DPRF: A Generalizable Dynamic Persona Refinement Framework for Optimizing Behavior Alignment Between Personalized LLM Role-Playing Agents and Humans
Abstract: The emerging LLM role-playing agents (LLM RPAs) aim to simulate individual human behaviors, but the persona fidelity is often undermined by manually-created profiles (e.g., cherry-picked information and personality characteristics) without validating the alignment with the target individuals. To address this limitation, our work introduces the Dynamic Persona Refinement Framework (DPRF). DPRF aims to optimize the alignment of LLM RPAs' behaviors with those of target individuals by iteratively identifying the cognitive divergence, either through free-form or theory-grounded, structured analysis, between generated behaviors and human ground truth, and refining the persona profile to mitigate these divergences. We evaluate DPRF with five LLMs on four diverse behavior-prediction scenarios: formal debates, social media posts with mental health issues, public interviews, and movie reviews. DPRF can consistently improve behavioral alignment considerably over baseline personas and generalizes across models and scenarios. Our work provides a robust methodology for creating high-fidelity persona profiles and enhancing the validity of downstream applications, such as user simulation, social studies, and personalized AI.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several unresolved issues that future research could address:
- Absence of human evaluation: Behavioral alignment is assessed only with automated text similarity metrics; no blinded human judgments (e.g., target individuals, domain experts) to validate persona fidelity and cognitive plausibility.
- No statistical testing or variance reporting: Improvements are presented as averages without confidence intervals, significance tests, or sensitivity to random seeds; reproducibility and robustness are unclear.
- Convergence criterion is naive: Termination uses string equality or a fixed iteration cap; lacks semantic convergence measures, adaptive stopping rules, or stability diagnostics across runs.
- Sensitivity to initial persona quality: The framework’s performance may depend on the starting persona; no systematic study of different initializations, basins of attraction, or failure modes.
- Reliability of LLM-based behavior analysis: The Behavior Analysis Agent can hallucinate or misattribute divergences; no calibration against human-coded analyses, inter-rater reliability, or error propagation assessment.
- Theory-of-Mind (ToM) scaffold generality: ToM may not be optimal across domains; no comparison with alternative cognitive frameworks (e.g., Big Five, values, Self-Determination Theory, goal/plan hierarchies) or hybrid analyses.
- Mapping divergences to persona edits: The refinement step lacks a formal, auditable mapping from identified divergences to specific persona changes; no taxonomy of edit types or causal justification.
- Overfitting risk to ground truth: DPRF might tailor personas to replicate specific utterances rather than generalizable behavior; no held-out contexts or cross-task transfer tests to check generalization.
- Ground-truth knowledge constraints: The agent may reflect facts the persona could not plausibly know; no mechanism to enforce knowledge constraints, retrieval gating, or epistemic uncertainty in personas.
- Limited task diversity: Evaluation is restricted to text generation tasks; no tests on decision-making, interactive multi-turn behavior, planning, or action choices where alignment is crucial.
- PublicInterview failure analysis: The study acknowledges poor performance but does not systematically analyze contributing factors (topic shifts, interviewer style, real-time goals, social context) or propose concrete remedies.
- Missing multimodal context: Real interviews involve audio, video, prosody, and social cues; no exploration of multimodal DPRF variants or integration of situational signals and environment features.
- Structural fidelity metrics are thin: Beyond embeddings/ROUGE/BERTScore, there is no measurement of discourse structure, argumentation schemes, rhetorical devices, emotion trajectories, or pragmatic intent alignment.
- Safety in mental health domains: Generating posts with depression and suicidal ideation poses safety risks; no clinical guardrails, harm audits, crisis-response constraints, or IRB/ethical oversight plan.
- Fairness and stereotype risks: Persona refinement may amplify demographic stereotypes; no bias audits, counterfactual evaluations (sensitive attribute flips), or debiasing mechanisms.
- Privacy risks and re-identification: Use of public figure interviews and PDB profiles raises privacy concerns; de-identification procedures are described but not validated with formal privacy/re-identification tests.
- Data leakage verification: No checks for model memorization of public figures or dataset leakage; absence of retrieval tests or contamination audits for models with internet-scale training.
- Automatic selection of analysis strategy: Choosing free-form vs ToM analysis is manual; no meta-controller or criteria to select the optimal analysis method per scenario dynamically.
- Persona stability and drift: Iterative edits may cause drift or contradictory traits; no mechanism for resolving conflicts, representing uncertainty, or tracking persona change over time.
