evaluation on high-DoF characters (hands/fingers, facial joints) where contact-rich fine motor control and action dimensionality become challenging.
- Curriculum learning: No investigation of curricula (motion phase scheduling, difficulty ramps) for hard acrobatics or unstable behaviors; unclear best practices within MimicKit.
- Diagnostics and failures: Lacking tools/metrics for diagnosing common RL/Adversarial IL failure modes (discriminator collapse, reward hacking, mode collapse), and recovery strategies.
- Policy architecture choices: No ablations of network architectures (MLP sizes, normalization, recurrent layers), action distributions, or observation encoders and their impact on performance.
- Data efficiency of ASE: Missing quantification of how much data is required to learn a useful latent skill space and its coverage/diversity relative to dataset size.
- Evaluation protocols for pose-error termination: Paper notes substantial benefits when enabled but does not quantify improvements or provide guidelines on when/how to use it without biasing comparisons.
- Safety constraints: No discussion of safety-aware training (constraint RL, torque/velocity/joint limit safety envelopes) for real-robot applicability.
- Benchmark standardization: Tracking datasets, splits, and evaluation code are not formalized as a benchmark suite; open need for a standardized, simulator-agnostic leaderboard and protocols.
- Interoperability with broader ecosystems: No integrations with common RL libraries (e.g., Gymnasium API, RLlib, CleanRL, Stable-Baselines3) or dataset standards for motion imitation.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be implemented with the framework as released (with current IsaacGym support and the provided motion datasets and methods).
- High-fidelity character animation from mocap (media/entertainment)
- Sector: Software, Gaming, Film/TV, AR/VR
- What: Train DeepMimic/ADD policies to closely track mocap clips for lifelike in-engine animation (walks, flips, rolls, dance, getups).
- Tools/workflows: Mocap → retarget to rig (XML) → MimicKit train (PPO/ADD) → export model → Unity/Unreal runtime policy wrapper.
- Assumptions/dependencies: NVIDIA GPU; IsaacGym; correctly rigged assets; mocap licensing; runtime integration for inference.
- Style-consistent motion synthesis and editing (media/entertainment)
- Sector: Software, Creative tools, Digital humans
- What: Use AMP to match behavioral “style” across clips without strict tracking; create stylized variants (e.g., energetic, relaxed) for avatars/VTubing/VRChat.
- Tools/workflows: Curate style dataset → AMP train → style selector UI in DCC (e.g., Blender/Maya) or game engines.
- Assumptions/dependencies: Sufficient diverse motion dataset; curator-defined style labels; GPU training.
- Skill library creation for reusable controllers (R&D, content pipelines)
- Sector: Software, Robotics R&D, Games
- What: Train ASE to learn latent skill embeddings that can be reused across tasks and characters; build “skill banks” (locomotion, acrobatics).
- Tools/workflows: ASE pretrain → small high-level policy for task sequencing → deployment in sandbox/game toolchains.
- Assumptions/dependencies: Adequate coverage of skills in the dataset; inference latency budget; basic hierarchical control glue code.
- Automatic reward tuning via ADD (R&D acceleration)
- Sector: Software, Robotics R&D
- What: Reduce manual reward engineering by learning adaptive tracking objectives with differential discriminators.
- Tools/workflows: Swap DeepMimic tracking rewards for ADD in config; hyperparameter tuning via provided logs/TensorBoard/W&B.
- Assumptions/dependencies: Quality positive examples; discriminator stability; careful seed/mode management.
- Synthetic, physics-consistent motion data generation (ML data engineering)
- Sector: Computer Vision, Perception, Simulation
- What: Use trained controllers to render large, labeled datasets (e.g., joint angles/positions) for training pose estimators or action recognizers.
- Tools/workflows: Batch simulation with vectorized envs (4k+ envs) → export trajectories → dataset packaging.
- Assumptions/dependencies: Distribution shift between sim and real; rendering pipeline; compute for scale-out.
- Rapid benchmarking and reproducible studies (academia)
- Sector: Academia, Open science
- What: Standardize evaluation across DeepMimic/AMP/ASE/ADD; reproduce baselines; ablations on control modes and termination flags.
- Tools/workflows: Use provided configs, logging, plotting tools; distributed training (--num_workers).
- Assumptions/dependencies: Access to GPUs; IsaacGym installation; consistent seeds/data splits.
- Teaching labs and coursework in RL for control (education)
- Sector: Education
- What: Coursework modules on policy optimization, adversarial imitation, skill discovery; practical labs with immediate visual feedback.
