To Infinity and Beyond: Tool-Use Unlocks Length Generalization in State Space Models
Abstract: State Space Models (SSMs) have become the leading alternative to Transformers for sequence modeling. Their primary advantage is efficiency in long-context and long-form generation, enabled by fixed-size memory and linear scaling of computational complexity. We begin this work by showing a simple theoretical result stating that SSMs cannot accurately solve any ``truly long-form'' generation problem (in a sense we formally define), undermining their main competitive advantage. However, we show that this limitation can be mitigated by allowing SSMs interactive access to external tools. In fact, we show that given the right choice of tool access and problem-dependent training data, SSMs can learn to solve any tractable problem and generalize to arbitrary problem length/complexity (i.e., achieve length generalization). Following our theoretical finding, we demonstrate that tool-augmented SSMs achieve remarkable length generalization on a variety of arithmetic, reasoning, and coding tasks. These findings highlight SSMs as a potential efficient alternative to Transformers in interactive tool-based and agentic settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “To Infinity and Beyond: Tool-Use Unlocks Length Generalization in State Space Models”
Overview
This paper studies two kinds of AI models that read and write long sequences of text: Transformers (like many big chatbots) and State Space Models (SSMs, like Mamba). Transformers are powerful but slow and costly when the text gets long. SSMs are much faster on long text, but they have a big weakness: their memory is fixed-size, so they struggle with truly long, multi-step problems.
The main idea of the paper is simple: if you let SSMs use external tools—like a notebook they can read and write, a search function, or a code runner—they can “think” step-by-step with help and handle much longer and harder problems than before. With the right kind of training, SSMs can keep solving bigger versions of the same problem far beyond what they saw during training. The authors call this length generalization.
What questions did the paper ask?
- Can SSMs, with their fixed memory, solve tasks that get longer and more complicated as the input grows?
- If not, can giving SSMs interactive access to tools (like an external memory or filesystem) remove this limit?
- Does this work not just in theory, but also in practice, on tasks like big-number math, logic, and coding?
How did they study it?
The authors combine theory (mathematical proofs) and experiments.
Theory in everyday terms
- Think of an SSM as a person with a small notepad (fixed memory). If you ask them to write a very long essay or solve a long puzzle where the answer gets longer as the task grows, they eventually run out of space. The paper proves this limitation formally: without outside help, SSMs cannot reliably solve “truly long-form” tasks just by thinking to themselves (even if they write a step-by-step solution, called Chain-of-Thought).
- Now give the SSM a set of tools—like a big external notebook it can read and write, and allow it to use these tools interactively (not just once). The paper proves that with the right training examples, an SSM can learn to use these tools to solve any task that is computable and generalize to much longer versions—meaning it can handle bigger inputs or more steps than it saw during training.
Key settings they compare:
- CoT-only: the model “thinks out loud” but has no tools.
- Single-turn tool-use: the model can call a tool once.
- Interactive tool-use: the model can use tools many times, switching between “thinking,” using tools, and writing the final answer.
Result from the proofs:
- CoT-only and single-turn tool-use aren’t enough; SSMs still hit a wall on long tasks.
- Interactive tool-use breaks the wall and enables length generalization.
Experiments in everyday terms
The authors train models to follow step-by-step demonstrations that include tool commands. They test on much larger problems than the ones seen during training.
Tools they provide to the models:
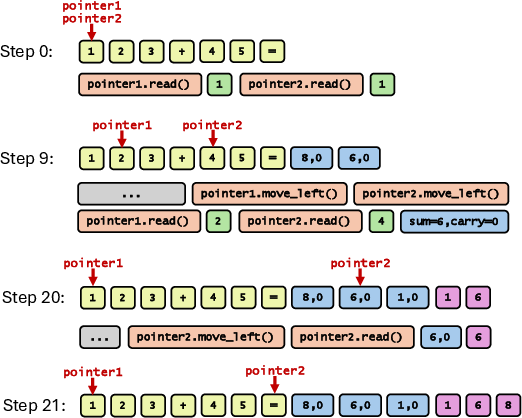
- A “pointer-based memory”: like a cursor that can move left/right across the whole conversation and read tokens (helps with long arithmetic and step tracking).
- A “search tool”: find all occurrences of a string in the context (helps with logic tasks).
- Real coding tools: shell commands to read/edit files and run code (helps fix bugs across many files).