- Longitudinal adaptation: DPRF’s behavior with continuous, evolving ground truth is untested; no evaluation of long-term stability, catastrophic forgetting, or incremental learning protocols.
- Data efficiency claims unquantified: The framework claims data efficiency but lacks scaling curves that relate performance to the number/quality of ground-truth samples and iteration count.
- Computational cost and latency: No profiling of iteration cost, token usage, or throughput; unclear how DPRF scales to thousands of users or near real-time personalization.
- Model-size dependence: Improvements appear larger with stronger models (e.g., Claude), but there is no systematic scaling study across parameter counts or providers to isolate model capability effects.
- Baseline persona construction risk: Curated baselines may bias results; no comparison to automatic persona extraction/generation baselines or alternative biography-based baselines with standardized protocols.
- Cross-lingual and cultural generalization: All tasks are English-centric; no evaluation across languages, cultural contexts, or non-Western social norms and interview styles.
- Robustness to adversarial prompts and distribution shift: The refined personas are not stress-tested for prompt injection, adversarial contexts, or out-of-distribution topics.
- Failure characterization: Aside from PublicInterview, the paper does not classify typical failure modes (e.g., incorrect goals, implausible emotions, knowledge errors) or provide diagnostic tools.
- Persona edit interpretability: Edits are not analyzed for interpretability or trust; no audit trail, versioning, or user-facing explanations of what changed and why.
- Formalization of DPRF as optimization: The framework is positioned as gradient-free optimization, but lacks theoretical analysis (e.g., convergence guarantees, stability bounds, or objective formulations).
- Handling contradictory human behaviors: Real individuals exhibit inconsistent behavior; DPRF does not represent uncertainty, sub-personas, or context-conditioned traits to reconcile contradictions.
- Integration with fine-tuning or RLHF: DPRF is compared only conceptually to training-based methods; no empirical trade-off study (e.g., performance, data needs, interpretability) when combined or contrasted.
- Release and reproducibility: Prompts, refined personas, and code are not fully specified for external replication; absence of standardized pipelines, seeds, and artifacts for independent validation.
Glossary
- Ablation study: An experimental method that removes or varies components to assess their impact on performance. "and report the findings from our ablation study."
- BERTScore F1: A similarity metric that uses contextual embeddings from BERT to compare generated text with reference text, reported as an F1 score. "We employ commonly adopted similarity-based metrics for comparison, including Sentence Embedding Similarity, which we calculated with SentenceTransformers~\cite{reimers2019sentence-bert}, ROUGE-L F1~\cite{lin-2004-rouge}, and BERTScore F1~\cite{zhang2020bertscoreevaluatingtextgeneration}."
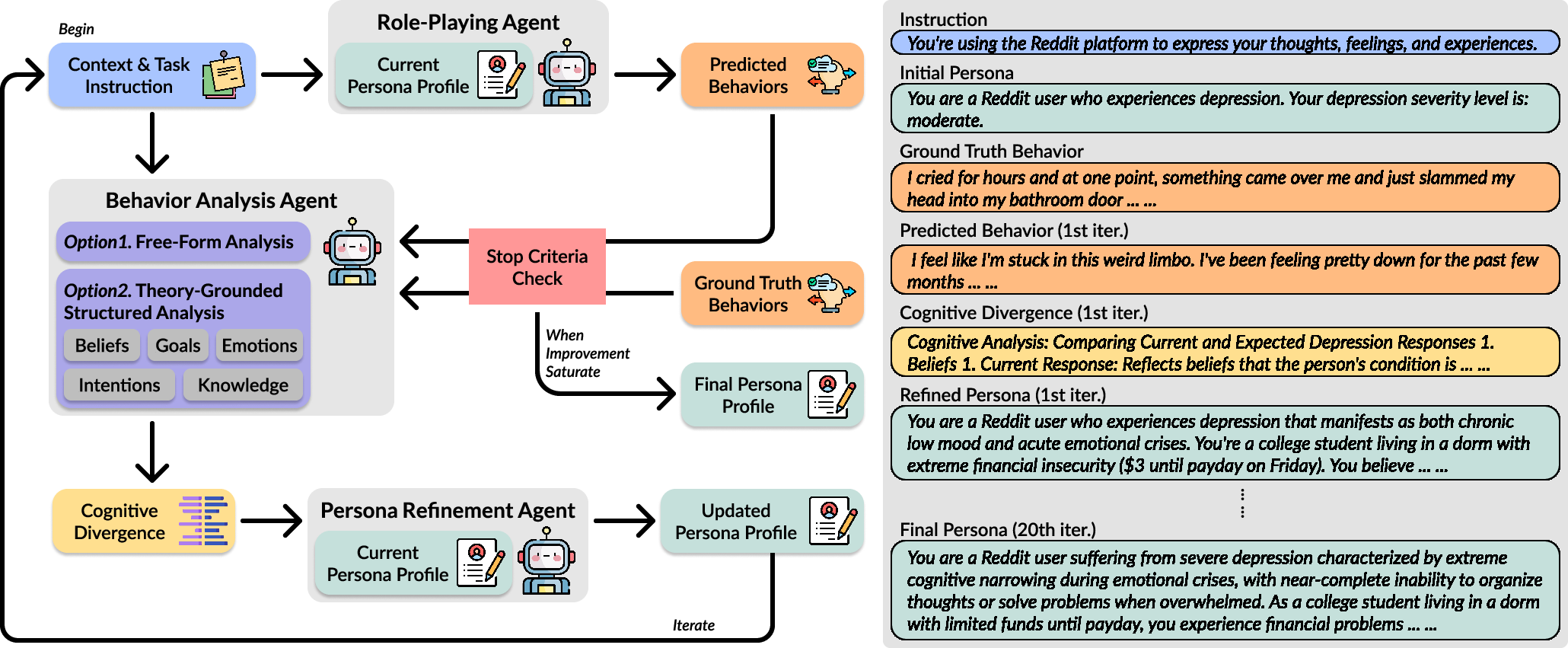