- Tools/workflows: Prepackaged arg files; sandboxed assignments; visualization and log plotting scripts.
- Assumptions/dependencies: Lab machines with NVIDIA GPUs; simplified assets; curated datasets.
- Early-stage robot behavior prototyping in simulation (robotics R&D)
- Sector: Robotics (legged/humanoid)
- What: Prototype locomotion or acrobatic behaviors for morphologies close to Unitree Go2/G1; compare torque vs PD control.
- Tools/workflows: Import robot URDF/XML → environment config → multi-GPU training → offline evaluation with failure flags.
- Assumptions/dependencies: Currently simulation-only engine; accurate mass/inertia/friction; actuator limits modeled.
- Failure detection and safety instrumentation in sim (tooling)
- Sector: Robotics, Safety testing
- What: Use MimicKit’s done flags (FAIL/SUCC/TIME) to build failure analytics for behaviors (falls, undesired contacts).
- Tools/workflows: Instrument info dict; offline risk analytics; curriculum adjustments.
- Assumptions/dependencies: Failure modes well-encoded in env; coverage of rare events.
- Pipeline for motion retargeting across morphologies (content pipelines)
- Sector: Software, Games, Robotics sim
- What: Retarget mocap to humanoid/SMPL/Unitree-like rigs; train controllers with minimal code changes due to character-agnostic design.
- Tools/workflows: Rig mapping → environment config swap → batch training → QA filmstrips.
- Assumptions/dependencies: Quality rig mapping; stable kinematic tree definitions; consistent joint limits.
Long-Term Applications
These are high-impact applications that will benefit from MimicKit’s methods but need additional research, integration, scaling, or real-world validation.
- Sim-to-real deployment for dynamic legged/humanoid robots
- Sector: Robotics, Industrial/field robots
- What: Transfer ADD/DeepMimic/ASE-trained policies to hardware for agile locomotion, getups, and athletic maneuvers.
- Tools/products: Real-robot Engine backends; domain randomization; onboard inference; safety supervisor.
- Assumptions/dependencies: Support for real robot engines; accurate actuator/sensor models; compliance/safety certification; robust state estimation.
- Assistive robotics and exoskeleton gait controllers
- Sector: Healthcare, MedTech
- What: Controllers that imitate target therapeutic gait patterns, adapt style/tempo via AMP/ASE.
- Tools/products: Clinician-in-the-loop tuning; patient-specific motion priors; regulated medical software stack.
- Assumptions/dependencies: Clinical trials; biomechanical validation; regulatory approval; human-in-the-loop safety.
- Contact-rich manipulation via imitation and learned rewards
- Sector: Manufacturing, Logistics, Service robotics
- What: Extend ADD/AMP to manipulation skills (assembly, tool use) using curated demonstrations.
- Tools/products: Contact-rich simulators; multimodal discriminators (vision + proprioception); task success metrics.
- Assumptions/dependencies: High-fidelity contact simulation; sensory realism; dataset collection at scale.
- Household service robots with skill libraries
- Sector: Consumer robotics
- What: ASE-based latent skill libraries (locomotion, simple manipulation, getups) orchestrated by task planners/LfLMs.
- Tools/products: High-level scheduler; language grounding; safety and failover behaviors.
- Assumptions/dependencies: Robust generalization; reliable perception; resource-constrained inference on-device.
- Digital human platforms with real-time style control
- Sector: Media, Social/enterprise XR
- What: Runtime style-conditioned motion generation (AMP) and skill blending (ASE) for NPCs/avatars in MMOs/virtual meetings.
- Tools/products: Engine plugins; model compression/distillation; QoS-aware motion LOD.
- Assumptions/dependencies: Latency <16 ms/frame; cross-platform inference; user-friendly style controls.
- Sports training and rehabilitation analytics
- Sector: Sports-tech, Healthcare
- What: Compare athlete motion to simulated “ideal” references; skill shaping using adversarial priors; personalized drills.
- Tools/products: Mocap capture; similarity metrics; coach dashboards; biofeedback interfaces.
- Assumptions/dependencies: Accurate biomechanical mapping; validated assessment metrics; privacy-compliant data use.
- Standardized safety and performance benchmarks for learning-based control
- Sector: Policy, Standards bodies, Consortiums
- What: Establish public benchmarks (done flag semantics, tracking errors, success/failure rates) for motion control safety and fidelity.
- Tools/products: Open datasets; leaderboards; certification test suites.
- Assumptions/dependencies: Multi-stakeholder governance; reproducibility infrastructure; legal/IP clarity for datasets.