Tasks they tried:
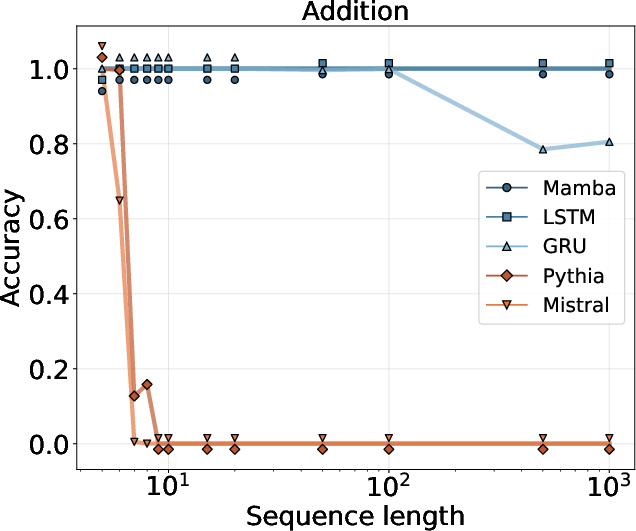
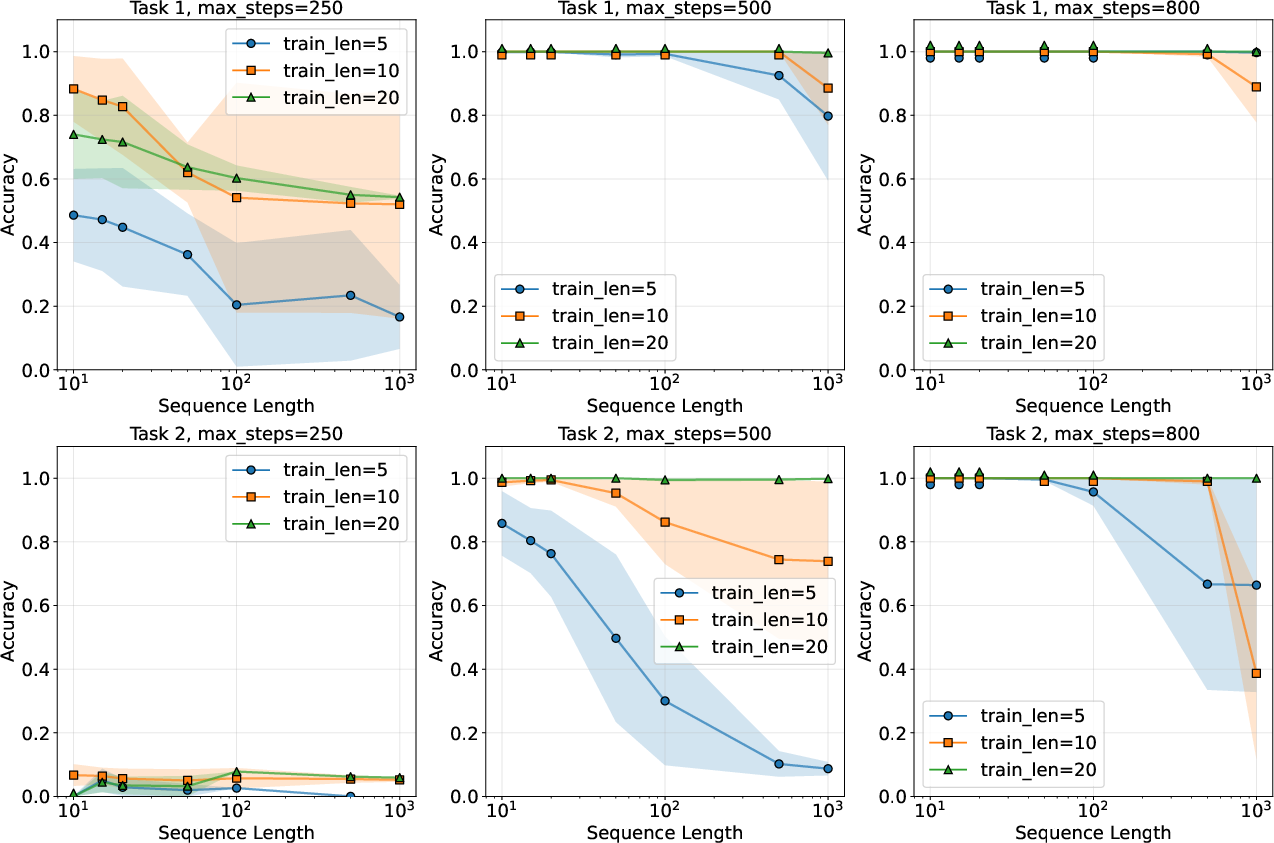
- Multi-digit addition and multiplication: Learn the standard paper-and-pencil methods. Models trained on small numbers (like 5–10 digits) are tested on much bigger ones (up to 1,000 digits).
