- The paper introduces OCNOpt, a novel optimizer that unifies backpropagation with dynamic programming to frame deep learning as an optimal control problem.
- It leverages second-order methods with low-rank approximations and layer-wise feedback policies, enhancing convergence and stability.
- Empirical results demonstrate improved robustness and accuracy across various models including Neural ODEs, ResNets, and feedforward networks.
Optimal Control Theoretic Neural Optimizer: Unifying Backpropagation and Dynamic Programming
The paper "Optimal Control Theoretic Neural Optimizer: From Backpropagation to Dynamic Programming" (2510.14168) introduces OCNOpt, a new class of neural network optimizers derived from optimal control theory. The work establishes a formal connection between backpropagation and the dynamic programming principle, leading to a principled framework for higher-order optimization in deep learning. OCNOpt leverages efficient second-order computations, layer-wise feedback, and game-theoretic extensions, demonstrating improved robustness and convergence across a range of architectures, including feedforward networks, residual networks, and Neural ODEs.
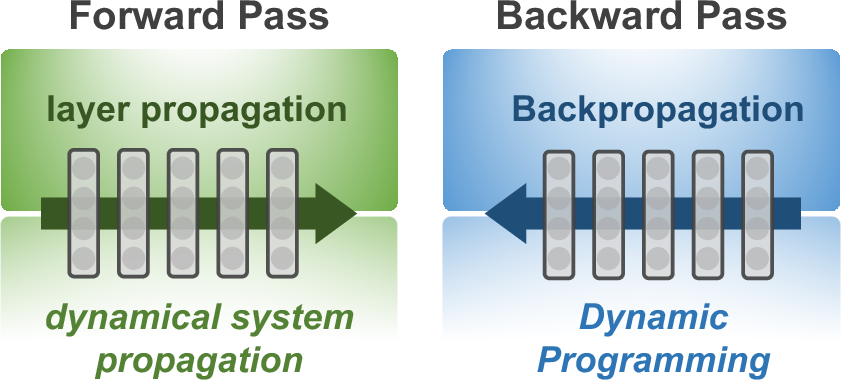
Figure 1: OCNOpt interprets the forward pass as dynamical system propagation and explores the variational structure of backpropagation as dynamic programming.
Theoretical Foundations: Backpropagation as Dynamic Programming
The central theoretical contribution is the formalization of DNN training as an optimal control problem (OCP), where each layer is treated as a time step in a dynamical system and the weights as control variables. The paper demonstrates that backpropagation is equivalent to a first-order approximation of the Bellman equation, the core of dynamic programming. This insight is formalized in Theorem 1, which shows that the backward recursion in backpropagation corresponds to solving an approximate dynamic programming problem with a first-order expansion of the Bellman objective.
By extending this expansion to second order, the authors recover the Differential Dynamic Programming (DDP) algorithm, which introduces feedback policies and second-order curvature information into the optimization process. The DDP update generalizes Newton's method and, under further simplification, reduces to gradient descent. This unification provides a rigorous foundation for designing new optimizers that interpolate between first- and second-order methods.
OCNOpt: Algorithmic Design and Implementation
OCNOpt is constructed by adapting DDP to the context of deep learning, with several key innovations to ensure scalability and efficiency:
- Low-Rank and Gauss-Newton Factorization: The second-order matrices required by DDP are approximated using low-rank outer products, propagated efficiently via vector-Jacobian products. The Gauss-Newton approximation is employed at the output layer, leveraging its connection to the Fisher information matrix and natural gradient methods.
- Curvature Approximation: To avoid the prohibitive cost of inverting large Hessians, OCNOpt supports multiple curvature approximations, including identity (SGD-like), diagonal (RMSProp/Adam-like), and Kronecker-factored (KFAC/EKFAC-like) structures. This flexibility allows OCNOpt to inherit the computational efficiency of first-order methods while retaining second-order benefits.
