- The paper demonstrates that layered control architectures, which separate fast proprioceptive stabilization from slower perception-based navigation, enable superior robustness in humanoid locomotion.
- It introduces a two-stage training curriculum that first focuses on blind stabilization and then fine-tunes with perception, effectively avoiding poor local minima.
- Extensive simulation and hardware experiments confirm that two-stage policies achieve up to 10% higher success rates and 3× fewer contacts than monolithic models.
Layered Control Architectures for Robust Humanoid Locomotion
This paper presents a systematic investigation into the role of control architecture in enabling robust humanoid locomotion over unstructured terrain. The central thesis is that a minimal layered control architecture (LCA)—comprising a fast proprioceptive stabilizer and a slower, compact perception-driven navigation policy—yields superior robustness compared to monolithic, end-to-end designs, regardless of network complexity or perception encoder sophistication.
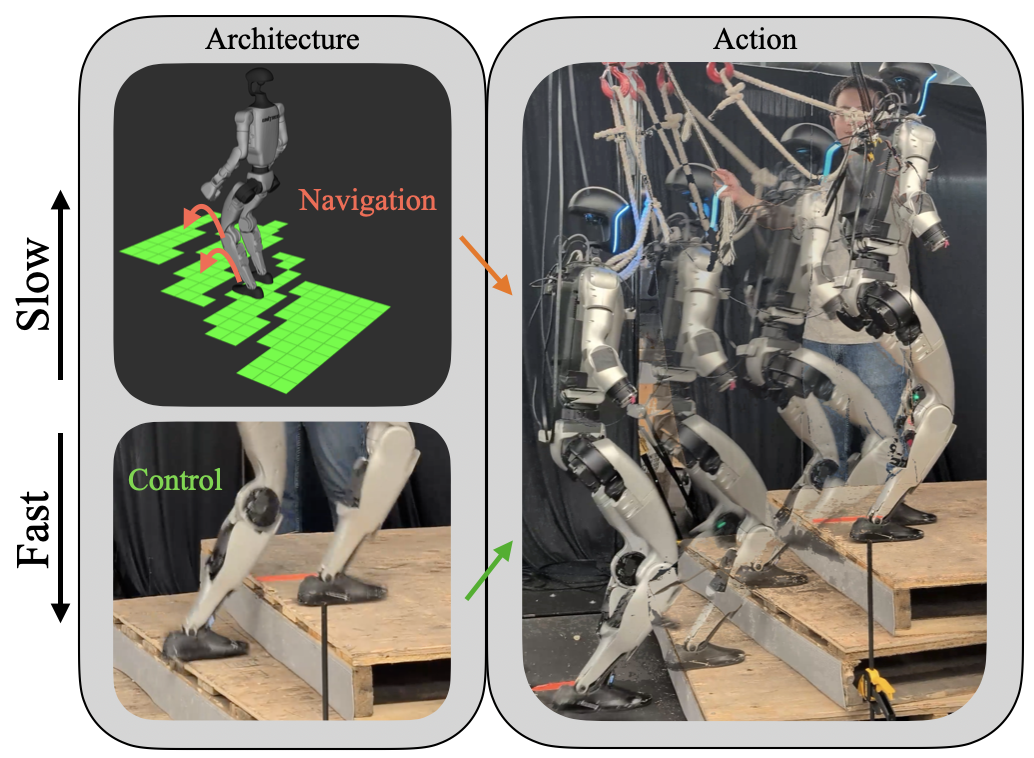
Figure 1: A humanoid robot trained to traverse complex terrain through use of a combination perception information and fast proprioception information. Using this input effectively requires the use of structured architecture in order to produce performant and robust results.
Architectural Principles and Theoretical Motivation
The LCA paradigm is motivated by decades of guidance–navigation–control (GNC) practice and recent theoretical work on multi-rate control [matni2024lca]. The architecture enforces separation of timescales: a high-rate stabilizer operates on proprioceptive signals, while a lower-rate navigation module processes exteroceptive cues (e.g., heightmaps). This separation is not merely for computational efficiency; it enables "diversity-enabled sweet spots" (DeSS) [nakahira2021diversity], where the combined stack outperforms any single monolithic policy.
The paper formalizes the optimization landscape for two-stage training. By first optimizing the fast stabilizer in a blind setting, the method avoids poor local minima associated with highly non-concave reward landscapes. The subsequent introduction of perception allows the navigation layer to condition the stabilizer on longer-horizon terrain information, yielding improved robustness and generalization.