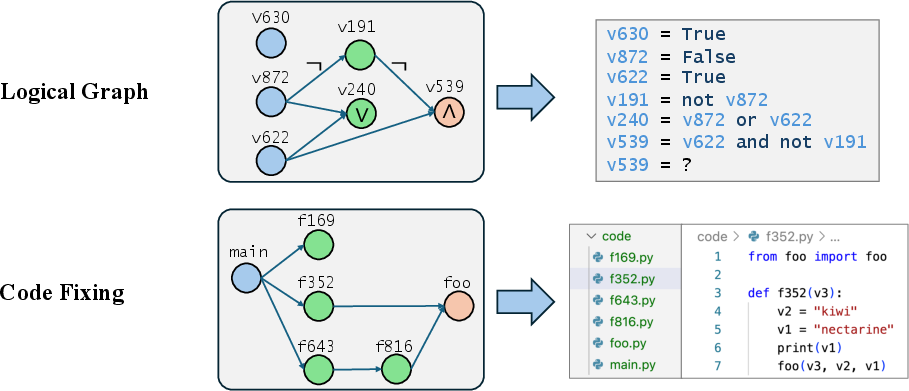
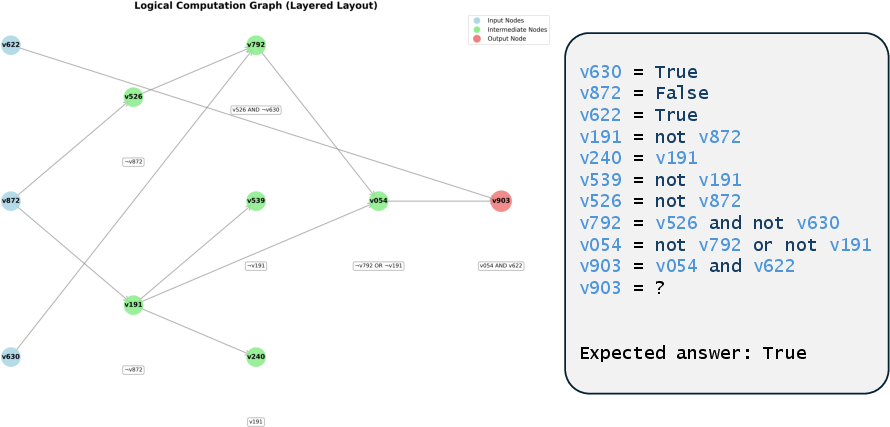
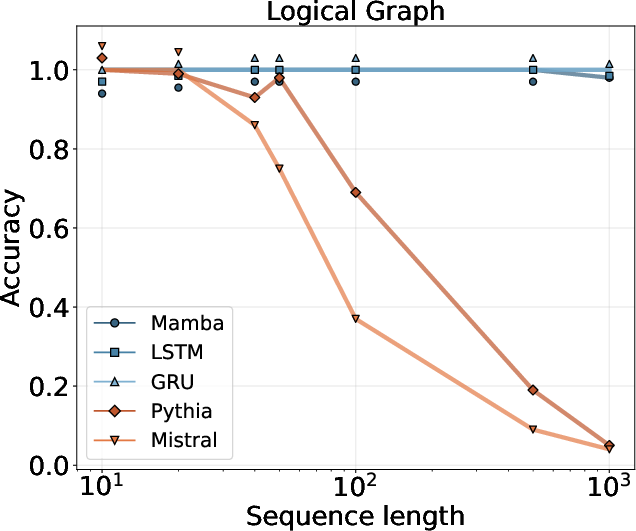
- Logical graphs: Read a small program that describes a network of logical operations and compute the final result.
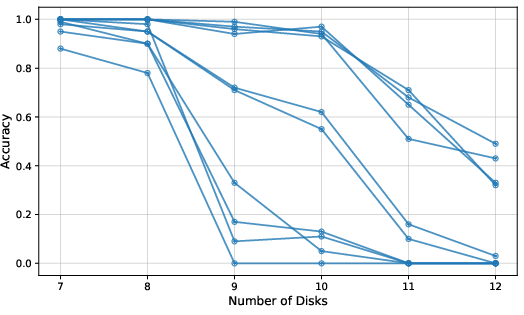
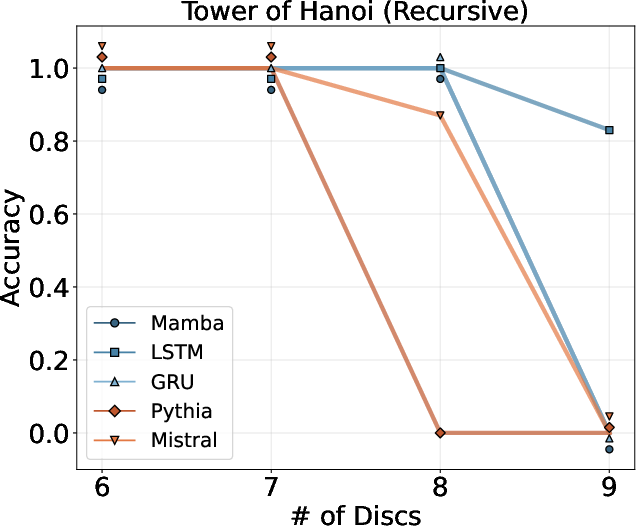
- Tower of Hanoi: Output the sequence of moves to solve the puzzle as the number of disks grows.