- Behavior Analysis Agent (BAA): An LLM-based component that compares agent-generated behavior with human ground truth to identify cognitive divergences. "The behavior analysis agent compares the behaviors predicted by LLM RPA with human ground truth behavior and identifies underlying divergences with respect to cognitive characteristics in a text summary ."
- Behavioral alignment: The degree to which an agent’s generated behaviors match those of the target human individual. "DPRF can consistently improve behavioral alignment considerably over baseline personas and generalizes across models and scenarios."
- Data-driven optimization: Iteratively improving a system (e.g., a persona) using empirical data rather than one-shot manual creation. "The premise of our work is that persona generation should be treated as a data-driven optimization process rather than a one-shot task."
- Data-efficient: Achieving strong performance while requiring relatively small amounts of data. "Lastly, DPRF is designed to be model-agnostic, domain-agnostic, and data-efficient."
- De-identification: The process of removing or masking personally identifying information to prevent re-identification. "De-identification was carefully and exhaustively conducted over the interview transcript to ensure a fair evaluation and mitigate the potential biases that the transcript might reveal the speakers' identities."
- Domain-agnostic: Designed to work across different application areas without domain-specific customization. "Lastly, DPRF is designed to be model-agnostic, domain-agnostic, and data-efficient."
- Downstream applications: Tasks or systems that use the outputs of a method (e.g., refined personas) for further analysis or deployment. "enhancing the validity of downstream applications, such as user simulation, social studies, and personalized AI."
- Dynamic Persona Refinement Framework (DPRF): The proposed iterative framework that refines LLM personas to better align with human behavior. "To address this limitation, our work introduces the Dynamic Persona Refinement Framework (DPRF)."
- Few-shot learning: Methods that enable models to adapt or generalize from a small number of examples. "DPRF differs from traditional prompt-based optimization or few-shot learning methodologies that ask the model to generate a ``best'' persona in a single-turn generation."
- Fine-tuning: Adjusting a pre-trained model’s parameters on task-specific data to improve performance. "First, it is a gradient-free method that does not require fine-tuning the underlying LLM's parameters."
- Gradient-free: Optimization approaches that do not update model parameters via gradient descent. "First, it is a gradient-free method that does not require fine-tuning the underlying LLM's parameters."
- Ground truth: The authoritative or true reference data used to evaluate or guide models. "the alignment between an LLM RPA's generated behaviors and observed human ground truth."
- Inference-time optimization: Improving behavior or outputs during model inference rather than during training. "our experiments position DPRF as a gradient-free, inference-time optimization framework."
- Latent representation: A hidden, internal description capturing essential characteristics, modifiable to affect behavior. "Instead, DPRF is designed upon the recognition that the persona is a latent, modifiable representation of agents' cognitive characteristics that can be refined with respect to behavioral analysis."