- Vision-driven imitation from videos
- Sector: Robotics, CV
- What: Combine AMP/ADD with video encoders to learn from in-the-wild videos (no mocap).
- Tools/products: Self-supervised representation learning; pose estimation integration; weakly supervised discriminators.
- Assumptions/dependencies: Robust 2D→3D pose lifting; domain gaps; noisy labels handling.
- Auto-reward “compiler” for new morphologies and tasks
- Sector: Developer tooling, Platform products
- What: Generalize ADD into a tool that derives reward functions from examples across rigs, reducing reward engineering time.
- Tools/products: GUI for example selection; reward diagnostics; policy bootstrapping templates.
- Assumptions/dependencies: Stability across diverse tasks; explainability of learned rewards; integration with multiple simulators.
- On-device, energy-efficient controllers via distillation
- Sector: Edge AI, Robotics, Mobile XR
- What: Distill PPO/ADD/ASE policies into compact networks for low-power deployment.
- Tools/products: Quantization/pruning pipelines; latency/energy KPIs; fallback safe modes.
- Assumptions/dependencies: Accuracy–latency trade-offs; hardware accelerators; thermal constraints.
- Human–robot collaboration and teleoperation assistance
- Sector: Industrial, Medical, Defense
- What: Use ASE latent spaces to interpolate/blend skills under operator guidance; smooth handover between human input and policy autonomy.
- Tools/products: Shared autonomy interfaces; intent inference; safety overlays.
- Assumptions/dependencies: Reliable operator intent decoding; human factors validation; fail-safe guarantees.
- Biomechanics-informed design and prosthetic testing in sim
- Sector: Biomechanics, Medical devices
- What: Iterate prosthetic designs by training controllers to desired gait/style; evaluate comfort/effort proxies via tracking errors and smoothness.
- Tools/products: Parametric rig/asset libraries; design-of-experiments automation.
- Assumptions/dependencies: Valid biomechanical proxies; subject-specific calibration; ethics/regulatory pathways.
- Multi-engine, cross-simulator and real-system backends
- Sector: Simulation platforms, Robotics vendors
- What: Extend Engine abstraction beyond IsaacGym (e.g., Isaac Lab, MuJoCo, Bullet, real robot drivers) for broader adoption.
- Tools/products: Engine SDKs; conformance tests; device adapters (pos/vel/torque).
- Assumptions/dependencies: Engine API maturity; consistent physics/contacts; maintenance burden.
- RL MLOps for motion control at scale
- Sector: Platform engineering
- What: Training farm orchestration (distributed PPO/AWR), experiment tracking, artifact/version management for motion policies.
- Tools/products: Kubernetes-based trainers; dataset registries; policy evaluation dashboards.
- Assumptions/dependencies: Cloud/GPU budget; data governance; reproducibility protocols.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Hardware/software stack: Requires NVIDIA GPUs and IsaacGym (or successor engines) for high-throughput simulation; CUDA drivers; stable physics and contact modeling.
- Data quality: High-quality, licensed motion capture or curated datasets for target skills/styles; asset rigging and kinematic consistency.
- Sim-to-real gap: Domain randomization, actuator/sensor fidelity, latency, and safety layers are necessary for hardware deployment.
- Compute and engineering: Multi-GPU scaling for large skill libraries; inference latency constraints for real-time applications.
- Safety and compliance: Particularly for healthcare and human-facing robots—requires rigorous validation, risk assessment, and regulatory approvals.
- IP and licensing: Motion data, character assets, and integration into commercial engines may have licensing restrictions.
Glossary
- Action distribution: A probability distribution over actions parameterized by the policy/network, from which actions are sampled. "parameters of an action distribution, value function predictions, discriminator predictions, or other quantities required by the learning algorithm."
- Actor-critic algorithm: An RL architecture with separate networks for the policy (actor) and the value estimator (critic). "For an actor-critic algorithm, such as PPO \citep{PPO2017}, the model may contain multiple neural networks, one for the policy (i.e. actor) and the value function (i.e. critic)."
- Adversarial Differential Discriminator (ADD): An adversarial motion-tracking method using a differential discriminator to learn adaptive tracking rewards. "ADD is an adversarial motion tracking method that uses a differential discriminator to automatically learn adaptive motion tracking objectives \citep{zhang2025ADD}."