- Coding: Fix a bug that requires editing multiple files in a codebase. They collected real tool-use traces from coding agents and trained models to imitate them.
Models they compared:
- SSMs and RNNs: Mamba, LSTM, GRU
- Transformers: Pythia, a Mistral-based local-attention Transformer
What did they find, and why is it important?
- Without tools, SSMs fail on truly long, growing-output tasks. Even if they “show their work,” their fixed memory becomes a bottleneck. This confirms the theory.
- Single-turn tool-use isn’t enough for SSMs to beat the limitation.
- With interactive tool-use, SSMs show remarkable length generalization:
- Arithmetic: Mamba and other recurrent models trained on small numbers reliably solved 1,000-digit additions and multiplications by following the learned algorithms with the memory tool.
- Logical graphs: SSMs scaled to graphs far larger than the training ones.
- Tower of Hanoi: Some improvement, but more modest, likely because the number of moves grows exponentially.
- Coding: When trained on interactive tool-use traces (like iteratively running code, reading files, making small changes), Mamba handled larger codebases better than a comparable Transformer. For small codebases, the Transformer often did great; but as projects got larger and longer than the training data, Mamba’s accuracy held up better—if it was trained to imitate interactive agents.
- Bottom line: Giving SSMs the ability to use tools interactively turns their fixed memory into a non-issue, letting them keep solving bigger and bigger problems while staying efficient.
What does this mean going forward?
- SSMs could be excellent “agents” that use tools—like code editors, search engines, databases, and external memory—especially when tasks need many steps and produce long outputs.
- This can make AI systems both fast (thanks to SSMs’ efficiency on long sequences) and capable (thanks to tools that extend memory and computation).
- It changes how we should evaluate and train models: not just as standalone text generators, but as parts of a system that can act, read, write, and iterate with tools.
- For real-world applications (coding assistants, math tutors, research helpers), training with interactive tool-use examples can unlock strong generalization to bigger, more complex problems than seen during training.
Takeaway
SSMs alone are fast but hit a wall on long, growing tasks. Add interactive tool-use—especially external memory—and that wall disappears. With the right training, SSMs can “learn the method” and keep applying it to much larger problems, making them a strong, efficient alternative to Transformers in tool-based, multi-step settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and can guide future research:
- Theoretical necessity claims are only shown for CoT-only and single-turn settings; the minimal degree of interaction (e.g., bounded number of tool calls or bounded observation bandwidth) required for GSSMs to overcome the lower bound is not characterized.
- Length generalization proof relies on a custom pointer-based external memory tool with idealized read/write semantics; robustness to realistic tool constraints (latency, failures, partial observability, rate limits, noisy outputs, and non-atomic operations) is not analyzed.
- The learning algorithm used in the positive result is a non-standard “string matching” approach; there is no proof that standard training (e.g., SGD on common SSMs/RNNs) reliably induces the required tool-use behavior and length generalization.
- Sample complexity and coverage requirements for the training trajectories (e.g., how much of the Turing machine’s transition table must be seen, as a function of task complexity) are not quantified.
- Theoretical framework assumes finite state spaces for GSSMs; extension of the lower bound and positive results to continuous, high-precision hidden states typical of modern SSMs (and the role of numerical precision/quantization) is not provided.
- The definition of long-form generation assumes finite input/output spaces and monotone support growth; applicability to tasks with infinite alphabets, continuous outputs, or non-monotone output distributions is unclear.
- The lower bound provides an error floor of at least 1−α beyond some length, but the tightness of this bound and its dependence on architecture size, precision, and output entropy are not empirically validated.
- Sufficiency result hinges on exact simulation of a Turing machine via tool calls; there is no characterization of tasks for which exponential-time or exponential-length outputs make interactive SSMs impractical (e.g., Tower of Hanoi), nor formal criteria linking output growth rate to achievable generalization.
- The impact of different external memory abstractions (pointer tape vs. random-access store, key–value memory, vector databases, graph stores) on learnability, data efficiency, and length generalization is not explored.
- The role of logging choices (e.g., whether to append observations to the context) on learnability and generalization is only fixed to one regime; alternative logging policies and their trade-offs are not studied.
- No analysis of the computational cost and latency introduced by frequent interactive tool calls; end-to-end efficiency gains of SSMs with tools vs. Transformers with tools are not quantified.
- Transformers with interactive tool-use and/or external memory retrieval were not systematically benchmarked in the same agentic settings, leaving unclear whether similar length generalization could be achieved with attention-based models.