- Lexical fidelity: How closely the chosen words and phrasing of generated text match the reference at a fine-grained level. "we observe a distinction between its effect on holistic semantic alignment (measured by Sentence Embedding Similarity) and fine-grained lexical fidelity (measured by ROUGE-L and BERTScore)."
- LLM Role-Playing Agents (LLM RPAs): LLM-driven agents that simulate specific individuals based on persona profiles to predict behaviors. "This capability has enabled LLM Role-Playing Agents (LLM RPAs), which are designed to simulate a specific individual by predicting their behaviors, social interactions, and reasoning processes based on a provided persona profile~\cite{park2023generative, park2024generative}."
- MBTI personality types: A psychological typology framework (Myers–Briggs Type Indicator) categorizing personalities into 16 types. "including their detailed biographical descriptions and MBTI personality types."
- Model-agnostic: Applicable across different models without requiring model-specific changes. "Lastly, DPRF is designed to be model-agnostic, domain-agnostic, and data-efficient."
- Multi-perspective judging systems: Evaluation setups that aggregate judgments from diverse perspectives or personas. "as evaluators in multi-perspective judging systems~\cite{zheng2023judging, chen2025multi},"
- Persona fidelity: The faithfulness of a persona profile in representing the target individual’s true characteristics and behaviors. "but the persona fidelity is often undermined by manually-created profiles (e.g., cherry-picked information and personality characteristics) without validating the alignment with the target individuals."
- Persona Refinement Agent (PRA): The component that revises the current persona using divergence analysis and context. "This agent takes the current persona , the divergence analysis , and the original context as input to generate the revised persona "
- Prompt-based optimization: Improving model outputs by crafting or iteratively refining prompts rather than changing model parameters. "DPRF differs from traditional prompt-based optimization or few-shot learning methodologies that ask the model to generate a ``best'' persona in a single-turn generation."
- Role-Playing Agent (RPA): The agent that generates behavior by simulating a persona in a given context. "A standard RPA takes a persona profile of an individual or a group of people and a task context as input, and is then prompted to generate a behavioral response accordingly by ``role-playing'' the given persona."
- ROUGE-L F1: A text-overlap metric based on the longest common subsequence, reported as an F1 score. "We employ commonly adopted similarity-based metrics for comparison, including Sentence Embedding Similarity, which we calculated with SentenceTransformers~\cite{reimers2019sentence-bert}, ROUGE-L F1~\cite{lin-2004-rouge}, and BERTScore F1~\cite{zhang2020bertscoreevaluatingtextgeneration}."
- Sentence Embedding Similarity: A measure of semantic similarity computed from vector embeddings of sentences. "We employ commonly adopted similarity-based metrics for comparison, including Sentence Embedding Similarity, which we calculated with SentenceTransformers~\cite{reimers2019sentence-bert}, ROUGE-L F1~\cite{lin-2004-rouge}, and BERTScore F1~\cite{zhang2020bertscoreevaluatingtextgeneration}."
- SentenceTransformers: A library for generating sentence-level embeddings for semantic similarity tasks. "We employ commonly adopted similarity-based metrics for comparison, including Sentence Embedding Similarity, which we calculated with SentenceTransformers~\cite{reimers2019sentence-bert}, ROUGE-L F1~\cite{lin-2004-rouge}, and BERTScore F1~\cite{zhang2020bertscoreevaluatingtextgeneration}."
- Stop criterion: The condition determining when an iterative process should terminate. "The persona refinement process terminates when a stop criterion is met: either when the refined persona converges (i.e., is identical to in the last iteration) or after a pre-set maximum number of iterations is reached."
- Structured analysis: An analysis constrained by an explicit theoretical framework or dimensions. "DPRF aims to optimize the alignment of LLM RPAs' behaviors with those of target individuals by iteratively identifying the cognitive divergence, either through free-form or theory-grounded, structured analysis, between generated behaviors and human ground truth,"
- Theory of Mind (ToM): The cognitive capacity to attribute beliefs, goals, intentions, emotions, and knowledge to oneself and others. "Further, we investigated the effectiveness of a theory-grounded behavior analysis agent in the principles of Theory of Mind (ToM)~\cite{premack1978does}."
- User surrogates: Agent-based substitutes used to stand in for humans in experiments or evaluations. "including their use as human surrogates in social science experiments~\cite{10.1145/3526113.3545616, park2023generative, hua2023war},"
Collections
Sign up for free to add this paper to one or more collections.