- Layer-wise Feedback Policies: Unlike standard optimizers, OCNOpt computes parameter updates as feedback policies, adjusting updates based on the propagated state deviations. This closed-loop structure enhances robustness, especially under large learning rates or unstable hyperparameters.
The algorithm is compatible with a wide range of architectures, including residual and inception blocks, by appropriately redefining the propagation rule and Bellman objective. For continuous-time models such as Neural ODEs, OCNOpt extends to the continuous-time Bellman equation, with efficient ODE-based backward propagation of second-order terms.
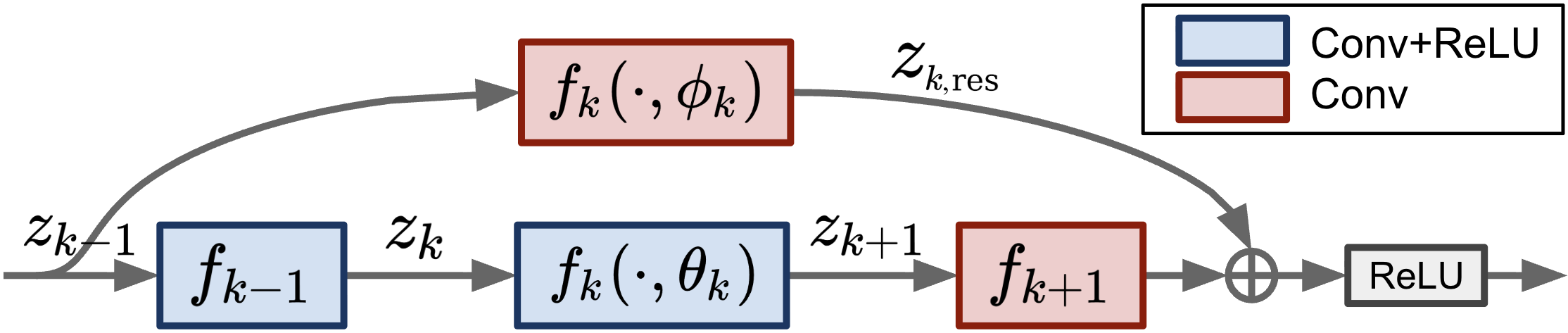
Figure 2: Example of a residual block as Fk(xk,θk,ϕk), illustrating the Markovian construction for skip connections.
Empirical Evaluation
OCNOpt is evaluated on diverse datasets (WINE, DIGITS, MNIST, FMNIST, SVHN, CIFAR10, CIFAR100) and architectures (FCNs, CNNs, ResNets, Inception, Neural ODEs). The optimizer consistently matches or outperforms standard first-order (SGD, Adam, RMSProp) and second-order (EKFAC) baselines, as well as OCP-inspired methods (vanilla DDP, E-MSA), particularly in terms of convergence speed, robustness, and final accuracy.
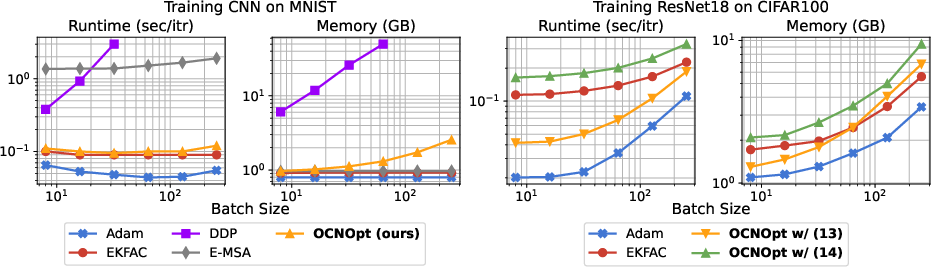
Figure 3: Computational complexity of various optimizers on CNN (MNIST) and ResNet18 (CIFAR100) as a function of batch size (log-log scale).