- Hybrid architectures (attention + SSM) are noted but not evaluated in agentic settings; their potential to balance efficiency with generalization in tool-use scenarios remains open.
- The experimental addition/multiplication tasks use strictly synthetic, noiseless trajectories and exact-match evaluation; robustness to noisy, imperfect, or suboptimal demonstrations (common in real settings) is not examined.
- The distillation setup for coding filters for successful and short trajectories, introducing selection bias; effects of training on mixed-quality or failed trajectories on generalization are not assessed.
- The coding task focuses on a single synthetic bug class (propagating a variable through dependencies); generalization to diverse, realistic bug types, larger and heterogeneous repositories, and multi-file refactoring is untested.
- The agentic coding environment uses simple bash tools; portability to richer tool ecosystems (IDEs, compilers, static analyzers, test harnesses, version control workflows) and the effect on generalization are unexplored.
- Sensitivity to initialization and training randomness is noted for Tower of Hanoi but not systematically studied across tasks; reproducibility and stability across seeds and training curricula need quantification.
- The pointer-based memory experiments show strong generalization under teacher-forcing; error accumulation at inference (e.g., compounding mistakes in tool calls and reads) and mitigation strategies are not evaluated.
- Task mixture results (addition + multiplication) hint at synergies under limited budgets, but there is no principled model of task relatedness or guidance for constructing auxiliary task sets that maximize generalization.
- Theoretical and experimental work focuses on exact correctness; approximate solutions, probabilistic tasks, and trade-offs between accuracy and tool-call budgets are not modeled.
- Safety, security, and sandboxing considerations for tool-use (e.g., preventing harmful commands, ensuring integrity of external state) are not addressed.
- Memory persistence across sessions (lifelong external memory) and multi-agent collaboration over shared tools/memory are not covered; implications for scalability and generalization are open.
- There is no release of code, datasets, or tool implementations to facilitate replication and broader evaluation across tasks and models.
- Practical guidance on constructing training trajectories that achieve the necessary coverage (e.g., curriculum design, trajectory diversity, automated trajectory generation) is not provided.
- The trade-off between SSM hidden-state size and interactive tool complexity (e.g., how increasing model capacity reduces reliance on tools) remains unexplored.
- The effect of positional encodings, state updates, and architectural variants within SSMs on tool-use learning and length generalization is only minimally ablated.
- How these findings translate to multilingual, multimodal, or streaming settings (e.g., speech or vision + text) with tool-use is left unexplored.
Practical Applications
Immediate Applications
The following bullets summarize specific, deployable use cases that leverage interactive tool-use with State Space Models (SSMs) to achieve efficient long-form generation and length generalization today.
- Software engineering (coding agents)
- Application: SSM-based interactive code agents for large repositories that perform iterative run–test–edit loops to fix bugs, trace variables, and propagate changes across deep dependency graphs.
- Sector: Software
- Tools/products/workflows: IDE plugins, CI/CD bot runners,
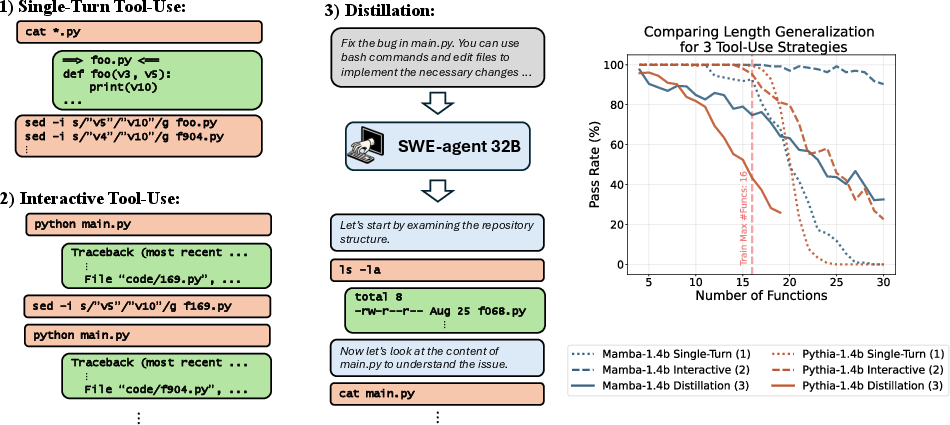
grep/search tools, bash/file I/O, ReAct-style multi-turn workflows, trajectory distillation from capable SWE agents. - Assumptions/dependencies: Requires curated interactive tool-use trajectories (not single-turn), robust tool APIs (file system, test runners), and task prompts that encourage iterative interaction. Performance degrades if limited to single-turn use.