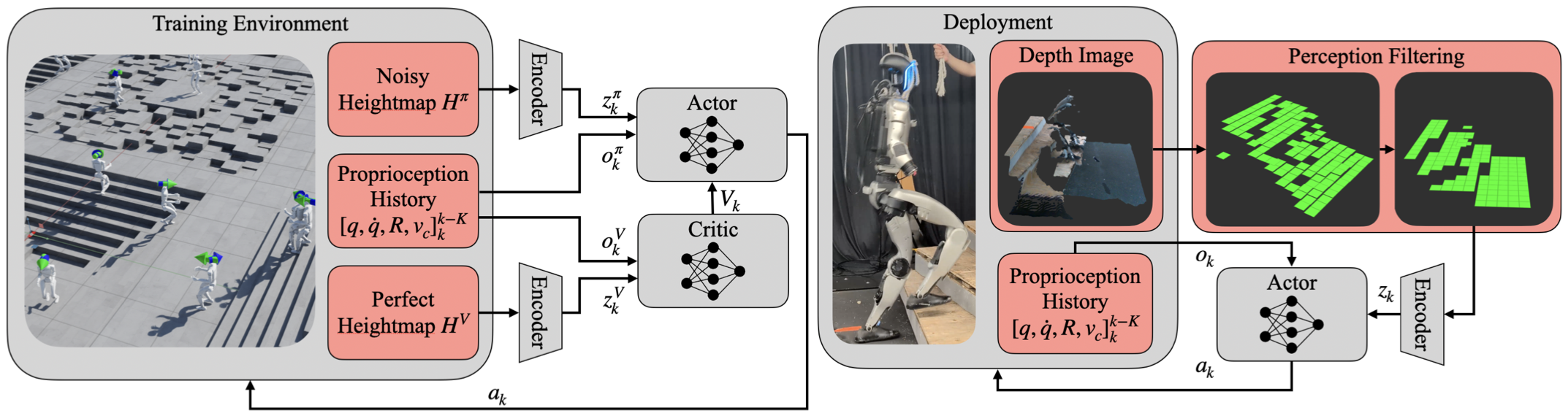
Figure 2: Training and Deployment Overview: both actor and critic are two-stage architectures each with their own perception encoder. The actor receives noisy heightmap information, while the critic receives perfect information, and each receive proprioception history. During deployment, a depth image is filtered and passed through the trained encoder, and the actor combines this with the proprioception history to determine action.
Network and Observation Design
The proposed architecture consists of:
- Perception Encoder: Either a small CNN or MLP, mapping a local heightmap (11×11 grid) to a latent embedding.
- Actor Network: MLP or LSTM, consuming proprioceptive history and the perception embedding to output joint position setpoints.
- Critic Network: MLP with privileged access to a larger, noise-free heightmap and world-frame velocities.
Observations are normalized and zero-centered to facilitate sim-to-real transfer and reduce bias. The perception stack is intentionally minimal, with simple downsampling, outlier rejection, and quantization, eschewing complex filtering (e.g., U-Nets, Transformers).
Two-Stage Training Curriculum
Training proceeds in two stages:
- Blind Stabilization: The actor receives no perception input; only proprioception is used. This phase emphasizes stabilization and contact robustness.
- Perception-Critical Fine-Tuning: Heightmap input is enabled for the actor, allowing the policy to learn longer-horizon planning conditioned on local terrain.
This curriculum is shown to yield policies that are less sensitive to exteroceptive noise and more robust to out-of-distribution terrain.
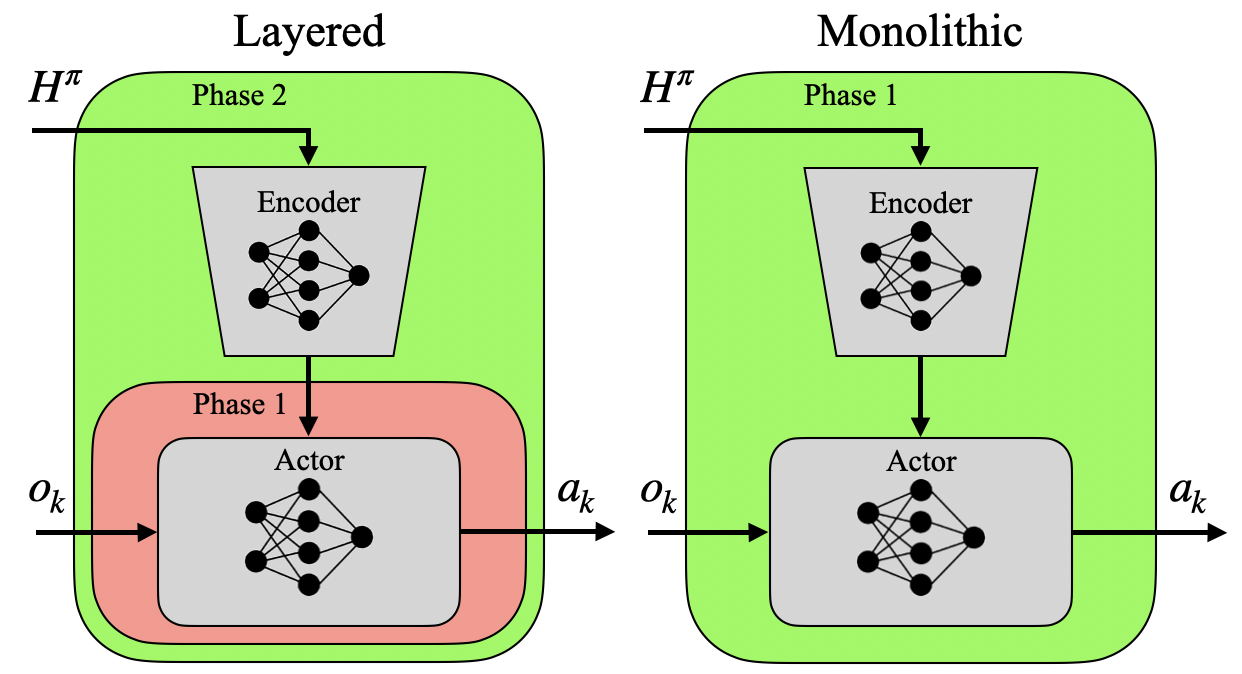
Figure 3: Layered verses monolithic architectures: while the network architecture may be identical, training in two phases allows them to assume the layered control structure.