- Adversarial Motion Priors (AMP): An adversarial distribution-matching approach that imitates the overall style of a motion dataset without tracking specific clips. "AMP is an adversarial distribution-matching method that aims to imitate the overall behavioral distribution (i.e. style) depicted in a dataset of motion clips \citep{2021-TOG-AMP}, without explicitly tracking any specific motion clip."
- Adversarial Skill Embeddings (ASE): An adversarial method that learns reusable, generative controllers via latent skill embeddings. "ASE is an adversarial methods for training reusable generative controllers \citep{2022-TOG-ASE}."
- Advantage-Weighted Regression (AWR): An off-policy RL algorithm that fits policies to actions weighted by estimated advantages. "Our framework provides an off-policy algorithm, Advantage-Weighted Regression (AWR) \citep{AWRPeng19}, as an alternative to PPO for settings that may require off-policy RL algorithms."
- Bootstrapping: Estimating future returns at a truncated trajectory by using a value function estimate. "In the event that a trajectory is truncated due to time, bootstrapping with a value function can be used to estimate future returns, as if the trajectory had continued after the last timestep."
- Character-agnostic: Designed to work across different characters without character-specific logic or tuning. "The environments and learning algorithms are designed to be character-agnostic, enabling the overall system to be easily configured to support characters with different morphologies, including humanoid and non-humanoid characters, such as quadrupedal robots."
- Control frequency: The rate at which control commands are applied to the simulator or robot. "The environment file can be used to specify the type of Engine to use for simulation, along with parameters such as the control model, control frequency, simulation frequency, etc."
- Control modes: The available modalities for issuing commands to the simulator (e.g., position, velocity, torque control). "supports the following control modes:"
- Degrees of Freedom (DoF): The number of independent parameters that define a joint’s or system’s configuration/motion. "The DoF velocity tracking error measures the differences in local angular velocities of each joint between the simulated character and the reference motion:"
- Differential discriminator: A discriminator that operates on motion differences to automatically shape adaptive tracking rewards. "uses a differential discriminator to automatically learn adaptive motion tracking objectives"
- Discount factor: A scalar in [0,1] that downweights future rewards in the return. "and is a discount factor."
- Discounted return: The sum of rewards over time where future rewards are geometrically discounted. "maximizes its expected discounted return ,"
- Distribution-matching: Learning to match the distribution (style) of demonstrated motions rather than track a specific reference. "distribution-matching methods, such as AMP,"
- Done flag: An indicator specifying whether and how an episode terminated (e.g., success, failure, time limit). "The done flag indicates if the current episode has been terminated."
- Early termination: Ending an episode before its nominal horizon when certain conditions occur (e.g., undesired contacts). "During training and evaluation, early termination is triggered only when the character makes undesired contact with the ground."
- Experience buffer: A memory structure that stores collected trajectories or transitions for learning updates. "The data collected through these interactions are stored in an experience buffer implemented in 0.9,0.9,0.9{mimickit/learning/experience_buffer.py}."
- Exponential map: A rotation representation using the exponential map from Lie algebra to Lie group (common for 3D joint rotations). "where 3D rotations are specified using 3D exponential maps \citep{ExpMapGrassia1998}."
- GPU simulators: Physics simulators running on GPUs to enable massive parallel data collection. "which can be massively parallelized using GPU simulators for high-throughput data collection during training."
- IsaacGym: NVIDIA’s GPU-accelerated physics simulator for reinforcement learning and robotics. "MimicKit currently only supports IsaacGym \citep{IsaacGym2021}"
- Kinematic tree: The hierarchical joint structure of an articulated body used to define pose ordering and traversal. "Joint rotations are recorded in the order that the joints are specified in the 0.9,0.9,0.9{.xml} file (i.e. depth-first traversal of the kinematic tree)."
- Latent skill embeddings: Vector encodings of skills learned such that different latent codes map to different behaviors. "to learn latent skill embeddings."
- Latent space: A continuous space of latent variables from which diverse behaviors can be generated. "Points in the latent space can be mapped to diverse behaviors by the ASE controller."
- Markov Decision Process (MDP): A standard formalism for sequential decision-making with states, actions, transitions, and rewards. "This enables the learning algorithms to emulate infinite-horizon MDPs given finite-length trajectories."
- Morphology: The physical structure and joint configuration of a character or robot. "different morphologies, including humanoid and non-humanoid characters, such as quadrupedal robots."
- Motion capture: Recording real human/animal movements to produce reference motion clips. "motion clips recorded via motion capture of live actors."
- Motion imitation: Training controllers to reproduce motions from demonstrations or datasets. "MimicKit provides a suite of motion imitation methods for training controllers."