- Cost-optimized agent pipelines (LLMops)
- Application: Replace Transformer-based agents with tool-augmented SSMs for tasks dominated by external tool interaction (code search, repository introspection, run–fix cycles), reducing per-token compute while maintaining accuracy beyond training lengths.
- Sector: Software, Cloud/Platforms
- Tools/products/workflows: Orchestrators with function-calling or action tagging, KV-cached tool outputs, external memory services.
- Assumptions/dependencies: Benefits concentrate on tool-heavy pipelines; requires sufficient trajectory coverage of action–observation pairs; attention is still useful for purely in-context tasks.
- Math tutoring and algorithmic learning apps
- Application: Step-by-step arithmetic tutors (multi-digit addition/multiplication) that explicitly use external memory (“scratchpad” with pointers/search) to generalize from short training examples to very long problems.
- Sector: Education
- Tools/products/workflows: Pointer-based memory tools, structured “scratchpad” outputs, CoT (chain-of-thought) scaffolds.
- Assumptions/dependencies: Needs high-quality demonstrations with interactive tool calls; generalization may be limited for tasks whose output length grows exponentially (e.g., Tower of Hanoi).
- Code review and variable flow tracing
- Application: Agents that trace variable propagation across modules (e.g., ensuring a specific variable is passed through all dependency paths), detect missing parameters, and propose fixes at scale.
- Sector: Software, Security/Quality
- Tools/products/workflows: Dependency graph extractors, code search tools, static analyzers, interactive edit-and-run loops.
- Assumptions/dependencies: Requires accurate graph construction and instrumented environments; benefits from interactive multi-turn workflows.
- Customer support and case management in long threads
- Application: SSM agents that navigate extensive ticket histories, search tool outputs, and iteratively update summaries or action plans with external memory.
- Sector: Customer Support, Enterprise Software
- Tools/products/workflows: Search in CRM/ticket systems, external memory for session state, ReAct-style “thought–action–observation” loops.
- Assumptions/dependencies: Integration with enterprise systems, access control, careful trajectory curation to avoid hallucinated actions.
- Data pipeline reasoning for DAGs
- Application: Agents that inspect large directed acyclic graphs (DAGs) of transformations, search for node definitions and dependencies, and plan consistent updates across the graph.
- Sector: Data Engineering/ETL
- Tools/products/workflows: Graph exploration tools, search APIs, external memory for intermediate derivations, iterative planning loops.
- Assumptions/dependencies: Requires tooling to expose DAGs in searchable formats and sufficient demonstration coverage.
- Academic benchmarks and replicable agentic evaluations
- Application: Construct and share datasets that include interactive tool-use trajectories (pointer-based memory, search, bash), enabling reproducible evaluations of length generalization under different agent designs.
- Sector: Academia/Research
- Tools/products/workflows: Open-source ReAct-style environments, standardized tool interfaces, length generalization benchmarks (arithmetic, logic graphs, coding).
- Assumptions/dependencies: Community adoption of tool-use benchmarks; clear protocol for masking tool observations during training.
- Energy-efficient AI guidance (organizational policy)
- Application: Internal policies encouraging tool-augmented SSMs for long-form, tool-heavy tasks to reduce compute and costs without sacrificing quality.
- Sector: Policy (organizational/IT governance)
- Tools/products/workflows: Procurement and architecture guidelines, cost/performance dashboards comparing SSM vs Transformer agents.
- Assumptions/dependencies: Evidence gathering on workload-specific benefits; risk assessment for tasks requiring global, in-context attention.
Long-Term Applications
These use cases are promising but require additional research, tooling, and scaling—especially in safety, integration, and data availability.
- Longitudinal healthcare reasoning
- Application: Agents that navigate years of EHRs with external memory, perform long-horizon reasoning (medication changes, lab trends), and produce actionable care plans.
- Sector: Healthcare
- Tools/products/workflows: Secure external memory stores, audited tool calls, structured clinical knowledge tools, ReAct-style clinical prompts.
- Assumptions/dependencies: HIPAA-compliant infrastructure, rigorous validation, bias/safety guardrails, and high-quality clinical trajectories.
- Financial analysis and backtesting over large horizons
- Application: Tool-augmented SSMs for long-horizon backtesting, portfolio attribution, and regulatory reporting over massive time-series.
- Sector: Finance
- Tools/products/workflows: Market data interfaces, external memory for intermediate results, audit-ready action logs.
- Assumptions/dependencies: Data quality, latency constraints, strict compliance and auditability.
- Robotics and long-horizon planning
- Application: Agents with external memory for planning sequences of actions in complex environments, recalling maps, and iteratively updating plans from sensor/tool observations.
- Sector: Robotics/Autonomy
- Tools/products/workflows: Memory tools connected to world models, planning toolkits, action–observation loops.
- Assumptions/dependencies: Real-time constraints, safety certification, robust integration with physical systems.