Simulation Experiments
Extensive simulation experiments are conducted in IsaacSim, with 4096 parallel environments and a balanced mixture of stair ascent/descent, uneven terrain, and flat ground. Seven policy variants are compared: blind baseline, three one-stage (monolithic) models, and three two-stage (layered) models, spanning MLP, LSTM, and CNN architectures.
Key metrics include success rate, contacts per step, and tracking error. On medium-difficulty tasks, all policies perform comparably. However, on hard, out-of-distribution terrain, two-stage policies consistently outperform one-stage models, with up to 10 percentage points higher success rates and 3× fewer contacts per step. Notably, the specific choice of encoder (CNN vs. MLP) and backbone (MLP vs. LSTM) has only minor impact compared to the architectural separation.
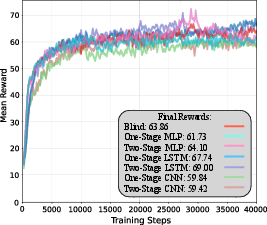
Figure 4: Training rewards from each of the policies. We see that in training, all the policies perform largely identically; we believe that the small deviations may be a function of the network architecture of that component, such as the LSTM's ability to store a hidden state or the CNN's ability to reason more spatially, but may also simply be products of randomness.
Hardware Validation
The policies are deployed on the Unitree G1 humanoid, with perception provided by dual Intel Realsense D435 cameras and onboard Jetson Orin NX. Four hardware tasks are evaluated: stair ascent, stair descent (navigation-dominant), and hinged/soft ledge (control-dominant).

Figure 5: The four hardware experiment tasks. The first two, stair ascent and stair descent, emphasize navigation, while the second two, hinged and soft ledge, emphasize control.
Results show that:
- Blind policies excel on control-dominant tasks but fail on navigation-dominant tasks due to lack of edge-aware foot placement.
- One-stage MLP policies underperform across all tasks, often failing to stabilize under exteroceptive noise.
- Two-stage policies (MLP and CNN+MLP) achieve high success rates on all tasks, demonstrating robust transfer from simulation to hardware.

Figure 6: Blind, MLP, and CNN depicted results. The monolithic policy is not included, as for some tasks it was never successful.
Implications and Future Directions
The findings strongly support the claim that architectural separation of timescales and information pathways is the primary enabler of robust perception-conditioned locomotion. The minimal LCA closes the gap to more complex pipelines that rely on richer models, elaborate perception stacks, or intricate reward shaping. This has significant implications for the design of future humanoid locomotion systems:
- Simplicity and Robustness: Minimal architectures with well-posed interfaces can achieve high robustness, reducing engineering overhead and computational requirements.
- Generalization: Layered designs are less prone to overfitting and more resilient to exteroceptive noise and OOD terrain.
- Scalability: The approach is amenable to scaling to more complex tasks and platforms, as the architectural principles are platform-agnostic.
Future work may explore deeper integration of model-based planning, adaptive rate separation, and architectural distillation, as well as theoretical analysis of the implicit multi-rate decomposition in teacher–student pipelines.
Conclusion
This paper provides compelling evidence that layered control architectures, not network complexity or perception encoder sophistication, are the key to robust humanoid locomotion in unstructured environments. The two-stage curriculum and minimal LCA yield policies that generalize well, transfer to hardware, and outperform monolithic alternatives. These results advocate for a principled architectural approach in the design of perception-conditioned control systems for legged robots.