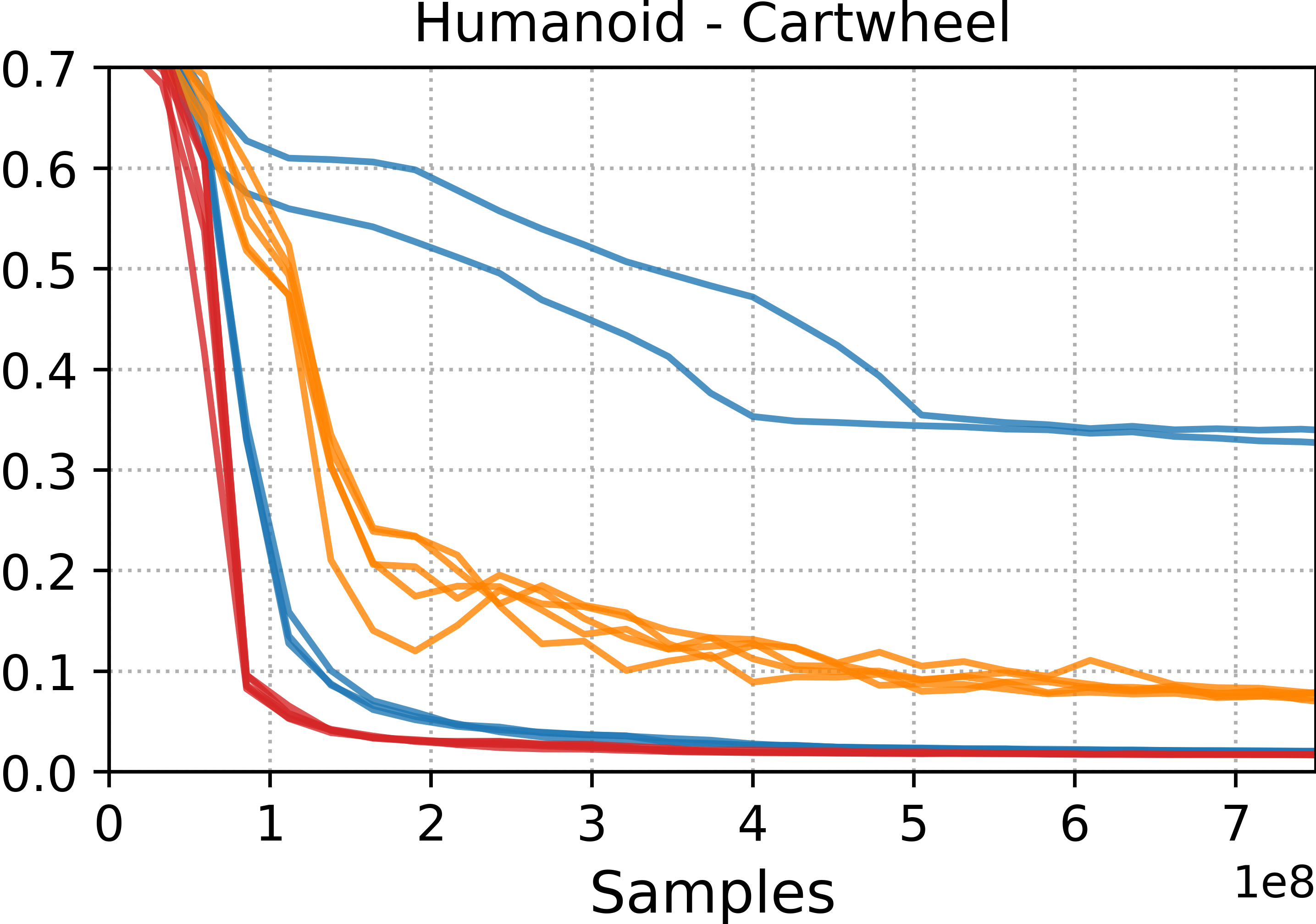
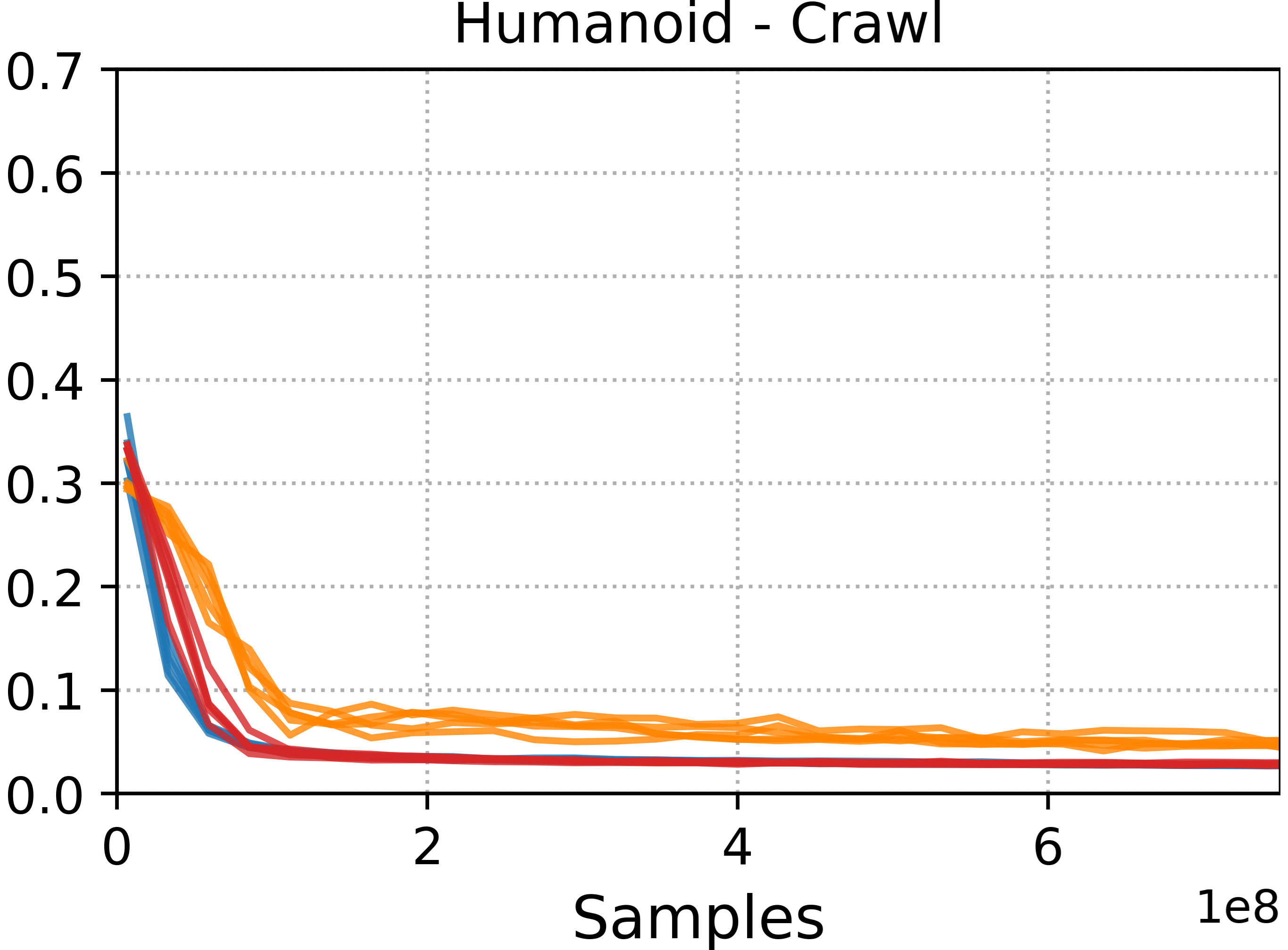
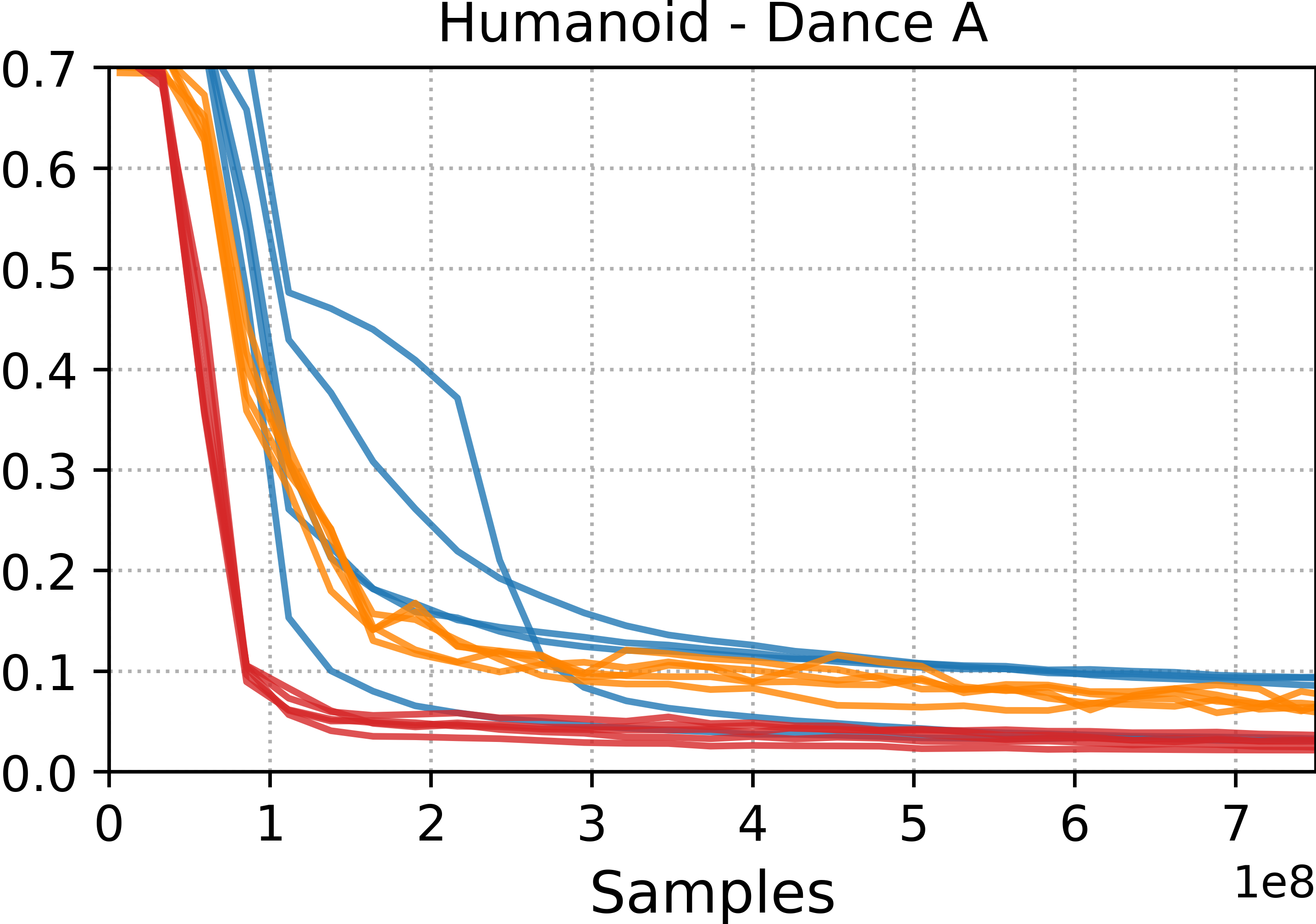
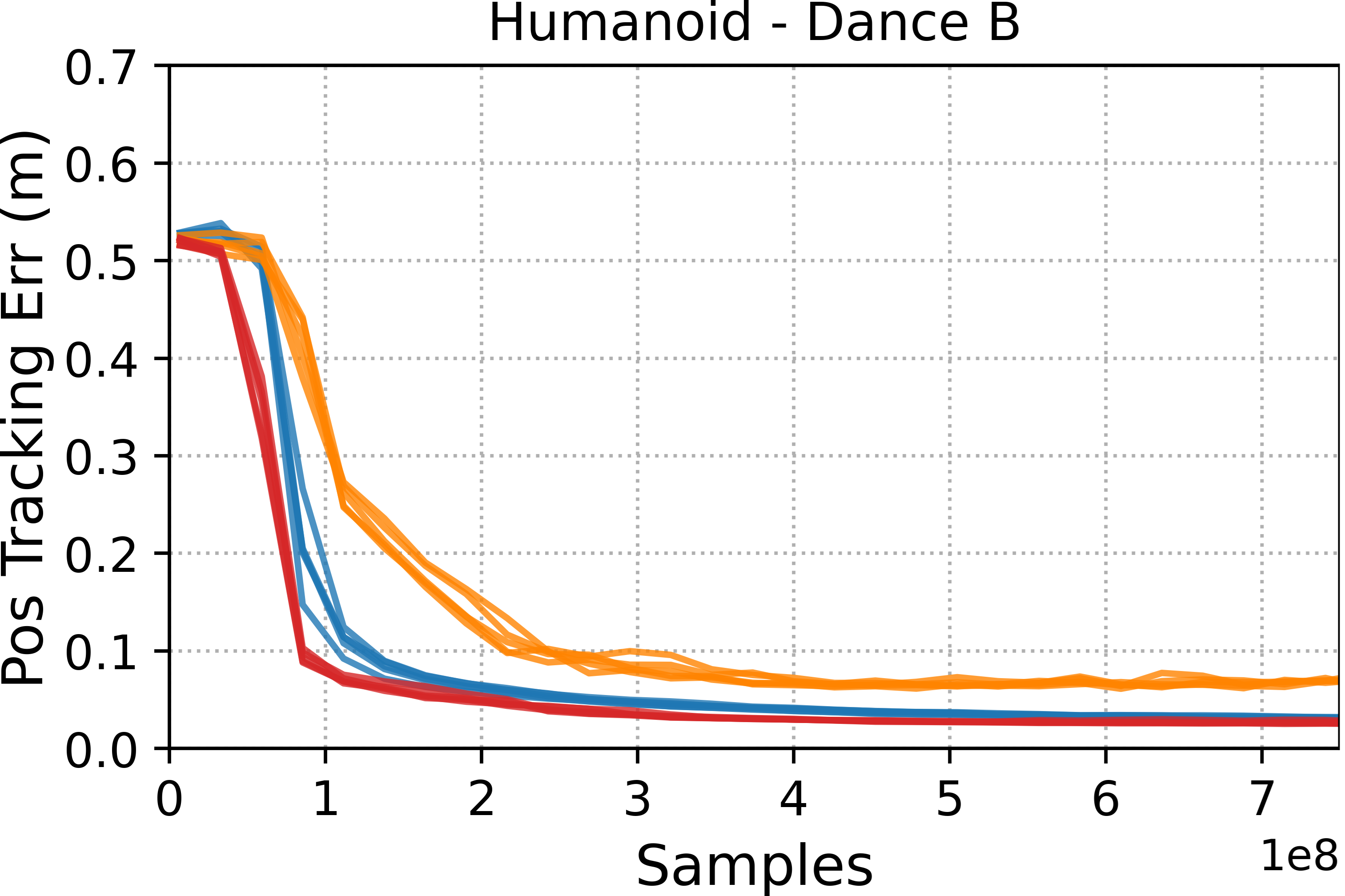
- Motion tracking: Training controllers to closely follow a specific reference motion trajectory. "Motion tracking methods, such as DeepMimic and ADD, are able to more accurately reproduce a given reference motion compared to distribution-matching methods, such as AMP."
- Mutual information: An information-theoretic measure used here to encourage discoverable and distinguishable skills. "a mutual information-based skill discovery objective"
- Off-policy algorithm: An RL approach that learns from data generated by a different behavior policy than the one being improved. "provides an off-policy algorithm, Advantage-Weighted Regression (AWR) \citep{AWRPeng19}"