- Scientific workflows and lab automation
- Application: Agents that manage long experimental protocols, search lab logs, and maintain persistent external memory across runs to generalize procedures.
- Sector: Scientific Research/Lab Automation
- Tools/products/workflows: LIMS integration, structured experiment logs, external scratchpads for protocols.
- Assumptions/dependencies: Standardization of lab tool interfaces, high-fidelity logging, contamination/safety controls.
- Formal verification and proof assistance
- Application: Efficient proof assistants that use external memory to navigate large theorem libraries and construct long proofs in interactive steps.
- Sector: Software Verification/Math
- Tools/products/workflows: Theorem search tools, tactic libraries, external proof state memory.
- Assumptions/dependencies: High-quality proof trajectories, domain-specific safety checks, reliable tool interoperability.
- Enterprise-scale code maintenance for monorepos
- Application: Autonomous agents that plan and execute multi-file refactors, API migrations, and dependency updates across massive codebases.
- Sector: Software
- Tools/products/workflows: Repository-wide search/edit tools, CI/CD orchestration, persistent external memory to track refactor state.
- Assumptions/dependencies: Access controls, rollback strategies, multi-agent coordination, robust evaluation frameworks.
- Multi-agent systems with shared external memory
- Application: Teams of SSM agents coordinating via shared, auditable memory substrates to decompose and solve large tasks.
- Sector: Software/Platforms
- Tools/products/workflows: Shared memory boards, permissions and consensus, telemetry for tool calls.
- Assumptions/dependencies: Access control policies, conflict resolution protocols, monitoring and governance.
- Curriculum-scale educational tutoring
- Application: Tutors that generalize to complex, multi-step problem sequences across grades by leveraging external memory and interactive reasoning.
- Sector: Education
- Tools/products/workflows: Structured trajectory datasets, progressive curricula, interactive scratchpads.
- Assumptions/dependencies: Content alignment, fairness and bias audits, student privacy protections.
- Regulatory standards for agentic tool-use and auditability
- Application: Policies defining logging, traceability, and accountability for agents that write to and read from external memory.
- Sector: Public Policy/Regulation
- Tools/products/workflows: Audited tool APIs, standardized action–observation logs, compliance testing suites.
- Assumptions/dependencies: Cross-industry consensus, privacy/security frameworks, enforcement mechanisms.
- Cloud platform services for external memory and tool orchestration
- Application: Managed services offering persistent, scalable “scratchpad” memory and tool orchestration optimized for SSM agents.
- Sector: Cloud/Platforms
- Tools/products/workflows: Memory-as-a-service, action routers, tool adapters with security layers.
- Assumptions/dependencies: Strong isolation, cost controls, service reliability and portability.
Cross-cutting assumptions and dependencies
Across applications, feasibility hinges on:
- Interactive tool-use: Single-turn tool calls (one-shot) are not sufficient; agents need multi-turn, ReAct-style loops with thoughts, actions, and observations interleaved.
- External memory design: Pointer/search-based tools must be reliable, secure, and exposed via stable APIs. Observations should be masked during training when appropriate.
- Training data quality: Length generalization requires trajectories with adequate coverage of state–symbol transitions (analogous to Turing machine operations). Poor coverage limits generalization.
- Safety and auditability: Tool calls should be logged with clear provenance; access controls and guardrails must prevent unsafe writes/reads.
- Task fit: SSMs excel when external tools dominate the workload and outputs scale with problem complexity; Transformers may remain preferable for purely in-context tasks without tool interaction.
- Output scaling: Generalization is strongest for tasks with linear output growth (e.g., arithmetic); tasks with exponentially growing outputs (e.g., Tower of Hanoi) require more careful design and may show limited extrapolation.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Agentic settings: Scenarios where models act as agents that interact with tools and environments to solve tasks. "interactive tool-based and agentic settings."
- Chain of Thought (CoT): A prompting style where models produce step-by-step reasoning before the final answer. "As test-time scaling paradigms that involve the generation of long Chain of Thought (CoT) have become the leading solution for improving reasoning capabilities"
- Directed-acyclic computation graph: A directed graph with no cycles used to represent dependencies in computations. "In this task, we construct a directed-acyclic computation graph with nodes."
- Distillation: Training a model to imitate the behavior or trajectories of a stronger agent/model. "3) Distillation: SWE-agent LLM \citep{yang2025swe} instructed to solve the bug in the code."
- External memory: Storage outside the model that can be read/written via tools to extend the model’s effective memory. "allowing SSMs access to external memory through interactive tool-use makes them much more powerful."
- Flash Attention: An optimized attention algorithm that improves efficiency and memory usage for long sequences. "efficient implementations such as Flash Attention \citep{dao2022flashattention} and KV caching enable close to linear complexity."