OCNOpt achieves competitive per-iteration runtime and memory usage, with overheads diminishing for larger models. The method is significantly more stable and efficient than prior OCP-based optimizers, which often fail to scale beyond small networks.
Neural ODEs and Continuous-Time Models
OCNOpt is the first scalable second-order optimizer for Neural ODEs, enabling efficient training for image classification, time-series prediction, and continuous normalizing flows. It outperforms Adam and SGD in both accuracy and negative log-likelihood, with only moderate increases in runtime and memory.

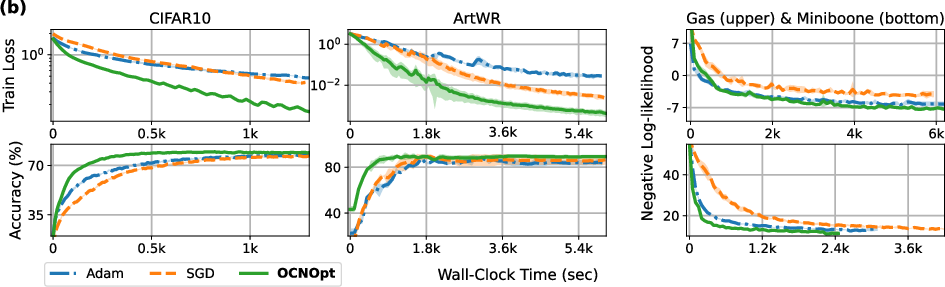
Figure 4: (a) Relative computational complexity of OCNOpt vs. Adam; (b) Convergence as a function of wall-clock time for OCNOpt, Adam, and SGD.
Ablation and Robustness Analysis
The ablation studies isolate the effect of layer-wise feedback policies, showing that enabling feedback consistently improves or maintains performance across architectures and datasets. The benefits are most pronounced under large learning rates, where OCNOpt stabilizes training and accelerates convergence, while SGD and Adam often diverge.

Figure 5: Accuracy improvement or degradation when enabling layer-wise feedback policies for each baseline.
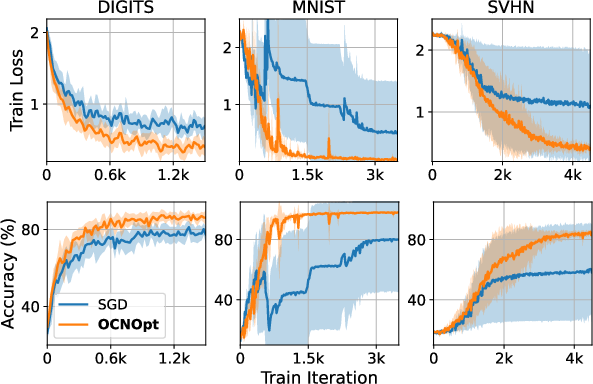
Figure 6: OCNOpt stabilizes training under unstable hyperparameters (large learning rates) across multiple datasets and architectures.
Sensitivity analysis further demonstrates that OCNOpt reduces hyperparameter sensitivity, yielding more consistent convergence across a range of learning rates.
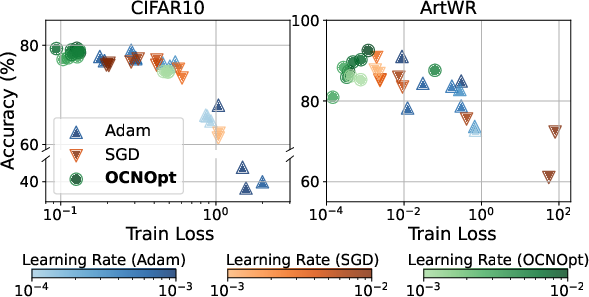
Figure 7: Sensitivity analysis of training results with different optimizers and learning rates (log scale).