- On-policy algorithm: An RL approach that learns from data generated by the current policy being optimized. "since PPO is an on-policy algorithm \cite{Sutton2018}, it can be notoriously sample inefficient."
- PD controller: A proportional-derivative joint controller specifying target positions (and implicitly velocities). "Commands specify target rotations for PD controllers, which support both 1D revolute joints and 3D spherical joints."
- Pose error termination: Terminating training episodes when the character’s pose deviates too far from the reference. "pose error termination used in \citet{2018-TOG-deepMimic} during training"
- Proprioceptive: Pertaining to internal sensing of the character’s body state (e.g., joint angles, velocities). "The observation can contain proprioceptive information on the character's body"
- Proximal Policy Optimization (PPO): A widely used on-policy policy-gradient RL algorithm for control tasks. "PPO is currently the most commonly-used RL algorithm for motion control tasks, and can be effectively scaled with high-throughput GPU simulators."
- Quadrupedal robot: A four-legged robotic platform. "a Unitree Go2 quadrupedal robot."
- Revolute joint: A one-degree-of-freedom rotational joint (hinge). "which support both 1D revolute joints and 3D spherical joints."
- SMPL body model: A popular parametric human body model used for graphics and vision. "modeled after the SMPL body model \citep{SMPL2015}"
- Spherical joint: A three-degree-of-freedom rotational joint allowing 3D orientation. "which support both 1D revolute joints and 3D spherical joints."
- Value function: A function estimating expected return from a state (or state-action), used for bootstrapping and critic learning. "the value function (i.e. critic)."
- Vectorized environments: Batched environment instances simulated in parallel for high-throughput data collection. "The simulations are implemented using vectorized environments, which can be massively parallelized using GPU simulators for high-throughput data collection during training."
Collections
Sign up for free to add this paper to one or more collections.