- Function calling: A model capability to invoke structured functions/tools programmatically. "does not naively support function calling"
- Generalized State Space Model (GSSM): A fixed-memory sequence model defined by an update rule and an output rule over a finite state. "A generalized state space model (GSSM) is a (potentially probabilistic) function "
- In-context learning: Learning behavior from examples provided in the input context without parameter updates. "tasks that involve memorization of long sequences and in-context learning \citep{jelassi2024repeat, park2024can, akyurek2024context}."
- Interactive Tool-Use: Multi-turn tool invocation interleaved with thoughts and outputs. "3) Interactive Tool-Use: The model is allowed to use as many commands as it needs, and freely interleave thoughts, commands and outputs."
- KV caching: Storing key-value pairs from past attention steps to speed up autoregressive generation. "efficient implementations such as Flash Attention \citep{dao2022flashattention} and KV caching enable close to linear complexity."
- Length generalization: The ability to generalize from short/simple training instances to problems of arbitrary length/complexity. "achieve length generalization on any tractable long-form generation task."
- Linear Transformers: Transformer variants designed so computation scales linearly with sequence length. "Examples of such architectures include variants of Linear Transformers \citep{katharopoulos2020transformers}"
- Local (sliding window) attention: Attention restricted to a fixed window of nearby tokens to reduce compute/memory. "Transformers where all the attention layers have local (sliding window) attention with fixed window size, are also GSSMs."
- Long-form generation: Tasks where the output length or space grows with problem complexity. "We formally define long-form generation tasks to be problems where the effective number of outputs grows with the complexity of the problem."
- Mamba: A state space model architecture for efficient sequence modeling with linear-time inference. "We finetune Mamba and Pythia (Transformer) on trajectories collected from different tool-use agents for solving a coding problem."
- Memory-tool oracle: A tool interface that exposes read/write operations to an external memory for the agent. "There exists memory-tool oracle "
- Neural GPU: A neural architecture designed to learn algorithmic tasks via parallel, convolutional-like operations. "with some improvements such as the Neural GPU \citep{kaiser2015neural}"
- Neural Turing Machine (NTM): A neural model augmented with differentiable external memory that can emulate algorithm execution. "\cite{graves2014neural} introduces the Neural Turing Machine (NTM), a neural network that can simulate Turing machines and thus execute computable algorithms."
- Next-token prediction objective: The standard language modeling objective of predicting the next token. "We train the model using the standard next-token prediction objective with teacher-forcing"
- Pointer-based memory: An external memory mechanism where the agent moves pointers to read/write tokens at specific positions. "we augment the model with a pointer-based memory tool that gives the model access to past tokens in the input/output context."
- Positional encodings: Representations injected into models to encode token positions for sequence processing. "including various choices of positional encodings and output format"
- ReAct: A framework for interleaving reasoning (thoughts) and actions (tool calls) with observations. "We introduce a new theoretical framework for studying ReAct \citep{yao2023react} agents"
- RetNet: A sequence model architecture with retentive mechanisms designed for efficient long-context processing. "H3 \citep{fu2022hungry}, RetNet \citep{sun2023retentive}, Mamba-1 and Mamba-2 \citep{gu2023mamba, dao2024transformers}"
- RoPE scaling: A technique to extend rotary positional embeddings to longer contexts at inference. "We experimented with applying RoPE scaling when using the Transformer beyond the training context length, both in finetuning and evaluation, and observed mixed results."
- Scratchpad: A technique where intermediate computations are written explicitly to aid model reasoning. "scratchpads \citep{nye2021show,lee2023teaching,zhou2023algorithms, abbe2024far}"
- Single-Turn Tool-Use: A setting where the agent may issue only one tool command before producing the final answer. "2) Single-Turn Tool-Use: The model is allowed to issue a single command, followed by an observation, and then generate the output."
- State Space Models (SSMs): Sequence models with fixed-size internal state updated over time, enabling linear compute scaling. "State Space Models (SSMs) have become the leading alternative to Transformers for sequence modeling."
- Teacher-forcing: Feeding the ground-truth previous tokens during training to stabilize learning. "We train the model using the standard next-token prediction objective with teacher-forcing"
- Test-time scaling: Improving capability by increasing computation (e.g., longer reasoning) during inference. "As test-time scaling paradigms that involve the generation of long Chain of Thought (CoT) have become the leading solution for improving reasoning capabilities"
- Tool-use trajectories: Logged sequences of thoughts, actions, and observations that demonstrate tool interactions. "In this paper, we study the length generalization of SSMs when trained on data with tool-use trajectories."
- Tower of Hanoi: A benchmark puzzle used to assess algorithmic reasoning and planning in models. "Tower of Hanoi task (a task which proved to be difficult for reasoning models, see \cite{shojaee2025illusion})."
Collections
Sign up for free to add this paper to one or more collections.