Game-Theoretic and Architecture-Aware Extensions
OCNOpt's control-theoretic framework naturally extends to game-theoretic settings, where layers or blocks are treated as players in a dynamic game. The optimizer supports adaptive alignment strategies (e.g., multi-armed bandit selection of skip connection placements), which further improve convergence and final accuracy.
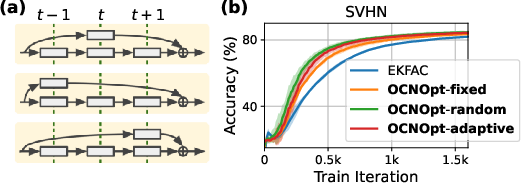
Figure 8: (a) Different placements of residual blocks yield distinct OCNOpt updates; (b) Training convergence for various alignment strategies.
The fictitious player transformation allows cooperative training by splitting layer weights among multiple players, enhancing robustness and convergence up to an optimal number of players.
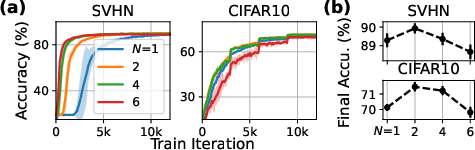
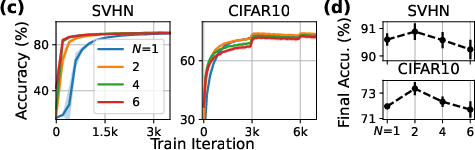
Figure 9: Training curves and final accuracies for different numbers of players in the fictitious player transformation.
Joint Optimization of Neural ODE Integration Time
OCNOpt enables joint optimization of architectural hyperparameters, such as the integration time T in Neural ODEs. By including T as a variable in the Bellman objective and penalizing large values, OCNOpt achieves faster convergence and reduced training time without sacrificing accuracy.
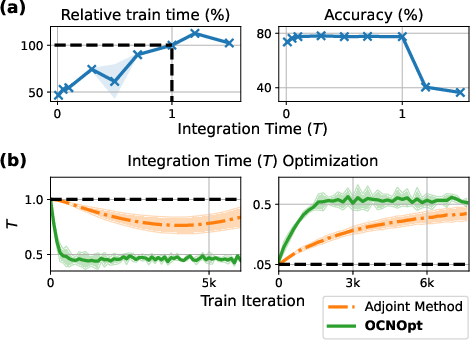
Figure 10: (a) Training time and accuracy vs. integration time T; (b) Convergence of T during joint optimization, with OCNOpt exhibiting stable dynamics.
Visualization of Feedback Policies
The feedback gains computed by OCNOpt can be visualized, revealing that the optimizer attends to meaningful differences in input space, such as distinguishing visually similar classes in MNIST.

Figure 11: Visualization of feedback policies on MNIST, highlighting the most responsive input differences.
Implications and Future Directions
OCNOpt provides a principled, scalable framework for incorporating optimal control and dynamic programming into deep learning optimization. The unification of backpropagation and DDP enables the design of optimizers that combine the efficiency of first-order methods with the robustness and adaptivity of second-order, feedback-driven updates. The framework is extensible to game-theoretic and architecture-aware settings, and supports joint optimization of model hyperparameters.
Key implications:
- OCNOpt bridges the gap between control theory and deep learning, offering a new lens for algorithmic design.
- The feedback structure enhances robustness, particularly in challenging optimization regimes.
- The method is applicable to a broad class of models, including continuous-time and hybrid architectures.
Future research directions include further reducing the computational gap with first-order methods, extending the OCP framework to stochastic and partial differential equation-based models (e.g., Neural SDEs, PDEs), and integrating with large-scale architectures such as Transformers.
Conclusion
The OCNOpt framework establishes a rigorous connection between backpropagation and dynamic programming, leading to a new class of scalable, robust, and efficient optimizers for deep neural networks. By leveraging control-theoretic principles, low-rank second-order approximations, and feedback policies, OCNOpt advances the state of the art in neural network optimization and opens new avenues for principled algorithmic development in machine learning.